 SwinTransformer模型優化
SwinTransformer模型優化
1.SwinTransformer概述#
自從Transformer在NLP任務上取得突破性的進展之后,業內一直嘗試著把Transformer用于CV領域。之前的若干嘗試都是將Transformer用在了圖像分類領域,但這些方法都面臨兩個非常嚴峻的挑戰,一是多尺度問題,二是計算復雜度的問題。
基于這兩個挑戰,swint的作者提出了一種層級式提取的Transformer,并通過移動窗口的方式來學習特征。在窗口內計算自注意力可以帶來更高的效率;同時通過移動的操作,讓相鄰的窗口之間有了交互,變相達到了一種全局建模的能力,進而解決了上面兩個問題。
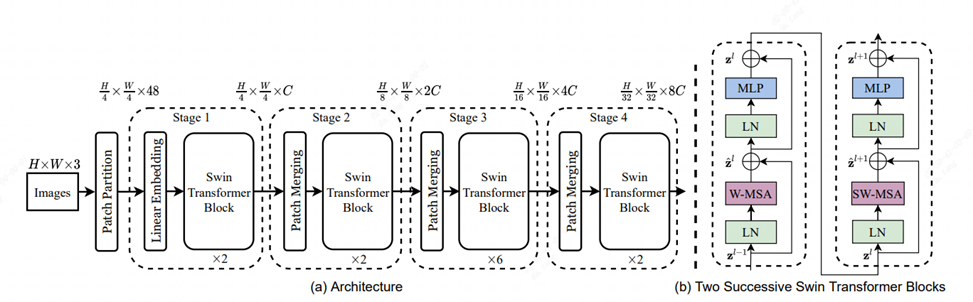
Swin Transformer將transformer結構與cnn的思想相結合,提出了一個可以廣泛應用到各個計算機視覺領域的backbone,在檢測、分類和分割等任務的數據集上都呈現出很好的效果,可以應用于很多對精度有較高要求的場景。Swin Transformer之所以能有這么大的影響力主要是因為在 ViT 之后,它通過在一系列視覺任務上的強大表現 ,進一步證明了Transformer是可以在視覺領域取得廣泛應用的。
下表中展示了目前swin-t模型在1684X上的性能情況,本文主要針對FP16和INT8模型進行優化部署。
| prec | time(ms) |
|---|---|
| FP32 | 41.890 |
| FP16 | 7.411 |
| INT8 | 5.505 |
2.性能瓶頸分析#
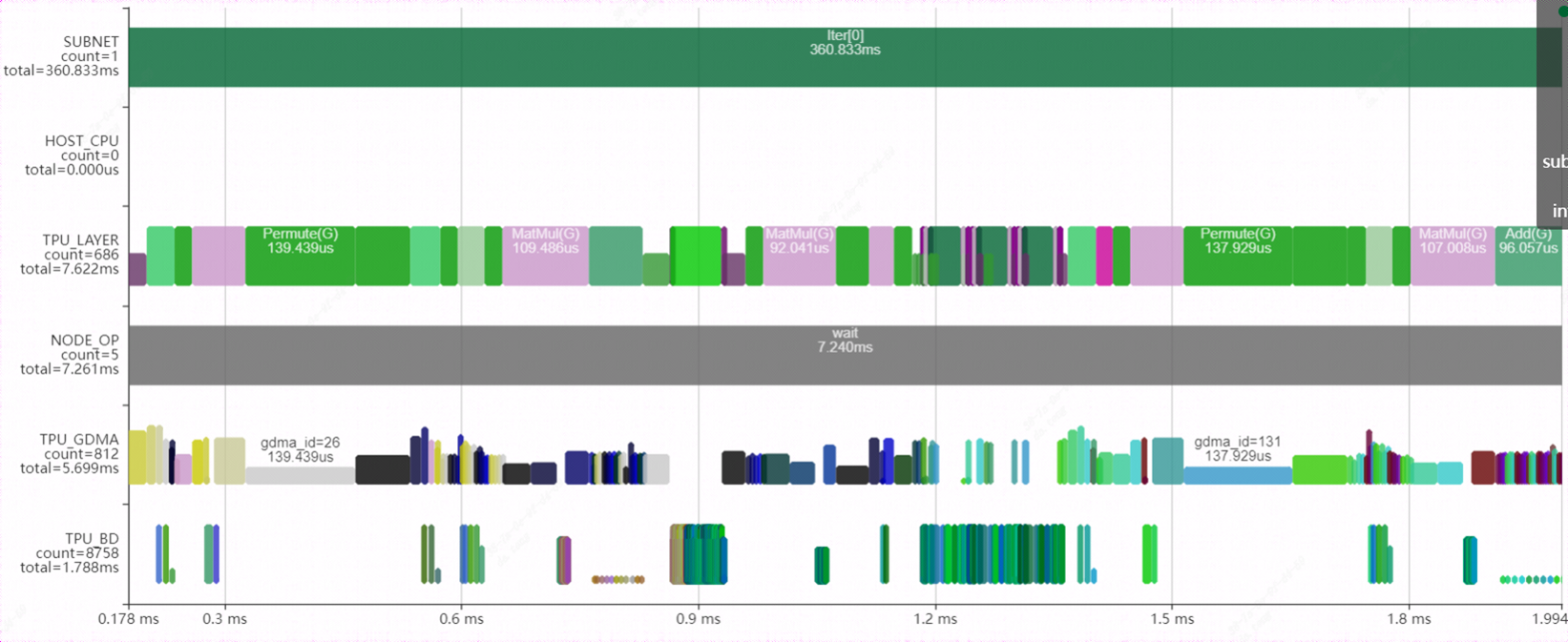
通過bmprofile工具可視化FP16模型在1684X上的運行狀態,這里截取了模型中的一個block。從圖中可以看出大量的permute(transpose)層穿插其中,一方面帶來較大的數據搬運開銷,另一方面使得網絡無法layergroup,并行效果較差。
3.模型優化#
3.1.transpose消除#
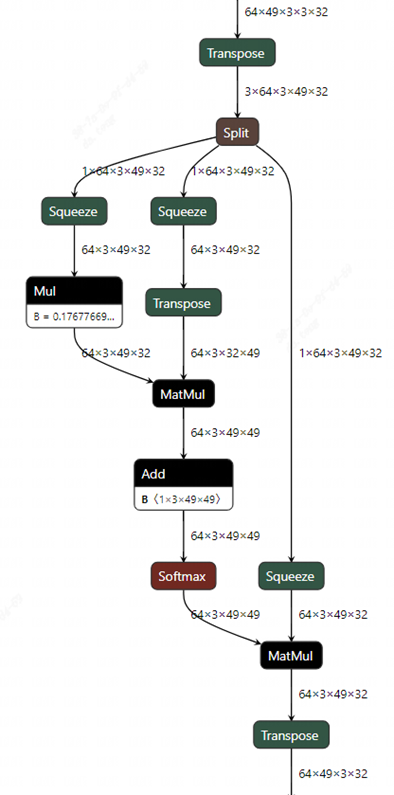
觀察圖中的attention結構,共有3個transpose層。其中第一個transpose層可以拆解為2個transpose,一是把QKV所在的維度(3)移到了最前面,二是將head所在維度(3)與patch所在維度(49)交換了順序。由于后面緊跟著split操作是為了將QKV拆分成三個分支,那么此處完全可以不做第一個transpose,而讓其直接在原維度上進行split。這樣再把第二個transpose的執行改變順序,讓他分別向下移動到三個分支上。這樣處理的原因是:在tpu-mlir中是支持transpose與相鄰的matmul算子融合的,因此當transpose下移到matmul算子上一層就可以與matmul融合。
細心的讀者可能會發現一個問題,QK相乘的matmul其右輸入已經有一個transpose了,再疊加另一個transpose在一起還能融合嗎?又與哪個transpose融合呢?為了解釋這個問題,我們可以從下面這張圖來分析。
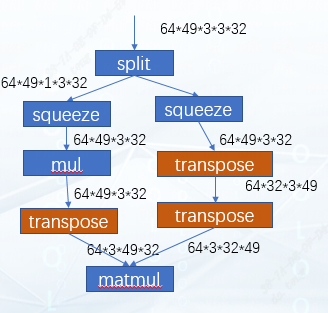
這是我們預期圖優化后達到的效果,可以看到這里matmul是將49x32和32x49這兩個矩陣做乘法,64和3可以看作batch。剛好我們的tpu-mlir中是支持hdim_is_batch這種優化的。因此對于這種情況,優化后左右兩個transpose都被消除掉,在matmul的輸出位置會再新增一個transpose。之后這個matmul再與右面剩下的transpose進行Rtrans融合就可以了。效果如下圖所示:
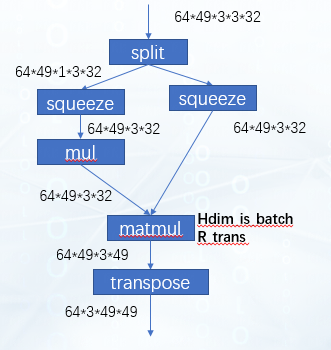
這個輸出多出來的transpose可以繼續被向下移動至下一個matmul之前,此時網絡結構如圖:
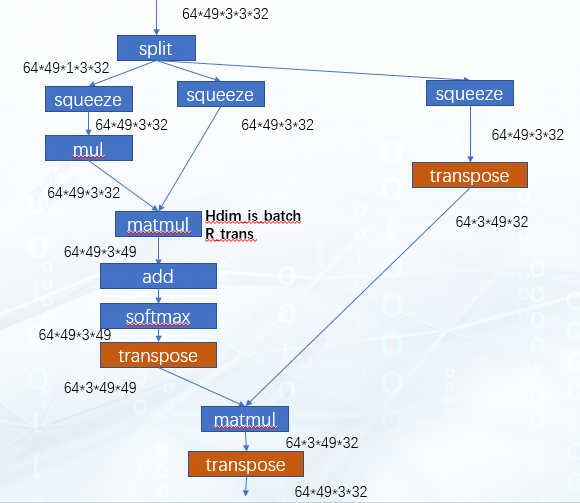
對于第二個matmul,再次應用hdim_is_batch的優化,消除左右輸入的transpose層,之后在輸出額外加入的transpose就可以剛好和網絡最后的transpose層抵消,至此,所有的transpose都被消除了。
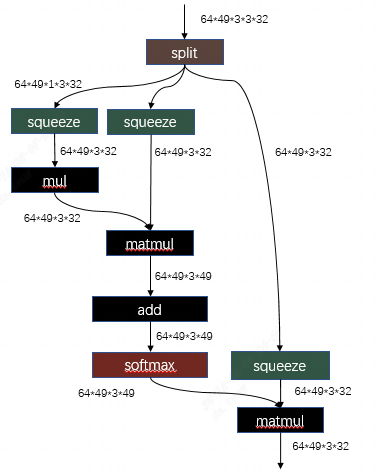
相關代碼:tpu-mlir/lib/Dialect/Top/Canonicalize/MatMul.cpp
MatmulWithPermuteAndSplit這個pattern就是用于識別swint中的attention結構,并將transpose+split+squeeze的結構進行調整,其目的就是為了讓整塊結構可以成功的利用我們編譯器已有的一系列針對transpose+matmul這個組合的優化。
3.2.更好的layergroup#
TPU 分為 Local Memory 和 Global Memory,一個獨立的計算指令的執行會經過 gdma(global → local),bdc,gdma(local→ global)的過程,在模型的執行過程中,我們希望gdma搬運類的操作越少越好,這樣可以更大程度地利用我們的TPU算力。基于這個想法,在tpu-mlir中設計了LayerGroup的功能,LayerGroup經過計算,可以將多個計算指令劃分到一個 Group ,在一個 Group 內,每個 Op 直接使用上一個 Op 計算后存放在 Local Memory的數據 ,可以減少每兩個Op數據銜接之間的搬出與搬入,從而減少了 io 的時間。因此,layergroup的效果往往也是我們優化一個模型要考慮的因素。
在完成了3.1中的優化工作后,按照運算邏輯,attention應該可以Group到一起,但實際情況并不如此,如圖所示,這里截取了final.mlir的一部分attention結構,這里的各個op都是global layer,說明其中仍存在優化點。
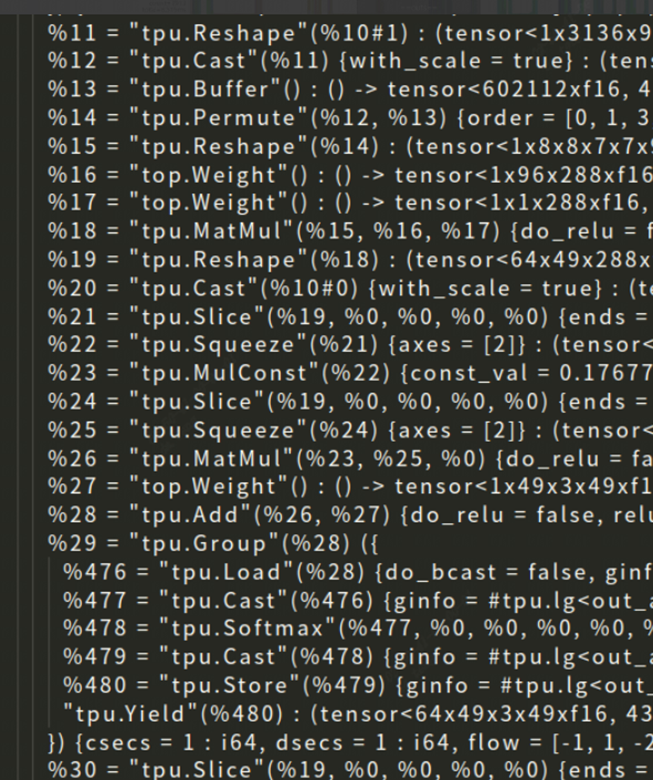
經過在tpu-mlir中的debug,分析其原因有兩點,一是SliceOp的local layer不支持5維的情況,二是SqueezeOp沒有支持localgen。下面針對這兩點進行優化。
3.1.1.SliceOp#
代碼:tpu-mlir/lib/Dialect/Tpu/Interfaces/Common/Slice.cpp
其中 LogicalResult tpu::SliceOp::LocalGenSupport()用于判斷該Op能否支持locallayer,其中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
else if (module::isBM1684XFamily()) {
if((int)getRunMode(getOperation()) == 1) {
return failure();
}
const auto offset = module::getI64Array(getOffset());
const auto steps = module::getI64Array(getSteps());
if (num_dims > 2) {
if (steps->at(1) != 1)
return failure();
}
if (num_dims > 4) {
return failure();
}
}
|
在這段代碼中觀察到,對于1684X芯片,在num_dims>4時直接認為不支持local layer。這里我們對邏輯做進一步完善,在group3d的情況下,5維的shape會按照[n,c,d,h*w]來處理,所以此時如果僅做slice_d,是不會導致數據有跨npu整理的行為的,那么此時他也是允許local layer的。
1 2 3 4 5 6 7 8 9 10 11 12 13 |
if(num_dims == 5){
int64_t in_shape[5];
int64_t out_shape[5];
tpu_mlir::group_type_t group_type = GROUP_3D;
module::getNCDHW(getInput(), in_shape[0],in_shape[1],in_shape[2],in_shape[3], in_shape[4],group_type);
module::getNCDHW(getOutput(), out_shape[0],out_shape[1],out_shape[2],out_shape[3], out_shape[4], group_type);
for(int i=0; i<5; ++i){
if(in_shape[i]!=out_shape[i] (i!=2)){
return failure();
}
}
return success();
}
|
3.1.2.SqueezeOp#
SqueezeOp還沒有支持local layer的codegen,但是1684X的后端中reshape算子是有local實現的,SqueezeOp剛好可以使用。
首先在TpuOps.td文件中給Tpu_SqueezeOp添加localgen的通用接口定義:DeclareOpInterfaceMethods
在這個接口定義的基礎上我們需要實現兩部分,調用后端算子的接口和判斷是否支持local的邏輯。
代碼:tpu-mlir/lib/Dialect/Tpu/Interfaces/BM1684X/Squeeze.cpp
這個文件中實現了SqueezeOp調用芯片后端算子的接口,我們為其新增codegen_local_bm1684x的接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
void tpu::SqueezeOp::codegen_local_bm1684x(int64_t n_step, int64_t c_step,int64_t h_step, int64_t d_step,int64_t w_step,group_type_t group_type,local_sec_info_t sec_info) {
auto op = getOperation();
auto input_spec = BM168x::get_input_spec(op, group_type);
auto output_spec = BM168x::get_output_spec(op,group_type);
if (input_spec->at(0).addr == output_spec->at(0).addr) {
return;
}
auto shape = module::getShape(getOutput());
reshape_spec_t spec = {0};
spec.dims = shape.size();
for (size_t i = 0; i < shape.size(); ++i) {
spec.shape[i] = shape[i];
}
BM168x::call_local_func("backend_api_reshape_local", spec, sizeof(spec), sec_info, input_spec->data(), output_spec->data());
}
|
代碼:lib/Dialect/Tpu/Interfaces/Common/Squeeze.cpp
這個文件中實現了SqueezeOp支持localgen的判斷邏輯。
1 2 3 4 5 6 7 8 9 10 11 |
LogicalResult tpu::SqueezeOp::LocalGenSupport() {
if (module::isCV18xx() || module::isBM1684Family()) {
return failure();
}
auto ishape = module::getShape(getInput());
auto oshape = module::getShape(getOutput());
if (ishape.size() < 2 || oshape.size() < 2 || ishape[0] != oshape[0] || ishape[1] != oshape[1]) {
return failure();
}
return success();
}
|
完成上述優化后讓我們再來編譯模型看一下效果:
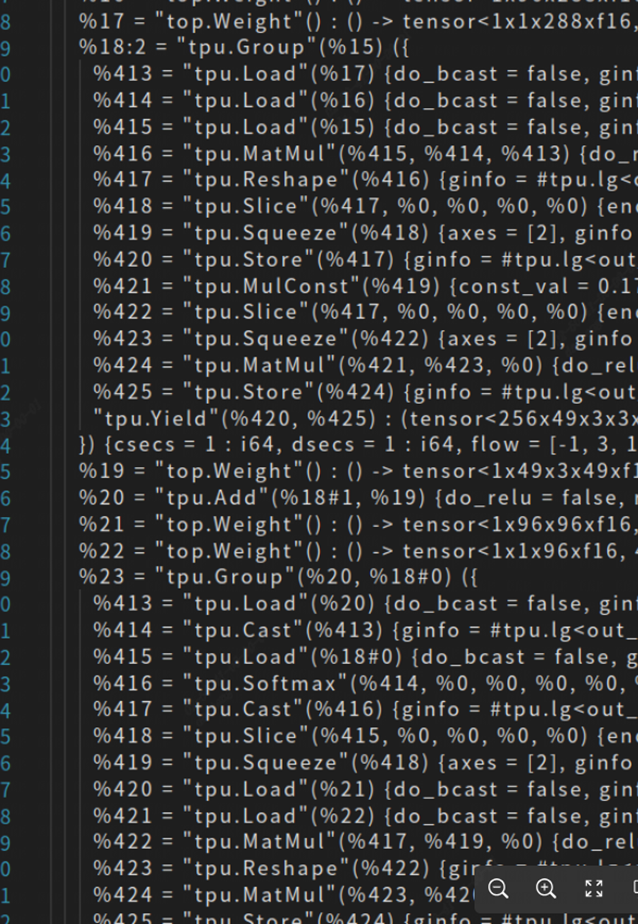
可以看到剛剛幾個global layer已經整理到一個group中了。
3.1.3.weight切分#
從上面group的效果來看,還存在著一個比較特殊的情況,這里AddOp并沒有和其他層group到一起。這里的原因是,add的一個輸入為權重,但是tpu-mlir目前對權重的處理是不進行切分,所以在切分遇到weight時,就認為其不支持group。但是像add這種點對點運算的Op,如果輸入為權重,理論上也是可以進行切分的。
為了支持這個功能,涉及修改的地方較多,感興趣的讀者可以先了解一下tpu-mlir中layer group的過程實現,相關的講解視頻在開源社區:layer group精講
此處概括一下支持weight切分的方式:
1.給top層WeightOp增加 allow_split的參數
2.LocalGenSupport支持add sub mul div max min這類點對點操作
3.做layer group之前給符合要求的op配置allow_split
4.完善layer group切分時涉及到輸入為weight的分支邏輯
完成上述優化后讓我們再來編譯模型看一下效果:
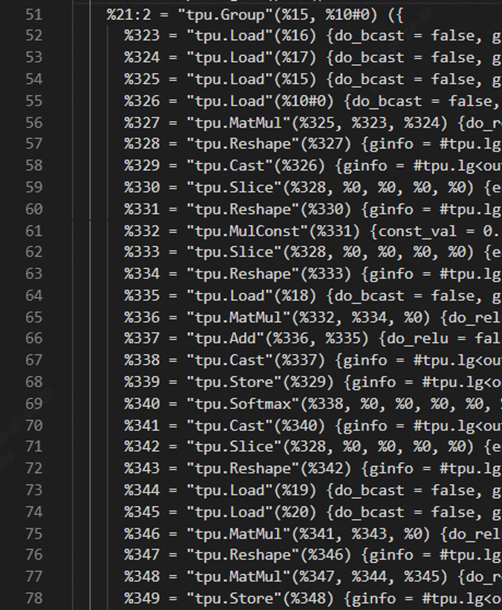
AddOp也成功的合入了group。
4.優化效果#
使用bmprofile工具再次觀察模型的運行情況,與優化前相比,節省了大量GDMA搬運的時間,BDC計算與GDMA搬運數據的并行效果更好了。
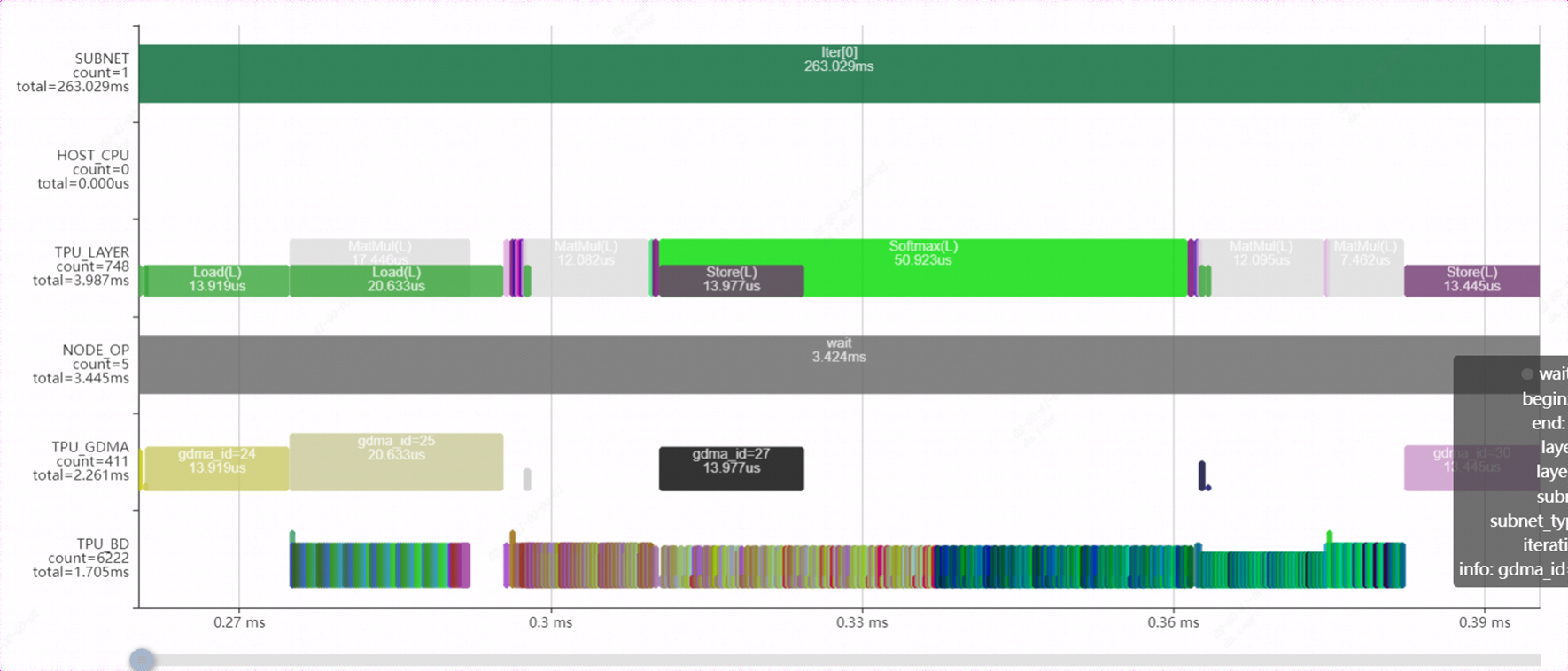
模型的性能變化情況:
| FP16 | INT8 | |
|---|---|---|
| 優化前 | 7.411ms | 5.505ms |
| 優化后 | 3.522ms | 2.228ms |
| 優化效果 | 性能提升110% | 性能提升145% |
FP16模型和INT8模型在1684X上的運行速度都得到了大幅度提升。至此,這一階段的swint優化工作完成。
希望這篇記錄文檔能為其他類似模型的優化工作提供幫助。
審核編輯:湯梓紅
-
計算機
+關注
關注
19文章
7511瀏覽量
88090 -
模型
+關注
關注
1文章
3254瀏覽量
48889 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
46022
發布評論請先 登錄
相關推薦
模型優化器中張量流保存模型運行失敗
Lite Actor:方舟Actor并發模型的輕量級優化
基于移動代理的層次優化挖掘模型
優化模型與LINDO/LINGO優化軟件
基于船舶備件費效分析備件優化模型分析
基于Kriging模型天線優化設計
單步電壓控制優化模型







 工商網監
工商網監
評論