 如何在CPU上優化ChatGLM-6B?一行代碼就行 | 最“in”大模型
如何在CPU上優化ChatGLM-6B?一行代碼就行 | 最“in”大模型
大語言模型的應用
與微調優化必要性
ChatGPT 的橫空出世開啟了大語言模型 (LLM) 的普及元年,BERT、GPT-4、ChatGLM 等模型的非凡能力則展現出類似通用人工智能 (AI) 的巨大潛力,也因此得到了多行業、多領域的廣泛關注。
為加速這些大模型與特定領域的深度融合,以及更好地適應特定任務,基于任務特性對這些模型進行定制化微調至關重要。
然而,它們龐大的參數使得用傳統方式對大模型進行調優面臨諸多挑戰,不僅要求相關人員熟練掌握微調技巧,還需要付出巨大的訓練成本。
近年來,出現了參數高效微調 (Parameter-Efficient Fine-Tuning, PEFT)和提示微調 (Prompt-tuning)技術。這些技術因其成本更低、應用方式更簡單便捷,正在逐漸取代大模型傳統調優方法。
本文結合目前在中文應用場景中具有出色表現的開源預訓練大模型 ChatGLM-6B,介紹如何通過對其開源 Prompt-tuning 代碼進行極少量的修改,并結合第四代英特爾至強可擴展處理器[1]的全新內置 AI加速引擎——英特爾高級矩陣擴展 (IntelAdvancedMatrix Extension,簡稱英特爾AMX)及配套的軟件工具,來實現高效、低成本的大模型微調。
基于英特爾 架構硬件的
微調優化方案
本文通過以下三個方面實現了基于第四代英特爾 至強 可擴展處理器的 ChatGLM 高效微調優化:
1.借助英特爾 AMX,大幅提升模型微調計算速度
AMX 是內置于第四代英特爾 至強 可擴展處理器中的矩陣乘法加速器,能夠更快速地處理 BFloat16 (BF16) 或 INT8 數據類型的矩陣乘加運算,從而顯著提升模型訓練和推理的性能。
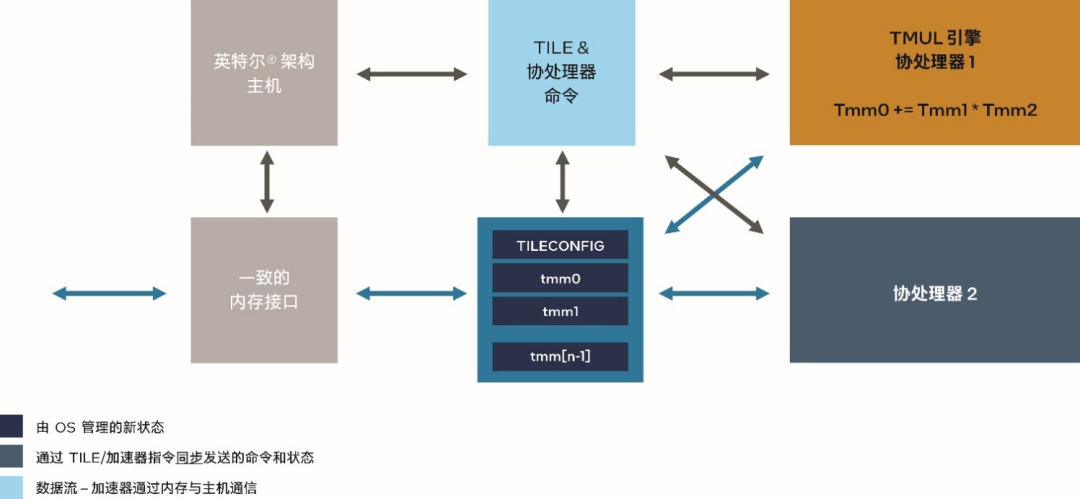
圖 1. 英特爾 AMX 技術架構
目前,現行的 PyTorch 框架中,已經可以通過具備 BF16 自動混合精度功能自動實現對 AMX 加速器的利用。
就ChatGLM-6B而言,其開源微調代碼的 autocast_smart_context_manager() 函數,也已具備對 CPU 自動混合精度的支持。
因此,只需在啟動微調時加入 CPU 自動混合精度的使能參數即可直接利用英特爾 AMX 帶來的優勢。
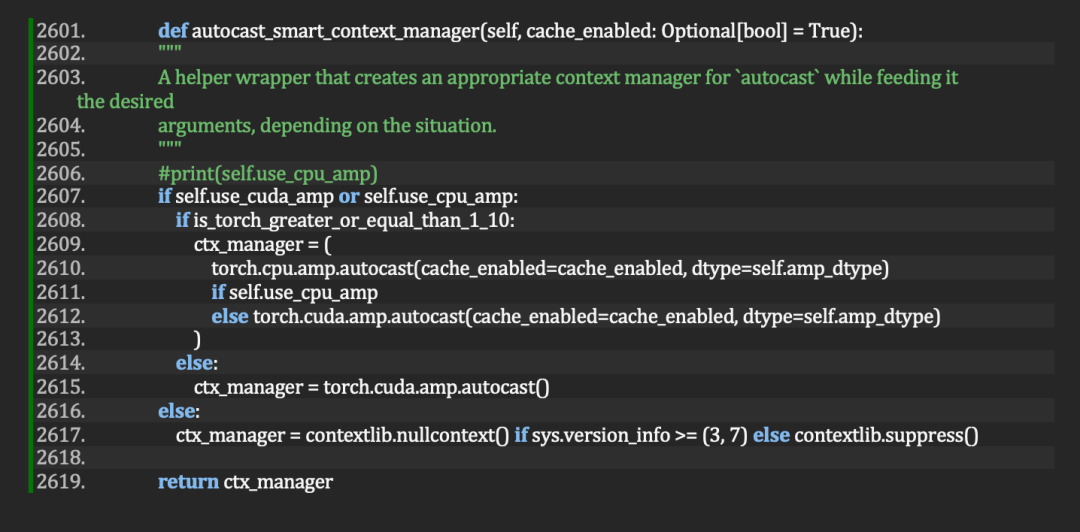
圖 2. 通過trainer.py 中的 autocast_smart_context_manager() 函數,在 ChatGLM-6B 開源 prompt-tuning 目錄下實現對 CPU 和 GPU 的自動混合精度支持
具體方法是在啟動微調的 train.sh 腳本時做如下修改:

2.結合英特爾 MPI 庫充分利用處理器架構特點和多核配置,發揮 CPU 的整體效率
第四代英特爾 至強 可擴展處理器最多可擁有 60 個內核。這些內核通過 4 個集群 (cluster) 的方式進行內部組織。
理論上,當多個處理器內核并行處理一個計算任務并需要共享或交換數據時,同一個集群內的內核之間的通信時延較低。
因此,在使用 PyTorch 框架進行模型微調時,我們可以將同一個集群上的內核資源分配給同一個 PyTorch 實例,從而為單個實例提供更理想的計算效率。
此外,通過利用 PyTorch 的分布式數據并行 (Distributed Data Parallel,DDP) 功能,還可將兩個 CPU 上的 8 個集群的內核資源匯集在一起,充分發揮整體效率。
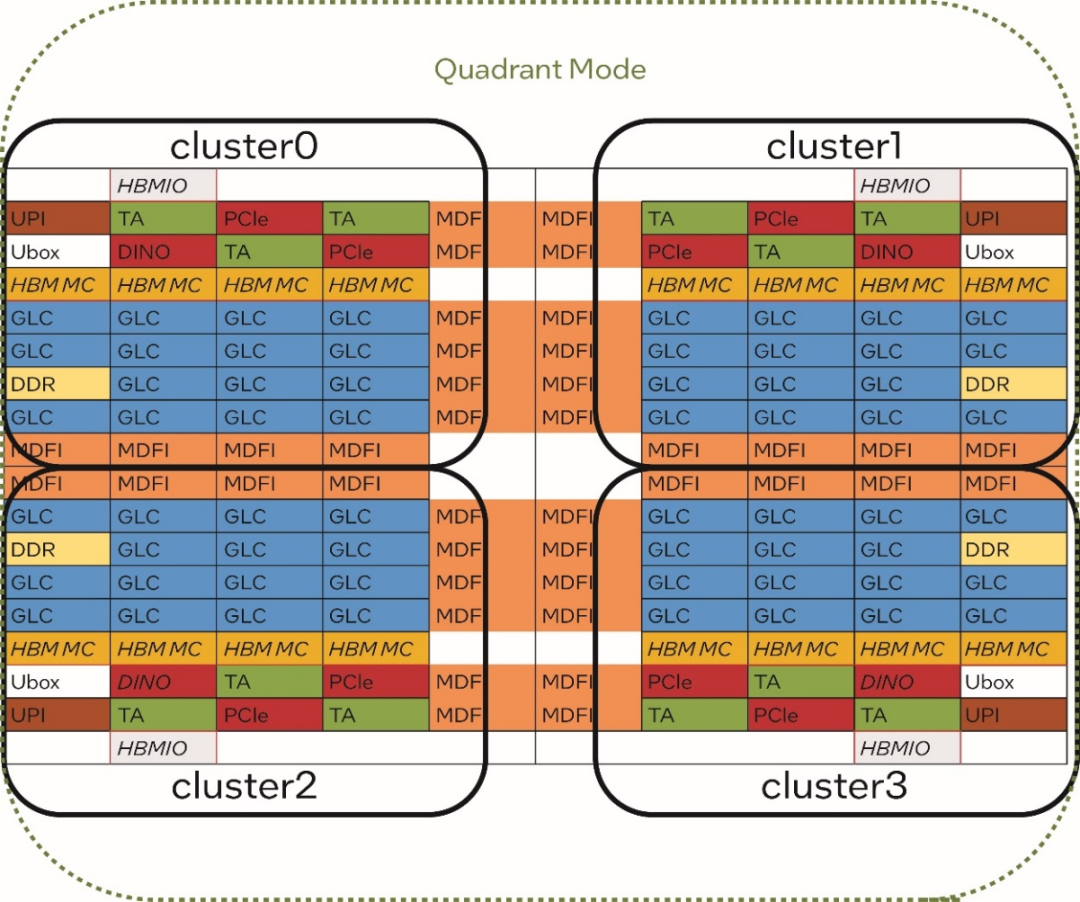
圖 3. 第四代英特爾 至強 可擴展處理器的內部集群 (cluster) 架構
為實現從應用程序代碼到數據通信的整體簡化,PyTorch 框架支持多種分布式數據并行后端 (backend),其中 MPI 后端方式能夠很好地滿足我們的優化需求。
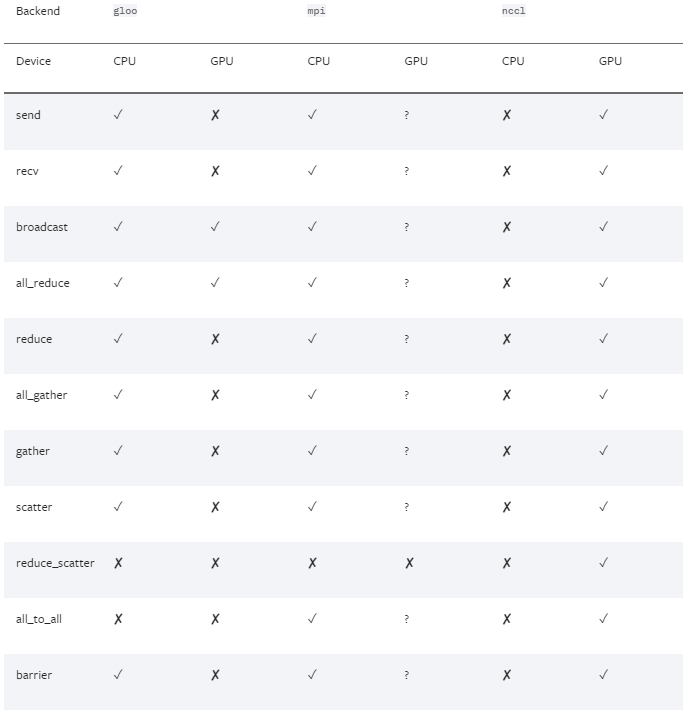
圖 4. PyTorch 支持的多種分布式數據并行的后端(來源:PyTorch 官網[2])
但是,通過 pip 或 conda 來安裝的預編譯PyTorch 二進制包中并未將 MPI 的后端作為缺省功能編譯。因此,我們需要安裝 MPI 協議工具庫并通過手工編譯來獲得對 MPI 后端的支持。
英特爾MPI庫[3]是一個實現 MPICH 規范的多結構消息傳遞庫,使用該庫可創建、維護和測試能夠在英特爾 處理器上實現更優性能的先進和復雜的應用。它采用 OFI 來處理所有通信,能夠提供更高的吞吐量、更低的時延和更簡單的程序設計。
以下是基于英特爾MPI庫的 PyTorch 編譯步驟:
下載英特爾 MPI庫并安裝

安裝 PyTorch 編譯依賴包

下載 PyTorch 源碼并完成編譯、安裝

在獲得了支持 MPI 后端的 PyTorch 后,只需按如下方法在 ChatGLM Prompt-tuning 目錄下的 main.py 修改一行代碼:
將dist.init_process_group(backend='gloo', world_size=1,rank=0) 改為:
dist.init_process_group(backend='mpi')
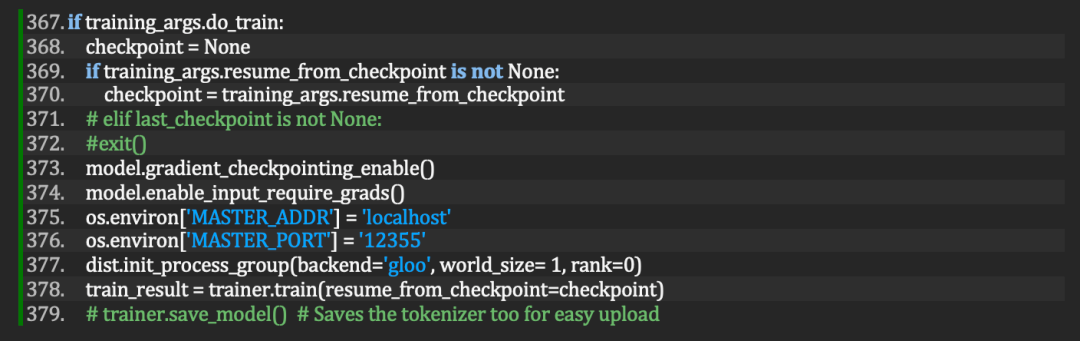
圖 5. 修改前的main.py

圖 6. 修改后的 main.py
3.利用至強 CPU Max 系列集成的 HBM 滿足大模型微調所需的大內存帶寬
基于 Transformer 的大模型,由于參數、訓練數據和模型規模的復雜程度較高,因此內存復雜度通常是 O(n2)。
這意味著這些大模型需要足夠大的內存帶寬支持才能獲得更好的運行性能。
英特爾 至強 CPU Max 系列[4],配備 64 GB 的 HBM2e 高帶寬內存,為在 CPU 上高效運行大模型提供了高達~1TB/s的內存帶寬支持[5]。
該 CPU 集成的 HBM,能夠在 3 種模式下靈活配置:
HBM-Only 模式——支持內存容量需求不超過 64 GB 的工作負載,具備每核 1 至 2 GB 的內存擴展能力,無需更改代碼和另購 DDR,即可啟動系統。 HBM Flat 模式——可為需要大內存容量的應用提供靈活性,通過 HBM 和 DRAM 提供一個平面內存區域 (flat memory region),適用于每核內存需求 >2 GB 的工作負載。可能需要更改代碼。 HBM 高速緩存模式——為內存容量 >64 GB或每核內存需求 >2GB 的工作負載提供更優性能。無需更改代碼,HBM 將用作 DDR 的高速緩存。
針對 ChatGLM-6B 微調,試驗結果顯示:與其他兩種模式相比, HBM 高速緩存模式在性能和使用方便性方面均更勝一籌。
在英特爾 至強 CPU Max 系列產品上,結合之前的兩項優化,我們可以通過以下命令行啟動 ChatGLM-6B 微調:

圖 7. 在擁有 32 個物理核的英特爾 至強 CPU Max 9462 雙路服務器上啟動微調
優化結果
通過以上簡單軟、硬件綜合優化,無須采用昂貴的 GPU 硬件,即可實現對 ChatGLM-6B 模型的高性能微調。
注:以上代碼修改需要配合 python 工具包 accelerate 0.18.0 和 transformers 4.28.0。
作者簡介:
夏磊,英特爾(中國)有限公司人工智能首席工程師,擁有近 20 年的人工智能從業經驗,在軟件算法、自動控制和工程管理等領域積累了豐富經驗。
-
英特爾
+關注
關注
61文章
9964瀏覽量
171787 -
cpu
+關注
關注
68文章
10863瀏覽量
211786
原文標題:如何在CPU上優化ChatGLM-6B?一行代碼就行 | 最“in”大模型
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
軟通動力領導一行訪問福州大學
RIMAC與IMD一行來訪聲揚科技,共話AI語音賦能產業升級

科大訊飛引領大模型應用新浪潮
chatglm2-6b在P40上做LORA微調
中國汽研董事長周玉林一行蒞臨國芯科技調研交流
在VSCODE終端make時遇到錯誤要一行一行看然后定位,可以直接跳轉點擊或者VSCODE定位錯誤嗎?
【AIBOX】裝在小盒子的AI足夠強嗎?

在uCGUI的回調函數里加了行代碼,stm32無法啟動怎么解決?
云上貴州大數據產業發展有限公司總經理張雷一行蒞臨拓維信息考察交流

淺談代碼優化與過度設計
三步完成在英特爾獨立顯卡上量化和部署ChatGLM3-6B模型
ChatGLM3-6B在CPU上的INT4量化和部署





 工商網監
工商網監
評論