 大語言模型“書生·浦語”多項專業評測拔頭籌
大語言模型“書生·浦語”多項專業評測拔頭籌
最近,AI大模型測評火熱,尤其在大語言模型領域,“聰明”的上限被不斷刷新。
“SuperCLUE是由創立于2019年的CLUE學術社區最新發布的中文通用大模型綜合性評測基準,包含SuperCLUE-Opt客觀題測試、SuperCLUE-Open主觀題測試、SuperCLUE-LYB瑯琊榜用戶投票的匿名對戰測試三大基準組成。為更好地反映國內大模型與國際領先大模型間的差距和優勢,SuperCLUE選取了多個國內外有代表性的可用模型進行評測,同時由于其數據集保密性高,對大模型來說是‘閉卷考試’,減少了模型訓練數據混入評測數據的可能性。此外,SuperCLUE還通過自動化評測方式測試不同模型效果,可一鍵對大模型進行評測,相對更客觀。” “書生·浦語”:不僅善于考試,還是開源大模型中的佼佼者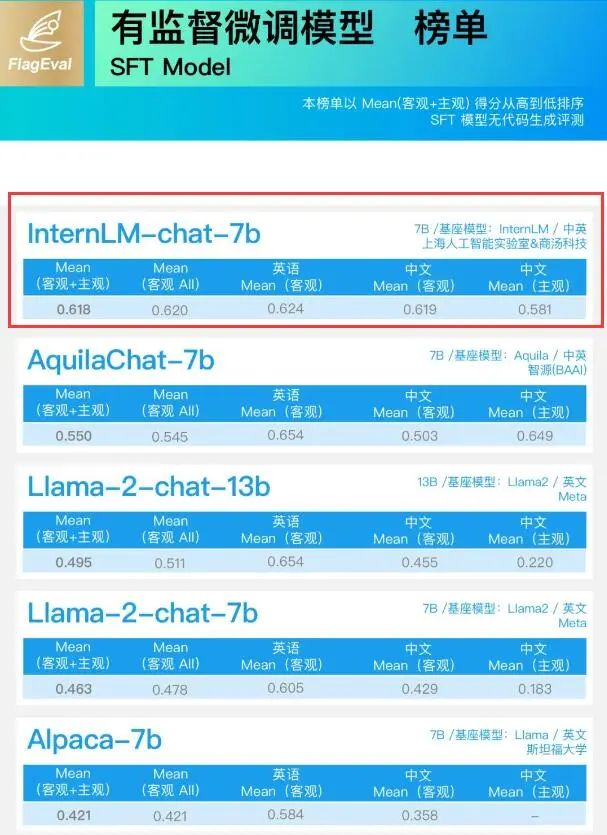
 ?
? ?作為SuperCLUE綜合性三大基準之一,SuperCLUE-Opt評測基準每期有3700+道客觀題(選擇題),由基礎能力(10個子任務)、中文特性能力(10個子任務)、學術專業能力(50+子任務)組成,采用封閉域測試方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在學術專業方面取得較大領先,同時全面領先于第三名Baichuan-13B-Chat。
?作為SuperCLUE綜合性三大基準之一,SuperCLUE-Opt評測基準每期有3700+道客觀題(選擇題),由基礎能力(10個子任務)、中文特性能力(10個子任務)、學術專業能力(50+子任務)組成,采用封閉域測試方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在學術專業方面取得較大領先,同時全面領先于第三名Baichuan-13B-Chat。
商湯與上海AI實驗室等聯合打造的大語言模型“書生·浦語”(InternLM)也表現出色,分別在智源FlagEval大語言模型評測8月排行榜和中文通用大模型綜合性評測基準SuperCLUE 7月評測榜兩項業內權威大模型評測榜單中獲得優異成績。 “FlagEval是知名人工智能新型研發機構北京智源人工智能研究院推出的大模型評測體系及開放平臺。FlagEval大模型評測體系構建了“能力-任務-指標”三維評測框架,可視化呈現評測結果,總計600+評測維度,包括22個主觀、客觀評測數據集,84433道評測題目。除知名的公開數據集 HellaSwag、MMLU、C-Eval外,FlagEval還集成了包括智源自建的主觀評測數據集Chinese Linguistics & Cognition Challenge (CLCC),北京大學等單位共建的詞匯級別語義關系判斷、句子級別語義關系判斷、多義詞理解、修辭手法判斷評測數據集。”
“SuperCLUE是由創立于2019年的CLUE學術社區最新發布的中文通用大模型綜合性評測基準,包含SuperCLUE-Opt客觀題測試、SuperCLUE-Open主觀題測試、SuperCLUE-LYB瑯琊榜用戶投票的匿名對戰測試三大基準組成。為更好地反映國內大模型與國際領先大模型間的差距和優勢,SuperCLUE選取了多個國內外有代表性的可用模型進行評測,同時由于其數據集保密性高,對大模型來說是‘閉卷考試’,減少了模型訓練數據混入評測數據的可能性。此外,SuperCLUE還通過自動化評測方式測試不同模型效果,可一鍵對大模型進行評測,相對更客觀。” “書生·浦語”:不僅善于考試,還是開源大模型中的佼佼者
“書生·浦語”,是商湯科技、上海AI實驗室聯合香港中文大學、復旦大學及上海交通大學打造的大語言模型,具有千億參數,在包含1.8萬億token的高質量語料上訓練而成。
今年6月,“書生·浦語”聯合團隊曾選取20余項評測進行檢驗,包括全球最具影響力的四個綜合性考試評測。結果顯示,“書生·浦語”在綜合性考試中表現突出,在多項中文考試中超越ChatGPT。(詳情可參考「AI考生今日抵達,商湯與上海AI實驗室等發布“書生·浦語”大模型」報道) 7月,“書生·浦語”正式開源70億參數的輕量級版本InternLM-7B。(https://github.com/InternLM/InternLM)
后續又推出升級版對話模型InternLM-Chat-7Bv1.1,成為首個具有代碼解釋能力的開源對話模型,能根據需要靈活調用Python解釋器等外部工具,解決復雜數學計算等任務的能力顯著提升。
此外,該模型還可通過搜索引擎獲取實時信息,提供具有時效性的回答。
在北京智源人工智能研究院FlagEval大語言模型評測體系8月最新排行榜中, “InternLM-chat-7B”和“InternLM-7B”分別在監督微調模型(SFT Model)榜單、基座模型(Base Model)榜單中取得第一和第二名。
“InternLM-chat-7B”還刷新中英客觀評測記錄。 「什么是“基座模型”、“有監督微調模型”?」 基座模型(Base Model)是經過海量數據預訓練(Pre-train)得到的,它具備一定的通用能力,比如:GPT-3。 有監督微調模型(SFT Model)則是經過指令微調數據(包含了各種與人類行為及情感相關的指令和任務的數據集)訓練后得到的,具備了與人類流暢對話的能力,如:ChatGPT。 普遍的觀點認為,基座模型在很大程度上決定了微調模型的能力。 因此,FlagEval大語言模型評測體系針對基座模型的評測主要從“提示學習評測”和“適配評測”兩方面進行;針對有監督微調模型的評測則從“復用針對基座模型的客觀評測” 進一步增加“引入主觀評測”。 此次兩個榜單中,“InternLM-chat-7B”和“InternLM-7B”均表現出優異的綜合性能,超越備受關注的Llama2-chat-13B/7B和Llama2-13B/7B。 特別在SFT Model測試中,InternLM-chat-7B中文能力大幅領先同時,英文能力也與對手保持在相近水平,展現出更強的實用性能。
?SuperCLUE評測從基礎能力、專業能力、中文特性能力三個不同維度對國內外通用大模型產品進行評價,考察大模型在70余個任務上的綜合表現。
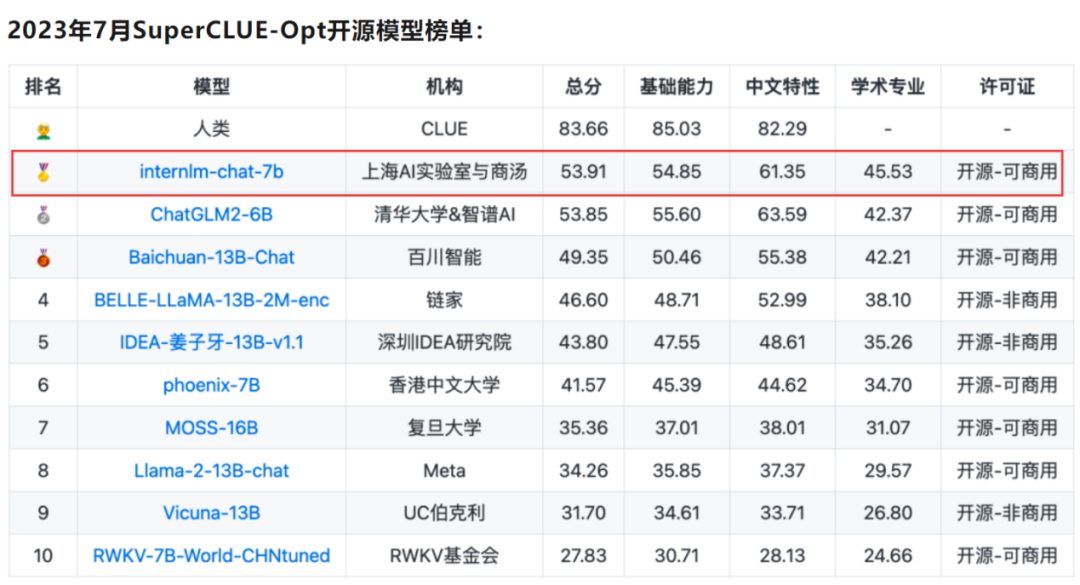
“書生·浦語”InternLM-chat-7B在7月公布SuperCLUE評測榜單中表現出色,在SuperCLUE-Opt開源大模型榜單拔得頭籌。
?作為SuperCLUE綜合性三大基準之一,SuperCLUE-Opt評測基準每期有3700+道客觀題(選擇題),由基礎能力(10個子任務)、中文特性能力(10個子任務)、學術專業能力(50+子任務)組成,采用封閉域測試方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在學術專業方面取得較大領先,同時全面領先于第三名Baichuan-13B-Chat。

相關閱讀,戳這里
《讓大模型“百花齊放”,商湯大裝置SenseCore提供一片沃土》《商湯發布多模態多任務通用大模型“書生2.5”》
《商湯聯合發布通才AI智能體通關<我的世界>》

原文標題:大語言模型“書生·浦語”多項專業評測拔頭籌
文章出處:【微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
商湯科技
+關注
關注
8文章
510瀏覽量
36090
原文標題:大語言模型“書生·浦語”多項專業評測拔頭籌
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
云知聲山海大模型多項評測名列前茅
近日,智源研究院發布并解讀了國內外100余個開源和商業閉源的語言、視覺語言、文生圖、文生視頻、語音語言大模型綜合及專項評測結果。
云知聲山海大模型多項能力全球領跑
國內人工智能權威機構清華大學基礎模型研究中心發布SuperBench九月綜合榜單。本次評測選取海內外24個具有代表性的大模型,結果顯示,山海大模型對齊、智能體、安全等

【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
松。
入門篇主要偏應用,比如大語言模型的三種交互方式,分析了提示工程、工作記憶和長短期記憶,此篇最后講了ChatGPT的接口和擴展功能應用,適合大語言模型應用技術人員閱讀。
進階篇就非
發表于 07-21 13:35
名單公布!【書籍評測活動NO.34】大語言模型應用指南:以ChatGPT為起點,從入門到精通的AI實踐教程
聯系,視為放棄本次試用評測資格!
2018 年,OpenAI 發布了首個大語言模型——GPT,這標志著大語言模型革命的開始。這場革命在 20
發表于 06-03 11:39
大語言模型:原理與工程時間+小白初識大語言模型
種語言模型進行預訓練,此處預訓練為自然語言處理領域的里程碑
分詞技術(Tokenization)
Word粒度:我/賊/喜歡/看/大語言模型
發表于 05-12 23:57
【大語言模型:原理與工程實踐】大語言模型的應用
,它通過抽象思考和邏輯推理,協助我們應對復雜的決策。
相應地,我們設計了兩類任務來檢驗大語言模型的能力。一類是感性的、無需理性能力的任務,類似于人類的系統1,如情感分析和抽取式問答等。大語言
發表于 05-07 17:21
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》2.0
讀者更好地把握大語言模型的應用場景和潛在價值。盡管涉及復雜的技術內容,作者盡力以通俗易懂的語言解釋概念,使得非專業背景的讀者也能夠跟上節奏。圖表和示例的運用進一步增強了書籍的可讀性。本
發表于 05-07 10:30
【大語言模型:原理與工程實踐】大語言模型的基礎技術
全面剖析大語言模型的核心技術與基礎知識。首先,概述自然語言的基本表示,這是理解大語言模型技術的前提。接著,詳細介紹自然
發表于 05-05 12:17
名單公布!【書籍評測活動NO.31】大語言模型:原理與工程實踐
放棄本次試用評測資格!
緣起:為什么要寫這本書
OpenAI的ChatGPT自推出以來,迅速成為人工智能領域的焦點。ChatGPT在語言理解、生成、規劃及記憶等多個維度展示了強大的能力。這不僅體現在
發表于 03-18 15:49
名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
評測資格!
2022年11月,ChatGPT的問世展示了大模型的強大潛能,對人工智能領域有重大意義,并對自然語言處理研究產生了深遠影響,引發了大模型研究的熱潮。
距ChatGPT問世不
發表于 03-11 15:16
上海AI實驗室發布新一代書生·視覺大模型
近日,上海人工智能實驗室(上海AI實驗室)聯手多所知名高校及科技公司共同研發出新一代書生·視覺大模型(InternVL)。
書生?浦語 2.0(InternLM2)大語言模型開源
這個模型在 2.6 萬億 token 的高質量語料基礎上進行訓練,包含 7B 和 20B 兩種參數規格以及基座、對話等版本,以滿足不同復雜應用場景的需求。
發表于 01-19 09:39
?272次閱讀
商湯科技發布新一代大語言模型書生·浦語2.0
1月17日,商湯科技與上海AI實驗室聯合香港中文大學和復旦大學正式發布新一代大語言模型書?·浦語2.0(InternLM2)。





 工商網監
工商網監
評論