 谷歌Gemini被曝算力達GPT-4五倍,手握TPU王牌碾壓OpenAI
谷歌Gemini被曝算力達GPT-4五倍,手握TPU王牌碾壓OpenAI
手中沒有足夠GPU的人,在商業化戰爭中鐵定出局。
著名的SemiAnalysis分析師Dylan Patel和Daniel Nishball,又來爆料行業內幕了。而整個AI社區,再次被這次的消息所震驚:OpenAI的算力比起谷歌來,只能說是小兒科——谷歌的下一代大模型Gemini,算力已達GPT-4的5倍!

根據Patel和Nishball的說法,此前屢屢被爆料將成為GPT-4大殺器的谷歌Gemini,已經開始在新的TPUv5 Pod上進行訓練了,算力高達~1e26 FLOPS,比訓練GPT-4的算力還要大5倍。如今,憑借著TPUv5,谷歌已經成為了算力王者。它手中的TPUv5數量,比OpenAI、Meta、CoreWeave、甲骨文和亞馬遜擁有的GPU總和還要多!雖然TPUv5在單芯片性能上比不上英偉達的H100,但谷歌最可怕的優勢在于,他們擁有高效、龐大的基礎設施。沒想到,這篇爆料引來Sam Altman圍觀,并表示,「難以置信的是,谷歌竟然讓那個叫semianalysis的家伙發布了他們的內部營銷/招聘圖表,太搞笑了。 」

有網友卻表示,這僅是一篇評論性文章,并非實際新聞,完全是推測。

不過,此前Dylan Patel參與的兩篇稿件,無一例外都被證實,并且引發了業內的軒然大波。無論是谷歌的內部文件泄漏事件(「我們沒有護城河,OpenAI也沒有」)——

谷歌DeepMind的首席執行官Demis Hassabis在一次采訪中確認了谷歌護城河的真實性
還是GPT-4的架構、參數等內幕消息大泄密——

下面讓我們來仔細看看,這次的爆料文章,又將帶來多少重磅內幕消息。
沉睡的巨人谷歌已經醒來
提出Transformer開山之作「Attention is all you need」的作者之一、LaMDA和PaLM的關鍵參與者Noam Shazeer,曾受MEENA模型的啟發,寫過一篇文章。
在這篇文章里,他準確地預言了ChatGPT的誕生給全世界帶來的改變——LLM會越來越融入我們的生活,吞噬全球的算力。這篇文章遠遠領先于他的時代,但卻被谷歌的決策者忽略了。

論文地址:https://arxiv.org/pdf/2001.09977.pdf
現在,谷歌擁有算力王國所有的鑰匙,沉睡的巨人已經醒來,他們的向前迭代的速度已經無法阻擋,在2023年底,谷歌的算力將達到GPT-4預訓練FLOPS的五倍。而考慮谷歌現在的基建,到明年年底,這個數字或許會飆升至100倍。谷歌是否會在不削減創造力、不改變現有商業模式的基礎上在這條路上繼續深耕?目前無人知曉。
「GPU富豪」和「GPU窮人」
現在,手握英偉達GPU的公司,可以說是掌握了最硬的硬通貨。OpenAI、谷歌、Anthropic、Inflection、X、Meta這些巨頭或明星初創企業,手里有20多萬塊A100/H100芯片,平均下來,每位研究者分到的計算資源都很多。
個人研究者,大概有100到1000塊GPU,可以玩一玩手頭的小項目。

CoreWeave已經拿英偉達H100抵押,用來買更多GPU
而到2024年底,GPU總數可能會達到十萬塊。現在在硅谷,最令頂級的機器學習研究者自豪的談資,就是吹噓自己擁有或即將擁有多少塊GPU。在過去4個月內,這股風氣越刮越盛,以至于這場競賽已經被放到了明面——誰家有更多GPU,大牛研究員就去哪兒。Meta已經把「擁有世界上第二多的H100 GPU」,直接拿來當招聘策略了。

與此同時,數不清的小初創公司和開源研究者,正在為GPU短缺而苦苦掙扎。因為沒有足夠虛擬內存的GPU,他們只能虛擲光陰,投入大量時間和精力,去做一些無關緊要的事。他們只能在更大的模型上來微調一些排行榜風格基準的小模型,這些模型的評估方法也很支離破碎,更強調的是風格,而不是準確性、有用性。他們也不知道,只有擁有更大、更高質量的預訓練數據集和IFT數據,才能讓小開源模型在實際工作負載中得到改進。

「誰將獲得多少H100,何時獲得H100,都是硅谷現在的頂級八卦。」OpenAI聯合創始人Andrej Karpathy曾經這樣感慨
是的,高效使用GPU很重要,許多GPU窮人把這一點忽視了。他們不關心規模效應的效率,也沒有有效利用自己的時間。到明年,世界就會被350萬H100所淹沒,而這些GPU窮人,將徹底與商業化隔絕。他們只能用手中的游戲用GPU來學習、做實驗。大部分GPU窮人仍然在使用密集模型,因為這就是Meta的Llama系列模型所提供的。如果不是扎克伯格的慷慨,大部分開源項目會更糟。如果他們真的關心效率,尤其是客戶端的效率,他們會選擇MoE這樣的稀疏模型架構,并且在更大的數據集上進行訓練,并且像OpenAI、Anthropic、Google DeepMind這樣的前沿LLM實驗室一樣,采用推測解碼。
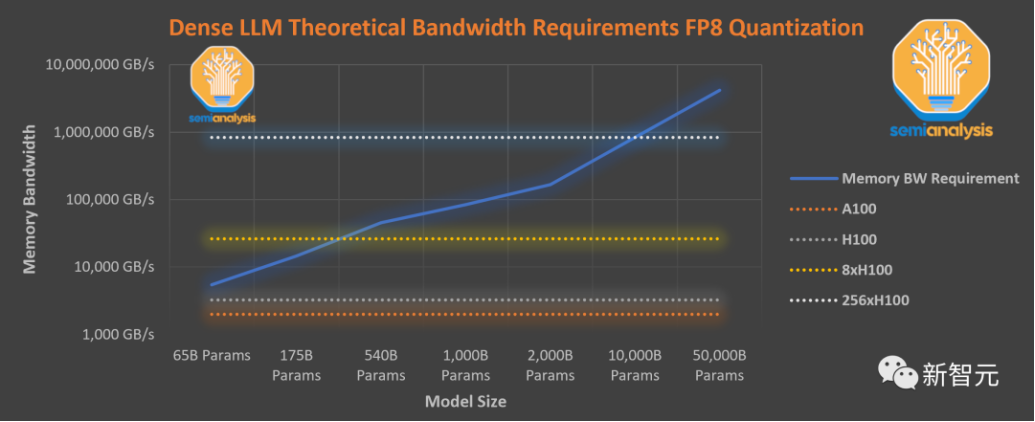
此圖表假設,無法融合每個操作、注意力機制所需的內存帶寬、硬件開銷相當于參數讀取,都會導致效率低下。實際上,即使使用優化的庫,比如英偉達的FasterTransformer庫,總開銷甚至還會更大
處于劣勢的公司應該把重點放在提高模型性能或減輕token到token延遲上,提高計算和內存容量要求,減少內存帶寬,這些才是邊緣效應所需要的。他們應該專注于在共享基礎架構上高效地提供多個微調模型,而不必為小批量模型付出可怕的成本代價。然而,事實卻恰恰相反,他們卻過于關注內存容量限制或量化程度太高,卻對模型實際質量的下降視而不見。總的來說,現在的大模型排行榜,已經完全亂套了。雖然閉源社區還有很多人在努力改進這一點,但這種開放基準毫無意義。出于某種原因,人們對LLM排行榜有一種病態的癡迷,并且為一些無用的模型起了一堆愚蠢的名字,比如Platypus等等。在以后,希望開源的工作能轉向評估、推測解碼、MoE、開放IFT數據,以及用超過10萬億個token清洗預訓練數據,否則,開源社區根本無法與商業巨頭競爭。
現在,在大模型之戰的世界版圖已經很明顯:美國和中國會持續領先,而歐洲因為缺乏大筆投資和GPU短缺已經明顯落后,即使有政府支持的超算儒勒·凡爾納也無濟于事。而多個中東國家也在加大投資,為AI建設大規模基礎設施。
當然,缺乏GPU的,并不只是一些零散的小初創企業。即使是像HuggingFace、Databricks(MosaicML),以及Together這種最知名的AI公司,也依然屬于「GPU貧困人群」。事實上,僅看每塊GPU所對應的世界TOP級研究者,或者每塊GPU所對應的潛在客戶,他們或許是世界上最缺乏GPU的群體。雖然擁有世界一流的研究者,但所有人都只能在能力低幾個數量級的系統上工作。雖然他們獲得了大量融資,買入了數千塊H100,但這并不足以讓他們搶占大部分市場。
你所有的算力,全是從競品買的
在內部的各種超級計算機中,英偉達擁有著比其他人多出數倍的GPU。其中,DGX Cloud提供了預訓練模型、數據處理框架、向量數據庫和個性化、優化推理引擎、API以及英偉達專家的支持,幫助企業定制用例并調整模型。
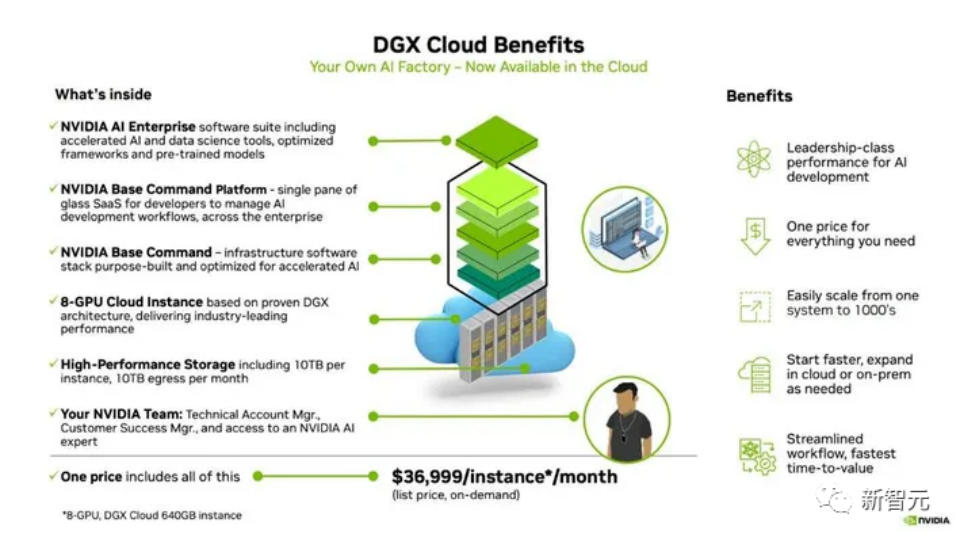
如今,這項服務也已經吸引了來自SaaS、保險、制造、制藥、生產力軟件和汽車等垂直行業的多家大型企業。即便是不算上那些未公開的合作伙伴,僅僅是由安進(Amgen)、Adobe、CCC、ServiceNow、埃森哲(Accenture)、阿斯利康(AstraZeneca)、蓋蒂圖片社(Getty Images)、Shutterstock、晨星(Morningstar)、Evozyne、Insilico Medicine、Quantiphi、InstaDeep、牛津納米孔(Oxford Nanopore)、Peptone、Relation Therapeutics、ALCHEMAB Therapeutics和Runway等巨頭組成的這份比其他競爭對手要長得多的名單,就已經足夠震撼了。考慮到云計算的支出和內部超級計算機的建設規模,企業從英偉達這里購買的似乎比HuggingFace、Together和Databricks所能夠提供的服務加起來還要多。
作為行業中最有影響力的公司之一,HuggingFace需要利用這一點來獲得巨額投資,建立更多的模型、定制和推理能力。但在最近一輪的融資中,過高的估值讓他們并沒有得到所需的金額。Databricks雖然可以憑借著數據和企業關系迎頭趕上。但問題在于,如果想要為超過7,000個客戶提供服務,就必須將支出增加數倍。不幸的是,Databricks無法用股票來購買GPU。他們需要通過即將開始的私募/IPO來進行大規模融資,并進一步用這些現金來加倍投資于硬件。從經濟學的角度來看有些奇怪,因為他們必須先建設,然后才能引來客戶,而英偉達同樣也在為他們的服務一擲千金。不過,這也是參與競爭的前提條件。
這里的關鍵在于,Databricks、HuggingFace和Together明顯落后于他們的主要競爭對手,而后者又恰好是他們幾乎所有計算資源的來源。也就是說,從Meta到微軟,再到初創公司,實際上所有人都只是在充實英偉達的銀行賬戶。那么,有?能把我們從英偉達奴役中拯救出來嗎?是的,有?個潛在的救世主——谷歌。
谷歌算?之巔,OpenAI不及一半
雖然內部也在使用GPU,但谷歌的手中卻握著其他「王牌」。其中,最讓業界期待的是,谷歌下一代大模型Gemini,以及下一個正在訓練的迭代版本,都得到了谷歌無以倫比的高效基礎設施的加持。
早在2006年,谷歌就開始提出了構建人工智能專用基礎設施的想法,并于2013年將這一計劃推向高潮。他們意識到,如果想大規模部署人工智能,就必須將數據中心的數量增加一倍。因此,谷歌開始為3年后能夠投入生產的TPU芯片去做準備。最著名的項目Nitro Program在13年發起,專注于開發芯片以優化通用CPU計算和存儲。主要的目標是重新思考服務器的芯片設計,讓其更適合谷歌的人工智能計算工作負載。自2016年以來,谷歌已經構建了6種不同的AI芯片,TPU、TPUv2、TPUv3、TPUv4i、TPUv4和TPUv5。谷歌主要設計這些芯片,并與Broadcom進行了不同數量的中后端協作,然后由臺積電生產。TPUv2之后,這些芯片還采用了三星和SK海力士的HBM內存。
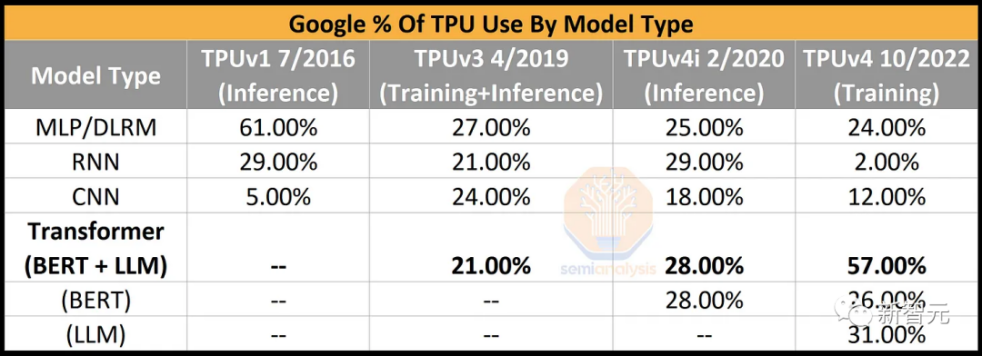
在介紹Gemini和谷歌的云業務之前,爆料者先分享了關于谷歌瘋狂擴張算力的一些數據——各季度新增加的?級芯?總數。對于OpenAI來說,他們擁有的總GPU數量將在2年內增加4倍。而對于谷歌來說,所有人都忽視了,谷歌擁有TPUv4(PuVerAsh)、TPUv4 lite,以及內部使?的GPU的整個系列。此外,TPUv5 lite沒有在這里算進去,盡管它可能是推理較?語?模型的主?。如下圖表中的增長,只有TPUv5(ViperAsh)可視化。
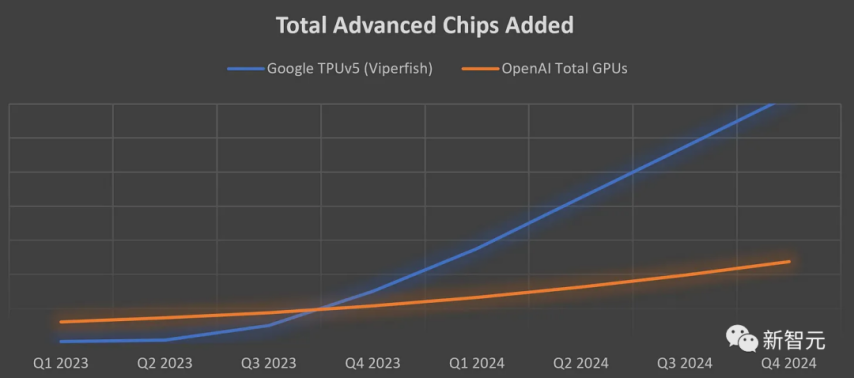
即使對他們的能力給予充分肯定,谷歌的算力也足以讓所有人都傻了眼。實際上,谷歌擁有的TPUv5比OpenAI、Meta、CoreWeave、甲骨文和亞馬遜擁有的GPU總和還要多。并且,谷歌能夠將這些能力的很大一部分出租給各種初創公司。當然,就每個芯片方面的性能來說,TPUv5與H100相比有顯著的差距。
撇開這點不說,OpenAI的算力只是谷歌的一小部分。與此同時,TPUv5的構建能夠大大提升訓練和推理能?。此外,谷歌全新架構的多模態大模型Gemini,一直在以令人難以置信的速度迭代。據稱,Gemini可以訪問多個TPU pod集群,具體來講是在7+7 pods上進行訓練。
爆料者表示,初代的Gemini應該是在TPUv4上訓練的,并且這些pod并沒有集成最大的芯片數——4096個芯?,而是使用了較少的芯片數量,以保證芯片的可靠性和熱插拔。如果所有14個pod都在合理的掩模場利用率(MFU)下使?了約100天,那么訓練Gemini的硬件FLOPS將達到超過1e26。作為參考,爆料者在上次「GPT-4架構」文章中曾詳細介紹了GPT-4模型的FLOPS比2e25稍高一點。而?歌模型FLOPS利?率在TPUv4上?常好,即使在?規模訓練中,也就是Gemini的第?次迭代,遠遠?于GPT-4。
尤其是,就模型架構優越方面,如增強多模態,更是如此。真正令人震驚的是Gemini的下一次迭代,它已經開始在基于TPUv5的pod上進?訓練,算力高達~1e26 FLOPS,這比訓練GPT-4要大5倍。據稱,第?個在TPUv5上訓練的Gemini在數據??存在?些問題,所以不確定谷歌是否會發布。這個~1e26模型可能就是,公開稱為Gemini的模型。再回看上?的圖表,這不是?歌的最終形態。?賽已經開始了,而?歌有著巨?的優勢。如果他們能夠集中精力并付諸實施,至少在訓練前的計算規模擴展和實驗速度方面,他們終將勝出。
他們可以擁有多個比OpenAI最強大的集群,還要強大的集群。谷歌已經摸索了一次,還會再來一次嗎?當前,?歌的基礎設施不僅滿?內部需求,Anthopic等前沿模型公司和?些全球最?的公司,也將訪問TPUv5進?內部模型的訓練和推理。?歌將TPU遷移到云業務部門,并重新樹立了商業意識,這讓他們贏得了一些大公司的青睞果斷戰斗。未來幾個月,你將會看到谷歌的勝利。這些被推銷的公司,有的會為它的TPU買單。
-
gpu
+關注
關注
28文章
4740瀏覽量
128949 -
算力
+關注
關注
1文章
977瀏覽量
14821 -
OpenAI
+關注
關注
9文章
1089瀏覽量
6514
原文標題:侵吞全球算力!谷歌Gemini被曝算力達GPT-4五倍,手握TPU王牌碾壓OpenAI
文章出處:【微信號:ICViews,微信公眾號:半導體產業縱橫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT升級 OpenAI史上最強大模型GPT-4發布
人工通用智能的火花:GPT-4的早期實驗
GPT-4創造力竟全面碾壓人類!最新創造力測試GPT4排名前1%
GPT-4創造力竟全面碾壓人類!最新創造力測試GPT4排名前1%

OpenAI宣布GPT-4 API全面開放使用!
GPT-4沒有推理能力嗎?
OpenAI最新大模型曝光!劍指多模態,GPT-4之后最大升級!

ChatGPT重磅更新 OpenAI發布GPT-4 Turbo模型價格大降2/3

OpenAI發布的GPT-4 Turbo版本ChatGPT plus有什么功能?

成都匯陽投資關于谷歌攜 Gemini 王者歸來,AI 算力和應用值得期待
ChatGPT plus有什么功能?OpenAI 發布 GPT-4 Turbo 目前我們所知道的功能

OpenAI計劃宣布ChatGPT和GPT-4更新
開發者如何調用OpenAI的GPT-4o API以及價格詳情指南
OpenAI API Key獲取:開發人員申請GPT-4 API Key教程





 工商網監
工商網監
評論