 使用 Vision Transformer 和 NVIDIA TAO,提高視覺 AI 應用的準確性和魯棒性
使用 Vision Transformer 和 NVIDIA TAO,提高視覺 AI 應用的準確性和魯棒性
Vision Transformer(ViT)正在席卷計算機視覺領域,提供令人難以置信的準確性、復雜現實場景下強大的解決方案,以及顯著提升的泛化能力。這些算法對于推動計算機視覺應用的發展發揮了關鍵作用,而 NVIDIA 則通過 NVIDIA TAO Toolkit 和 NVIDIA L4 GPU,使應用集成ViT 變得輕而易舉。
ViT 的不同之處
ViT 是一種將原本用于自然語言處理的 Transformer 架構應用于視覺數據的機器學習模型。相比基于 CNN 的同類模型具有一些優勢,并能夠并行處理大規模輸入的數據。CNN 采用的是局部操作,因而缺乏對圖像的全局理解;而 ViT 則以并行和基于自注意的方式來有效地處理圖像,使得所有圖像塊之間能夠相交互,從而提供了長程依賴和全局上下文的能力。
圖 1 展示了 ViT 模型中的圖像處理流程。輸入圖像被分為較小的固定尺寸的圖塊,之后這些圖塊被展平并轉換為一系列的標記 (tokens) 。這些標記連同位置編碼一起被輸入到 Transformer 編碼器中,該編碼器由多個自注意力和前饋神經網絡組成。
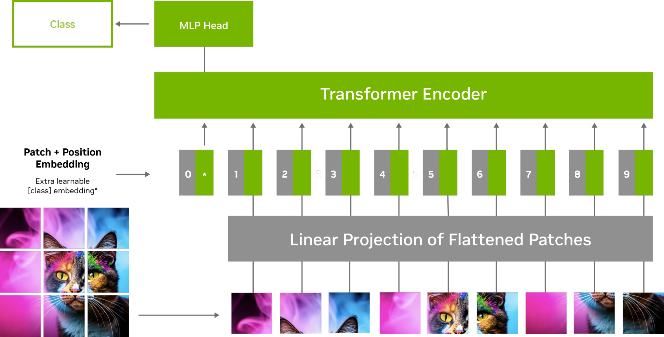
圖 1. 包含位置編碼器和編碼器的 ViT 模型處理圖像
通過自注意力機制,每個標記或圖塊與其他標記進行交互,以決定哪些標記是重要的。這有助于模型捕捉標記之間的關系和依賴,并學習哪些標記是更重要的。
例如在有一只鳥的圖像中,模型會更關注重要的特征,比如眼睛、鳥嘴和羽毛等,而不是背景。這使得訓練更加高效,增強了對圖像損壞和噪聲情況的魯棒性,并在未見過的物體上表現出更優越的泛化能力。
為何 ViT 對計算機
視覺應用至關重要
真實世界的環境具有多樣且復雜的視覺模式。與 CNN 不同,ViT 憑借自身的可擴展性和適應性,能夠處理各種任務,而且無需針對具體的任務調整架構。

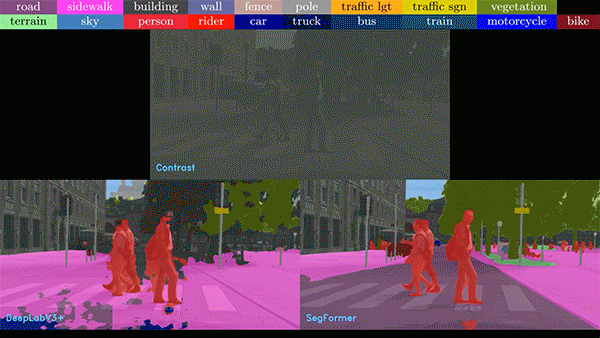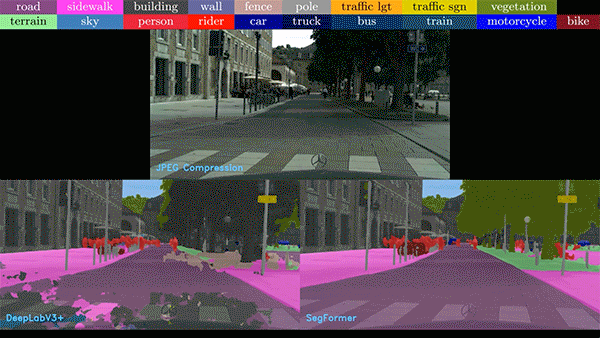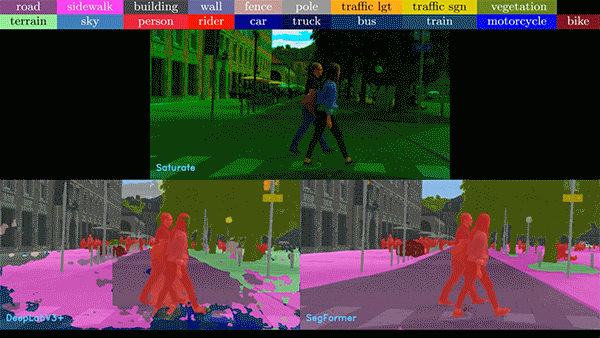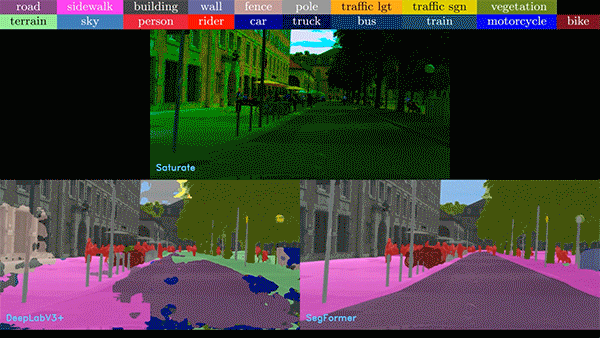
圖 2. 各種不完美和嘈雜的
現實數據給圖像分析帶來了難題
在下面的視頻中,我們比較了基于 CNN 和 ViT 的模型的噪聲視頻。在任何情況下,ViT 模型表現都優于 CNN 模型。
視頻 1. 了解 SegFormer,這是一個
結合高效率和穩健語義分割能力的 ViT 模型
將 ViT 與 TAO Toolkit 5.0 集成
TAO 是一個低代碼 AI 工具包,用于構建和加速視覺 AI 模型,可用于輕松地構建和集成 ViT 到應用和 AI 工作流程中。用戶可以通過簡單的界面和配置文件快速開始訓練 ViT,無需深入了解模型架構。
TAO Toolkit 5.0 提供幾種常用于計算機視覺任務的先進 ViT,包括:
全注意力網絡(FAN)
FAN 是由 NVIDIA 研究團隊開發的一系列基于 Transformer 架構的神經網絡主干模型。該系列模型在對抗各種干擾方面達到了當前技術水平的最佳程度,如表格 1 所示。這些主干模型能夠輕松適應新的領域,對抗噪聲和模糊。表格 1 展示了所有 FAN 模型在 ImageNet-1K 數據集上所達到的準確率,無論是干凈版本還是經過干擾處理后的版本。
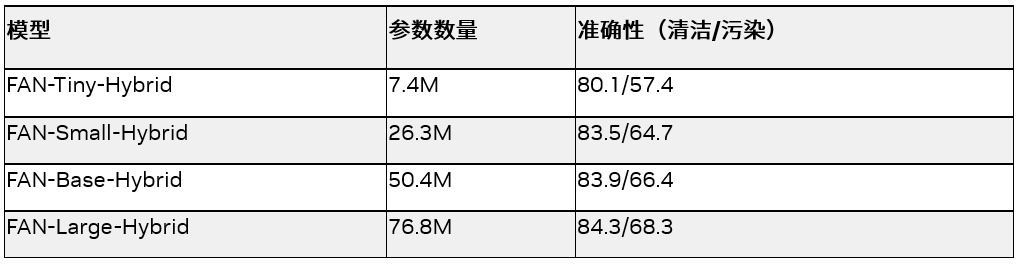
表 1. FAN 模型的大小和準確性
全局上下文 Vision Transformer (GC-ViT)
GC-ViT 是 NVIDIA 研究部門開發的一種具有極高準確性和計算效率的新型架構。該架構解決了 Vision Transformer 中缺乏歸納偏置的問題。通過使用局部自注意力機制,GC-ViT 在參數較少的情況下在 ImageNet 上取得更好的結果,同時結合全局自注意力,可以實現更好的局部和全局空間交互。
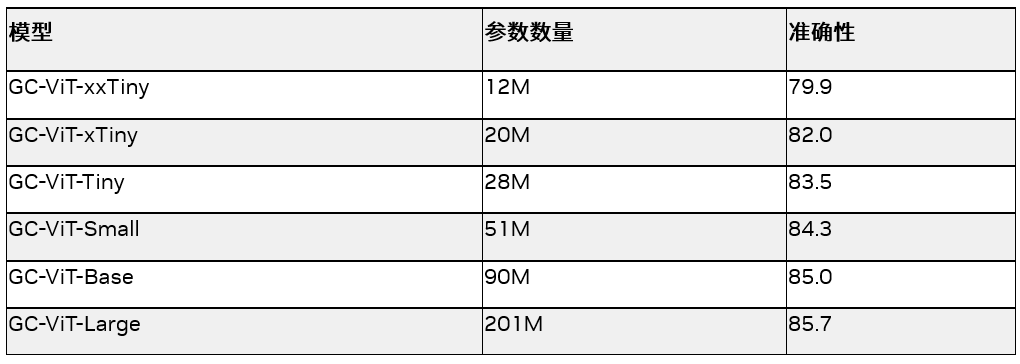
表 2. GC-ViT 模型的大小和準確性
帶有改進后去噪錨框的檢測 Transformer(DINO)
DINO 是最新一代的檢測變換器(DETR),其訓練收斂速度比其他 ViT 和 CNN 更快。在 TAO 工具套件中,DINO 十分靈活,可以與傳統 CNN(例如 ResNets)和基于 Transformer 的骨干網絡(如 FAN)和 GC-ViT 等相結合。
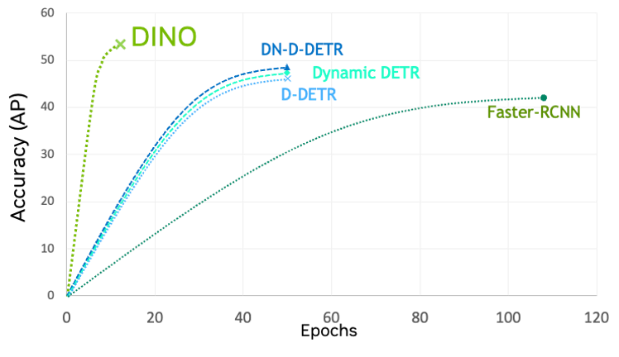
圖 3. DINO 與其他模型的準確性比較
Segformer
Segformer 是一個輕量級且具有魯棒性的基于 Transformer 的語義分割模型。其解碼器由輕量級的多頭感知層組成。它避免使用大多 Transformer 使用的位置編碼,可在不同分辨率下進行高效推理。
使用 NVIDIA L4 GPU
高效驅動 Transformer
NVIDIA L4 GPU 是為未來的視覺 AI 工作負載而打造的。它們采用 NVIDIA Ada Lovelace 架構,旨在加速具有變革性的 AI 技術。
L4 GPU 擁有高達 FP8 485 TFLOPs 的計算能力,適于運行 ViT 工作負載。相較更高精度的計算方式,FP8 的低精度計算可以減輕內存壓力,還可以顯著提升 AI 的處理速度。
L4 是一款多功能、節能高效的設備,具有單槽、低調的外形,非常適合用于視覺 AI 部署(包括在邊緣位置)。
您可以觀看Metropolis Developer Meetup(https://info.nvidia.com/metropolis-meetup-june2023.html),了解有關 ViT、NVIDIA TAO Toolkit 5.0 以及 L4 GPU 的更多信息。
點擊“閱讀原文”,或掃描下方海報二維碼,在 8 月 8日聆聽NVIDIA 創始人兼 CEO 黃仁勛在 SIGGRAPH 現場發表的 NVIDIA 主題演講,了解 NVIDIA 的新技術,包括屢獲殊榮的研究,OpenUSD 開發,以及最新的 AI 內容創作解決方案。
原文標題:使用 Vision Transformer 和 NVIDIA TAO,提高視覺 AI 應用的準確性和魯棒性
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3821瀏覽量
91508
原文標題:使用 Vision Transformer 和 NVIDIA TAO,提高視覺 AI 應用的準確性和魯棒性
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
自動駕駛中常提的魯棒性是個啥?
如何提高OTDR測試的準確性
如何提高電位測量準確性
如何提升ASR模型的準確性
深度學習模型的魯棒性優化
魯棒性在機器學習中的重要性
如何提高系統的魯棒性
如何評估 ChatGPT 輸出內容的準確性
如何保證測長機測量的準確性?

傾斜光柵的魯棒性優化
影響電源紋波測試準確性的因素
電流探頭測試小技巧:提高準確性和安全性






 工商網監
工商網監
評論