 數據閉環,智能駕駛下半場的制勝法寶
數據閉環,智能駕駛下半場的制勝法寶
行業需求及現狀
智能駕駛進入數據驅動時代,數據閉環是智能駕駛量產落地的核心飛輪:更多場景,需要更多數據,訓練更復雜的算法模型。
隨著近兩年的技術迭代,智能駕駛發展的重心已從技術研發比拼轉移到商業化落地的競爭,自2022年起,頭部車企紛紛宣布城市場景NOA(Navigate on Autopilot,自動輔助導航駕駛)的量產落地計劃。據預測,2025年中國城市NOA前裝市場規模將達到76億元。實現城市NOA是智能駕駛商業化向前邁出的一大步,而智能駕駛的成熟依賴于高效的算力、完善的算法模型和大量有效的數據。
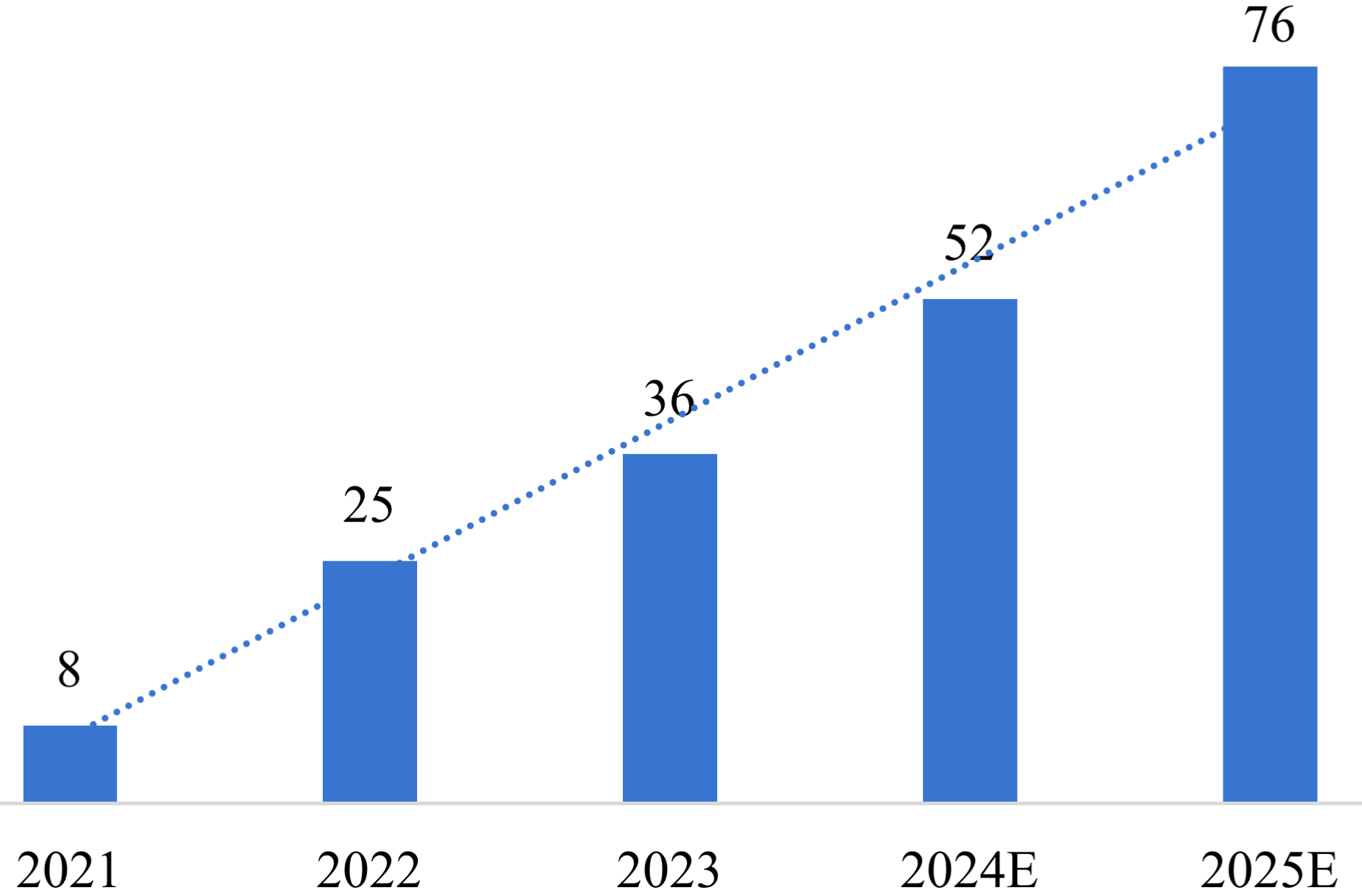
圖12021—2025年中國城市NOA市場規模預測(億元)
智能駕駛所需的場景數據應該盡可能多地涵蓋Corner Case,算法模型的升級迭代也需要新場景數據的不斷投喂,數據重要性日益凸顯,從主機廠到Tier 1,智能駕駛產業上下游各玩家都將目光投向了智能駕駛數據閉環的打造。智能駕駛進入下半場之后,那些無法在數據閉環能力上取得突破的公司在一方面會被“高成本”和“低效率”拖累,另一方面還會因為對Corner Case的解決能力無法取得突破,而難以令終端消費者滿意。對智能駕駛來說,更高質量的訓練數據在其場景化落地中發揮不可或缺的作用,擁有一套完整的數據服務工具對實現智能駕駛數據閉環的高效運轉至關重要。依據全國信息安全標準化技術委員會發布的《汽車采集數據處理安全指南》,汽車采集數據指通過汽車傳感設備、控制單元采集的數據,以及對其進行加工后產生的數據。汽車采集數據經過標注、處理、存儲、管理等處理,形成有效數據集,進一步存儲在云端服務器中,之后傳輸至算法模型,經過訓練部署到車端進行應用驗證,形成一套由數據驅動算法迭代,進而驅動智能駕駛能力升級的閉環模型。
智能駕駛數據服務的痛點與難點
獲取低成本、高質量的數據
智能駕駛的真正落地需要大量高質量、安全無偏差的數據,但目前獲取低成本、高質量的數據仍然是行業發展的一大痛點。對于數據標注公司來說,質量的提升也就意味著更多成本投入,這與客戶控制成本的理念相違背。另一方面,智能駕駛在不同場景的數據需求要求數據標注公司提供持續穩定的數據,這對于多數數據服務商來說也是高難度的挑戰。
采集標注、分析處理、管理的難度和復雜度
在數據的整體生產環節中,數據采集、數據處理和數據管理等各個環節都涉及海量數據,若處理不當,可能會導致項目質量問題和項目啟動延遲,但由于各個模塊的自動化程度都不夠高,導致AI從業者將80%以上精力都花在數據管理上。另一方面,當前解決各種Corner Case的方式主要是實車采集足夠多的相關數據,然后訓練模型,讓模型具備應對能力,這種方式效率較低,而且很多特殊場景出現頻率低,實車很難采集到。
數據標注的效率
傳統的智能駕駛數據閉環,在數據預處理、數據標注等環節效率較低。例如,多數公司在數據標注環節都會依靠“人海戰術”,即依靠人工一個個地對采集回來的數據做場景分類,不僅效率較低,而且會有一定概率產生誤差,對結果影響較大。為了解決智能駕駛數據服務的痛點,早在2021年,云測數據就推出了新智能駕駛數據解決方案1.0,面向智能駕駛領域不同落地場景下的高質量AI訓練數據需求,通過場景數據庫、定制化數據采集標注、數據標注&數據管理平臺等服務,一站式解決智能駕駛從研發初期到落地的訓練數據需求,從而大幅降低AI模型訓練成本,加速智能駕駛相關應用的落地迭代周期,節省研發時間和成本。
云測數據的智能駕駛解決方案
提供豐富的高質量數據集
云測數據是Testin云測旗下AI數據標注服務品牌,通過自建數據場景實驗室和數據標注基地,可為智能駕駛、智慧城市、智能家居、智慧金融、新零售等眾多領域提供高精度、場景化的數據采集、數據標注服務,全方位支持文本、語音、圖像、視頻等各類型數據的處理。目前,云測數據深度合作伙伴覆蓋了汽車、手機、工業、家居、金融、安防、教育、新零售、地產、生態系統等行業。在智能駕駛領域,云測數據憑借高質量的AI訓練數據交付實力已與業內包括自主、合資車企,大型Tier1、Tier2,以及無人出租車、智能駕駛等眾多廠商,建立了持久良好的合作關系。
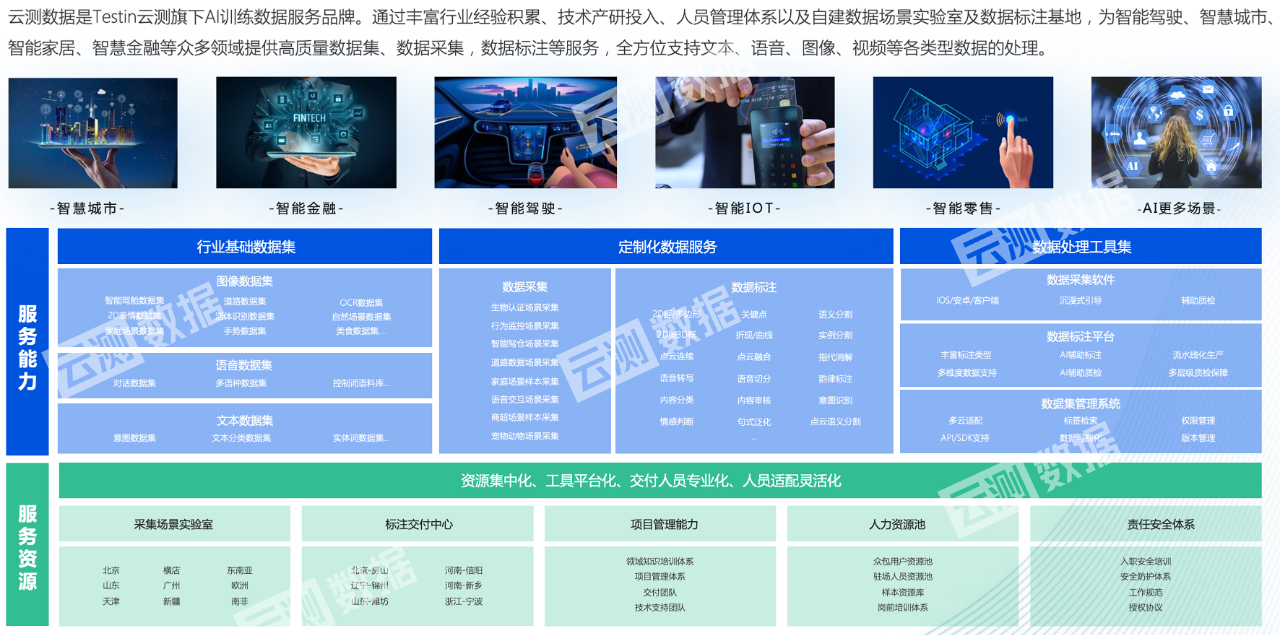
圖2云測數據介紹
全新升級迭代的完整數據工具鏈
針對當下智能駕駛應用場景更加豐富,數據閉環已經成為智能駕駛量產落地的核心飛輪的發展趨勢。云測數據以集成數據底座為核心,全面升級了數據標注及數據管理工具鏈,在今年推出智能駕駛數據解決方案2.0。相較于1.0版本,2.0版本在數據閉環能力、自動標注能力、數據管理工具鏈、人工效能評估等方面進行了全新升級:通過系統集成將大模型預標注能力與人工標注完美結合,提升了數據集和場景化數據服務能力,助力企業數據流轉效率的全面提升。
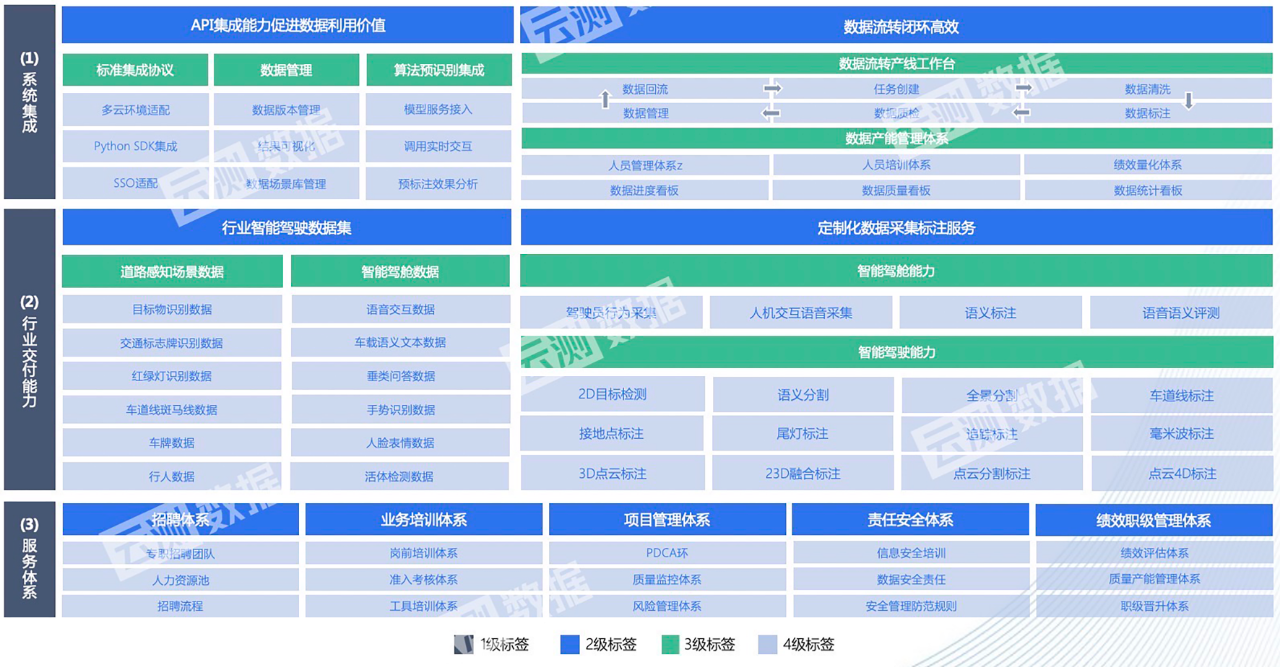
圖3 云測數據智能駕駛解決方案2.0
支持大模型的高效數據標注平臺
云測數據升級人工標注與自動標注算法交互能力,全面提升了數據標注效率。通過將云測數據標注平臺與眾多行業大模型緊密結合,幫助企業更好地提質增效。2.0方案集成了不同模型的預標注能力,包括圖像整幀、自選物體、區域、點云批次識別和文本識別等,重新定義了基于預標注的人工標注效能,如能效看板、綜合看版等。針對特定算法類型的數據持續優化迭代,涵蓋點云4D疊幀、語義分割聯合標注和智能ID軌跡預測。數據集也更加豐富,納入了更多場景數據,標注方法也從原來以點線面體為主進化到融合4D標注規則。在云測數據標注平臺的加持下,針對不同場景的Corner Case的識別和判斷能力和在算法持續迭代的數據閉環階段,數據預處理能力、數據挖掘能力、數據標注能力等方面,都表現出了明顯提升。

圖4云測數據點云4D疊幀演示
支持BEV-Transformer標注,順應智能駕駛發展趨勢
面對當下主流感知大模型的數據服務能力升級,云測數據解決方案支持了更多智能駕駛標注類型,如現在諸多企業基于BEV+Transformer算法研發,對BEV視角環視拼接加點云融標注成為了主流。支持特定類型也使云測數據能更快速響應客戶數據標注需求;同時可實現自動標注結果校驗,并提升大模型標注能力和評測服務能力,助力智駕企業實現更自然、更智能、更多樣化的人機交互方式。在數據標注效率方面,與人工標注相比,BEV空間標注效率約提升1.5倍以上。例如,人工標注3D點云拉框需要先選擇屬性,再選擇車頭朝向。現在,人工只需大致框選一個區域,就完成了自動貼合,基于一些特定標簽類別就能實現自動選擇。其效率比人工拉框至少快了1.5倍到兩倍。又如4D標注地面箭頭,原來需要每幀標注,現在基于4D標注加空間坐標,只要標注對應一幀,通過映射即可將30幀結果疊在一起,完成多傳感器融合4D標注,效率更高。
審核編輯 黃宇
-
智能駕駛
+關注
關注
3文章
2521瀏覽量
48764
發布評論請先 登錄
相關推薦
激活汽車電子“芯”動能!思瑞浦一站式模擬產品方案解鎖智駕全場景

從特斯拉看智能駕駛未來發展
黑芝麻智能推出武當C1200家族芯片 開啟未來出行新篇章
聚焦“智物融合,AI碳索”,涂鴉智能以生成式AI引領行業創新潮流

高通驍龍賦能智能駕駛,開啟汽車產業變革下半場
汽車市場進入“勝者為王”時代,但車企的城市輔助駕駛困境如何解決
德沃克OBF智能工廠:智能制造下半場的王炸

Commvault助力Baptist Health防御網絡威脅 保護關鍵數據安全
大模型之戰的下半場:垂直化應用與生態化發展
誰能打造最強車型?從OTA看車企的智能化之爭有多激烈






 工商網監
工商網監
評論