 科大訊飛獲國際多通道語音分離與識別大賽CHiME-7冠軍
科大訊飛獲國際多通道語音分離與識別大賽CHiME-7冠軍
前方有好消息傳來!
時隔3年后,國際多通道語音分離和識別大賽CHiME-7再次“上線”。當地時間8月25日,CHiME-7 Workshop在Meta公司都柏林研發中心舉行,官方組委會現場公布了大賽成績:
科大訊飛聯合中科大語音及語言信息處理國家工程研究中心(NERC-SLIP)、國家智能語音創新中心,在參與的多設備多場景遠場語音識別任務(DASR)中獲得全部兩個賽道的第一名。
繼2016年以來參與CHiME-4、CHiME-5、CHiME-6三屆比賽并奪冠后,訊飛聯合團隊堅持技術創新,此次在參與任務主賽道中語音識別錯誤率21%,相比賽事官方給出的基線系統,相對降低了60%以上。連續四屆拿下冠軍、領跑國際競爭對手的同時,科大訊飛在核心源頭技術上也實現了自我突破。
語音識別任務難度加碼!“群雄逐鹿”再領頭
作為有“最難語音識別任務”之稱的語音領域權威賽事,CHiME(Computational Hearing in Multisource Environments)系列比賽發起于2011年,致力于集聚學術界和工業界優秀的學術力量,持續突破語音識別技術水平,不斷在更高噪聲、更高混響、更高對話復雜度的場景下提出具有創新性的解決方案,解決著名的“雞尾酒會問題”,難點在于怎樣在充滿噪聲的雞尾酒會,分辨并聽清多人同時交談的聲音。
參與CHiME-7的團隊高手如云,如中科院聲學所、西北工業大學、劍橋大學、帕德博恩大學、捷克布爾諾理工大學、日本電信NTT、英偉達、俄羅斯STC等國內外知名研究機構、高校和企業。
本次CHiME-7中的語音識別任務由馬爾凱理工大學、卡內基梅隆大學、約翰霍普金斯大學、東京都立大學的學者們共同組織,稱為“多設備多場景遠場語音識別任務(DASR)”。
在CHiME-6的基礎上,CHiME-7進一步提升了難度,不僅在對話場景、麥克風設備類型上進行了擴充,同時要求參賽者只能使用統一的一套算法系統進行測試,這對語音識別系統的魯棒性提出了極高的要求。具體如下:
在考察場景中,擴大了CHiME-6測試集范圍,同時新增加了兩個數據集DiPCo和Mixer 6;
三個數據集分別使用不同的麥克風設備,包含線性陣列、環形陣列、分布式麥克風等;
數據集中多人對話場景更加豐富,除朋友聚會之外還新增了采訪、打電話等場景。
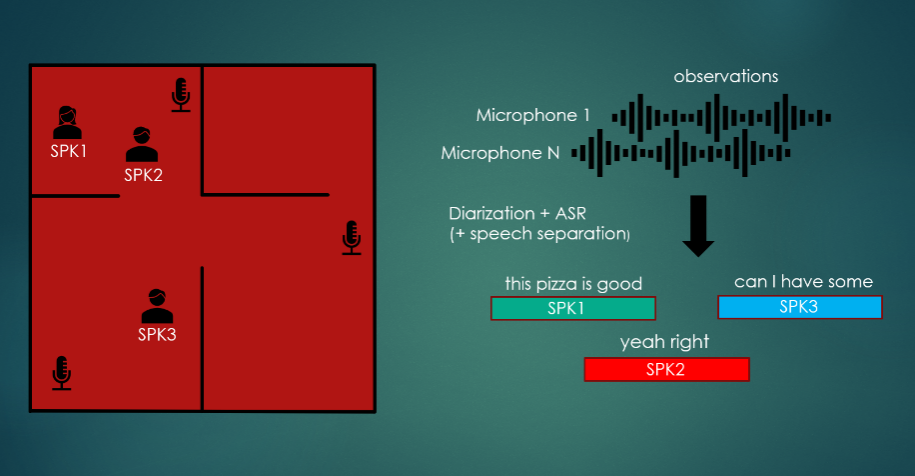
CHiME-7官方給出的任務圖例
該任務分為主賽道(Main Track,默認提交)和子賽道(Sub Track,自由提交),具有很高的挑戰性,也與真實復雜場景中的語音識別要求更為貼近:
主賽道需要首先要完成遠場數據下的說話人角色分離任務,即從連續的多人說話語音中切分出不同說話人片段、判斷出每個片段是哪個說話人,然后再進行語音識別;
子賽道中說話人角色分離的信息是人工標注的,參賽者可以直接使用,在人工分離邊界的基礎上直接進行語音識別。
此次比賽核心考察指標為DA-WER(Diarization Attributed WER),即綜合考察系統對多個說話人的角色分離效果,以及語音識別效果。
科大訊飛聯合團隊參加了所有兩個賽道,在主賽道和子賽道分別以21%和16%語音識別錯誤率拿下雙冠,將真實說話人角色分離情況下的語音識別錯誤率與使用人工標注間的差別控制在5%,這也標志著在實際環境中的應用效果將得到進一步提升。
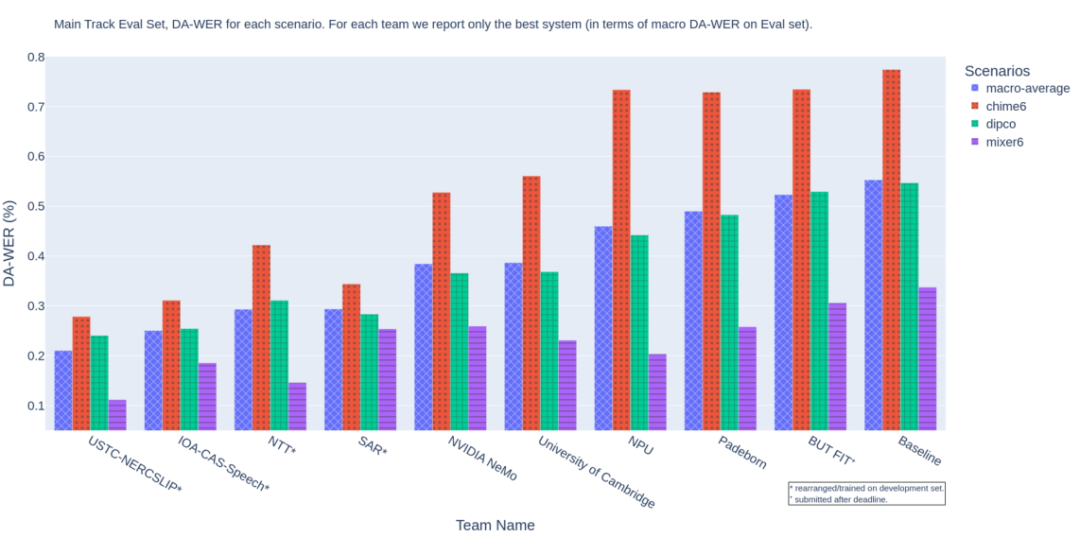
主賽道語音識別成績,排名指標DA-WER取自三個數據集上的平均值,值越低成績越好
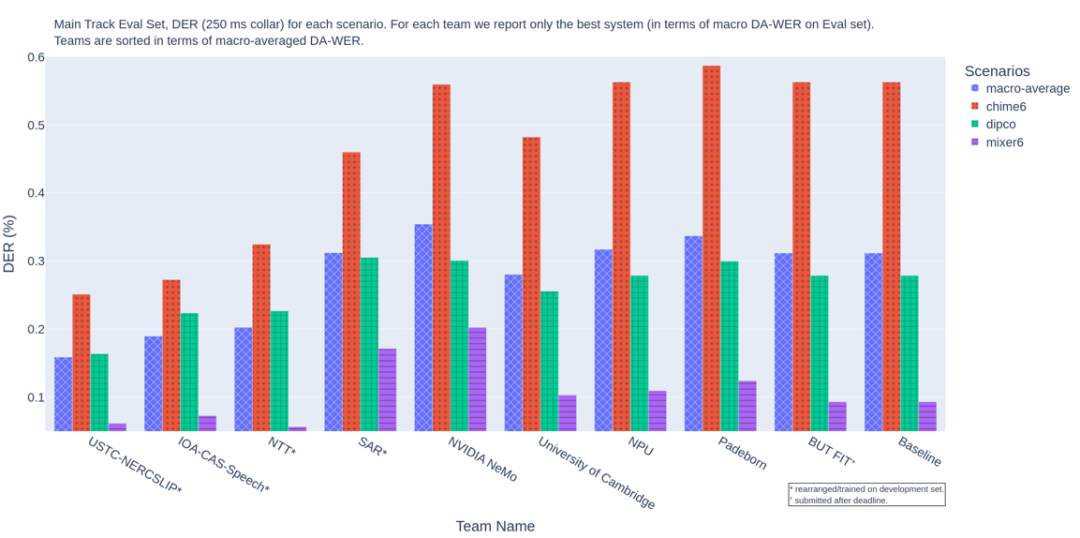
主賽道說話人角色分離成績,排名指標DER代表說話人角色分離錯誤率,值越低成績越好
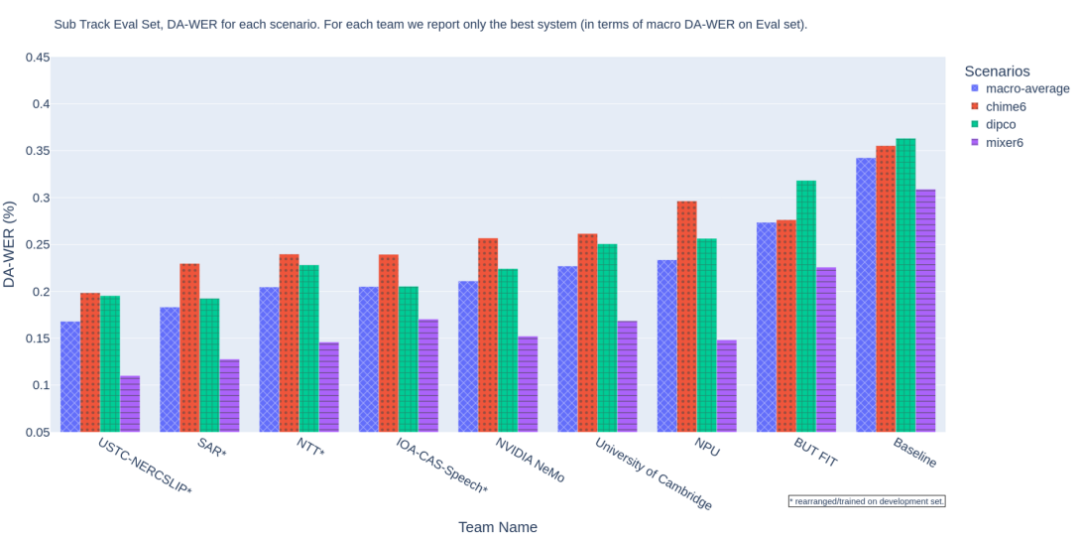
子賽道語音識別成績,排名指標DA-WER取自三個數據集上的平均值,值越低成績越好
面對挑戰,我們的“新招數”有哪些?
如何突破語音交疊、遠場混響與噪聲干擾、隨意的對話風格等重重難關,在更復雜的語音素材里精準實現說話人角色分離和語音識別?
基于長期技術積累,以及訊飛語音識別技術在落地應用中的實踐和反饋,聯合團隊創新并使用了多種技術方法。
基于記憶模塊的多說話人特征神經網絡說話人角色分離算法 (Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding , NSD-MA-MSE)
該方法旨在解決高噪聲、高混響、高說話人重疊段場景的說話人角色分離問題。基于對大規模的說話人聚類得到的類中心向量,團隊設計了一種記憶模塊,可以利用該模塊與當前目標人片段,通過注意力機制計算來得到更加精確的目標說話人特征。整體上,團隊采用序列到序列的方式來預測多個說話人的輸出幀級語音/非語音概率。該模型極大降低了說話人角色分離錯誤率,有效地幫助了后續的分離和識別模塊。
陣列魯棒的通道挑選算法(Array-Robust Channel Selection)
該算法基于波束語音信噪比挑選準則,即使對于不同的陣列分布場景,也能夠自動挑選出有效通道,從而減少下游任務無效噪聲和語音干擾。同時,團隊提出了一種空間-說話人同步感知的迭代說話人角色分離算法(Spatial-and-Speaker-Aware Iterative Diariazation Algorithm,SSA-IDA),通過結合陣列空間建模和機器學習長時建模的優勢,迭代修正說話人角色分離系統中聲學特性相似的說話人錯分情況,從而更加精確捕捉目標說話人的信息。
該算法不僅有效的降低了環境干擾噪聲,而且可以進一步消除干擾說話人的語音,從而大幅降低下游語音識別任務的難度。
場景自適應自監督表征學習方案(Scene Adaptive Self-Supervised Learning Method)
該方案用于匹配復雜場景的語音識別,將經過前端處理后的音頻作為自監督模型的輸入,并提取高層次表征作為指導標簽,實現了對特定場景的快速自適應匹配;同時,結合層級漸進式學習和一致性正則約束,進一步提高了預訓練模型對下游語音識別任務的魯棒性。利用預訓練模型的層級信息進行融合,實現了語音識別在復雜場景的效果提升。
望過去、向未來:更好的AI離不開更好的語音識別
連續四屆獲得CHiME冠軍背后,是科大訊飛在語音識別技術和應用上踏過的漫長之路:
從2010年國內首批開展深度神經網絡語音識別研究,到全球首個中文語音識別深度神經網絡(DNN)上線、循環神經網絡(RNN)語音識別全面升級、全球首創基于全序列卷積神經網絡(DFCNN)的語音識別,近幾年持續探索無監督預訓練、多模態在語音識別上的應用;
從2010年推出語音輸入的訊飛輸入法上線、訊飛語音云發布,到落地教育、醫療、城市、工業、金融、汽車等各行各業,還有面向你我生活學習工作的訊飛翻譯機、智能辦公本、AI學習機、訊飛聽見、錄音筆、智能耳機……
不論是大型國際會議、全球賽事,還是身邊的一通電話、一次詢問,在繁雜的聲音世界里,是持續進化的語音識別技術讓機器更了解我們所言所語。
面向未來,科大訊飛在CHiME-7中的技術成果鏈接著更多的應用可能:
立志于讓機器人走進每個家庭的“訊飛超腦2030”計劃里,似乎可以看到未來人和機器自然交互的新場景。CHiME-7中的技術成果能夠讓機器人面向每個家庭成員實現更精準的語音識別,再加上多模感知、多維表達、認知智能和AI運動智能算法等有機結合,實現系統性創新——家庭陪伴機器人不僅能夠聽清、聽懂每位家庭成員的需求,還能真正做到情感陪伴與日常生活照顧……
**智能語音是萬物互聯機器溝通的入口,也是人工智能賦能千行萬業、浸潤千家萬戶的秘鑰;**智能語音是我們的初心,是載譽的過往和現在,也是燦爛的將來。
審核編輯:劉清
-
機器人
+關注
關注
211文章
28418瀏覽量
207095 -
信噪比
+關注
關注
3文章
260瀏覽量
28628 -
語音識別
+關注
關注
38文章
1739瀏覽量
112659 -
深度神經網絡
+關注
關注
0文章
61瀏覽量
4527
原文標題:四連冠!科大訊飛獲國際多通道語音分離與識別大賽CHiME-7冠軍
文章出處:【微信號:iFLYTEK1999,微信公眾號:科大訊飛】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
科大訊飛發布訊飛星火4.0 Turbo大模型及星火多語言大模型
科大訊飛發布訊飛星火4.0 Turbo:七大能力超GPT-4 Turbo
科大訊飛AI總部園區正式啟用
科大訊飛發布智能辦公本Air 2
科大訊飛AI學習機暑期重磅升級
科大訊飛發布“訊飛星火V3.5”:基于全國產算力訓練的全民開放大模型

舒適打字體驗與強大功能合一:科大訊飛AI智能鍵盤D1的優勢解析
科技創新與智能助力:揭秘科大訊飛智能鍵盤D1的獨特魅力

科大訊飛AI機械鍵盤D1的前瞻性設計:告別傳統,迎接智能化時代






 工商網監
工商網監
評論