1. 1800億參數,世界頂級開源大模型Falcon官宣!碾壓LLaMA 2,性能直逼GPT-4
原文:https://mp.weixin.qq.com/s/B3KycAYJ2bLWctvoWOAxHQ
一夜之間,世界最強開源大模型Falcon 180B引爆全網!
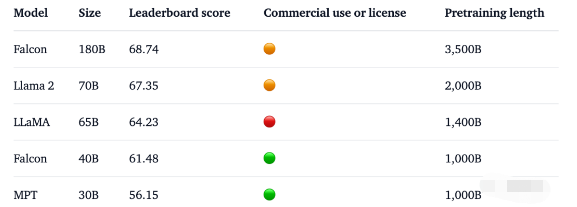
1800億參數,Falcon在3.5萬億token完成訓練,直接登頂Hugging Face排行榜。
基準測試中,Falcon 180B在推理、編碼、熟練度和知識測試各種任務中,一舉擊敗Llama 2。
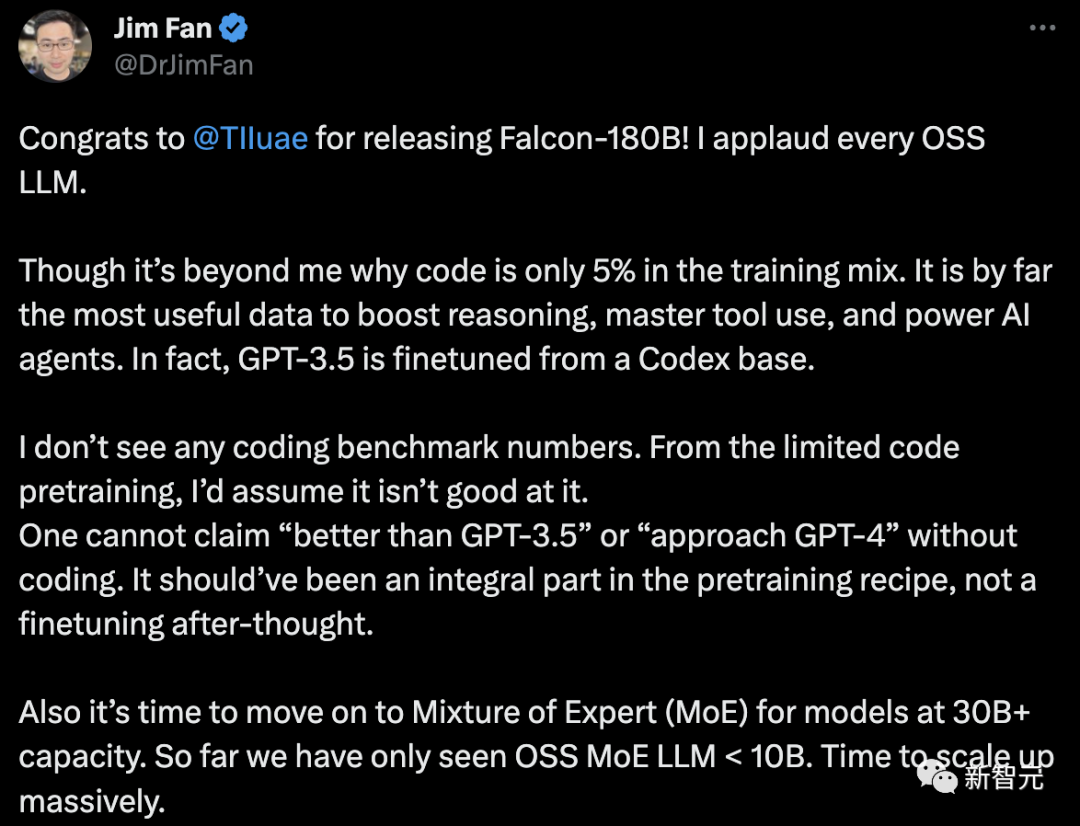
甚至,Falcon 180B能夠與谷歌PaLM 2不差上下,性能直逼GPT-4。不過,英偉達高級科學家Jim Fan對此表示質疑,- Falcon-180B的訓練數據中,代碼只占5%。而代碼是迄今為止對提高推理能力、掌握工具使用和增強AI智能體最有用的數據。事實上,GPT-3.5是在Codex的基礎上進行微調的。- 沒有編碼基準數據。沒有代碼能力,就不能聲稱「優于GPT-3.5」或「接近GPT-4」。它本應是預訓練配方中不可或缺的一部分,而不是事后的微調。- 對于參數大于30B的語言模型,是時候采用混合專家系統(MoE)了。到目前為止,我們只看到OSS MoE LLM < 10B。
一起來看看,Falcon 180B究竟是什么來頭?世界最強開源大模型此前,Falcon已經推出了三種模型大小,分別是1.3B、7.5B、40B。官方介紹,Falcon 180B是40B的升級版本,由阿布扎比的全球領先技術研究中心TII推出,可免費商用。

這次,研究人員在基底模型上技術上進行了創新,比如利用Multi-Query Attention等來提高模型的可擴展性。對于訓練過程,Falcon 180B基于亞馬遜云機器學習平臺Amazon SageMaker,在多達4096個GPU上完成了對3.5萬億token的訓練。總GPU計算時,大約7,000,000個。Falcon 180B的參數規模是Llama 2(70B)的2.5倍,而訓練所需的計算量是Llama 2的4倍。具體訓練數據中,Falcon 180B主要是RefinedWe數據集(大約占85%) 。此外,它還在對話、技術論文,以及一小部分代碼等經過整理的混合數據的基礎上進行了訓練。這個預訓練數據集足夠大,即使是3.5萬億個token也只占不到一個epoch。官方自稱,Falcon 180B是當前「最好」的開源大模型,具體表現如下:在MMLU基準上,Falcon 180B的性能超過了Llama 2 70B和GPT-3.5。在HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC 及ReCoRD上,與谷歌的PaLM 2-Large不相上下。另外,它在Hugging Face開源大模型榜單上,是當前評分最高(68.74分)的開放式大模型,超越了LlaMA 2(67.35)。
2. Meta的Flamera頭顯對增強現實有了新的愿景
原文:https://mp.weixin.qq.com/s/UepWwW7D03_jISTsSmjwnA
Meta的最新原型頭顯Flamera像是直接從科幻動作片中來的一樣,它在Siggraph 2023上引起了人們的注意 —— Flamera在那里獲得了令人垂涎的Best in Show獎。據悉,Flamera原型頭顯展示了接近人眼分辨率和全新的"透視"真實世界的技術。該原型或許為VR、MR和AR的未來鋪平了道路。頭顯原型展示的技術突破引發了人們的興趣和關注。Moor Insights&Strategy副總裁兼首席分析師Ansel Sag表示:“這絕對是我見過的質量最好的(增強現實)實現透視真實世界的全新方法。”

Giving Reality the Bug Eye出于顯而易見的原因,在物理上不可能將頭顯的攝像頭與用戶的眼睛完全放置在同一位置。這種位移導致了我(作者,以下簡稱我)個人經歷的視角的轉變:我在使用AR/VR頭顯時撞到了墻上,或者被被椅子絆倒了。像Meta Quest Pro這樣的尖端頭顯,通過從正確的角度重新投射周圍環境的視圖,跨越了這一障礙,但解決方案可能會導致視覺失真。Meta的蟲眼Flamera提出了一個新穎的解決方案。它摒棄了當前頭顯青睞的外部攝像頭陣列,采用了獨特的“光場穿透”設計,將圖像傳感器與物理控制到達傳感器的光的孔徑配對。會導致不正確視角的光被阻擋,而提供準確視角的光則被允許到達傳感器。當直接通過鏡頭觀看時,結果很奇怪:這有點像透過紙上的洞看世界。頭顯重新排列原始圖像以消除間隙并重新定位傳感器數據。一旦這個過程完成,耳機就會為用戶提供準確的世界視圖。Sag說:“這絕對是一個原型,但它的圖像質量和分辨率給我留下了深刻印象。” “幀速率很好,”ModiFace的軟件開發總監Edgar Maucourant也演示了這款頭顯,并對此印象深刻,“我的眼睛所看到的東西和我的手的位置與我的手真正的位置之間沒有延遲,也沒有差異。”Maucourant認為Flamera的準確性可能會為用戶直接與周圍世界互動的AR應用程序帶來福音。“例如,如果我們考慮遠程輔助,人們必須操縱物體,那么今天它是用HoloLens和Magic Leap等AR眼鏡來實現的……我們可以想象使用AR穿透來實現這一點。”Meta’s Answer to the Apple Vision Pro?與微軟的HoloLens和Magic Leap進行比較很重要。它們通過透明顯示器繞過了透視問題,讓用戶的視覺暢通無阻。當HoloLens于2016年發布時,這種方法感覺像是未來的趨勢,但其顯示質量、視野和亮度仍然存在問題。Meta的Quest Pro和蘋果即將推出的Vision Pro強調了這一方向的轉變。盡管以AR/VR頭顯(或者,蘋果方以“空間計算機”)的形式進行營銷,但它們顯然是虛擬現實家族的一個分支。它們通過不透明的顯示器完全遮擋了用戶的視野。增強現實是通過視頻饋送提供的,該視頻饋送將外部世界投射到顯示器。Vision Pro解決直通問題的方法更注重肌肉而非大腦。它使用了一系列與其他AR/VR頭顯類似的外部攝像頭,但將其與蘋果定制的R1芯片配對,該芯片與蘋果M2芯片協同工作(就像該公司筆記本電腦中的芯片一樣)。R1是一個“視覺處理器”,可以幫助vision Pro的12臺相機通過計算校正視角(以及其他任務)。這很像Meta在Quest Pro上嘗試的方法,但蘋果將功率提高到了11。Meta的Flamera取而代之的是用鏡頭校正視角。這大大降低了準確直通AR所需的原始計算能力。但這并不是說Meta已經完全打開了AR。Flamera的技術距離可供購買的頭顯還有很長的路要走,目前與傳統的直通AR相比存在一些缺點。Sag表示,該頭顯“視野相當有限”,并注意到其景深“不連續”,這意味著遠處的物體看起來比實際更近。Maucourant警告說“顏色不太好”,并認為頭顯的分辨率很低。盡管如此,Flamera或展示了Meta、蘋果和其他希望進入AR領域的公司之間即將發生的爭論方向。科技界的大腕們似乎確信,明天最好的AR/VR頭顯看起來更像最初的Oculus Rift,而不是微軟的HoloLens。然而,目前這些原型更多還是在研究階段,離成為消費級產品還有一段距離。未來,頭顯技術的發展還需要在各個方面進行突破和創新,以實現更高的分辨率、更低的延遲、更舒適的使用體驗等。只有解決了這些問題,才能讓用戶真正感受到頭顯帶來的沉浸式體驗,進一步推動VR、MR和AR技術的廣泛應用。
3. 騰訊混元大模型正式亮相,我們搶先試了試它的生產力
原文:https://mp.weixin.qq.com/s/xuk77KHJHhoh6kWkf-4AKg
上個星期,國內首批大模型備案獲批,開始面向全社會開放服務,大模型正式進入了規模應用的新階段。在前期發布應用的行列中,有些科技巨頭似乎還沒有出手。很快到了 9 月 7 日,在 2023 騰訊全球數字生態大會上,騰訊正式揭開了混元大模型的面紗,并通過騰訊云對外開放。作為一個超千億參數的大模型,混元使用的預訓練語料超過兩萬億 token,憑借多項獨有的技術能力獲得了強大的中文創作能力、復雜語境下的邏輯推理能力,以及可靠的任務執行能力。

騰訊集團副總裁蔣杰表示:「騰訊混元大模型是從第一個 token 開始從零訓練的,我們掌握了從模型算法到機器學習框架,再到 AI 基礎設施的全鏈路自研技術。」打開大模型,全部都是生產力騰訊一直表示在大模型的相關方向上早已有所布局,專項研究一直有序推進。這個不是「新技術」的大模型是什么級別?在大會上蔣杰通過直接詢問混元大模型的方式透露了一些基本信息,它的參數量是千億級,訓練用的數據截止到今年 7 月份,此外騰訊也表示大模型的知識將會每月更新。騰訊在現場展示了「騰訊混元大模型小程序」、騰訊文檔中的 AI 助手以及騰訊會議 AI 助手的能力。機器之心第一時間獲得測試資格嘗試了一番,首先是微信小程序。

從生產力、生活、娛樂到編程開發,它開放的能力可謂非常全面了,符合一個千億級大模型的身份。那么混元真的能有效地完成這些任務嗎?我要寫一份 PPT,只想好了主題卻不知從何寫起,問一下混元大模型。只需幾秒,AI 就給了一份分出七個部分的大綱,每一部分里也包含細分的點:輸入一篇 arXiv 上 9 月份谷歌提交的論文《RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback》摘要和介紹部分,長長的好幾段,很多大模型根本不支持這么多輸入內容,混元大模型直接進行了總結順便翻譯成中文。它詳細解釋了平方根倒數算法里面數字的意義(不過對注釋理解得不太透徹)。或許過不了多久,我們做開發的時候就離不開大模型了。然后是騰訊文檔。很多人已經把 GPT-4 等大模型工具用在了自己的工作流程中,混元大模型在騰訊文檔推出的智能助手功能中已有應用。在 PC 端新建智能文檔,輸入 “/”,就能根據需求實現內容生成、翻譯、潤色等操作。已覆蓋騰訊超過 50 個業務蔣杰總結了混元大模型的三大特點:具備強大的中文創作能力、復雜語境下的邏輯推理能力以及可靠的任務執行能力。目前不少業內大模型在場景中的應用依然有限,主要問題集中在容錯率高,只適用于任務簡單的休閑場景。騰訊在算法層面進行了一系列自研創新,提高了模型可靠性和成熟度。

針對大模型容易「胡言亂語」的問題,騰訊優化了預訓練算法及策略,通過自研的「探真」技術,讓混元大模型的「幻覺」相比主流開源大模型降低了 30-50%。「業界的做法是提供搜索增強,知識圖譜等『外掛』來提升大模型開卷考試的能力。這種方式增加了模型的知識,但在實際應用中存在很多局限性,」蔣杰表示。「混元大模型在開發初期就考慮完全不依賴外界數據的方式,進行了大量研究嘗試,我們找到的預訓練方法,很大程度上解決了幻覺的問題。」騰訊還通過強化學習的方法,讓模型學會識別陷阱問題,通過位置編碼的優化,提高了模型處理超長文的效果和性能。在邏輯方面,騰訊提出了思維鏈的新策略,讓大模型能夠像人一樣結合實際的應用場景進行推理和決策。騰訊混元大模型能夠理解上下文的含義,具有長文記憶能力,可以流暢地進行專業領域的多輪對話。除此之外,它還能進行文學創作、文本摘要、角色扮演等內容創作,做到充分理解用戶意圖,并高效、準確的給出有時效性的答復。這樣的技術落地之后,才能真正提升生產力。

在中國信通院《大規模預訓練模型技術和應用的評估方法》的標準符合性測試中,混元大模型共測評 66 個能力項,在「模型開發」和「模型能力」兩個領域的綜合評價獲得了當前最高分。在主流的評測集 MMLU、CEval 和 AGI-eval 上,混元大模型均有優異的表現,特別是在中文的理科、高考題和數學等子項上表現突出。構建大模型的意義在于行業應用。據了解,騰訊內部已有超過 50 個業務和產品接入并測試了騰訊混元大模型,包括騰訊云、騰訊廣告、騰訊游戲、騰訊金融科技、騰訊會議、騰訊文檔、微信搜一搜、QQ 瀏覽器等,并取得了初步效果。騰訊的程序員們,已經在用大模型工具提高開發效率了。此外,騰訊還通過自研機器學習框架 Angel,使模型的訓練速度相比業界主流框架提升 1 倍,推理速度比業界主流框架提升 1.3 倍。用于構建大模型的基礎設施也沒有拉下。此前騰訊曾表示已于今年年初構建了大規模算力中心,近期 MiniMax 和百川智能旗下的大模型都使用了騰訊的算力。騰訊也在致力于把行業數據與自身能力相結合,基于外部客戶的行業化數據來解決行業特定問題,與實體行業結合,不斷推動大模型的社會、經濟利益和商業價值。「根據公開數據顯示,國內已有 130 個大模型發布。其中既有通用模型也有專業領域模型。混元作為通用模型能夠支持騰訊內部的大部分業務,今天我展示的幾個深度接入的業務都有很大的用戶量。大模型已在我們的核心領域獲得了深度應用,」蔣杰說道。「我大模型首先是服務企業本身,其次是通過騰訊云對外開放。」在開放給客戶使用時,混元大模型將作為騰訊云模型即服務 MaaS 的底座。客戶既可以直接調用混元 API,也能將混元作為基座模型,為不同的產業場景構建專屬應用。可見,騰訊在大模型領域的策略講究的是一個穩字:專注打好基礎,不急于拿出半成品展示。而這一出手,就展現出了過硬的實力。

不過大模型的發展還在繼續,正如蔣杰所言:「毫不夸張地說,騰訊已經全面擁抱大模型。我們的能力一直在演進,相信 AIGC 的潛力是無限的,我們已在路上。」
4. GitHub熱榜登頂:開源版GPT-4代碼解釋器,可安裝任意Python庫,本地終端運行
原文:https://mp.weixin.qq.com/s/TiSVeZOeWourVJ60yyyygw
ChatGPT的代碼解釋器,用自己的電腦也能運行了。剛剛有位大神在GitHub上發布了本地版的代碼解釋器,很快就憑借3k+星標并登頂GitHub熱榜。不僅GPT-4本來有的功能它都有,關鍵是還可以聯網。
ChatGPT“斷網”的消息傳出后引起了一片嘩然,而且一關就是幾個月。這幾個月間聯網功能一直杳無音訊,現在可算是有解決的辦法了。由于代碼是在本地運行,所以除了聯網之外,它還解決了網頁版的很多其他問題:-
3小時只能發50條消息
-
支持的Python模塊數量有限
-
處理文件大小有限制,不能超過100MB
-
關閉會話窗口之后,此前生成的文件會被刪除
如果沒有API,還可以把模型換成開源的Code LLaMa。這個代碼解釋器推出之后,很快有網友表示期待一波網頁版:

那么我們就來看看這個本地代碼解釋器到底怎么樣吧!讓GPT“重新聯網”既然調用了GPT-4的API,那GPT-4支持的功能自然都能用,當然也支持中文。關于GPT本身的功能這里就不再一一詳細展示了。不過值得一提的是,有了代碼解釋器之后,GPT的數學水平提升了好幾個檔次。所以這里我們用一個高難度的求導問題來考驗一下它,題目是f(x)=√(x+√(x+√x))。
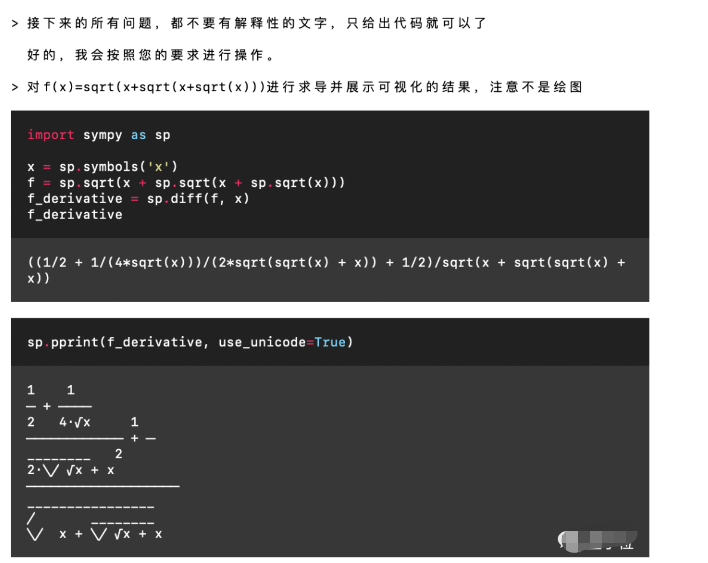
Emmm……這個結果有些抽象,不過應該是提示詞的問題,我們修改一下:
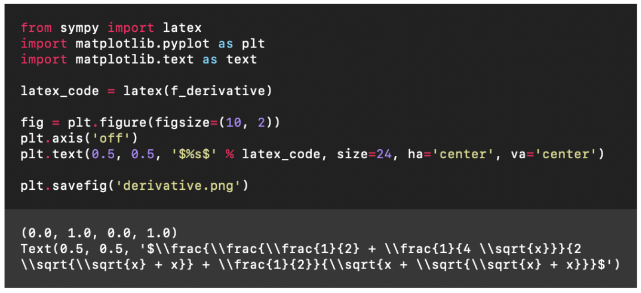
然后我們就看到了這樣的結果:
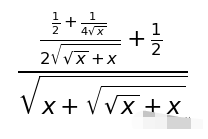
這個式子和標準答案長得不太一樣,不過是不是格式的問題呢?我們驗證了一下:
結果是正確的!接下來就要進入重頭戲了,來看看這個代碼解釋器的聯網功能到底是不是噱頭:比如我們想看一下最近有什么新聞。更多的內容請點擊原文,謝謝。
5. ReVersion|圖像生成中的Relation定制化
原文:https://mp.weixin.qq.com/s/7W80wWf2Bj68MnC8NEV9cQ
新任務:Relation Inversion今年,diffusion model和相關的定制化(personalization)的工作越來越受人們歡迎,例如DreamBooth,Textual Inversion,Custom Diffusion等,該類方法可以將一個具體物體的概念從圖片中提取出來,并加入到預訓練的text-to-image diffusion model中,這樣一來,人們就可以定制化地生成自己感興趣的物體,比如說具體的動漫人物,或者是家里的雕塑,水杯等等。現有的定制化方法主要集中在捕捉物體外觀(appearance)方面。然而,除了物體的外觀,視覺世界還有另一個重要的支柱,就是物體與物體之間千絲萬縷的關系(relation)。目前還沒有工作探索過如何從圖片中提取一個具體關系(relation),并將該relation作用在生成任務上。為此,我們提出了一個新任務:Relation Inversion。
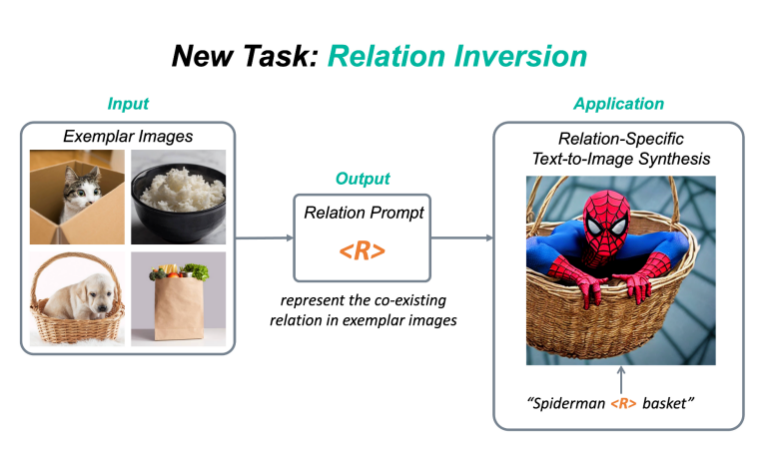
如上圖,給定幾張參考圖片,這些參考圖片中有一個共存的relation,例如“物體A被裝在物體B中”,Relation Inversion的目標是找到一個relation prompt來描述這種交互關系,并將其應用于生成新的場景,讓其中的物體也按照這個relation互動,例如將蜘蛛俠裝進籃子里。

論文:https://arxiv.org/abs/2303.13495代碼:https://github.com/ziqihuangg/ReVersion主頁:https://ziqihuangg.github.io/projects/reversion.html視頻:https://www.youtube.com/watch?v=pkal3yjyyKQDemo:https://huggingface.co/spaces/Ziqi/ReVersion
ReVersion框架作為針對Relation Inversion問題的首次嘗試,我們提出了ReVersion框架:
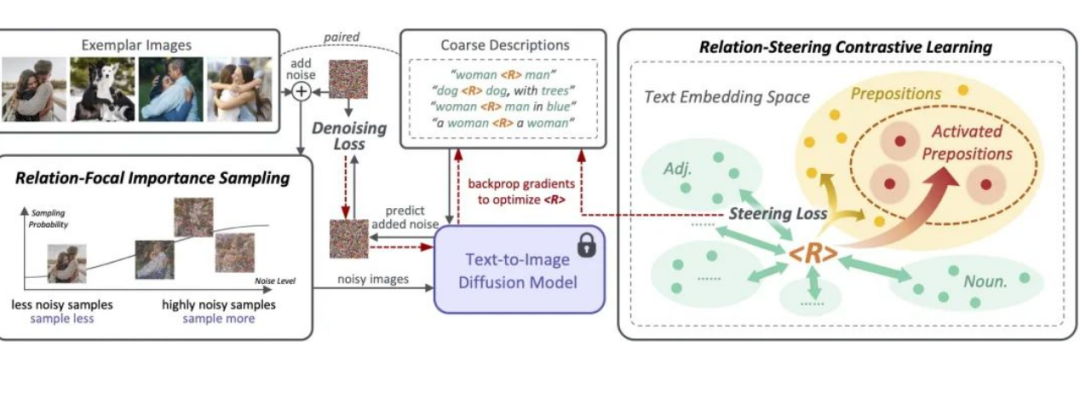
相較于已有的Appearance Invesion任務,Relation Inversion任務的難點在于怎樣告訴模型我們需要提取的是relation這個相對抽象的概念,而不是物體的外觀這類有顯著視覺特征的方面。我們提出了relation-focal importance sampling策略來鼓勵更多地關注high-level的relation;同時設計了relation-steering contrastive learning來引導更多地關注relation,而非物體的外觀。更多細節詳見論文。ReVersion Benchmark我們收集并提供了ReVersion Benchmark:https://github.com/ziqihuangg/ReVersion#the-reversion-benchmark它包含豐富多樣的relation,每個relation有多張exemplar images以及人工標注的文字描述。我們同時對常見的relation提供了大量的inference templates,大家可以用這些inference templates來測試學到的relation prompt是否精準,也可以用來組合生成一些有意思的交互場景。結果展示豐富多樣的relation,我們可以invert豐富多樣的relation,并將它們作用在新的物體上
6. 神經網絡大還是小?Transformer模型規模對訓練目標的影響
原文:https://mp.weixin.qq.com/s/el_vtxw-54LVnuWzS1JYDw
論文鏈接:https://arxiv.org/abs/2205.10505
01 TL;DR本文研究了 Transformer 類模型結構(configration)設計(即模型深度和寬度)與訓練目標之間的關系。結論是:token 級的訓練目標(如 masked token prediction)相對更適合擴展更深層的模型,而 sequence 級的訓練目標(如語句分類)則相對不適合訓練深層神經網絡,在訓練時會遇到 over-smoothing problem。在配置模型的結構時,我們應該注意模型的訓練目標。一般而言,在我們討論不同的模型時,為了比較的公平,我們會采用相同的配置。然而,如果某個模型只是因為在結構上更適應訓練目標,它可能會在比較中勝出。對于不同的訓練任務,如果沒有進行相應的模型配置搜索,它的潛力可能會被低估。因此,為了充分理解每個新穎訓練目標的應用潛力,我們建議研究者進行合理的研究并自定義結構配置。02 概念解釋下面將集中解釋一些概念,以便于快速理解:2.1 Training Objective(訓練目標)
 訓練目標是模型在訓練過程中完成的任務,也可以理解為其需要優化的損失函數。在模型訓練的過程中,有多種不同的訓練目標可以使用,在此我們列出了 3 種不同的訓練目標并將其歸類為 token level 和 sequence level:
訓練目標是模型在訓練過程中完成的任務,也可以理解為其需要優化的損失函數。在模型訓練的過程中,有多種不同的訓練目標可以使用,在此我們列出了 3 種不同的訓練目標并將其歸類為 token level 和 sequence level:-
sequence level:
-
-
classification 分類任務,作為監督訓練任務。簡單分類(Vanilla Classification)要求模型對輸入直接進行分類,如對句子進行情感分類,對圖片進行分類;而 CLIP 的分類任務要求模型將圖片與句子進行匹配。
-
token level:(無監督)
-
-
masked autoencoder:masked token 預測任務,模型對部分遮蓋的輸入進行重建
-
next token prediction:對序列的下一個 token 進行預測
2.2 Transformer Configration(模型結構:配置)
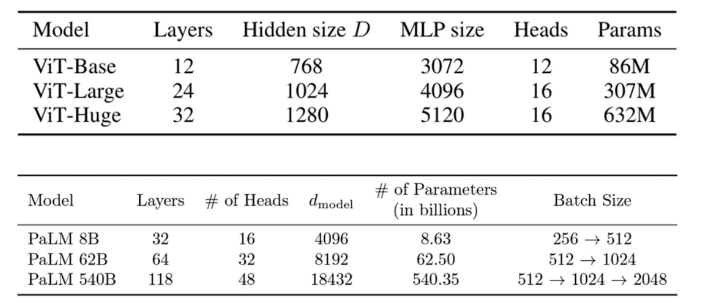
Transoformer 的配置指的是定義 Transformer 模型結構和大小的超參數,包括層數(深度),隱藏層大小(寬度),注意力頭的個數等。2.3 Over-smoothing (過度平滑)
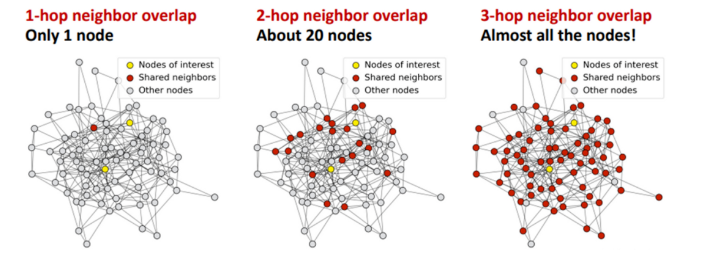
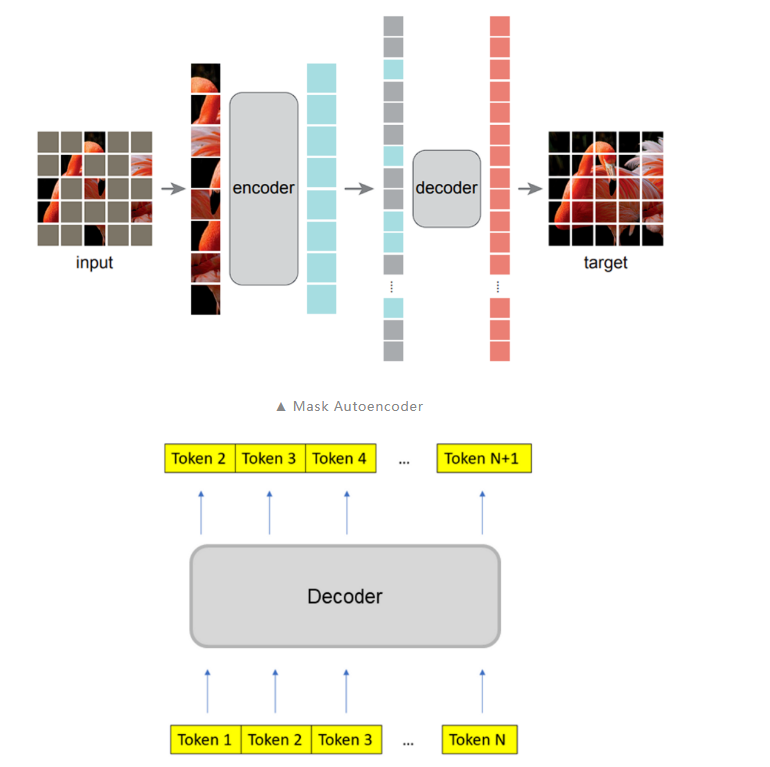
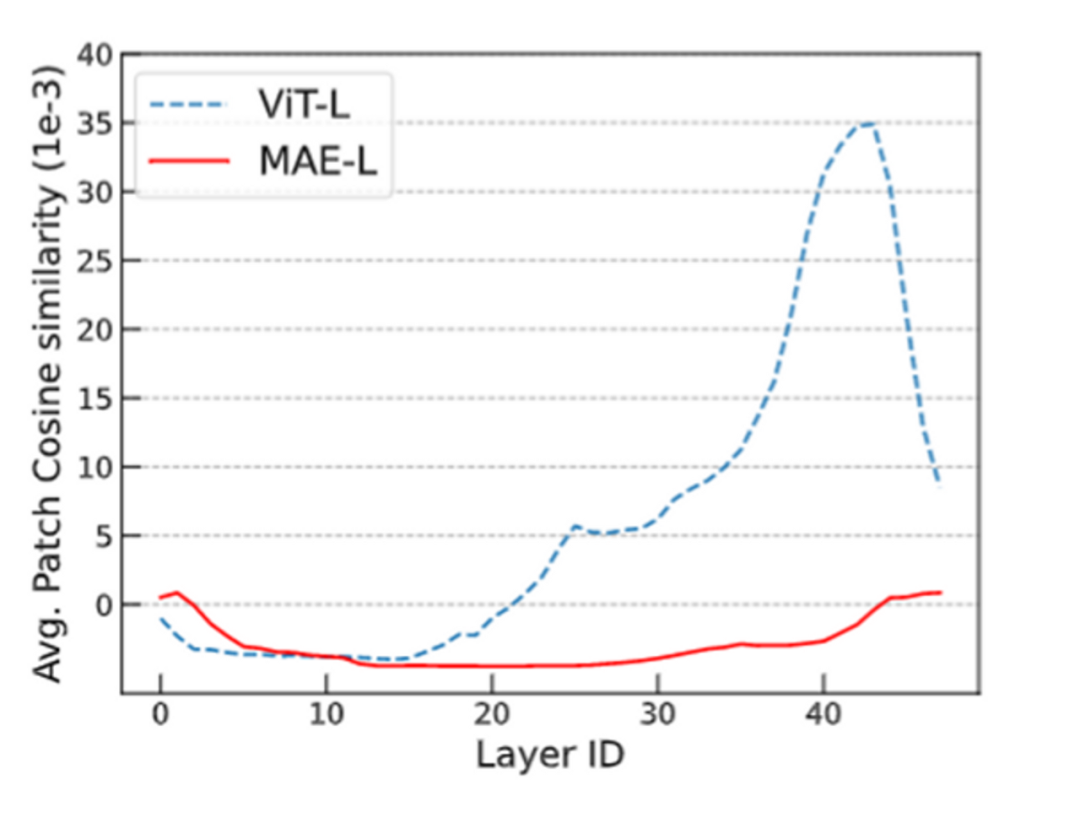
過度平滑是一個在圖神經網絡中的概念,具體表示模型輸出趨向平滑一致,各個點的輸出缺少細節和變化的現象。這一現象在圖神經網絡中被廣泛研究,但它也在 Transformer 模型中存在。(已有研究)發現 Transoformer 模型遇到的 over-smoothing 問題阻礙模型加深。具體而言,當堆疊多層的 Transformer layers 時,transformer layer 輸出的 token 表征(向量)會趨于一致,丟失獨特性。這阻礙了 Transformer 模型的擴展性,特別是在深度這一維度上。增加 Transformer 模型的深度只帶來微小的性能提升,有時甚至會損害原有模型的性能。1. ViT 和 MAE 中的 over-smoothing直觀上,掩碼自編碼器框架(例如 BERT、BEiT、MAE)的訓練目標是基于未掩碼的 unmasked token 恢復被掩碼的 masked token。與使用簡單分類目標訓練 Transformer 相比,掩碼自編碼器框架采用了序列標注目標。我們先假設掩碼自編碼器訓練能緩解 over-smoothing,這可能是掩碼自編碼器 MAE 有助于提升 Transformer 性能的原因之一。由于不同的 masked token 相鄰的 unmaksed token 也不同,unmasked token 必須具有充分的語義信息,以準確預測其臨近的 masked token。也即,unmasked token 的表征的語義信息是重要的,這抑制了它們趨向一致。總之,我們可以推斷掩碼自編碼器的訓練目標通過對 token 間的差異進行正則化,有助于緩解過度平滑問題。我們通過可視化的實驗來驗證了這一觀點。我們發現 ViT 的 token 表征在更深的層中更加接近,而 MAE 模型則避免了這個問題,這說明在掩碼自編碼器中,over-smoothing 問題得到了緩解。通過簡單的分類任務訓練 Transformer 模型則不具備這一特點。
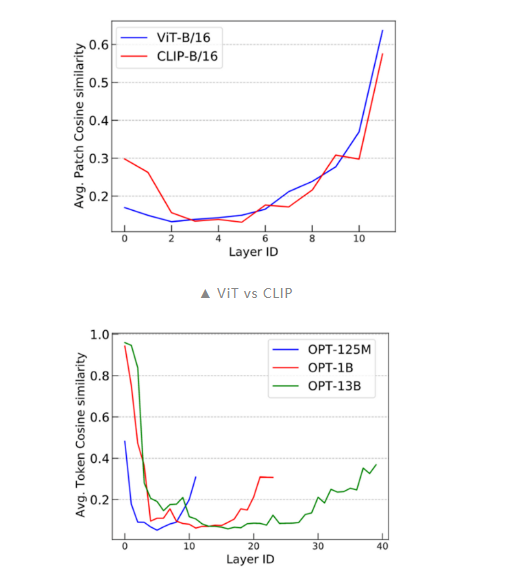
進一步的,我們還通過傅里葉方法對這一問題進行了研究,具體可以參考我們的論文。2. CLIP 和 LLM 中的 over-smoothing根據上述分析,我們可以得出結論:token 級的訓練目標(例如語言建模中的:next token prediction)表現出較輕的 over-smoothing。另一方面,基于 sequence 級別的目標(如對比圖像預訓練)更容易出現 over-smoothing。為了驗證這個結論,我們使用 CLIP 和 OPT 進行了類似的 cosine 相似度實驗。我們可以看到 CLIP 模型展現了與 Vanilla ViT 類似的 over-smoothing 現象。這一觀察結果符合我們的預期。此外,為了探究 next-token prediction 這一廣泛采用的語言建模預訓練目標是否可以緩解 over-smoothing,我們對 OPT 進行了評估,并發現它能夠有效應對 over-smoothing。這一發現具有重要意義,因為它有助于解釋為什么語言建模模型在可擴展性方面(如超大規模預訓練語言模型)優于許多視覺模型。
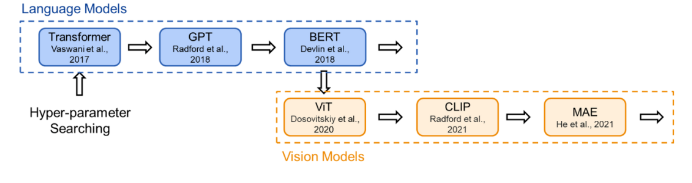
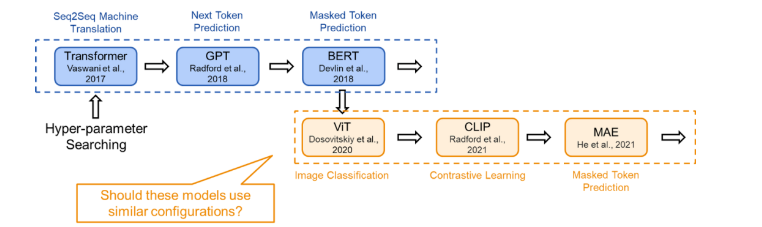
03 溯源:現有的Transformer架構是怎么來的為了在研究時保證公平的比較,現有的 Transformer 類模型通常會遵循固定的結構(small, base, large…),即相同的寬度和深度。比如前面提到的 transformer-base 就是寬度為 768(隱藏層),深度為 12(層數)。然而,對于不同的研究領域,不同的模型功能,為什么仍要采用相同的超參數?為此,我們首先對 Transformer 架構進行了溯源,回顧了代表性的工作中 Transformer 結構的來源:Vision Transformer 的作者根據 BERT 中 Transformer-base 的結構作為其 ViT 模型配置;而 BERT 在選擇配置時遵循了 OpenAI GPT 的方法;OpenAI 則參考了最初的 Transformer 論文。在最初的 Transformer 論文中,最佳配置來源于機器翻譯任務的笑容實驗。也就是說,對于不同任務,我們均采用了基于對機器翻譯任務的 Transformer 配置。(參考上文,這是一種序列級別的任務)
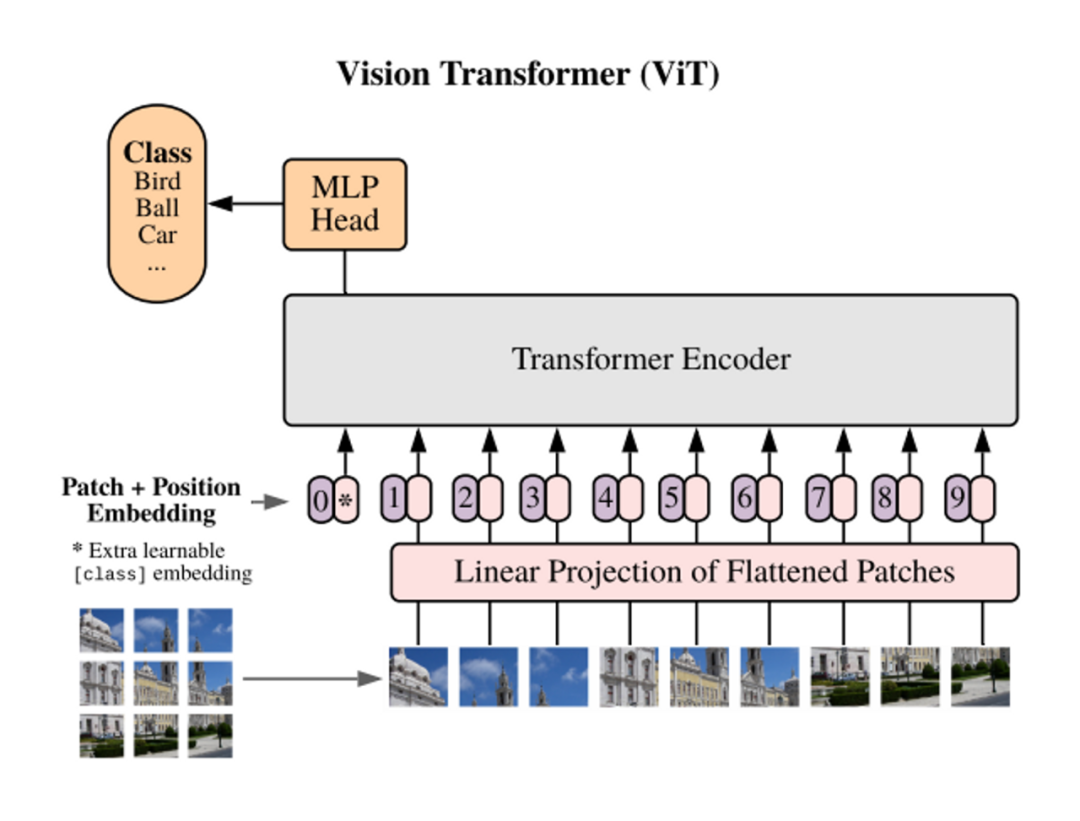
04 現狀:不同的模型采用不同的訓練目標現在,Transformer 模型通過各種訓練目標進行訓練。以 ViT 為例,我們可以在圖像分類的監督學習環境下從頭開始訓練 Transformer 模型。在這種直接的圖像分類任務中,每個圖像被建模為一個 token 序列,其中每個 token 對應圖像中的一個圖塊。我們使用來自圖像的所有 token(即圖塊)的全局信息來預測單個標簽,即圖像類別。在這里,由于訓練目標是捕捉圖像的全局信息,token 表示之間的差異不會直接被考慮。這一訓練目標與機器翻譯任務完全不同,機器翻譯要求模型理解 token 序列,并以此生成另一個序列。據此,我們可以合理假設對于這兩個不同任務,應該存在不同的最佳 Transformer 配置。
05 對于MAE訓練目標調整模型結構基于上述的討論,我們得到了如下認識:-
現有的 Transformer 模型在加深模型深度時會發生 over-smoothing 問題,這阻礙了模型在深度上的拓展。
-
相較于簡單分類訓練目標,MAE 的掩碼預測任務能夠緩解 over-smoothing。(進一步地,token 級別的訓練目標都能夠一定程度地緩解 over-smoothing)
-
MAE 的現有模型結構繼承于機器翻譯任務上的最佳結構設置,不一定合理。
綜合以上三點,可以推知 MAE 應該能夠在深度上更好的拓展,也即使用更深的模型架構。本文探索了 MAE 在更深,更窄的模型設置下的表現:采用本文提出的 Bamboo(更深,更窄)模型配置,我們可以在視覺和語言任務上得到明顯的性能提升。
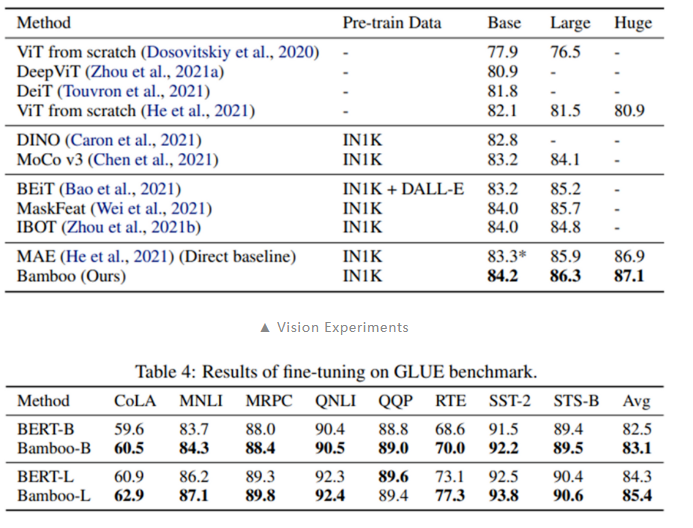
另外,我們在深度拓展性上也做了實驗,可以看到,當采用 Bamboo 的配置時,MAE 能夠獲得明顯的性能提升,而對于 ViT 而言,更深的模型則是有害的。MAE 在深度增加到 48 層時仍能獲得性能提升,而 ViT 則總是處于性能下降的趨勢。
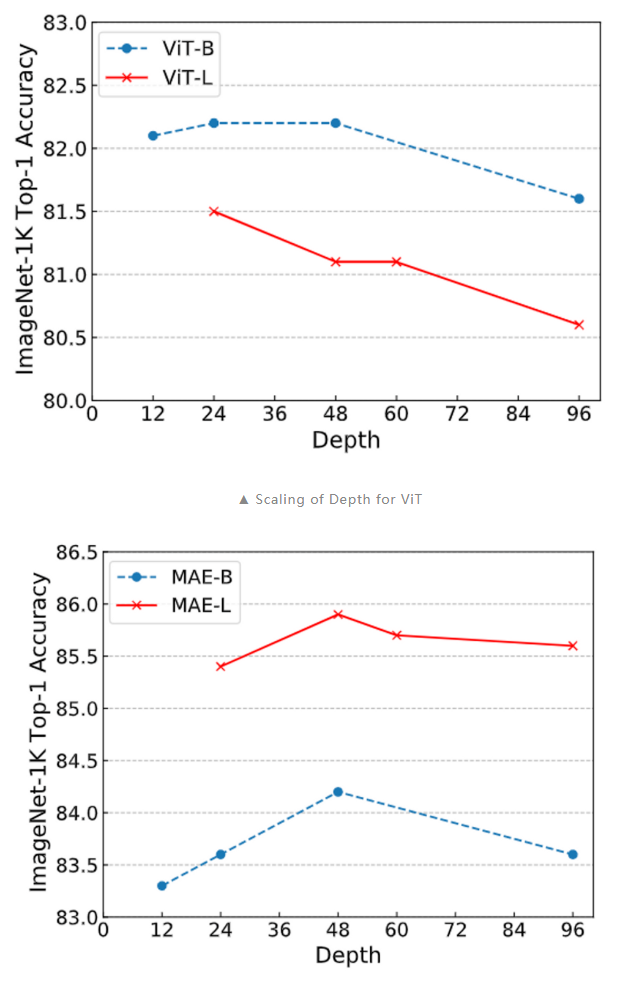
以上的結果佐證了本文提出的觀點:訓練目標能夠影響模型拓展的行為。Training objectives can greatly change the scaling behavior.06 結論本文發現,Transformer 的配置與其訓練目標之間存在著密切關系。sequence 級別的訓練目標,如直接分類和 CLIP,通常遇到 over-smoothing。而 token 級的訓練目標,如 MAE 和 LLMs 的 next token prediction,可以較好地緩解 over-smoothing。這一結論解釋了許多模型擴展性研究結果,例如 GPT-based LLMs 的可擴展性以及 MAE 比 ViT 更具擴展性的現象。我們認為這一觀點對我們的學術界有助于理解許多 Transformer 模型的擴展行為。
———————End———————
點擊閱讀原文進入官網
原文標題:【AI簡報20230908期】正式亮相!打開騰訊混元大模型,全部都是生產力
文章出處:【微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
原文標題:【AI簡報20230908期】正式亮相!打開騰訊混元大模型,全部都是生產力
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
相關推薦
近日,在2024年12月24日舉辦的開放原子開發者大會暨首屆開源技術學術大會上,騰訊云副總裁、騰訊混元大模型負責人劉煜宏發表了重要演講。他強
![的頭像]() 發表于
發表于 12-26 10:30
?241次閱讀
近日,北京智源人工智能研究院(BAAI)發布了最新的FlagEval大模型評測排行榜,其中多模態模型評測榜單的文生圖模型引起了廣泛關注。結果顯示,騰訊
![的頭像]() 發表于
發表于 12-25 10:06
?232次閱讀
近日,騰訊宣布其混元大模型正式上線,并開源了一項令人矚目的能力——文生視頻。該大模型參數量高達130億,支持中英文雙語輸入,為用戶提供了更為
![的頭像]() 發表于
發表于 12-04 14:06
?186次閱讀
近日,騰訊混元團隊最新推出的MoE模型“混元Large”已正式開源上線。這一里程碑式的進展標志著
![的頭像]() 發表于
發表于 11-08 11:03
?446次閱讀
驍龍峰會期間,高通技術公司宣布與騰訊混元合作,基于驍龍8至尊版移動平臺,共同推動了騰訊混元大
![的頭像]() 發表于
發表于 11-08 09:52
?427次閱讀
,分享了智能化應用的行業實踐,并發布了華為云在應用開發、運行、運維、集成領域的智能化新產品能力。 在主題為“ AI 賦能應用現代化,加速軟件生產力躍升論壇 ”的論壇上,徐峰首先介紹了 AI 軟件+應用領域將會成為
![的頭像]() 發表于
發表于 10-14 09:45
?544次閱讀

大模型應用百花齊放,AI編程助手作為新質生產力工具為企業和開發者帶來哪些價值?
![的頭像]() 發表于
發表于 09-02 09:25
?663次閱讀
5月21日-22日,北京機器視覺助力智能制造創新發展大會在北京國際會議中心圓滿舉行。本次大會以“Vision+AI引領新質生產力”為核心主題,聚焦“3D視覺與精準成像、AI大模型、工業
![的頭像]() 發表于
發表于 05-30 17:14
?587次閱讀

從騰訊方面獲悉,一站式智能體創作與分發平臺騰訊元器即日起全面升級了模型資源扶持方案。
![的頭像]() 發表于
發表于 05-27 14:22
?884次閱讀
據了解,騰訊混元大模型是騰訊全鏈路自研的萬億參數大模型,采用混合專家
![的頭像]() 發表于
發表于 05-23 17:05
?951次閱讀
當嫘祖也開始用大模型掌握新質生產力……
![的頭像]() 發表于
發表于 04-16 17:52
?572次閱讀

新質生產力,是2023年9月首次提到的新的詞匯,新質生產力是生產力現代化的具體體現,即新的高水平現代化生產力(新類型、新結構、高技術水平、高質量、高效率、可持續的
![的頭像]() 發表于
發表于 02-28 16:01
?2404次閱讀
新質生產力作為先進生產力的具體體現形式,是馬克思主義生產力理論的中國創新和實踐,是科技創新交叉融合突破所產生的根本性成果。
![的頭像]() 發表于
發表于 02-28 15:39
?1.1w次閱讀
自從ChatGPT爆火以來,各種AI大模型紛紛亮相,如百度科技的文心一言,科大訊飛的訊飛星火,華為的盤古AI大模型,
![的頭像]() 發表于
發表于 02-28 09:35
?2380次閱讀
新質生產力的發展主要集中在新能源、新材料、先進制造、電子信息等戰略性新興產業。 新質生產力作為先進生產力的具體體現形式,是馬克思主義生產力理論的中國創新和實踐,是科技創新交叉融合突破所
![的頭像]() 發表于
發表于 02-22 17:57
?4989次閱讀
 【AI簡報20230908期】正式亮相!打開騰訊混元大模型,全部都是生產力
【AI簡報20230908期】正式亮相!打開騰訊混元大模型,全部都是生產力





 工商網監
工商網監
評論