 流浪者緩解PyTorch DDP的層次SGD
流浪者緩解PyTorch DDP的層次SGD
羅漢·瓦爾馬(梅塔·艾)
PyTork DDP 點火 DDP該技術的性能對于模型勘探期間的快速迭代以及資源和成本節約至關重要。該技術的性能對于模型開發和勘探的快速迭代和成本節約至關重要。為了解決大規模培訓中慢節點引入的無處不在的性能瓶頸問題,巡航和梅塔公司共同開發了一個基于此解決方案的解決方案。SGD 等級式 SGD算法可以大大加速訓練 在有這些累贅者在場的情況下
減少斯特拉格勒公司的必要性
在 DDP 設置中,當一個或多個流程運行比其他流程慢得多時,可能會出現累贅問題(“累贅者 ” ) 。 如果發生這種情況,所有流程都必須等待累贅者,然后才能同步梯度和完成通信,而通信的瓶頸基本上將業績分配給了最慢的工人。 因此,即使培訓相對較小的模型,通信成本也可能是一個主要的性能瓶頸。
Stragglers 的潛在原因
在同步之前,工作量不平衡通常會造成嚴重的累贅問題,許多因素可能促成這種不平衡。 比如,在分布環境中,一些數據載荷工人可能會成為累贅者,因為某些輸入實例在數據大小方面可能出乎意料,或者由于網絡一/O不穩定,一些實例的數據傳輸可能大大放緩,或者在飛行數據轉換成本可能有很大差異。
除數據加載外,梯度同步之前的其他階段還可能造成累贅,例如,在建議系統中的前端路過時,嵌入表格的查尋工作量不平衡。
Stragglers 外觀
如果我們剖析 DDP 培訓有累加器的工作, 我們就會發現有些過程的梯度同步成本( a.k.a., 全部降低梯度) 可能比其它過程高得多。 因此, 分布式的性能可以以通信成本為主, 即使模型大小很小 。 在這種情況下, 有些過程的運行速度比拖累器的步數快, 因此它們必須等待拖累器, 并且花費更長的時間來進行減速 。
以下顯示 PyTorrch 剖析器在使用案例中輸出的兩個追蹤文件的截圖。 每個截圖剖析圖分立為 3 步 。
第一個截圖顯示,一個過程在第一和第二步都有非常高的削減成本,因為這個過程比排減速器提前到達同步階段,而且要花更多的時間等待。另一方面,在第二步,削減成本相對較低,這意味著:(1) 這一步沒有排減速器;或者(2) 這個過程是所有過程的排減速度,因此它不必等待任何其他過程。
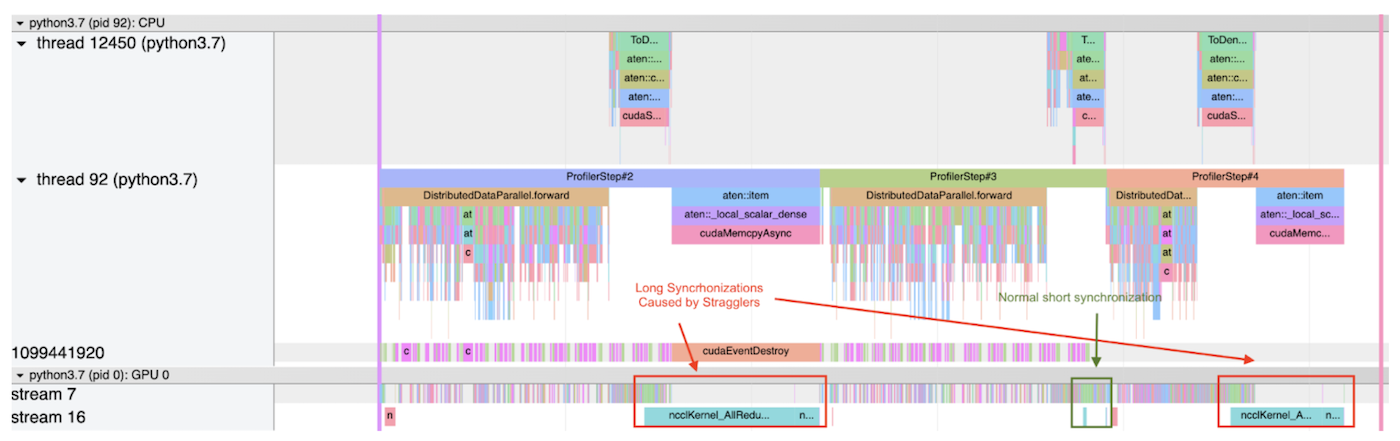
第一步和第三步 都被斯特拉格勒人拖慢了
第二個截圖顯示一個正常的大小寫, 不帶斜體。 在此情況下, 所有梯度同步都相對短 。
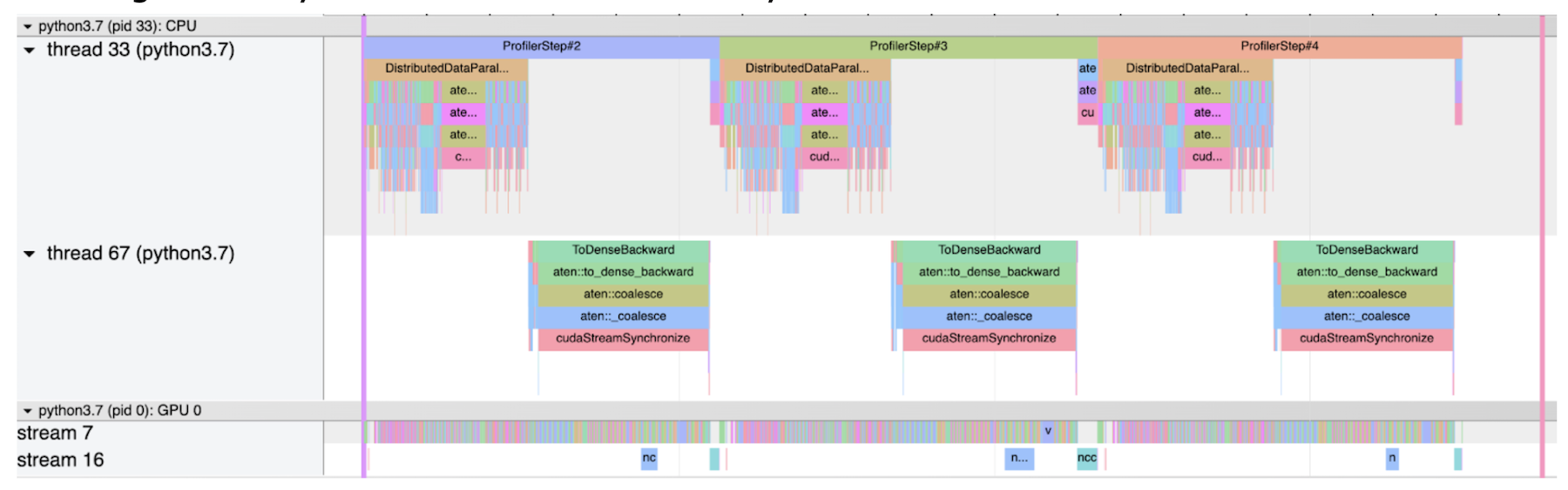
普通無斯特拉格器的普通大小寫
PyTorch 中的等級 SGD
最近,已提議通過減少大規模分布式培訓中的數據傳輸總量,優化通信成本,并提供了多重趨同分析,從而優化了通信成本(最近,SGD等級結構已提議通過大規模分布式培訓減少數據傳輸總量)。示例示例示例作為這一職位的主要新穎之處,在游輪上,我們可以利用SGD等級來減輕拖拉機,這也可能發生在培訓相對較小的模型上,2022年初,我們通過游輪到皮托爾奇執行。
等級制的SGD如何運作?
正如名稱所暗示的那樣,SGD等級將所有過程按等級劃分為不同層次的分組,并按以下規則同步進行:
同一級別的所有組組都有相同數量的流程,這些組的流程同步同步,同步期由用戶預先確定。
較高層次的一組是,使用較大的同步期,因為同步越來越昂貴。
當多個重疊組應該按照各自時期同步時,為了減少冗余同步和避免不同組間的數據競賽,只有最高層組可以同步。
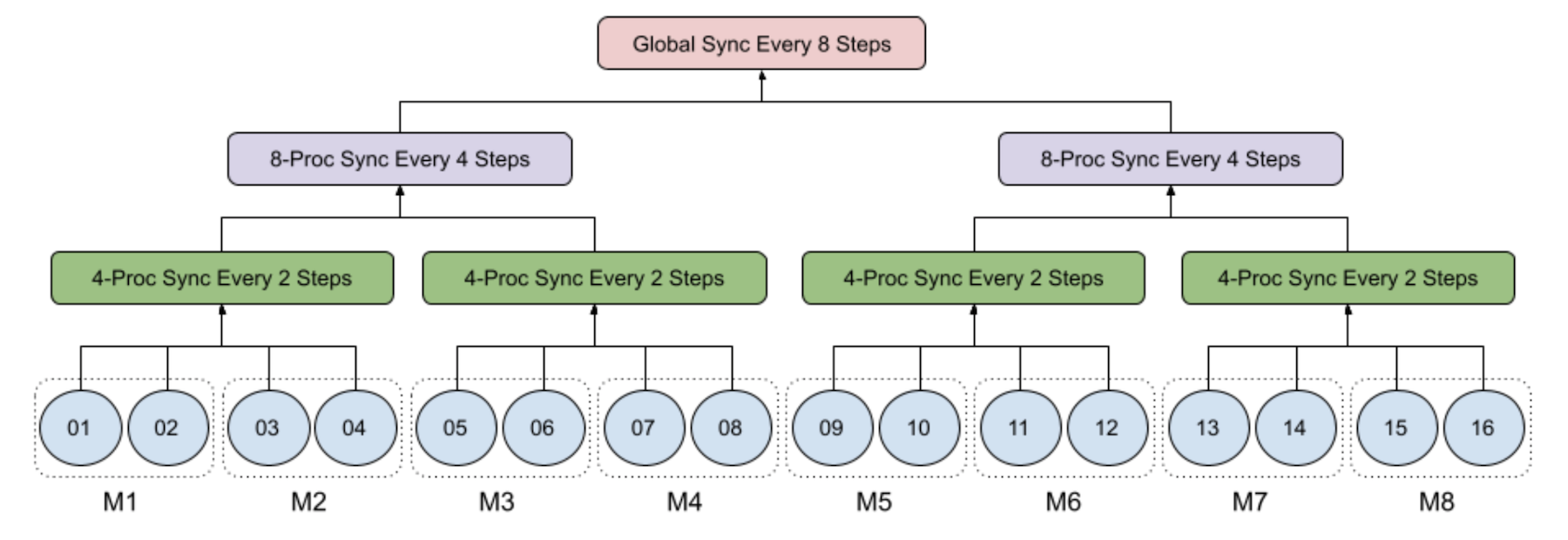
下圖舉例說明了8臺機器的16個工藝中4級級的SGD,每臺有2個GPU:
1級:1級:每個過程都在當地經營小型批次的SGD;
第2級:每兩臺機器的4-處理小組每兩臺機器每兩步同步;
第3級:每四臺機器每組8-處理8個程序,每四步同步;
4級:全球流程組由所有16個流程組成,超過8臺機器每8個步驟同步運行。
特別是,當步數除以8時,只執行3時的同步,而當步數除以4而不是8時,只執行2時的同步。
從直覺上看,可以將SGD等級視為本地 SGD只有兩級等級 — — 每一個過程都在當地運行小型批次 SGD , 然后以一定頻率同步全球。 這也可以幫助解釋一下,就像本地 SGD 一樣,等級 SGD 同步模型參數而不是梯度。 否則,當頻率大于1時,梯度下降在數學上是不正確的。
為什么分級的SGD SGD Mipigate Stragglers 能夠?
這里的關鍵洞察力是,當有一個隨機的減速器時,它只會直接減慢相對較少的一組進程,而不是所有進程。 下一次,另一個隨機的減速器很可能減慢另一組不同的小組,因此,一個等級可以幫助平滑減速效應。
下面的例子假設每步有8個流程中有一個隨機的分隔符。 在4個步驟后, 運行同步 SGD 的香草 DDP 會被排縮 4 次, 因為它每步都運行全球同步 。 相反, 等級 SGD 在前兩步后與四組流程同步, 然后在后兩步后與四組流程同步。 我們可以看到前兩步和最后兩步都有很大的重疊, 從而可以減少性能損失 。
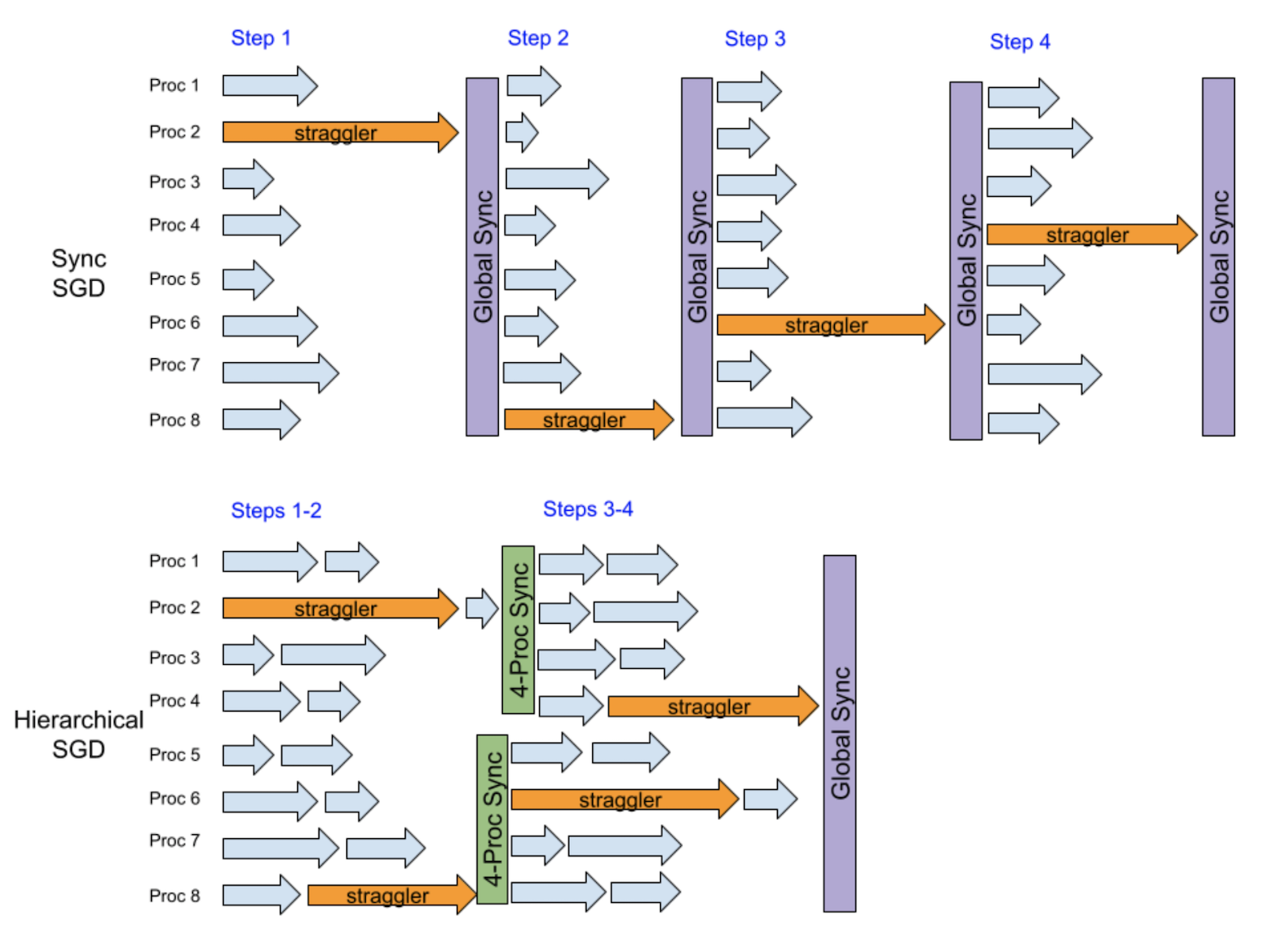
基本上,這一等級的SGD實例的緩解效應實際上是在每兩個步驟的頻率和每四個步驟的頻率之間,地方的SGD相對于地方的SGD的主要優勢是同一全球同步頻率的更好趨同效率,因為等級的SGD允許更低層次的同步。此外,等級的SGD有可能提供比地方的SGD低的同步頻率,并具有模型等同性,從而導致更高的培訓業績,特別是在大規模分布式培訓中。
使用范圍
減少斯特拉格勒排放量并不是在分布式培訓中進行的一項新研究。Galk SGD八八八流, 數據編碼, 梯度編碼,以及某些特別設計的參數-服務器結構,包括:后備工人和平平同步平行然而,據我們所知,在這項努力之前,我們還沒有找到一個良好的開放源碼PyTorch(開放源碼PyTorch)的緩解拖拉機的功能,可以像我們游輪培訓系統的插件一樣運作。相反,我們的實施只需要最小的修改 — — 不需要修改現有的代碼或調整現有的任何超參數。這對工業用戶來說是一個非常有吸引力的優勢。
如下面的代碼示例所示,DDP模式的設置只需要增加幾行,培訓循環代碼可以保持不動。 如前所述,SGD等級是本地 SGD 的擴大形式,因此增強功能可以與本地 SGD 相當相似(見PyTorch docs,2003年)。后 postlocalsg 噴霧器):
注冊一個本地的 SGD 后通信鉤,以運行一個同步的 SGD 和推遲級別 SGD 的熱級階段。
創建后本地 SGD 優化器, 將現有的本地優化器和等級 SGD 配置包起來 。
發件人: 發件人: 發件人: 發件人: 發件人: 發件人: 發件人: 發件人: 發件人: 發件人: 發件人: 發件人:
高分數計
等級SGD有兩個主要的超強參數:周期_ 群群大小_ dict和暖化步驟.
周期_ 群群大小_ dict命令從同步期到處理組大小的字典繪圖,用于在等級體系中初始化不同大小的流程組,以同時同步參數。預計較大組將使用較大的同步期。
暖化步驟指定一些步驟作為在 SGD 等級前同步 SGD 運行的熱級階段。 類似之后的本地 SGD運算算法,通常建議一個暖化階段,以達到更高的精度。開始日期(_localsgd_iter)用于后 本地 國家當 post_ localSGD_hook 注冊時。 通常在損失急劇減少時, 熱身階段至少應覆蓋培訓開始階段 。
PyTorrch 實施與相關文件提出的初步設計之間的一個微妙區別是,在暖化階段之后,每個東道主內部的流程默認仍然每一步都運行東道主內部的梯度同步。 這是因為:
東道方內部通信相對便宜,通常能夠大大加快趨同速度;
東道方內部組(對于大多數行業用戶來說,規模為4或8)通常可以很好地選擇最經常同步的最小流程組。 如果同步期為1, 則梯度同步比模型參數同步(a.k.a., 平均模型)要快, 因為 DDP 自動重疊梯度同步和后傳。
這種東道方內部梯度同步可因不設置而禁用員額(_L) 本地_ 梯度_ 全部減少參數以后 本地 國家.
演示演示
現在,我們證明,SGD等級可以通過減輕累贅來加快分散培訓。
實驗設置
我們比較了SGD等級與當地SGD等級與SGD等級與SGD等級與SGD等級的成績,并比較了SGD等級與重新發送18由于模型太小,培訓不會因同步期間的數據傳輸成本而受阻。 為了避免從遠程存儲中輸入數據時產生的噪音,輸入數據是從內存中隨機模擬的。 我們把培訓使用的GPU數量從64個增加到256個。 每個工人的批量規模為32個,而培訓的迭代數量是1,000個。 由于我們不評估這一組實驗的趨同效率,因此無法進行暖化。
我們還以128個和256個GPU和64個GPU的比例1%和2%的速率模仿了擠壓器,以確保平均每個步驟至少有一個壓壓壓器。這些壓壓器隨機出現在不同的 CUDA 設備上。每個壓壓壓器在正常的單步訓練時間之外再拖延1秒( 在我們的設置中為~ 55米 ) 。 這可以被視為一種實際的情景,其中1%或2%的輸入數據在培訓期間在數據處理費用( I/O 和/或蒼蠅的數據轉換)方面出局,而這種費用比平均數高20x。
下面的代碼片段顯示了如何在訓練循環中模仿一個拖拉機。 我們將其應用到 ResNet 模型中, 它也可以很容易地應用到其他模型中 。
損失 = 損失 fn(y_pred, y)
每臺機器有4臺NVIDIA Tesla T4GPU,每臺GPU有16GB內存,通過32Gbit/sepernet網絡連接,每臺都裝有96個VCPU,360GB RAM。
| 結構架構架構 | 重新發送18(450MB) |
| 工人 工人 | 64、128、256 |
| 后端 | nccc 單位 |
| gpu | Tesla T4, 16 GB內存 |
| 批批批量大小 | 32x 32 x |
| Straggler 期限 | 1 秒 1 秒 |
| Straggler 率 | 128個和256個GPU的1%,64個GPU的2% |
本地SGD和等級 SGD使用多種配置。 本地SGD每2、4和8個步驟分別運行全球同步。
我們用以下配置來管理SGD的等級結構:
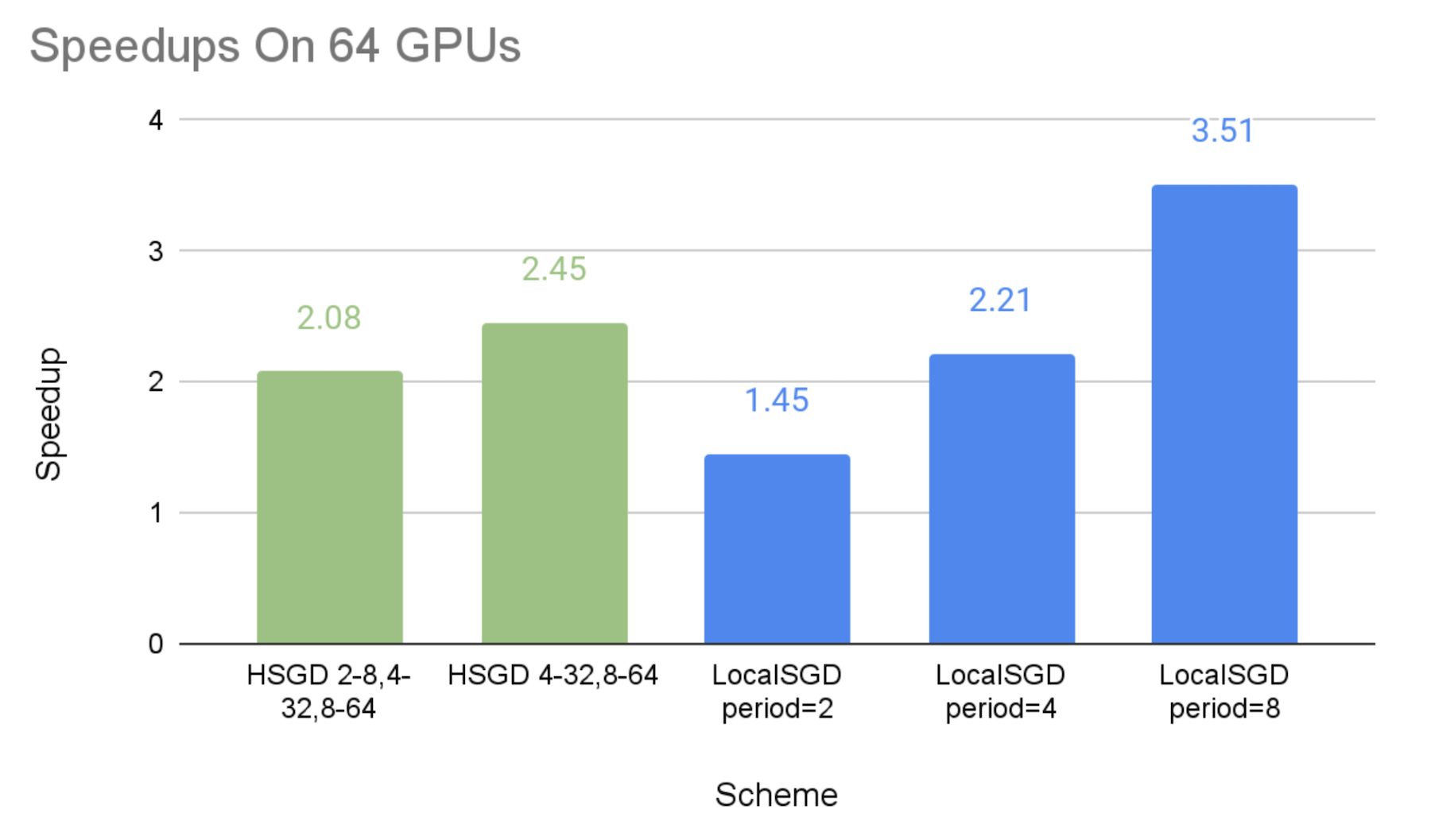
64 GPUs:
8-處理組、32-處理組和全球64-處理組分別每2、4和8個步驟同步。HSGD 2-8,4-32,8-64”.
每個32個處理組和全球64個處理組分別每4個和8個步驟同步。HSGD 4-32,8-64”.
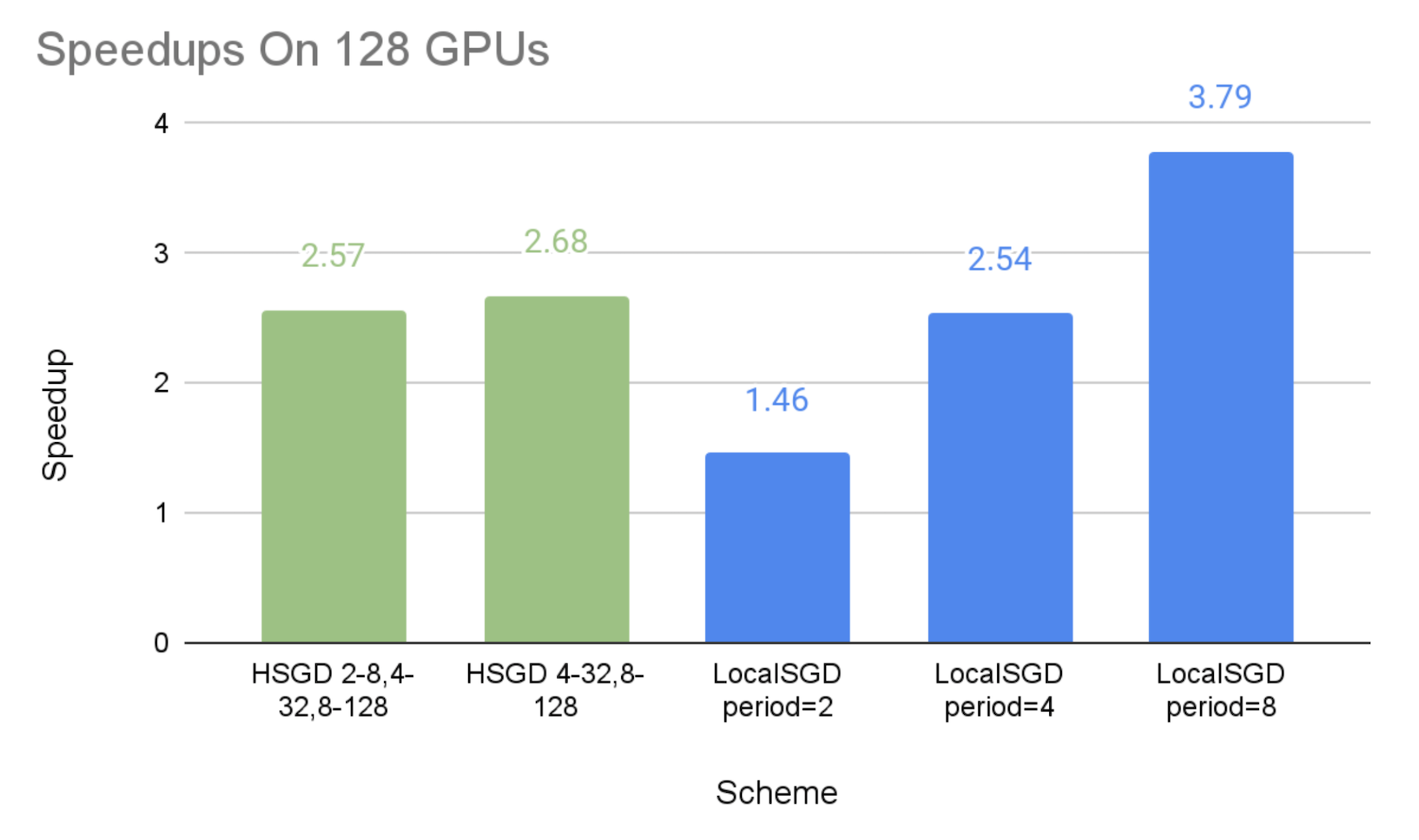
在128個GPUs上:
8-處理組、32-處理組和全球128-處理組的每個8-處理組、32-處理組和全球128-處理組分別每2、4和8個步驟同步。SGSGD 2-8,4-32,8-128”.
每個32個處理組和全球128個處理組分別每4個和8個步驟同步。HSGD 4-32,8-128”.
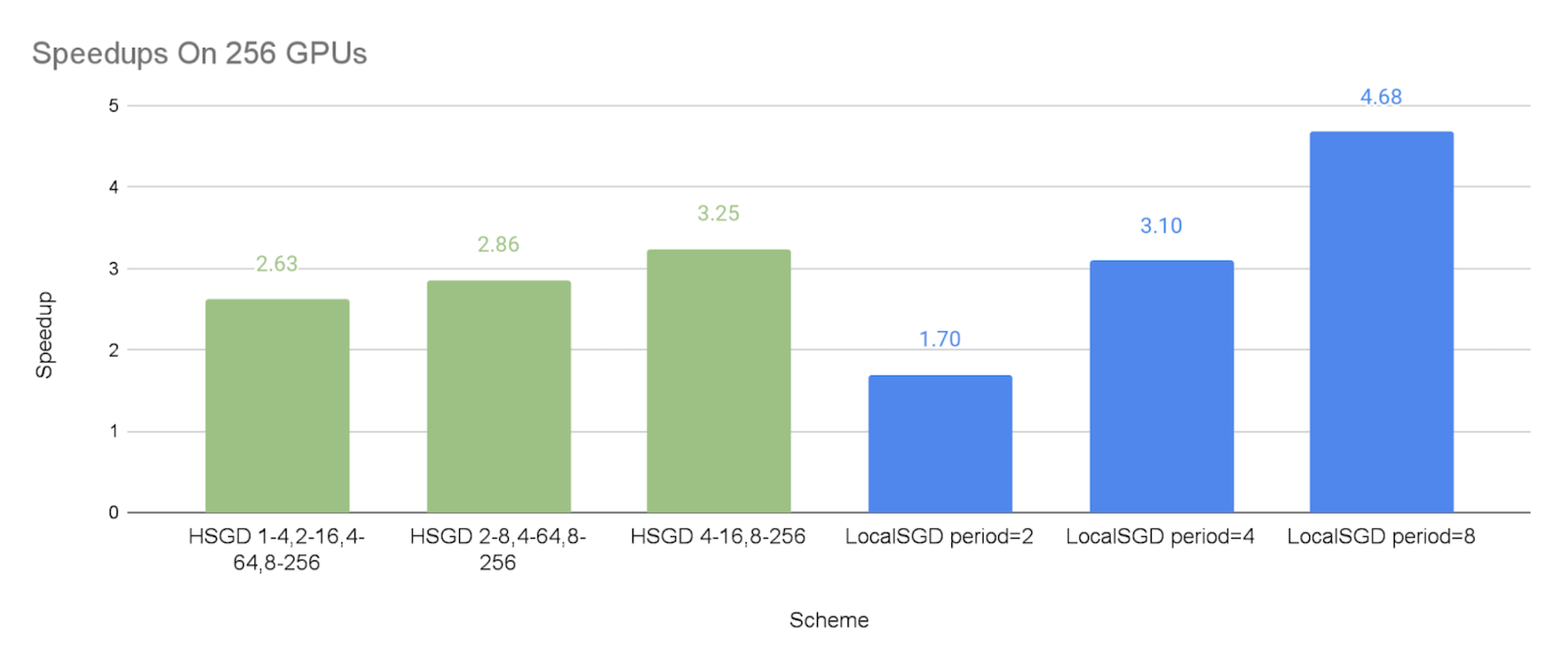
在256個GPUs上:
每個4-處理組、16-處理組、64-處理組和全球256-處理組分別每1、2、4和8個步驟同步一次。1,4,2,16,4,64,8,256”.
8-處理組、64-處理組和全球256-處理組每2、4和8個步驟同步。SGSGD 2-8,4-64,8-256”.
每16個處理組和全球256個處理組分別每4個和8個步驟同步。HSGD 4-16,8-256”.
實驗結果
下圖顯示了不同通信計劃相對于同步的 SGD 基線,與效仿的施壓者相比的加速速度。
如預期的那樣,我們可以看到,SGD等級和當地SGD能夠以較低的同步頻率加快速度。
SGD等級制度的加速實施是:2.08x-2.45x64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,2.57x-2.68x在128個GPUs,和2.63x-3.25x這表明,等級分級的SGD可以大大減輕排擠因素,而這種緩解在更大的規模上可以更加有效。
當地SGD的性能與同步期分別為2個步驟和8個步驟,這可被視為試驗的SGD等級制度下限和上限,這是因為,SGD等級制度比全球每2個步驟同步的頻率要低,但與全球同步期每8個步驟相比,其在小集團的低水平同步是額外的間接費用。
總體來說,SGD等級可以比當地SGD在通信成本和模式質量之間提供比當地SGD更好的權衡。 因此,如果當地SGD在8或4等相當大的同步期不能帶來令人滿意的趨同效率,SGD等級可以有更好的機會實現良好的速度和模式對等。
由于試驗中只使用模擬數據,我們沒有在這里證明模型對等,在實踐中可以通過以下兩種方式實現:
包括等級制和暖化步驟在內的超參數;
在某些情況下,等級級的SGD可能導致與原有模式相比,相同數量的培訓步驟的質量略低(即,趨同率較低),但是,如果每步培訓的速度加快到2X,仍然有可能以更多的步驟實現模式對等,但總培訓時間更小。
限制
在應用SGD等級來緩解排減因素之前,用戶應認識到這種方法的一些局限性:
這種方法只能緩解不同工人在不同時期遇到的非持久性阻力因素。 但是,對于長期性阻力因素,因為硬件退化或特定主機的網絡問題可能造成這種阻力因素,這些阻力因素會每次都減緩同一個低層次分組的速度,導致幾乎沒有緩解阻力因素。
這種方法只能緩解低頻排減器。 例如,如果30%的工人可以隨機地在每一步中成為排減器,那么大多數低級同步器仍會因排減器而放慢速度。 結果,SGD等級的SGD可能不會顯示出相對于同步的 SGD的明顯性能優勢。
由于SGD適用的平均模式與香草 DDP使用的向后偏差一樣,與后向不重疊,其平均模式與香草 DDP使用的向后偏差相同,因此,由于通信和后向通行證之間沒有重疊的性能損失,SGD的性能增益必須大于其性能損失。 因此,如果遞減者只慢慢了不到10%的培訓,SGD的等級可能無法加快速度。 這一限制可以解決。overlapping optimizer step和backward pass未來。
由于SGD等級比當地SGD受到的研究要少,因此不能保證具有精細的同步同步顆粒特性的SGD等級比當地SGD某些先進形式的SGD(例如:慢速然而,據我們所知,這些先進的算法還不能作為PyTorrch DDP插件(如SGD等級插件)得到本地的支持。
承認的確認
我們要感謝巡游隊的隊友寶天, 謝爾蓋·沃羅貝夫, 尤金·塞利文奇克、李宣賢, 丹環, 伊恩·阿克曼, 陳李立, 瑪根·朱麥根, 越南 Anh To, 龍小輝, 陳世玉, 亞歷山大·西多羅夫, 伊戈爾·茨韋特科夫, 胡信胡, 馬納夫·卡塔利亞, 瑪麗娜·魯布佐娃, 和穆罕默德·法瓦茲以及Meta隊友沈力、趙延利、蘇拉伊·蘇布拉馬尼揚、哈米德·舒詹澤里、安賈利·斯里達爾和伯納德·阮支持。
審核編輯:湯梓紅
-
算法
+關注
關注
23文章
4623瀏覽量
93110 -
pytorch
+關注
關注
2文章
808瀏覽量
13283
發布評論請先 登錄
相關推薦
直流浪涌保護器與交流浪涌保護器的區別和作用

JRCS工控機SGD-640-K7-2C維修,JRCS顯示屏維修案例
視頻解碼芯片DDP3310B電子資料
流浪寵物疫情監控系統的設計資料分享
通過Cortex來非常方便的部署PyTorch模型
什么是聲卡DDP電路/聲卡杜比定邏輯技術
Pytorch入門教程與范例
人臉識別助力為流浪者找到親人 應用越發廣泛
基于區塊鏈技術的文檔處理遷移平臺MIGRANET介紹
DDP442X ASIC組件及其應用程序編程接口的詳細資料描述





 工商網監
工商網監
評論