 TPU內存(一)
TPU內存(一)
首先我們來看一下TPU的簡要架構。
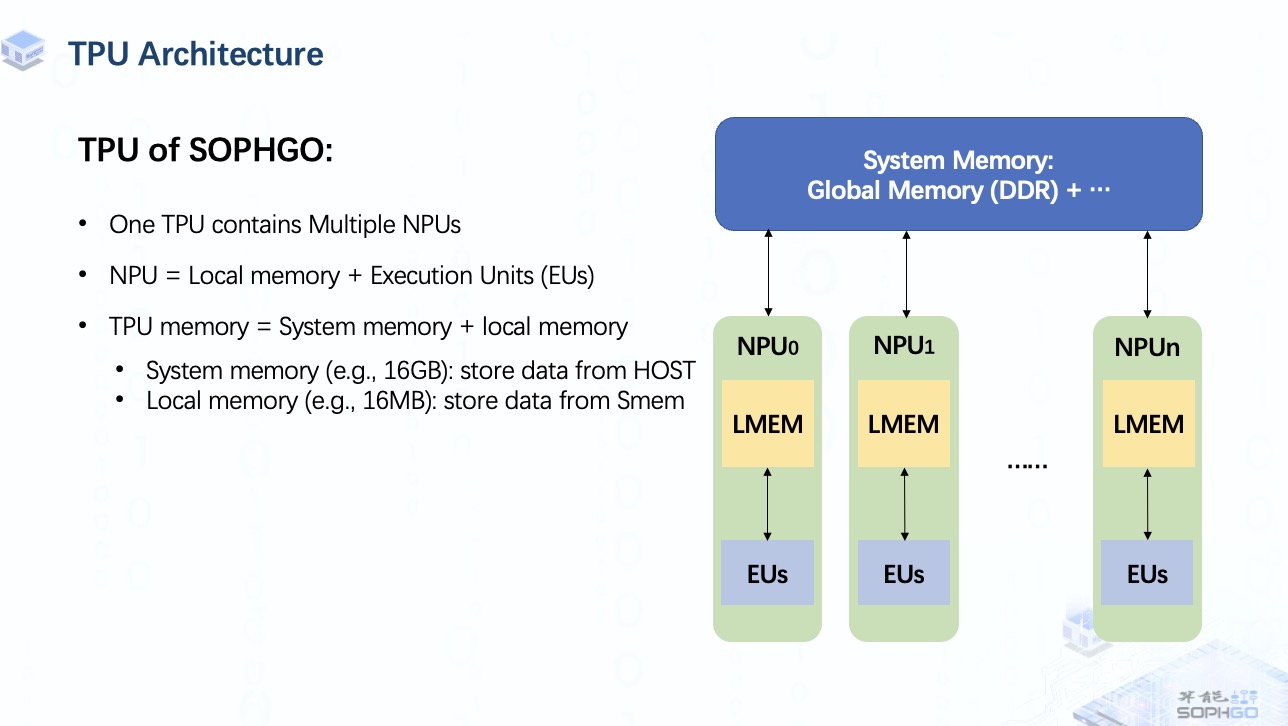
我們可以從ppt中了解到一個TPU中包含多個NPU(Neuron Processing Unit),主要由一個local memory和多個執行單元組成。前者用于存儲要運算的數據,后者是TPU上最小的計算單元。每個NPU一次可以驅動它的所有EU做一個MAC操作。
就整體 TPU 內存而言,它由system memory和local memory組成。 system memory的主要部分是global memory,其實就是一塊DDR。 有時根據 TPU 的特殊設計還會有其他組件,但我們不會在視頻中提及這些部分,所以現在了解global memory就足夠了。 而對于local memory,我們暫時只需要知道是一組Static RAM就可以了。 稍后我會進一步解釋。
通常global memory很大,用于存儲來自host端的整個數據塊。
而local memory雖然有限但在計算速度上更有優勢。
所以有時候對于一個很大的張量,我們需要把它切分成幾個部分,送到local memory中進行計算,然后把結果存回global memory。
為了在 TPU 上執行這些操作,我們就需要用到指令。
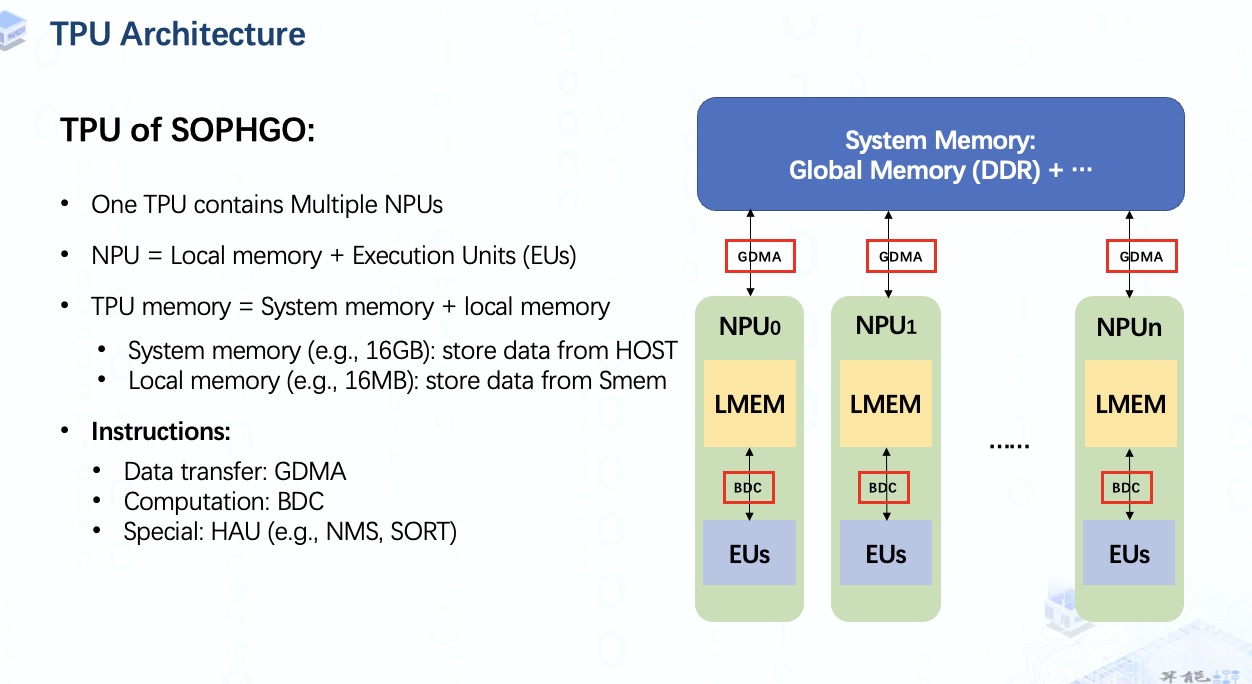
指令主要有兩種:
- GDMA用于system memory和local memory間或system memory內的數據傳輸;
-
BDC用于驅動執行單元在NPU上做計算工作;
另外,對于那些不適合并行加速的計算,比如NMS,SORT,我們還需要HAU指令,但是這意味著我們需要額外的處理器。
對于local memory的構成,它是由多個Static RAM組成的。每個 SRAM 稱為一個bank。此外,我們將這些 SRAM 分成多個部分給同樣數量的NPU,每個部分稱為一個lane。
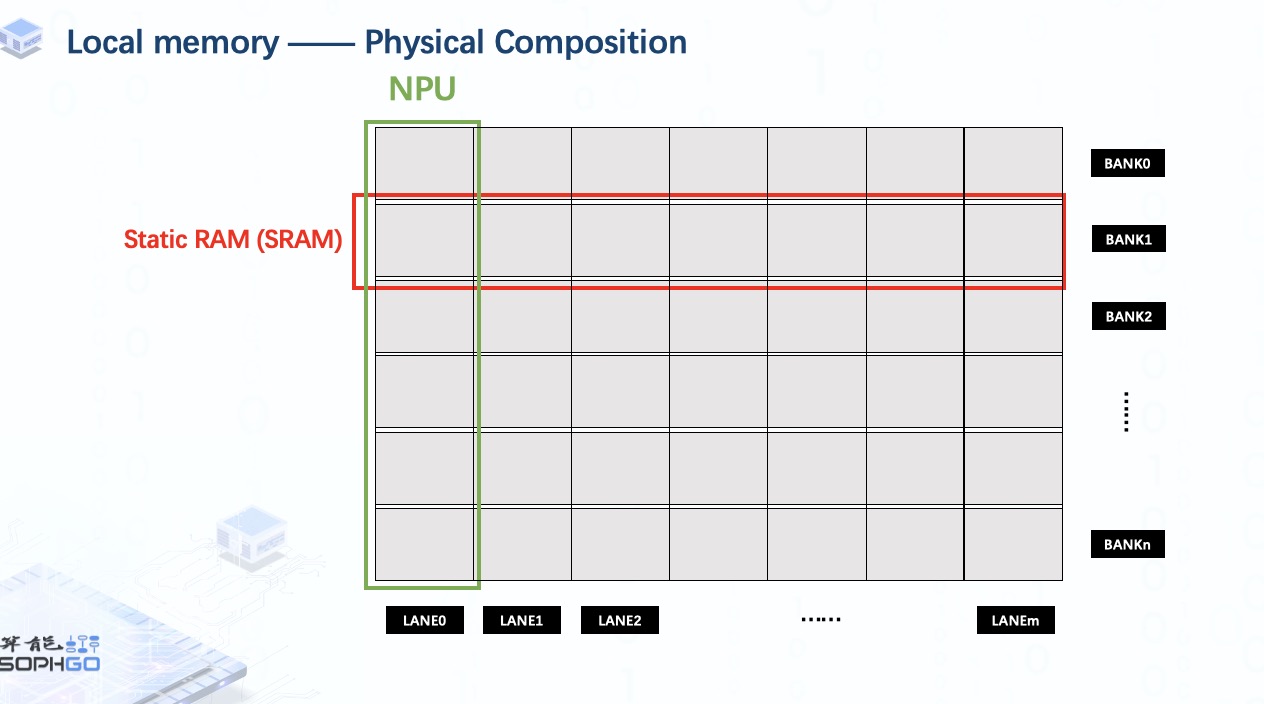
而對于每個NPU,它只能訪問屬于它的那部分local memory,這使得單個NPU的執行單元只能處理自己local memory上的那部分張量。
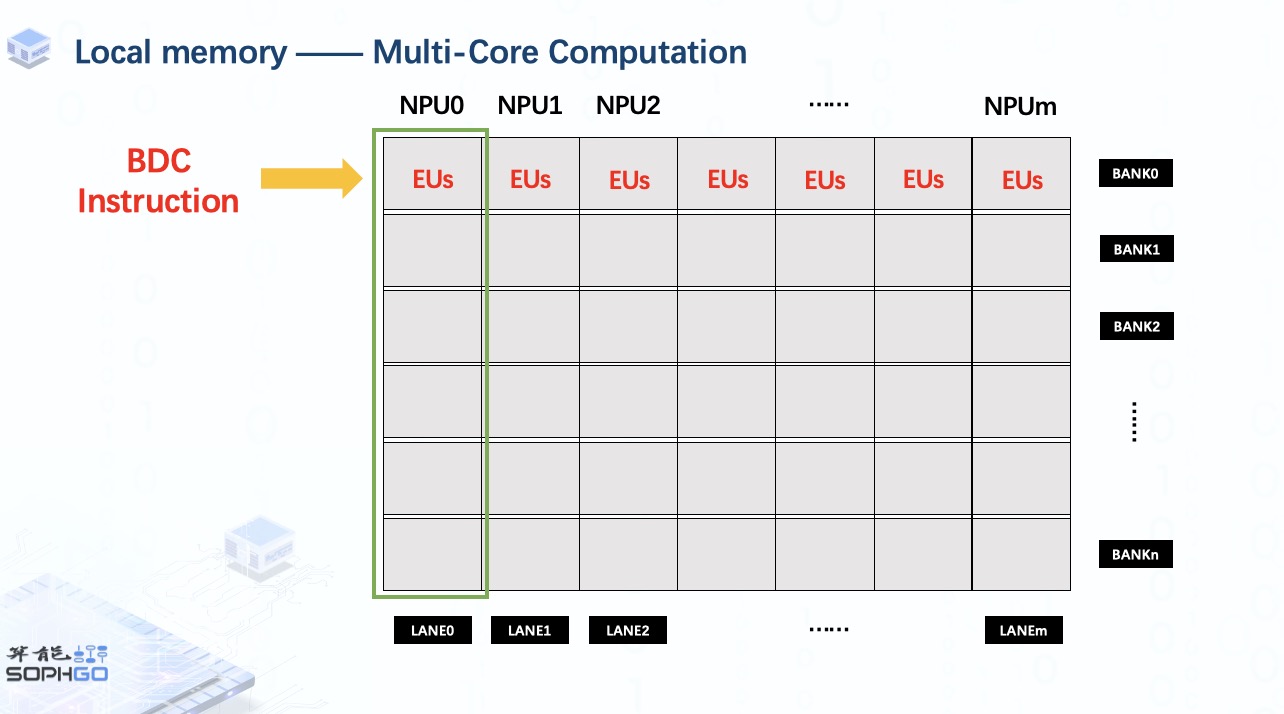
一旦我們調用單個 BDC 指令,所有 NPU 的執行單元將在每個 NPU 的相同位置執行相同的操作。 這就是 TPU 加速運算的方式。
此外,TPU 可以同時處理的數據數量取決于每個 NPU 上的執行單元數量。
對于一個特定的TPU,EU Bytes是固定的,所以對于不同類型的數據,EU的個數會有所不同。
例如當EU Bytes為64時,則表示一個NPU可以同時處理64個int8數據。
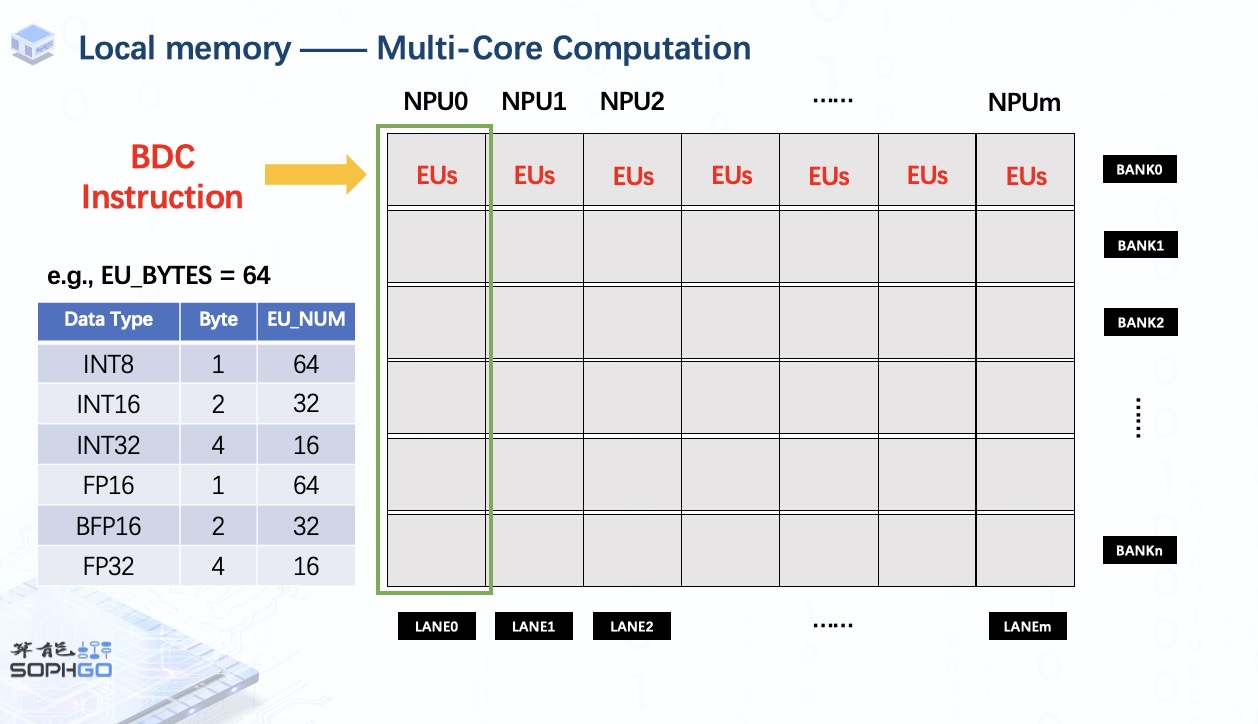
同理,我們可以根據數據的字節計算出對應的EU_NUM。
對于地址分配,假設我們的local memory由16個SRAM組成,總內存為16MB,有64個NPU,那么每個NPU的內存為256KB。

單個通道中每個bank的內存大小則為16KB,相當于16x1024 字節。
所以這個塊的地址范圍是從0到16x1024 – 1。
同理,NPU0中下個bank的地址從16x1024開始到32x1024-1
按照這個規則,我們就可以得到local memory上的所有地址。
-
DDR
+關注
關注
11文章
712瀏覽量
65342 -
內存
+關注
關注
8文章
3025瀏覽量
74047 -
TPU
+關注
關注
0文章
141瀏覽量
20728
發布評論請先 登錄
相關推薦
TPU-MLIR開發環境配置時出現的各種問題求解
CORAL-EDGE-TPU:珊瑚開發板TPU
TPU透明副牌.TPU副牌料.TPU抽粒廠.TPU塑膠副牌.TPU再生料.TPU低溫料
TPU副牌低溫料.TPU熱熔料.TPU中溫料.TPU低溫塑膠.TPU低溫抽粒.TPU中溫塑料
供應TPU抽粒工廠.TPU再生工廠.TPU聚醚料.TPU聚酯料.TPU副牌透明.TPU副牌.TPU中低溫料
采購TPU復牌料.復牌TPU原料.TPU復牌透明塑料.TPU廢邊料.TPU廢膜料.TPU低溫料
如何驗證MC68332 TPU配置是否正確?
BM1684中各種內存的概念
tpu是什么材料_tpu硬度范圍_tpu的應用
一文了解CPU、GPU和TPU的區別
一文搞懂 CPU、GPU 和 TPU

TPU和NPU的區別
谷歌發布多模態Gemini大模型及新一代TPU系統Cloud TPU v5p





 工商網監
工商網監
評論