 檢索增強的語言模型方法的詳細剖析
檢索增強的語言模型方法的詳細剖析
本篇內容是對于ACL‘23會議上陳丹琦團隊帶來的Tutorial所進行的學習記錄,以此從問題設置、架構、應用、挑戰等角度全面了解檢索增強的語言模型,作為對后續工作的準備與入門,也希望能給大家帶來啟發。
1 簡介:Retrieval-based LMs = Retrieval + LMs
首先對于一個常規的(自回歸)語言模型,其任務目標為通過計算
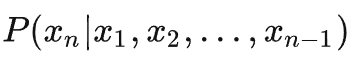
并加以采樣來預測句子中的下一個token,以此來完成對于整個句子的生成。
掩碼語言模型/編碼器-解碼器語言模型的概率計算方式與此不同,但在此不做過多討論。
而檢索增強的語言模型通過給語言模型掛載一個外部知識庫,在語言模型進行生成的同時也在知識庫中檢索相關文檔,以此來對語言模型的生成進行輔助。
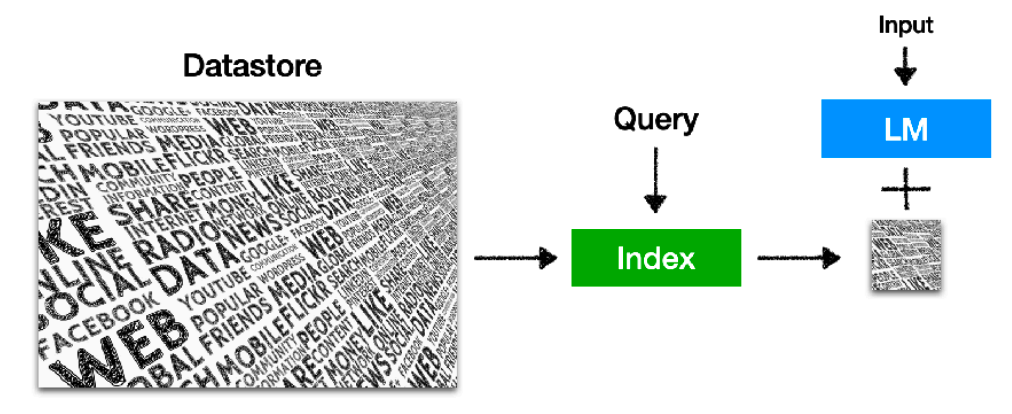
Retrieval-based LMs概念圖
然而,現有的(全參數)大語言模型已經展現出了強勁的性能。我們為什么要使用檢索增強的語言模型?以及檢索增強的語言模型能夠解決常規語言模型怎樣的缺陷?
1. LLMs不能夠僅通過參數來記憶全部的長尾(long-tail)知識。
所謂長尾知識,即為不熱門不常用的知識(e.g. 河北省2020年的總人口數有多少)。現有工作[1]也已指出,僅遵循scaling law擴大模型規模,對于長尾知識也只能夠提供較小的性能提升,實際的性能提升仍為較為常用和熱門的知識所提供的。這證明語言模型本身對于長尾知識的記憶及應用能力仍然較差,而這種“較差”與模型的規模并無直接關聯。通過對知識庫的檢索可以對這方面知識有更好的“回憶”作用。
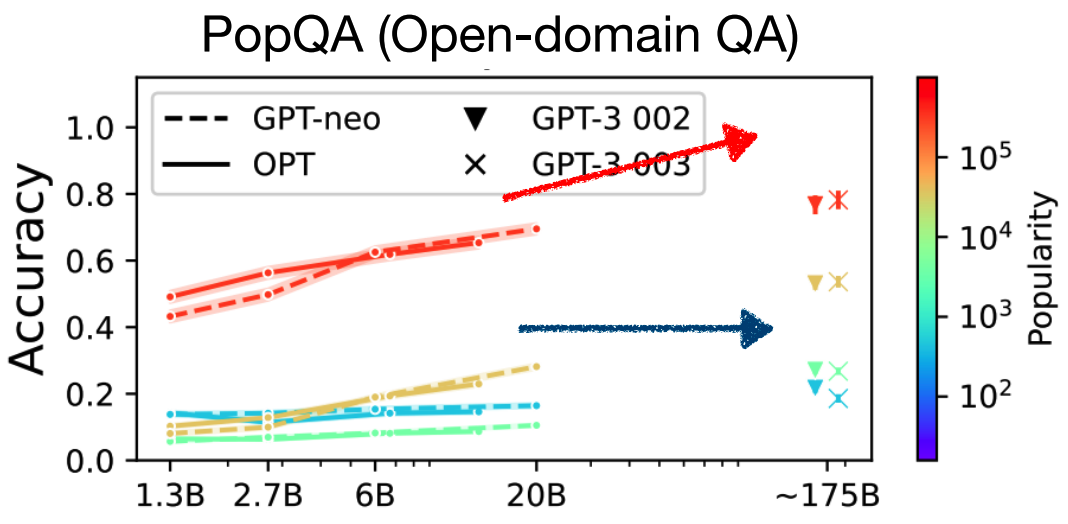
Performance on less popular questions (blue) doesn’t improve over scale
2. LLMs通過參數所記憶的知識很容易過時,并且難以更新。
如今互聯網的信息呈爆炸式增長,知識更新速度極快,而語言模型通過參數所記憶的知識只能夠保證是當時數據收集時的最新,而無法與時俱進,且語言模型預訓練的消耗量極大,無法完成對于知識的頻繁更新。雖然現有的所提出的一些“知識編輯”的方法可以對此問題有一定的緩解作用,但是可擴展性不佳。而對于檢索增強的語言模型來說,僅需要對于外部的知識庫進行更新即可解決此類問題,且更新知識庫的花費相比于重新訓練一個語言模型甚至是可以忽略不計的,并且對外部知識庫內的知識可以很容易地實現規模的擴張。
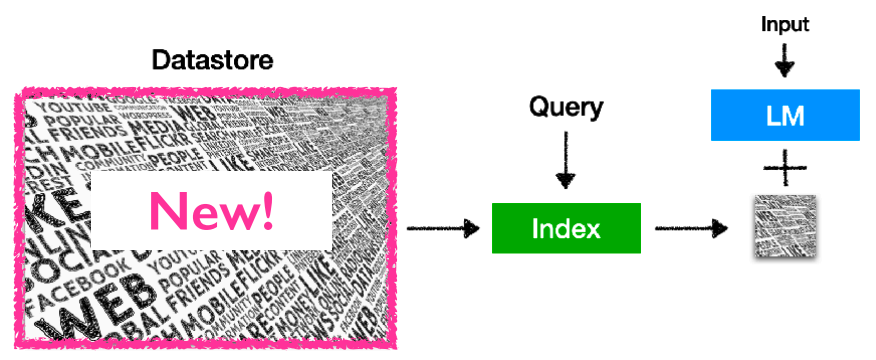
Retrieval-based LMs僅通過更新外部知識庫實現對于知識的更新
3. LLMs的輸出難以解釋和驗證。
我們通常很難對于語言模型所給出答案的原因以及依靠來源進行分析,這便導致我們很難去判斷語言模型這個“黑箱”內部的真實運行邏輯,也使得我們無法完全相信其所給出的答案(即使通常情況下是正確的,但也是不可解釋的)。而檢索增強的語言模型通過返回檢索得到的外部文檔作為依靠,我們可以很容易地知道模型正在依靠怎樣的文本知識去進行當前內容的生成,通過分析及驗證其檢索到的相關文檔,來理解模型生成當前內容的運行邏輯。
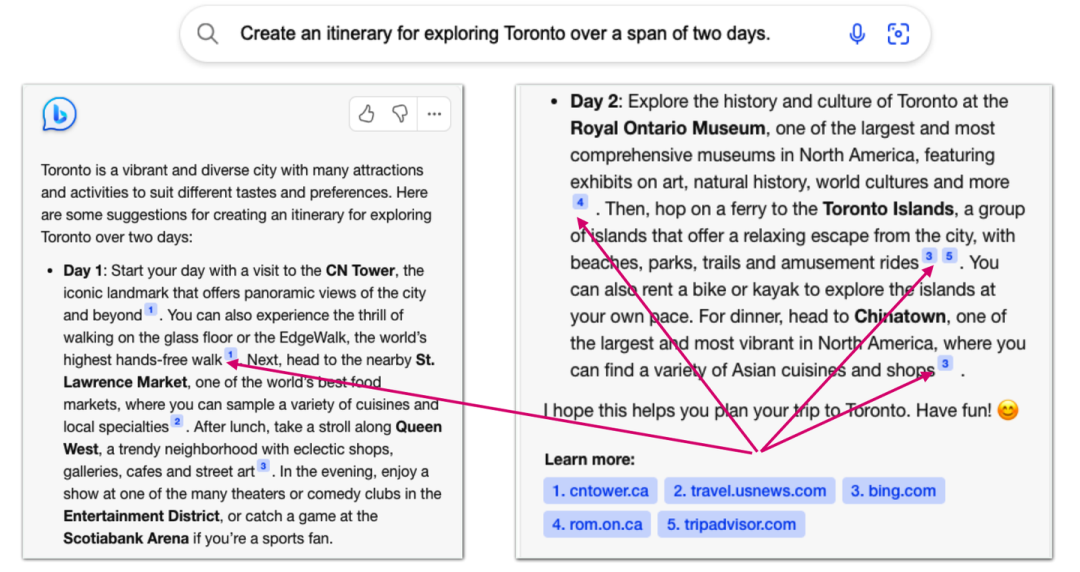
NewBing給出文檔來源的示例
4. LLMs很容易泄露隱私訓練數據。
如果將隱私數據(e.g. 用戶住址、聯系方式等)加入語言模型的預訓練階段,則使用語言模型的所有人均能夠接觸到這部分數據,顯然這會造成用戶隱私數據的泄露(OpenAI的ChatGPT也曾經面臨過此類問題),并且此類問題難以通過指令微調或者偏好對齊的方式進行徹底解決。而檢索增強的語言模型允許我們將隱私數據存儲在外部的知識庫中,而與語言模型本身參數沒有關系,語言模型可以通過訪問知識庫中的這部分數據來為我們提供更為個性化的服務,保護隱私的同時也能夠提高其個性化定制的能力。
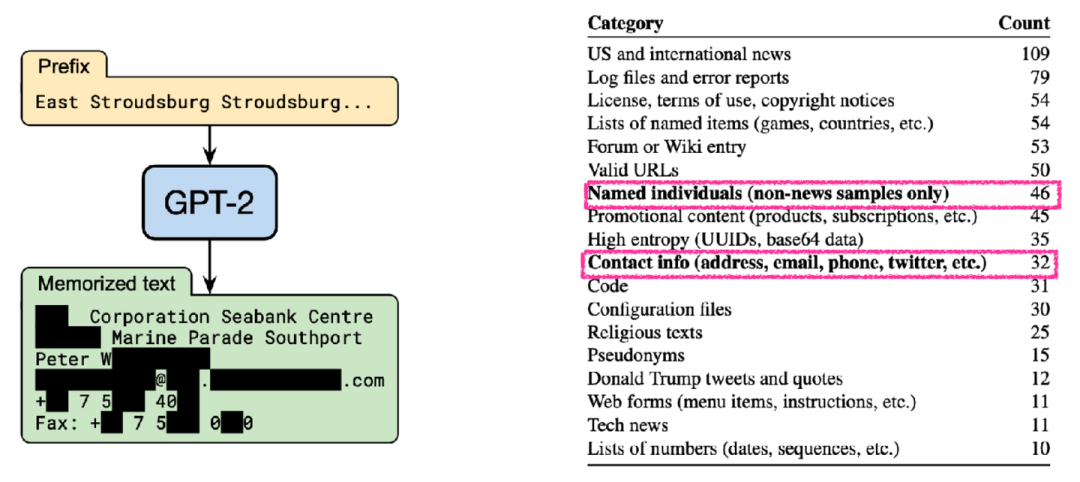
部分隱私數據被包含在了預訓練語料之中
5. LLMs規模極大,訓練和運行均極其昂貴。
不光是訓練一個大語言模型,將其部署且運行推理的花費也極其昂貴。而我們嘗試通過檢索增強的語言模型來減少語言模型本身的規模,實現一個較小的語言模型也能夠達到與大語言模型相媲美的性能。這顯然更加經濟,長期效果來看無論是對于學術界還是小規模的公司也更加友好。(現有檢索增強的語言模型工作[2]以25倍的參數縮減,實現了與GPT-3所匹配的性能)。
檢索增強的語言模型已然成為了目前較為關鍵的研究問題,值得深入探索。
2 問題定義:一個在測試階段使用外部知識存儲的語言模型
對于該定義,我們可以分為兩個部分來看:1)語言模型;2)在測試階段使用外部知識存儲。
而對于1)語言模型,則無需過多解釋,無論是目前性能較為work的自回歸Decoder-only語言模型,還是幾乎同期出現的Encoder-only/Encoder-Decoder語言模型均可以被考慮在內。
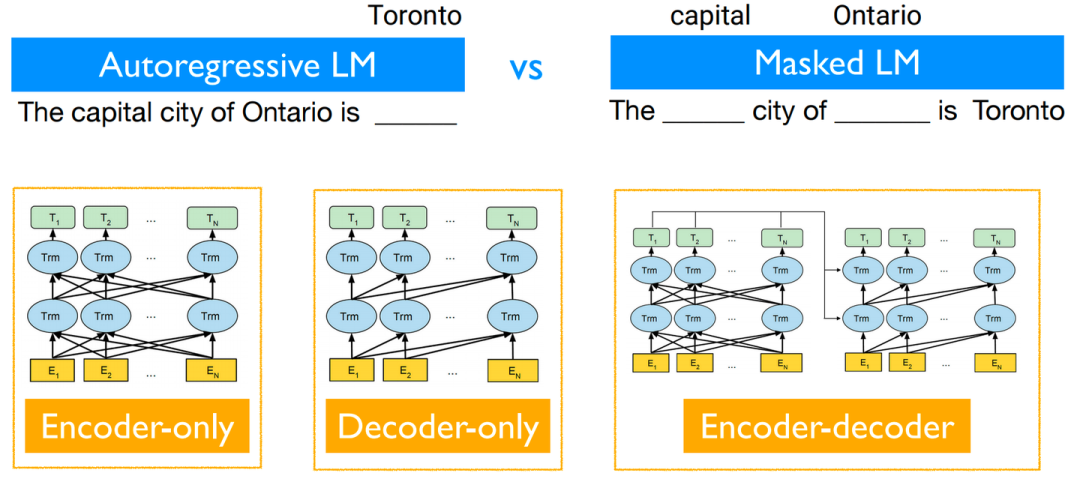
不同解碼方式/架構的語言模型
而預訓練+Prompting是目前對于語言模型較為常用且十分work的訓練范式,使語言模型能夠適配較多的下游任務,以達到通用化需求,其中可以適配的常見下游任務如下圖所示(不完全):

語言模型通過Prompting后適配的多種常見下游任務
且對于訓練好的模型,我們通常可以通過兩種評估手段來判斷模型性能的好壞,分別為:困惑度(Perplexity)和下游任務準確度(Downstream Accuracy)。
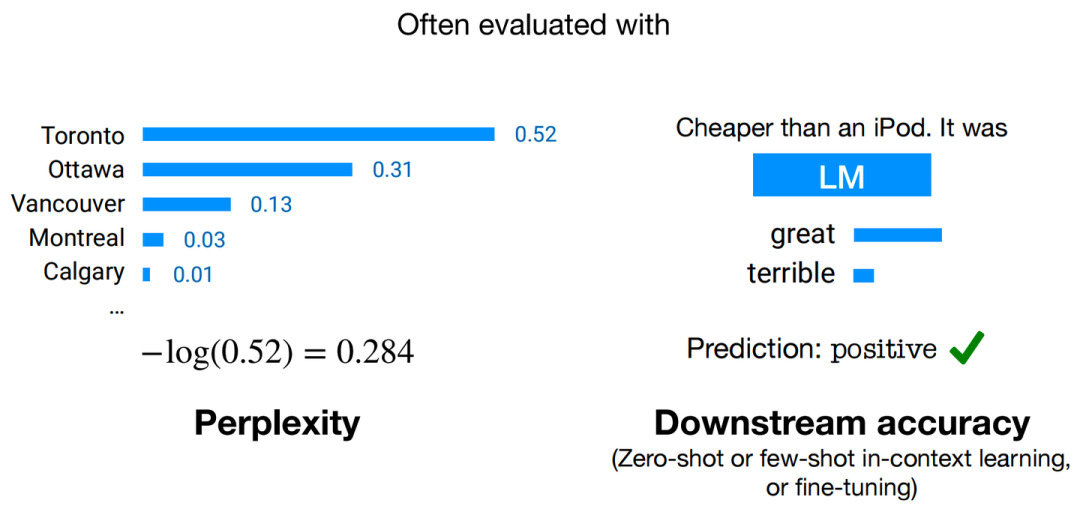
兩種常用評估手段
其中,Perplexity的計算方式為:
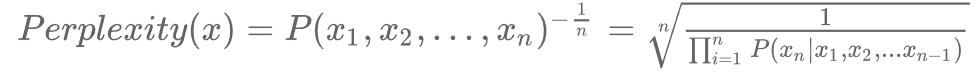
為方便計算,語言模型的實際評估過程中常使用log-perplexity進行計算(與上圖示例中相同),即只需要外套一個log,計算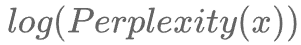 即可。
即可。
進一步的,對于2)在測試階段使用外部知識存儲,具體形式如下圖所示:
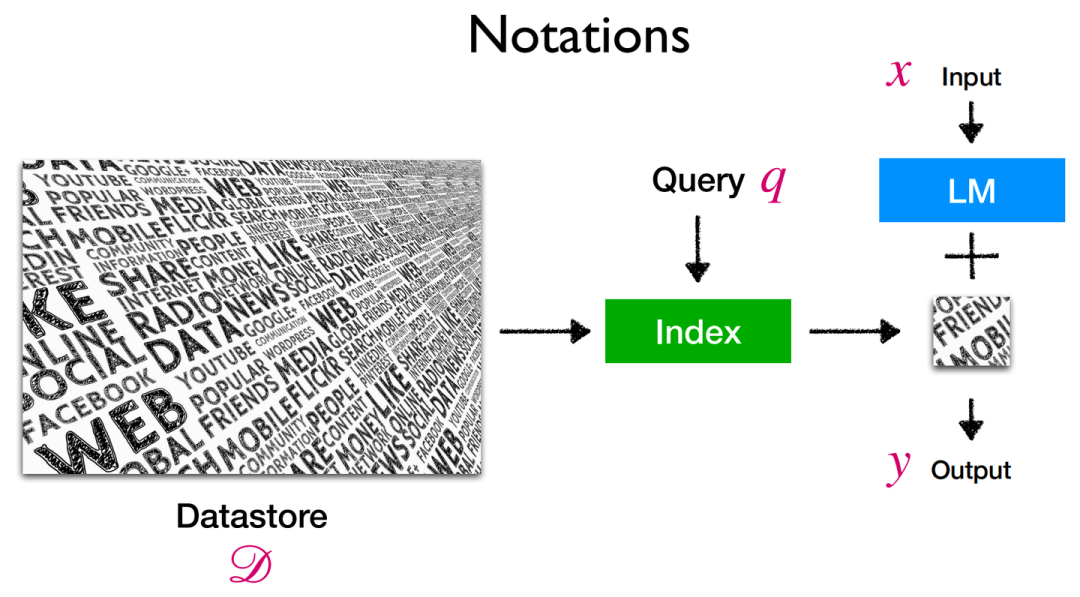
Retrieval-based LMs推理階段示意圖
首先對于Datastore,其內部組成大多為原始文本語料,即包含至少1-10B token的無標簽且非結構化數據(也有部分的知識庫為向量存儲形式)。而上圖中的Query即代表用于檢索的查詢,該檢索查詢q與輸入語言模型的x并不一定相同。Index即為在知識庫D中查找得到的與檢索查詢q最相似的一小部分(Top-k個)元素子集,這也是我們在知識庫中的查詢目標。
在此涉及到了相似度的計算,則便衍生出多種可選的相似度度量方式,可以是類似于TF-IDF的傳統計算方式,也可以是對嵌入向量間的點乘計算方式等等。同時檢索的方式也包含了精確檢索/近似檢索,此即為檢索開銷與檢索精度間的trade-off了。

兩種文本間相似度計算方式示例
而對于上述全部的定義,我們提出三點需要解答的問題以供后續展開:
(When)檢索查詢是怎樣的 & 何時執行檢索操作?
(What)檢索何種形式的內容?
(How)如何去利用檢索得到的內容?
3 架構:What & How & When
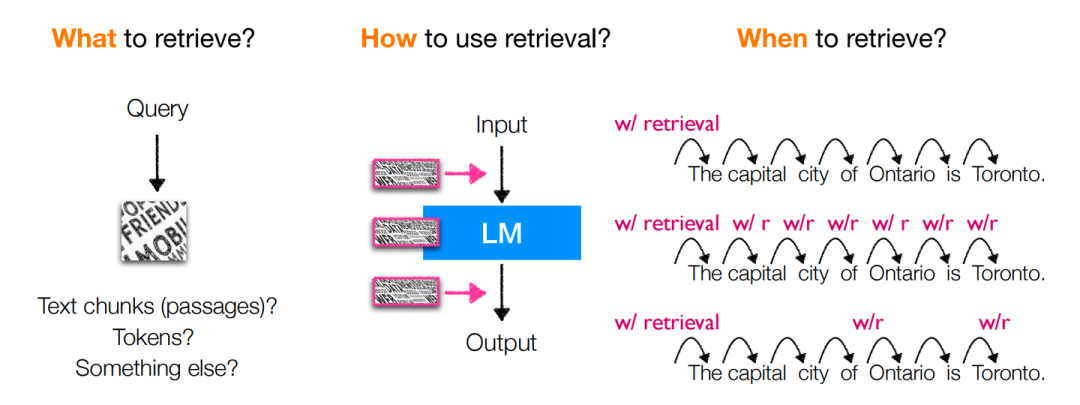
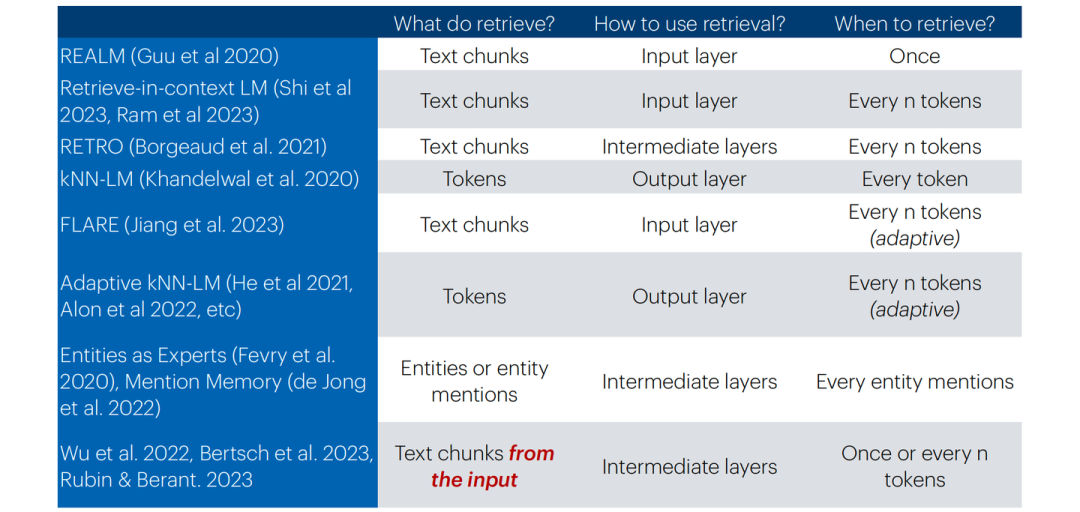
上圖即為對于以上所提出的三個問題的回答,可總結為下表:

分別對于各個情況進行對比討論,則我們可以從具體性能與經驗上可以得到下述結論:
1)對于“What to retrieve?”:
直接檢索chunks能夠降低檢索難度(因為原始語料中多數文本也正以大段的形式存在),且空間上更加友好。
相比于檢索chunks,檢索更細粒度的tokens可以更好地利用罕見模式(e.g. 檢索表示深度學習算法包的“torch”,而非火把“torch”)以及領域外知識(OOD),并且檢索也會非常高效(kNN搜索本身即十分高效),但會導致數據存儲在空間上開銷更大(e.g. Wikipedia:chunks-13M v.s. tokens-4B),并且語言模型輸出結果與檢索結果之間并無交叉注意力計算,性能因此會受到部分損害。
除這二者之外,檢索entity mention同樣為一種可行方式,其思想可歸納為“One vector per entity mention”,即去知識庫中檢索查詢中所出現的實體對象,在以實體為中心的任務中更加有效,相比于檢索token,在存儲空間上也更加友好,但同時也需要增加額外的實體檢測操作。
2)對于“How to use retrieval?”:
在input layer直接加入檢索到的文檔顯然十分簡單直觀,在面對大量、頻繁的文檔檢索場景時是十分低效的。
而在intermediate layer應用檢索到的信息,相比于直接在input layer添加檢索到的文檔,可以利用語言模型的更多塊(block),以支持更頻繁的檢索,使計算更加高效,但同時也會引入較多的復雜度,使得整個模型無法不經訓練直接使用。
在Output layer應用檢索信息則是對于語言模型預測token與檢索得到的token概率進行的加權聚合(以kNN-LM為代表),同樣可以不經訓練便可以直接使用,關鍵更多在于存儲各種token上下文時的空間開銷。
3)對于“When to retrieve?”:
上表中所提及的三種檢索頻率,應用上更多是根據剩余兩個問題所決定的架構而調整的,但我們可以發現上述三種選擇大多數情況下均為固定的檢索頻率。當前也正有工作向著自適應的檢索頻率進行發展,即當語言模型對給出答案置信度較高時,不執行檢索或降低檢索頻率,反之更加頻繁地執行檢索操作。抑或是在Output layer進行對于預測token的概率加權聚合時,將各個組件的權重視作與輸入x有關的函數,以動態調整檢索與語言模型預測結果對于最終輸出結果的作用權重。自適應的檢索頻率能夠提高效率,但最終的結果可能不是最優的。
由于所涉及到的各個工作實現細節過于繁多,在此并不展開來講,可根據下方總結圖表進行對應索引:
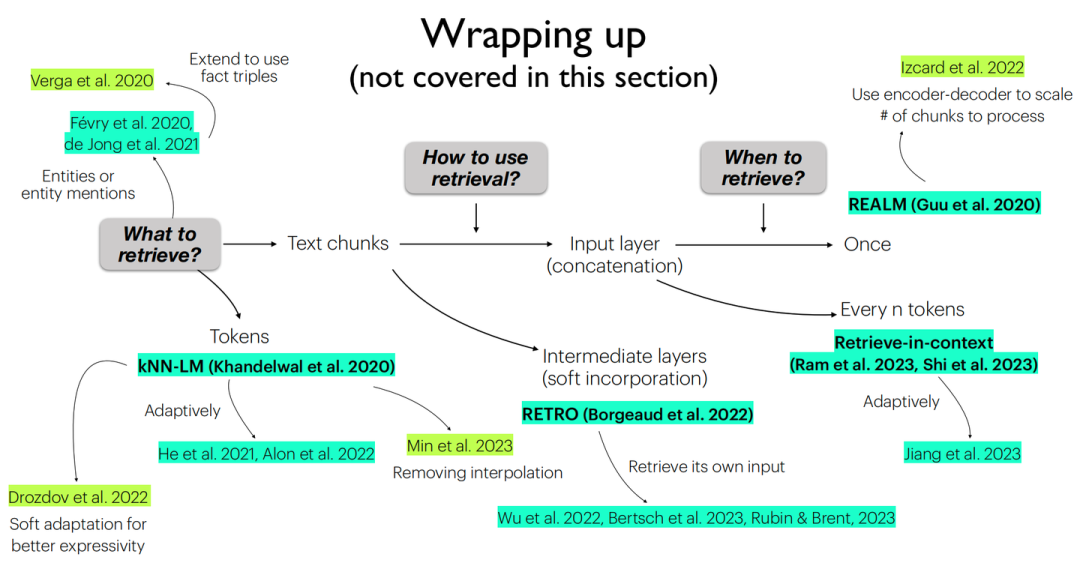
當前各工作所采取的不同架構總結圖
當前各工作所采取的不同架構總結表
上表中最后一行也提及了一類不同的檢索增強的語言模型,相比于其他種類,此類并不從外部的知識庫中進行信息的檢索,而是從自身生成的歷史信息中進行“自檢索”,其目標是為了處理超長文本或實現自身的長期記憶,這樣的架構設計也是為了實現這樣的下游任務而設計的。
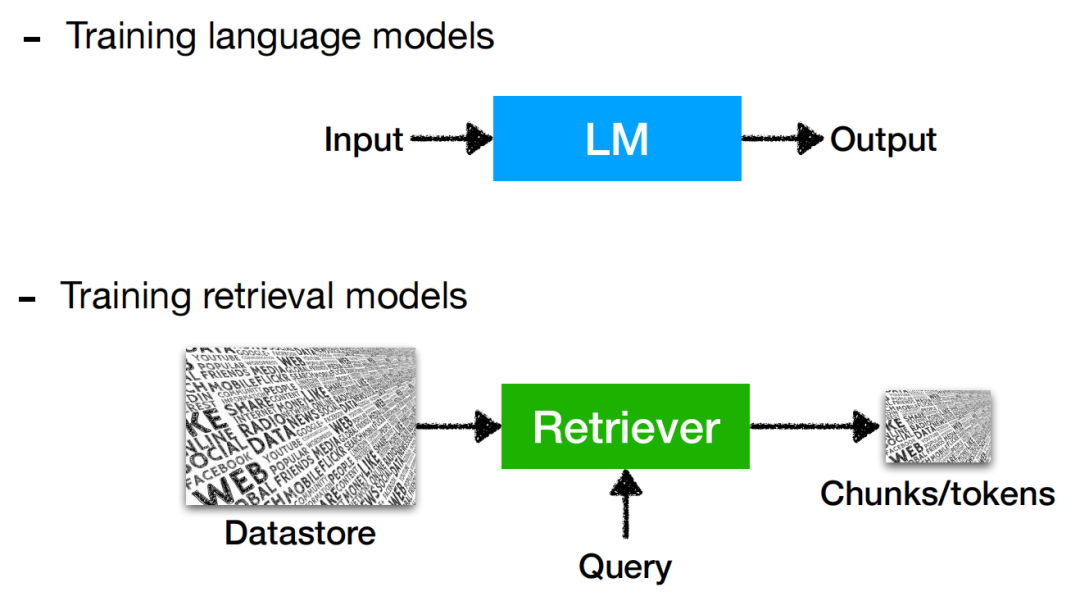
4 訓練:(To train and how to train) or not to train
檢索增強的語言模型的訓練同樣是最關鍵的一點,簡單地同時去訓練語言模型以及更新索引顯然無論在空間上還是在時間上都是復雜度極高的。現有工作中對于檢索增強的語言模型被證實的比較work的訓練方式可劃分為以下四類:
Independent training:語言模型與檢索器均是獨立訓練的。
Sequential training:獨立訓練單個組件后將其固定,另一個組件根據此組件任務目標進行訓練。
Joint training w/ asynchronous index update:允許索引是“過時”的,即每隔T步才重新更新檢索索引。
Joint training w/ in-batch approximation:使用“批內索引”,而不是完整知識庫中的全部索引。
以上提及的四類訓練方式各有優缺點:
Independent training:可以使用現成的模型(大型索引和強大的LM)而無需額外的訓練,每個部分都可以獨立改進;但語言模型沒有被訓練如何利用檢索,且檢索模型沒有針對語言模型的任務/域進行優化。
Independent training
Sequential training:可以使用現成的單個組件(大型索引或強大的LM),并且可以訓練語言模型以更加有效地利用檢索結果,或者可以訓練檢索器以更好地提供幫助語言模型的檢索結果;然而有一個組件仍然是固定沒有經過訓練的。

Sequential training
Joint training w/ asynchronous index update:此方法存在索引更新頻率的選取難題,頻率過高會導致開銷昂貴,頻率過低會導致索引“過時”而影響性能。
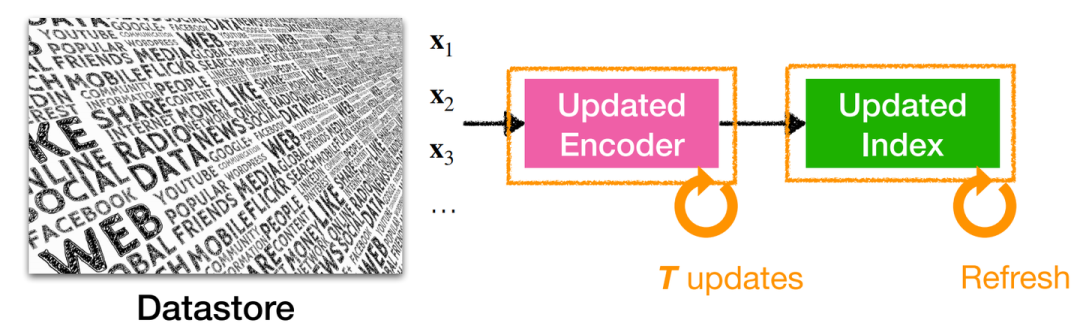
Joint training w/ asynchronous index update
Joint training w/ in-batch approximation:因在整個知識庫中實現重新索引會產生巨量的計算開銷,此方法只在批內進行重新索引的更新計算,以更小的計算開銷去近似整體重新索引的效果。
!Joint training w/ in-batch approximation
對于Joint training,其均能夠獲取更加良好的性能,但訓練更為復雜(異步更新、計算開銷、數據批處理等),并且訓練-測試的差異仍然存在。
整體看來,上述的四類訓練方式除了與模型的設計架構直接相關,還主要為訓練開銷與模型性能之間的trade-off,后續研究工作的開展也同樣應該是圍繞這種思路構建的,以尋求最佳的開銷-性能平衡點。以上所提到的四類訓練方式的全部相關信息可以被總結為下表:

訓練方式優/劣勢總結表
5 應用:What & How & When
首先,我們需要明確的是:What are the tasks?我們可以從下圖中得到一個全面的了解:
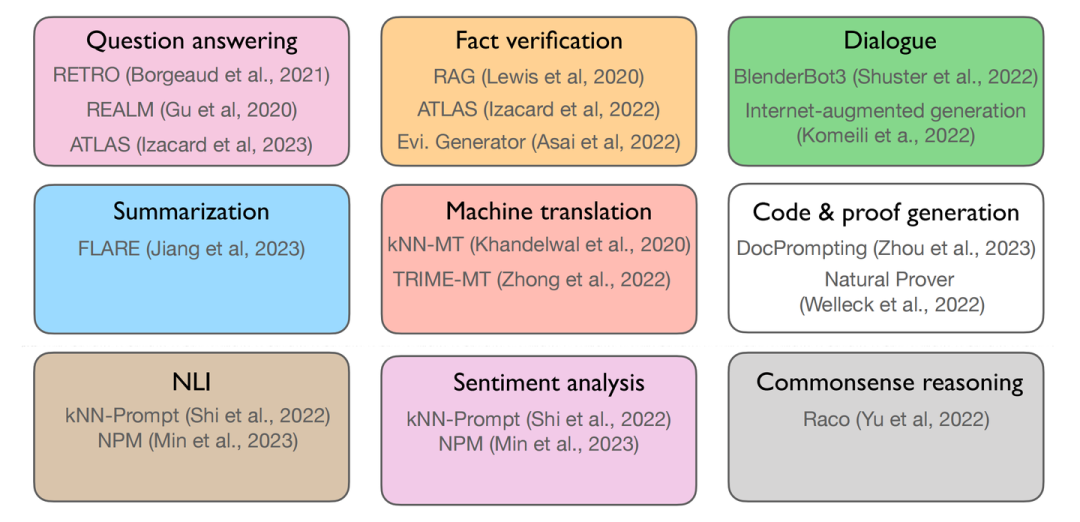
檢索增強的語言模型可應用的各類下游任務
其中第一行的三個任務所代表的是知識密集型任務(knowledge-intensive),第二行所表示的是More generations類型的任務,最下面一行所表示的是More classifications型任務。
同時我們還需要回答下列問題:
How can we adapt a retrieval-based LM for a task?
When should we use a retrieval-based LM?
針對How,目前主要的求解范式可以被分為:Fine-tuning,Reinforcement learning,Prompting;并且這三者可同時出現并利用,具體形式如下所示:
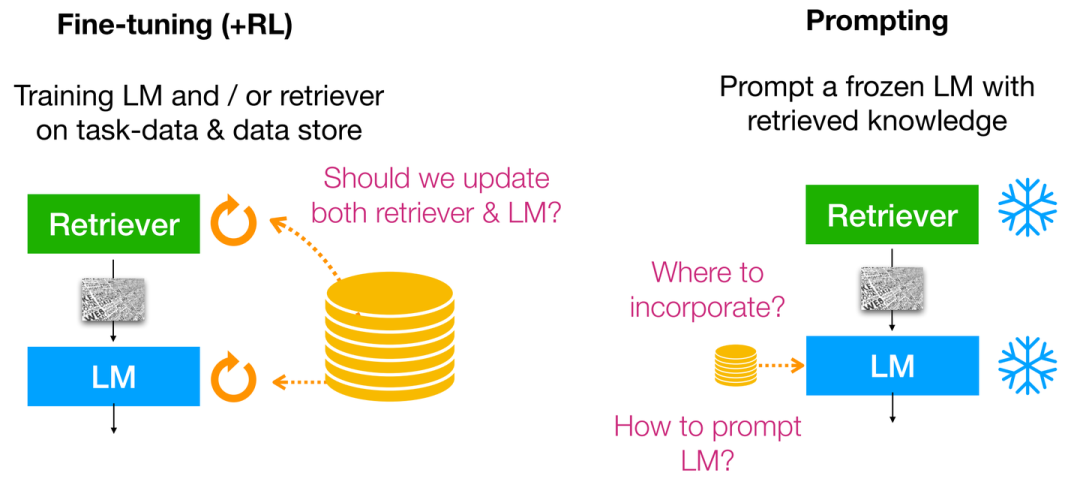
How can we adapt a retrieval-based LM for a task?
雖然Fine-tuning與Reinforcement learning(RLHF)的結合使得語言模型能夠更好地與人類偏好對齊,但需要額外的訓練以及收集額外的偏好/對齊數據。但如果我們不能為下游任務訓練語言模型時(e.g. 缺乏計算資源/專有未開源的語言模型等),此時我們便應該訴諸于Prompting,此時便無法從語言模型的中間層進行改進,而只能去操作語言模型的輸入/輸出層(輸入合并檢索上下文/輸出token概率插值聚合)。
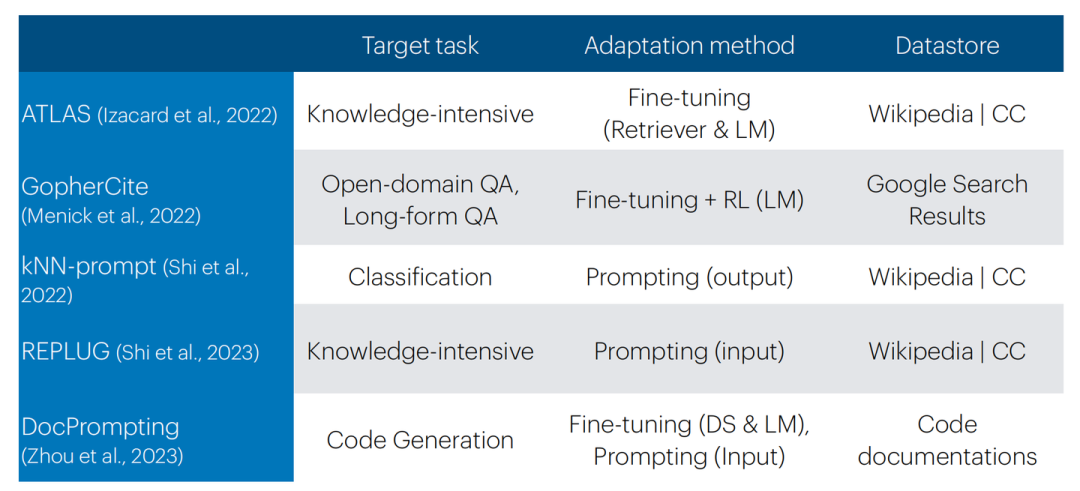
各類模型What & How & When分類總結
總結而言,Retrieval-based prompting實現起來非常簡單,無需訓練;但結果/性能上有更高的方差。Fine-tuning(+RL)需要額外訓練但結果/性能上方差較小,且需要收集更多的額外數據。并且需要注意的是,在下游任務上訓練檢索器會很有幫助。
并且我們需要明確知識庫的類型,這可以是多樣化的,大致可分為:Wikipedia,訓練數據,代碼文檔。但在OOD檢索上仍然具有挑戰。
而針對When,我們可以通過下圖進行總結:
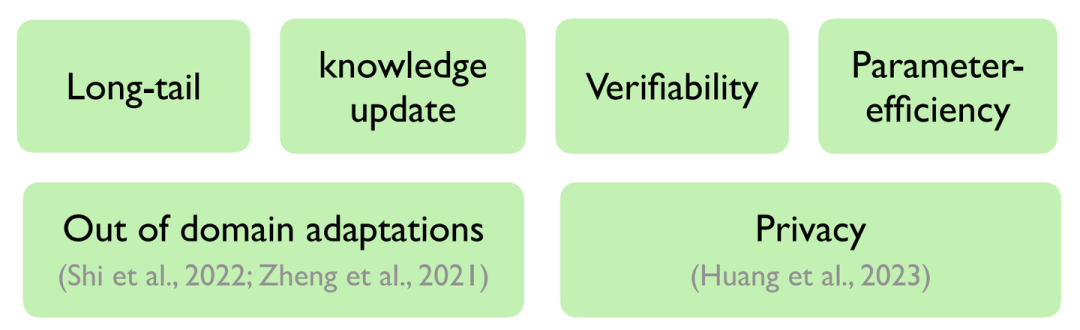
When should we use a retrieval-based LM?
其中上述六方面概念我們在前文中也有所總結,故在此不過多贅述。
在此需要注意的是,多數工作證實檢索增強的語言模型在MMLU數據集(Multiple-choice NLU任務)上表現不佳,聯想到先前也有工作表示通過向量相似度計算的方式無法很好地完成多詞條召回(Multi-tag recall)任務,故筆者猜測可能多選任務上性能不佳的原因也與此有關聯,此部分仍有很大的提升空間。
6 擴展:Multilingual & Multimodal
此類擴展均是面向了更加多樣化的知識庫形式,從而能夠使語言模型從更多種類的存儲形式中獲取知識。
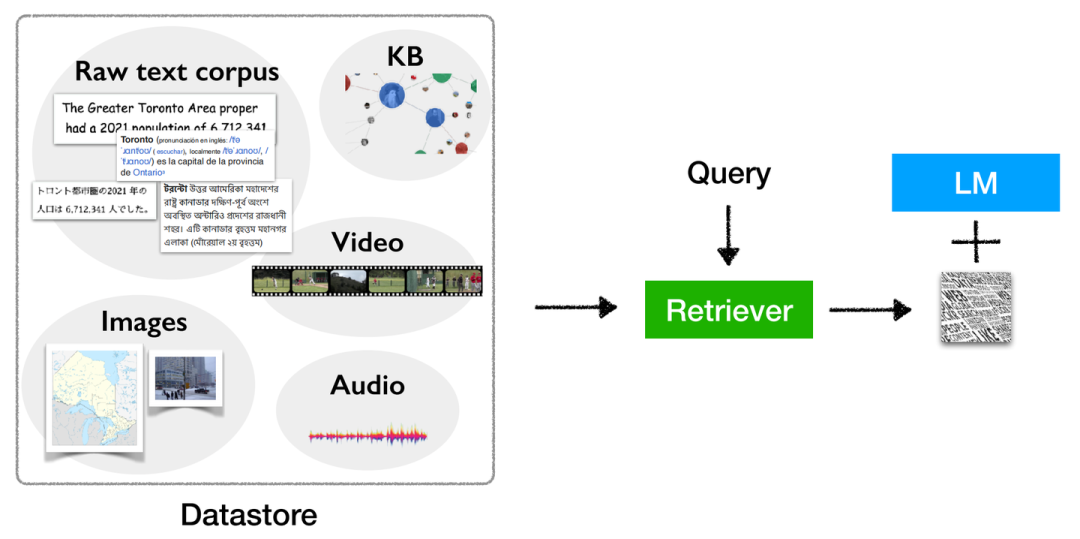
不限形式的檢索增強的語言模型
除了報告中介紹的具備代表性的多語言檢索增強的語言模型[3]外,更多此類工作總結如下:

多語言檢索增強的語言模型——現有工作
除了報告中所介紹的Meta最新多模態檢索增強的語言模型工作[4]外,更多此類工作總結如下:

多模態檢索增強的語言模型——現有工作
總結而言,擴展到多語言檢索:可以實現通過跨語言檢索和生成來克服許多世界語言中數據存儲的稀缺性(e.g. 中文互聯網數據中缺少的知識可以從英文互聯網數據中尋求補充);而擴展到多模態檢索:為了使輸入(輸出)適配更多的模態,從而可以將模型更加靈活通用地部署在各類下游任務上。
審核編輯:彭菁
-
解碼器
+關注
關注
9文章
1144瀏覽量
40829 -
存儲
+關注
關注
13文章
4338瀏覽量
85998 -
參數
+關注
關注
11文章
1846瀏覽量
32331 -
數據收集
+關注
關注
0文章
72瀏覽量
11211 -
語言模型
+關注
關注
0文章
533瀏覽量
10300
原文標題:陳丹琦 ACL'23 Tutorial - 基于檢索的大語言模型 學習筆記
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】大語言模型的應用
檢索式智能對話機器人開發實戰案例詳細資料分析概述
詳解剖析Go語言調度模型的設計
介紹幾篇EMNLP'22的語言模型訓練方法優化工作
虹科分享 | 谷歌Vertex AI平臺使用Redis搭建大語言模型






 工商網監
工商網監
評論