") 對于極暗場景RAW圖像去噪,你是否還在被標(biāo)定折磨?
對于極暗場景RAW圖像去噪,你是否還在被標(biāo)定折磨?
本文為 [ICCV 2023]LightingEveryDarkness in Two Pairs: A Calibration-Free Pipeline for RAW Denosing 的簡要介紹

Github:https://github.com/Srameo/LED
Homepage:https://srameo.github.io/projects/led-iccv23/
Paper:http://arxiv.org/abs/2308.03448
TL; DR;
基于標(biāo)定的方法在極低光照環(huán)境下的 RAW 圖像去噪中占主導(dǎo)地位。然而,這些方法存在幾個(gè)主要缺陷:
噪聲參數(shù)標(biāo)定過程費(fèi)力且耗時(shí),
不同相機(jī)的降噪網(wǎng)絡(luò)難以相互轉(zhuǎn)換,
合成噪聲和真實(shí)噪聲之間的差異被高倍數(shù)字增益放大。
為了克服上述缺點(diǎn),我們提出了一種無需標(biāo)定的pipeline來照亮LighingEveryDarkness(LED),無論數(shù)字增益或相機(jī)傳感器的種類。我們的方法無需標(biāo)定噪聲參數(shù)和重復(fù)訓(xùn)練,只需少量配對數(shù)據(jù)和快速微調(diào)即可適應(yīng)目標(biāo)相機(jī)。此外,簡單的結(jié)構(gòu)變化可以縮小合成噪聲和真實(shí)噪聲之間的domain gap,而無需任何額外的計(jì)算成本。在SID[1]上僅需總共6 對配對數(shù)據(jù)、和 0.5% 的迭代次數(shù)以及0.2%的訓(xùn)練時(shí)間,LED便表現(xiàn)出SOTA的性能!
Introduction
使用真實(shí)配對數(shù)據(jù)進(jìn)行訓(xùn)練
SID[1]首先提出一套完整的 benchmark 以及 dataset 進(jìn)行RAW圖像低光增強(qiáng)或去噪。為什么要從RAW圖像出發(fā)進(jìn)行去噪和低光增強(qiáng)呢?因?yàn)槠渚哂懈叩纳舷蓿唧w可以參考 SID[1]的文章。
那么它具體的做法是什么呢?很簡單,如圖1左,使用相機(jī)拍攝大量配對的真實(shí)數(shù)據(jù),之后直接堆到網(wǎng)絡(luò)里進(jìn)行訓(xùn)練。
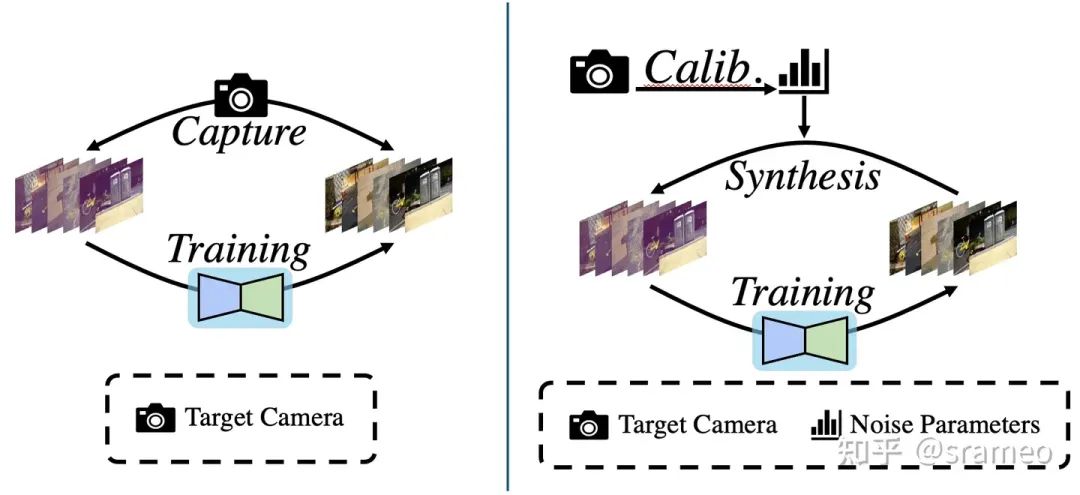
圖1: 基于真實(shí)配對數(shù)據(jù)進(jìn)行訓(xùn)練流程(左)以及基于噪聲模型標(biāo)定進(jìn)行訓(xùn)練流程(右)
但是有一個(gè)很重要的問題,不同的傳感器,噪聲模型以及參數(shù)都是不同的。那么按照這種流程,難道我們對每種相機(jī)都需要重新收集大量數(shù)據(jù)并重新訓(xùn)練?是不是有點(diǎn)太繁瑣了?
基于噪聲模型標(biāo)定的算法流程
對于上述提到的問題,近期的paper[2][3][4][5]統(tǒng)一告訴我們:是的。現(xiàn)在,大家主要卷的,包括在各種工業(yè)場景(手機(jī)、邊緣設(shè)備上),去噪任務(wù)都已經(jīng)開始采用基于標(biāo)定的手段。
那么什么是標(biāo)定呢?具體的標(biāo)定流程大家可以參考
@Wang Hawk
的文章Wang Hawk:60. 數(shù)碼相機(jī)成像時(shí)的噪聲模型與標(biāo)定。當(dāng)然,基于深度學(xué)習(xí)+噪聲模型標(biāo)定的算法大概就分為如下三步(可以參考圖1右):
1. 設(shè)計(jì)噪聲模型,收集標(biāo)定用數(shù)據(jù),
2.使用 1. 中的標(biāo)定的數(shù)據(jù)對對噪聲模型進(jìn)行參數(shù)估計(jì)埋個(gè)伏筆,增益(或者說iso)和噪聲方差有著log域的線性關(guān)系
3. 使用 2. 中標(biāo)定好的噪聲模型合成配對數(shù)據(jù)并訓(xùn)練神經(jīng)網(wǎng)絡(luò)。
這樣,對于不同的相機(jī),我們只需使用不同的標(biāo)定數(shù)據(jù)(收集難度相對于大規(guī)模配對數(shù)據(jù)集來講少了很多),便可以訓(xùn)練出對應(yīng)該相機(jī)的專用去噪網(wǎng)絡(luò)。
但是,標(biāo)定算法真的好嗎?
標(biāo)定缺陷以及 LED
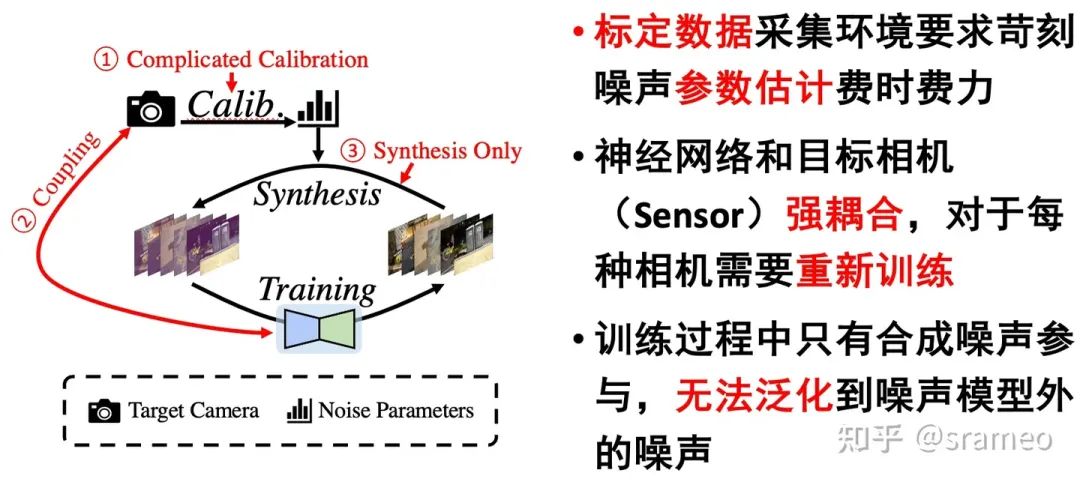
圖2: 基于噪聲模型標(biāo)定的算法缺陷
那么我們喜歡什么呢?
簡化標(biāo)定[6][7],甚至無需標(biāo)定,
快速部署到新相機(jī)上,
強(qiáng)大的“泛化”能力:很好的泛化到真實(shí)場景,克服合成噪聲到真實(shí)噪聲之間的domain gap。
So here comes LED!
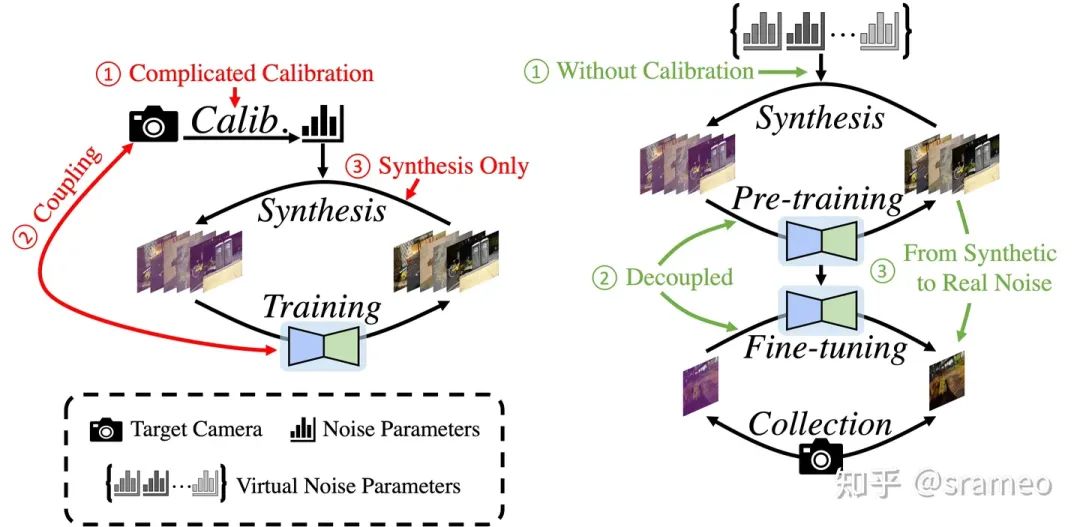
圖3: 標(biāo)定算法與LED的對比
無需標(biāo)定:相比于標(biāo)定算法需要使用真實(shí)相機(jī)的噪聲參數(shù),我們采用虛擬相機(jī)噪聲參數(shù)進(jìn)行數(shù)據(jù)合成,
快速部署:采用 Pretrain-Finetune 的訓(xùn)練策略,對于新相機(jī)僅需少量數(shù)據(jù)對網(wǎng)絡(luò)部分參數(shù)進(jìn)行微調(diào),
克服 Domain Gap:通過少量真實(shí)數(shù)據(jù)進(jìn)行 finetune 以獲得去除真實(shí)噪聲的能力。
LED 能做到什么?
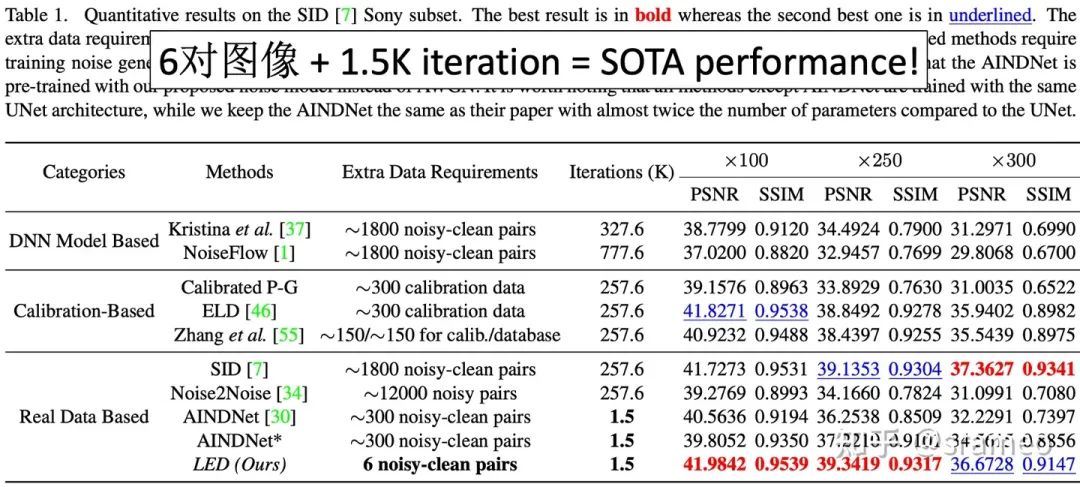
圖4: 6對數(shù)據(jù) + 1.5K iteration = SOTA Performance!
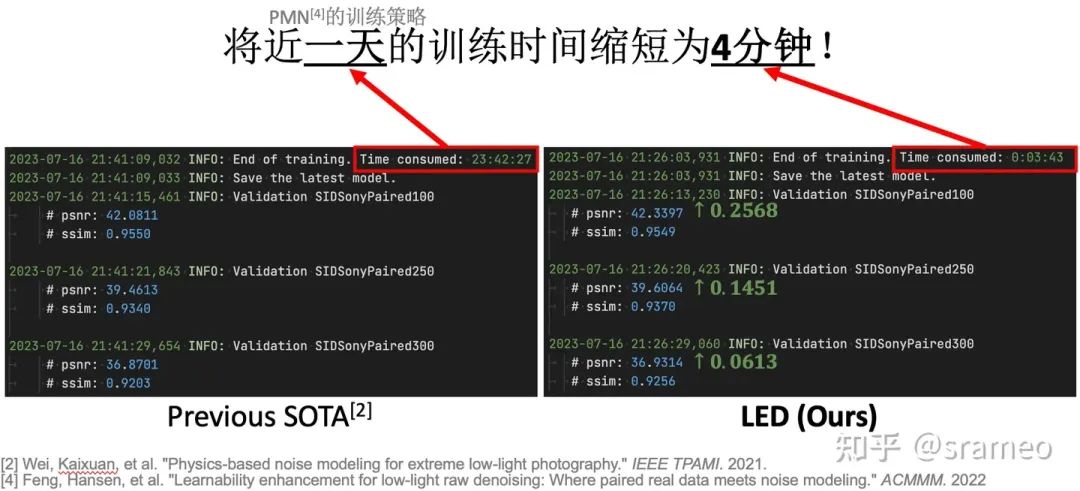
圖5: 更直觀的log對比
Method
LED大概分為一下幾步:
預(yù)定義噪聲模型Φ,從參數(shù)空間中隨機(jī)采集 N 組 “虛擬相機(jī)” 噪聲參數(shù),
使用 1. 中的 N 組 “虛擬相機(jī)” 噪聲參數(shù)合成并 Pretrain 神經(jīng)網(wǎng)絡(luò),
使用目標(biāo)相機(jī)收集少量配對數(shù)據(jù),
、
使用 3. 中的少量數(shù)據(jù) Finetune 2. 中預(yù)訓(xùn)練的神經(jīng)網(wǎng)絡(luò)。
當(dāng)然,一個(gè)普通的 UNet 并不能很好的完成我們前文說的3個(gè)“需要”。因此結(jié)構(gòu)上也需要做少量更改:
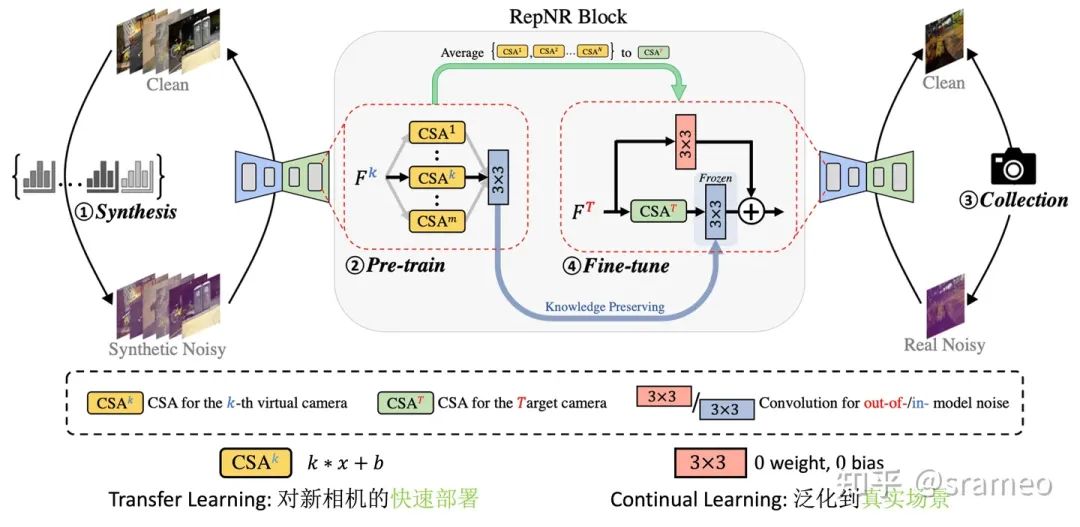
圖6: UNet 結(jié)構(gòu)中的 RepNR Block
首先,我們把 UNet 里所有的 Conv3 配上一組CSA (Camera Specific Alignment),CSA 指一個(gè)簡單的 channel-wise weight 和一組 channel-wise 的 bias,用于 feature space 上的對齊。
Pretrain 時(shí),對于第 k個(gè)相機(jī)合成的數(shù)據(jù),我們只訓(xùn)練第 k 個(gè)CSA以及 Conv3。
Finetune 時(shí),先將 Pretrain 時(shí)的CSA組進(jìn)行 Average 得到初始化的CSA^T (for target camera),然后先將其訓(xùn)練收斂;之后添加一個(gè)額外分枝,繼續(xù)微調(diào),額外分枝用于學(xué)習(xí)合成噪聲和真實(shí)噪聲之間的 Domain Gap。
當(dāng)然,由于CSA以及卷積都是線性操作,所以我們在部署時(shí)候可以將他們?nèi)慷贾貐?shù)化到一起,因此最終不會引入任何額外計(jì)算量!
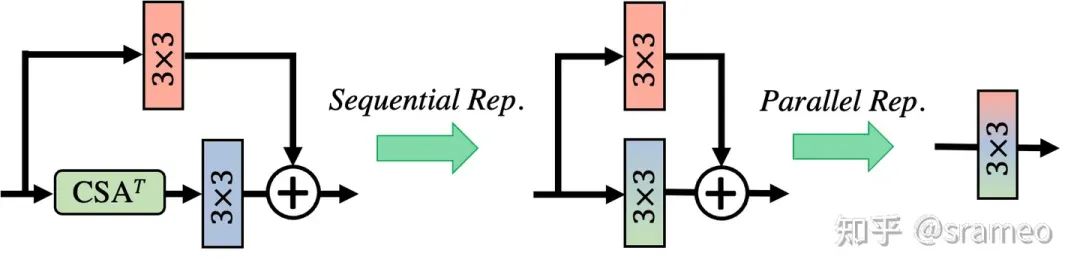
圖7: 重參數(shù)化
Visual Result
下圖表現(xiàn)出了 LED 對于 Out-of-model 噪聲的去除能力(克服合成噪聲與真實(shí)噪聲之間 Domain Gap 的能力)。
Out-Of-Model Noise 指不被預(yù)定義在噪聲模型中的噪聲,如圖8中由鏡頭所引起的噪聲或圖9中由 Dark Shading 所引起的噪聲

圖8: Out-Of-Model Pattern 去除能力(鏡頭引發(fā)的 Artifact)

圖9: Out-of-model 噪聲去除能力(Dark Shading)
Discussion on “為什么需要兩對數(shù)據(jù)?”
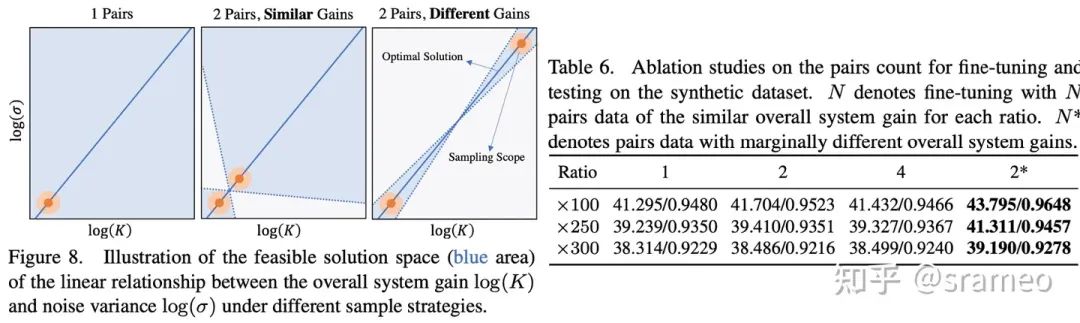
圖10
不知道大家記不記得之前埋的一個(gè)伏筆:增益和噪聲方差之間保持對數(shù)線性關(guān)系。
線性關(guān)系意味著什么呢?兩點(diǎn)確定一條直線!也就是說兩對數(shù)據(jù)(每對數(shù)據(jù)都能提供在某增益下噪聲方差的值)就可以確定這個(gè)線性關(guān)系。但是,由于存在誤差[2],所以我們需要增益差距盡可能大的兩對數(shù)據(jù)以完成網(wǎng)絡(luò)對線性關(guān)系的學(xué)習(xí)。
從圖10右也能看出,當(dāng)我們無論使用增益相同的 1、2、4 對數(shù)據(jù),性能并不會有太大的差距。而使用增益差距很大的兩對數(shù)據(jù)(差異很大指 ISO<500 與 ISO>5000)時(shí),性能有巨大提升。這也能驗(yàn)證我們的假設(shè),即兩對數(shù)據(jù)便可以學(xué)習(xí)到線性關(guān)系。
后記:關(guān)于開源
我們的訓(xùn)練測試包括對ELD的復(fù)現(xiàn)代碼都已經(jīng)開源到 Github 上了,如果大家感興趣的話可以幫我們點(diǎn)個(gè) star。
當(dāng)然不僅是代碼,我們還一口氣開源了 配對數(shù)據(jù)、ELD、PG(泊松-高斯)噪聲模型在多款相機(jī)上、不同訓(xùn)練策略、不同階段(指 LED 的 Pre-train 和 Fine-tune 階段)的一共15個(gè)模型,詳見 pretrained-model.md。
此外,由于 RepNR block 目前只在 UNet 上進(jìn)行了測試,不過我們相信其在別的模型上的潛力。于是,我們提供了快速將 RepNR block 用于別的模型上的代碼,僅需一行代碼,便可在你自己的網(wǎng)絡(luò)結(jié)構(gòu)上使用 RepNR block,配合我們的 Noisy-Clean 生成器,可以快速驗(yàn)證 RepNR block 在其他結(jié)構(gòu)上的有效性。相關(guān)講解以及代碼可以在 develop.md 中找到。
-
噪聲
+關(guān)注
關(guān)注
13文章
1123瀏覽量
47457 -
圖像
+關(guān)注
關(guān)注
2文章
1088瀏覽量
40515 -
GitHub
+關(guān)注
關(guān)注
3文章
473瀏覽量
16504
原文標(biāo)題:ICCV 2023 | 對于極暗場景RAW圖像去噪,你是否還在被標(biāo)定折磨?來試試LED!少量數(shù)據(jù)、快速部署!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于稀疏分解的圖像去噪
基于小波變換氣動光學(xué)效應(yīng)模糊圖像去噪
一種自適應(yīng)多尺度積閾值的圖像去噪算法
基于提升小波的圖像去噪算法的FPGA設(shè)計(jì)
基于一種新閾值函數(shù)的小波醫(yī)學(xué)圖像去噪
基于邊緣檢測的NSCT自適應(yīng)閾值圖像去噪
基于提升小波的圖像去噪算法的FPGA設(shè)計(jì)
基于數(shù)據(jù)驅(qū)動緊框架圖像去噪模型

基于中值濾波和小波變換的火電廠爐膛火焰圖像去噪方法
基于多通道聯(lián)合估計(jì)的非局部均值彩色圖像去噪方法
如何解決圖像去噪在去除噪聲的同時(shí)容易丟失細(xì)節(jié)信息的問題






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論