 揭秘英偉達A100、A800、H100、H800 GPU如何實現高性能大模型的百倍訓練加速
揭秘英偉達A100、A800、H100、H800 GPU如何實現高性能大模型的百倍訓練加速
關鍵詞:Transformer;PLM;SLM;NLM;LLM;Galactica;OPT;OPT-IML;BLOOM;BLOOMZ;GLM;Reddit;H100;H800;A100;A800;MI200;MI250;LaMA;OpenAI;GQA;RMSNorm;SFT;RTX 4090;A6000;AIGC;CHATGLM;LLVM;LLMs;GLM;AGI;HPC;GPU;CPU;CPU+GPU;英偉達;Nvidia;英特爾;AMD;高性能計算;高性能服務器;藍海大腦;多元異構算力;大模型訓練;通用人工智能;GPU服務器;GPU集群;大模型訓練GPU集群;大語言模型;深度學習;機器學習;計算機視覺;生成式AI;ML;DLC;圖像分割;預訓練語言模型;AI服務器;GH200;L40S;HBM3e;Grace Hopper;gracehopper
摘要:本文主要介紹大模型的內部運行原理、我國算力發展現狀。大模型指具有巨大參數量的深度學習模型,如GPT-4。其通過在大規模數據集上進行訓練,能夠產生更加準確和有創造性的結果。大模型的內部運行原理包括輸入數據的處理、多層神經網絡計算和輸出結果生成。這些模型通常由數十億個參數組成,需要龐大的計算資源和高速的存儲器來進行訓練和推理。
隨著大模型的快速發展,我國在算力發展方面取得顯著進展。近年來,我國投入大量資源用于高性能計算和人工智能領域研發,并建設一系列超級計算中心和云計算平臺。這些舉措不僅提升我國的科學研究能力,也為大模型訓練和應用提供強大支持。我國算力發展已經進入全球領先行列,為推動人工智能發展奠定堅實的基礎。
藍海大腦大模型訓練平臺是藍海大腦自主研發的高性能計算平臺,專用于大模型訓練和推理。該平臺采用先進的硬件架構和優化的軟件算法,可以提供高效的計算能力和存儲能力。
大模型內部運行原理
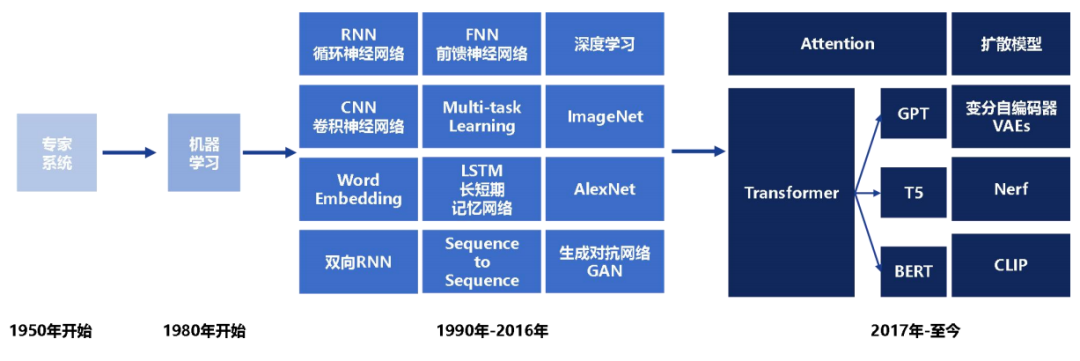
近年來,在大規模語料上預訓練 Transformer 模型產生了預訓練語言模型(Pre-trained Language Model, PLM),在各類自然語言處理任務上展現強大的語言理解與生成能力。研究發現擴大模型規模可以提高模型能力,導致大規模語言模型(Large Language Model, LLM)的產生。當模型規模超過一定閾值后,這些大模型不僅性能大幅提升,還表現出小模型所不具備的語言學習能力。
LLM技術的快速進展改變了AI系統的研發與應用范式。本文回顧了近年來LLM技術的發展歷程,同時總結了LLM的研發資源、存在的問題和未來方向。
一、引言
語言是人類獨有的表達和交流能力,在兒童早期就開始形成并伴隨一生不斷發展變化。然而機器想要像人類一樣自然地掌握理解和使用語言的能力,必須配備強大的人工智能算法。實現機器擁有類似人類閱讀、寫作和交流能力是一個長期的研究挑戰。
從技術上講,語言建模是提高機器語言智能的主要方法之一。語言建模通常是對詞序列生成概率進行建模,以預測未出現的詞語。語言建模研究在學術界受到廣泛關注。其發展可分為四個主要階段:
1、統計語言模型 (SLM)
SLM(Statistical Language Model)在20世紀90年代興起,基于統計學習方法,通過馬爾可夫假設來建立詞預測模型。其具有固定上下文長度 n 的 SLM 也稱為 n 元語言模型,例如 bigram 和 trigram 語言模型。廣泛應用于信息檢索和自然語言處理,但經常面臨維數災難的困擾。因此需要專門設計平滑策略,如回退估計和古德圖靈估計已被引入以緩解數據稀疏問題。
2、神經語言模型 (NLM)
自然語言處理領域中,循環神經網絡(RNN)等神經網絡模型被廣泛應用于描述單詞序列的概率。早期工作引入了詞的分布式表示概念,并基于分布式詞向量來構建詞預測函數,作為該領域的重要貢獻。后續研究擴展了學習詞語和句子有效特征的思路,開發出通用的神經網絡方法,為各類自然語言處理任務建立統一的解決方案。另外,word2vec提出使用簡化的淺層神經網絡來學習分布式詞表示,這些表示在多種自然語言處理任務中展現出非常有效。以上研究將語言模型應用于表示學習領域,而不僅限于詞序列建模,對自然語言處理產生了深遠影響。
3、預訓練語言模型 (PLM)
PLM通過在大規模語料上預訓練獲取語義表示,然后微調到下游任務。Transformer等結構的引入極大提高了性能。“預訓練-微調”成為自然語言處理的重要范式。
4、大語言模型 (LLM)
大語言模型繼續擴大模型和數據規模,展示出小模型所不具備的強大語言能力。GPT-3等模型表現出驚人的上下文學習能力。ChatGPT成功地將大語言模型應用到開放領域對話。
相比預訓練語言模型(PLM),大語言模型(LLM)有三大關鍵區別:
1)LLM展現出PLM不具備的驚人涌現能力,使其在復雜任務上表現強大
2)LLM將改變人類開發和使用AI系統的方式,需要通過提示接口訪問
3)LLM的研究和工程界限不再明確。LLM技術正在引領AI、自然語言處理、信息檢索和計算機視覺等領域的變革,基于LLM的實際應用生態正在形成。
但是,LLM的內在原理與關鍵因素還有待進一步探索,訓練大規模的LLM非常困難,將LLM與人類價值觀保持一致也面臨挑戰。因此需要更多關注LLM的研究和應用。
二、概述
下面將概述大語言模型(LLM)的背景,并概括GPT系列模型的技術演進歷程。
1、大語言模型的背景
大語言模型(LLM)通常指在大規模文本數據上訓練的、包含數千億級(或更多)參數的Transformer結構語言模型,比如GPT-3、PaLM、Galactica、LLaMA和LLaMA2等。LLM展示了強大的語言理解能力和通過文本生成解決復雜任務的能力。為快速理解LLM的工作原理,下面將介紹LLM的基本背景,包括擴展法則、涌現能力和關鍵技術。
1)大語言模型的擴展法則
目前大語言模型主要建立在Transformer架構之上,其中多頭注意力機制層堆疊在非常深的神經網絡中。現有的大語言模型采用類似的Transformer結構和與小型語言模型相同的預訓練目標(如語言建模),但是大語言模型大幅擴展模型規模、訓練數據量和總計算量(數量級上的提升)。大量研究表明擴展規模可以顯著提高語言模型的能力。因此,建立一個定量的方法來描述擴展效應很有意義。
KM擴展法則:2020年OpenAI團隊首次提出神經語言模型的性能與模型規模、數據集規模和訓練計算量之間存在冪律關系。在給定計算預算下,根據實驗提出三個公式來描述擴展法則。
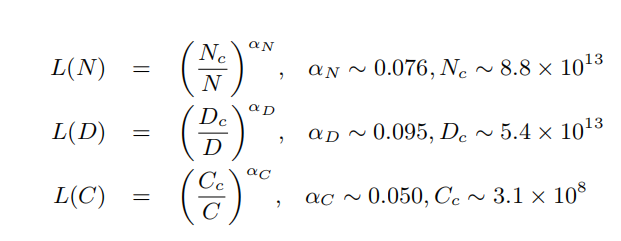
這里L是用自然對數表示的交叉熵損失。上述三個規律是通過擬合不同數據量、不同模型大小和不同訓練計算量條件下的語言模型性能得出。結果表明模型性能與這三個因素存在非常強的依賴關系。
Chinchilla擴展法則:Google DeepMind團隊提出了另一種替代的擴展法則形式,用于指導大語言模型的最優訓練計算量。通過變化更大范圍的模型規模和數據量進行嚴格的實驗,并擬合出一個類似的擴展法則,但具有不同的系數:
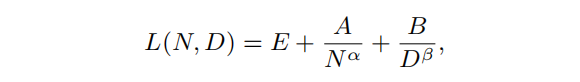
在該法則中E、A、B、α和β為經驗確定的系數。研究人員進一步在訓練計算量約束C ≈ 6ND的條件下,通過優化損失函數L(N,D)展示如何最優地在模型規模和數據量之間分配計算預算的方法。
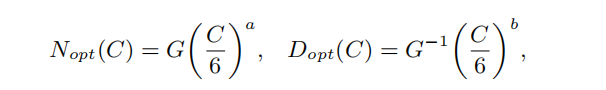
這里G是根據系數A、B、α和β計算得到的擴展系數。如文獻分析隨著給定計算預算的增加,KM擴展法則更傾向于將預算分配給模型規模,而Chinchilla擴展法則認為應該以相近的比例增加模型和數據規模。盡管存在一些局限性假設,這些擴展法則提供了對擴展效應的直觀理解,可以用于訓練過程中預測語言模型的性能。但是一些能力(如上下文學習)無法完全根據擴展法則預測,只有模型超過一定規模后才會出現。
大語言模型的關鍵特征之一是展現出預訓練語言模型所不具備的涌現能力,即只有模型達到一定規模后才出現的全新能力。當涌現能力出現時,性能會突然顯著提升,超過隨機水平,類似于物理學中的相變現象。涌現能力可以與復雜任務相關,需要關注那些能廣泛解決任務的通用能力。下面簡要介紹大語言模型的三種典型涌現能力和相關的代表性模型。
上下文學習:GPT-3首次提出這種能力,即只需要提供語言指令和少量示例,模型就可以生成預期的輸出,無需額外訓練。但這個能力與模型規模相關,需要達到一定參數量才會出現。
指令遵循:通過指令微調,大語言模型可以在完全未見過的任務上,僅根據語言描述就進行泛化。當模型超過680億參數后,這種能力才會顯著提升。不同模型對這種能力的掌握也有差異。
逐步推理:小模型難以解決需要多步推理的復雜任務,而大語言模型可以通過提供中間推理步驟的思維鏈提示來完成這類任務。當模型超過600億參數時,這種提示帶來的效果才會顯著。不同任務對這種能力的依賴程度也不同。
2)大語言模型的關鍵技術
經過長期發展大語言模型(LLM)進化到目前通用且具備強大能力的階段。主要技術進展包括:
擴展:增加模型、數據規模以及訓練計算量,可以顯著提升LLM的能力。合理利用擴展定律指導資源分配也很重要。
訓練:分布式訓練算法對成功訓練大模型至關重要。一些優化框架和技巧可以促進大規模分布式訓練。
能力引導:設計恰當的提示策略可以激發LLM的潛在能力,但對小模型效果可能不同。
對齊微調:通過人機交互的強化學習,使LLM生成內容符合人類價值觀。
工具操作:利用外部工具彌補LLM的局限,類似其“眼睛和耳朵”,可以擴展能力范圍。
此外,許多其他因素(例如硬件升級)也對 LLM 的成功 做出了貢獻。但是,我們主要討論在開發 LLM 方面的主要技 術方法和關鍵發現。
2、GPT 系列模型的技術演進
ChatGPT因其與人類交流的出色能力受到廣泛關注。它基于功能強大的GPT模型開發,對話能力得到了專門的優化。考慮到人們對ChatGPT和GPT模型的濃厚興趣,本文特別總結了GPT系列模型在過去幾年中的技術演進過程,以提高大眾的理解。總得來說OpenAI在大語言模型研究上經歷了以下幾個階段:
1)早期探索
根據OpenAI聯合創始人Ilya Sutskever的采訪,在OpenAI早期就已經探索過使用語言模型實現智能系統的想法,但當時試驗的是循環神經網絡(RNN)。隨著Transformer架構的出現,OpenAI開發出了兩個早期GPT模型:GPT-1和GPT-2,這些模型可以視為后來更強大的GPT-3和GPT-4的基礎。
GPT-1:在2018年,OpenAI基于當時新的Transformer架構,開發出第一個GPT模型。GPT-1采用Transformer解碼器結構,并使用無監督預訓練和有監督微調的方法,為后續GPT模型奠定基礎。
GPT-2:GPT-2在GPT-1的基礎上增加了參數量,達到150億,使用更大規模的網頁數據集進行訓練。通過無監督語言建模來完成下游任務,而不需要標注數據的顯式微調。
2)能力飛躍
盡管GPT-2旨在通過無監督訓練成為通用的多任務學習器,但與有監督微調的當前最優方法相比,其性能仍較弱。雖然GPT-2模型規模較小,經過微調后在下游任務尤其是對話任務中仍然取得廣泛應用。在GPT-2的基礎上,GPT-3通過擴大模型規模,實現了在類似生成式預訓練架構下的重大能力飛躍。
在2020年發布的GPT-3將模型規模進一步擴大到1750億參數。GPT-3論文正式提出上下文學習(In-Context Learning, ICL)的概念,即用小樣本或零樣本的方式使用語言模型。ICL本質上仍然是語言建模,只是預測的是完成給定任務的文本輸出。GPT-3不僅在NLP任務上表現強勁,在需要推理的任務上也展現出驚人的適應能力。盡管GPT-3論文沒有明確討論涌現能力,但可以觀察到其性能飛躍可能超越了基本的規模擴展法則,標志著從預訓練語言模型到大語言模型的重要進化。
3)能力增強
GPT-3成為OpenAI開發更強大語言模型的基礎,主要通過兩種方式進行改進:
使用代碼數據進行訓練:原始GPT-3在純文本上訓練,推理能力較弱。使用GitHub代碼微調可以增強其編程和數學問題解決能力。
與人類對齊:OpenAI早在2017年就開始研究如何從人類偏好中學習。他們使用強化學習方法訓練語言模型以符合人類期望。不僅提高了指令遵循能力,也能減輕有害內容生成。通過人機交互強化學習對齊語言模型與人類價值觀非常重要。
4)語言模型的重要里程碑
基于之前的探索,OpenAI取得兩個重要進展:ChatGPT和GPT-4,極大地提升AI系統的能力:
ChatGPT:2022年11月發布是對話優化的GPT模型,訓練方式類似InstructGPT。展現出與人交流的卓越能力和豐富知識,是目前最強大的聊天機器人,對AI研究影響重大。
GPT-4:2023年3月發布,支持多模態輸入,相比GPT-3.5有顯著提升,在各類困難任務上優于ChatGPT。通過迭代對齊,對惡意問題的響應也更安全。OpenAI采用各種策略減輕潛在風險。
盡管取得長足進步,這些語言模型仍存在局限,需要持續優化使其更強大和安全。OpenAI采用迭代部署策略來控制風險。
三、大語言模型資源
鑒于訓練大語言模型面臨的技術難題和計算資源需求,從零開始開發或復現大語言模型非常困難。一個可行的方法是在現有語言模型的基礎上進行增量開發或實驗研究。下面簡要總結用于開發大語言模型的公開可用資源,包括公開的模型Checkpoint、語料庫和代碼庫。
1、公開可用的模型檢查點或API
考慮到預訓練模型的高昂成本,公開的預訓練檢查點對研究組織開展大語言模型至關重要。參數規模是使用這些模型時需要考慮的關鍵因素。為幫助用戶根據計算資源選擇適當的研究方向,將公開的模型分為百億和千億參數兩個級別。另外,公開的API可以直接使用模型進行推理,無需本地運行。下面介紹公開的模型檢查點和API。
1)百億參數量級別的模型
百億參數量級的公開語言模型包括mT5、PanGu-α、T0、GPT-NeoX-20B、CodeGen、UL2、Flan-T5 和 mT0等,參數規模在100-200億之間。其中Flan-T5可用于指令微調研究,CodeGen專為生成代碼設計,mT0支持多語言。針對中文任務,PanGu-α表現較好。LLaMA是最近公開的模型,在指令遵循任務上展現卓越能力。這類規模的模型通常需要數百至上千個GPU/TPU。為準確估計所需計算資源,可使用計算量指標如FLOPS。
2)千億參數量級別的模型
千億參數量級的公開語言模型較少,主要有OPT、OPT-IML、BLOOM、BLOOMZ、GLM和Galactica。其中OPT用于復現GPT-3,BLOOM和BLOOMZ在多語言建模上表現較好,OPT-IML進行過指令微調。這類模型通常需要數千個GPU/TPU,比如OPT使用992個A100 GPU,GLM使用了96個DGX-A100節點。
3)大語言模型的公共API
相比直接使用模型,API提供更方便的方式使用大語言模型,無需本地運行。GPT系列模型的API已經被廣泛使用,包括ada、babbage、curie、davinci等。其中davinci對應GPT-3最大模型。此外還有與Codex相關的代碼生成API。GPT-3.5系列新增text-davinci-002等接口。gpt-3.5-turbo-0301對應ChatGPT。最近,GPT-4的API也發布。總體來說,接口選擇取決于具體應用場景和響應需求。
2、常用語料庫
與小規模預訓練語言模型不同,大語言模型需要更大量且內容廣泛的數據進行訓練。為滿足這一需求,越來越多的公開數據集被發布用于研究。這里簡要概述一些常用的大語言模型訓練語料庫,根據內容類型分為六類:Books、CommonCrawl、Reddit Links、Wikipedia、Code、Others。
1)Books
BookCorpus包含超過1.1萬本電子書,覆蓋廣泛的主題,被早期小規模模型如GPT和GPT-2使用。Gutenberg語料包含超過7萬本各類文學作品,是目前最大的公開書籍集合之一,被用于訓練MT-NLG和LLaMA等模型。而GPT-3中使用的未公開的Books1和Books2數據集規模更大。
2)CommonCrawl
CommonCrawl是最大的開源網絡爬蟲數據庫之一,已被廣泛運用于大型語言模型訓練。現有基于CommonCrawl的過濾數據集包括C4、CC-Stories、CC-News和RealNews。C4包括五個變種18,即 en,en.noclean ,realnewslike ,webtextlike 和 multilingual。其中,en 版本被用于預訓練 T5, LaMDA,Gopher和 UL2用于預訓練多個模型;CC-Stories和CC-News是CommonCrawl數據的子集,包含故事形式的內容;RealNews也被用作預訓練數據。
3)Reddit Links
Reddit是一個社交媒體平臺,用戶可以在上面提交鏈接和帖子。WebText是一個著名的基于Reddit的語料庫,由Reddit上高贊的鏈接組成。OpenWebText是易于獲取的開源替代品。PushShift.io是一個實時更新的數據集,包括自Reddit創建以來的歷史數據。提供有用的實用工具,支持用戶搜索、總結和對整個數據集進行初步統計分析。用戶可以輕松地收集和處理Reddit數據。
4)Wikipedia
Wikipedia是一個在線百科全書,包含大量高質量的文章,涵蓋各種主題。采用解釋性寫作風格并支持引用,覆蓋多種不同語言和廣泛的知識領域。Wikipedia英語版本被廣泛應用于大多數LLM(如GPT-3、LaMDA和LLaMA),還提供多種語言版本,可在多語言環境下使用。
5)Code
收集代碼數據的主要來源是從互聯網上爬取有開源許可證的代碼,包括開源許可證的公共代碼庫(如GitHub)和與代碼相關的問答平臺(如StackOverflow)。Google公開發布BigQuery數據集,包含各種編程語言的大量開源許可證代碼片段,是典型的代碼數據集。CodeGen使用的BIGQUERY是BigQuery數據集的一個子集,用于訓練多語言版本的CodeGen-Multi。
6)Others
The Pile是一個大規模、多樣化的開源文本數據集(超過800GB數據),包含書籍、網站、代碼、科學論文和社交媒體平臺等內容。由22個高質量的子集組成,被廣泛應用于不同參數規模的模型中,如 GPT-J(6B)、CodeGen(16B)和 Megatron-Turing NLG(530B)。此外,ROOTS是由各種較小的數據集組成的大型語料庫,覆蓋59種不同的語言,用于訓練BLOOM。
為了預訓練LLM,通常需要混合使用不同的數據源,如C4、OpenWebText和The Pile等,并從相關源(如Wikipedia和BigQuery)提取數據以豐富預訓練數據中的相應信息。為快速了解現有 LLM 使用的數據來源,下面介紹三個代表性 LLM 的預訓練語料庫:
GPT-3(175B)在混合數據集上進行訓練,包括 CommonCrawl、WebText2、Books1、Books2 和 Wikipedia。
PaLM(540B)使用由社交媒體對話、過濾后的網頁、書籍、Github、多語言維基百科和新聞組成的預訓練數據集,共包含 7800 億 token。
LLaMA從多個數據源中提取訓練數據,包括 CommonCrawl、C4、Github、Wikipedia、書籍、ArXiv 和 StackExchange。LLaMA(6B)、LLaMA(13B)和 LLaMA(32B)的訓練數據大小為 1.0 萬億 token,而 LLaMA(65B)使用了 1.4 萬億 token。
3、代碼庫資源
在這部分,簡要介紹一些可用于開發 LLM 的代碼庫。
1)Transformers
Transformers 是一個由 Hugging Face 開發的 Python 庫,采用 Transformer 架構。提供簡單易用的 API,方便用戶定制各種預訓練模型。該庫擁有龐大活躍的用戶和開發者社區,定期更新和改進模型和算法。
2)DeepSpeed
Microsoft 開發的深度學習優化庫(兼容 PyTorch),已被用于訓練多個 LLM,例如 MT NLG 和 BLOOM。支持分布式訓練優化技術,如內存優化(ZeRO 技術和梯度檢查點)和管道并行。
3)Megatron-LM
NVIDIA 開發的深度學習庫,用于訓練LLM。提供分布式訓練優化技術,如模型和數據并行、混合精度訓練和FlashAttention,可提高訓練效率和速度,實現高效分布式訓練。
4)JAX
Google 開發的 Python 庫,用于高性能機器學習算法運算。支持在硬件加速下進行數組高效運算,可在各種設備上進行高效計算,還支持自動微分和即時編譯等特色功能。
5)Colossal-AI
HPC-AI Tech開發的深度學習庫,用于訓練大規模人工智能模型。基于 PyTorch 實現,支持并行訓練策略和 PatrickStar 方法優化異構內存管理。最近發布 ColossalChat 類 ChatGPT 模型(7B 和 13B 版本)。
6)BMTrain
OpenBMB 開發的分布式訓練庫,強調簡潔代碼、低資源占用和高可用性。BMTrain 已在其 ModelCenter 中遷移常見 LLM(如 Flan T5 和 GLM),用戶可直接使用。
7)FastMoE
FastMoE是一種專門用于MoE模型的訓練庫,基于PyTorch開發,注重效率和用戶友好性。簡化了將Transformer模型轉換為MoE模型的過程,支持數據和模型并行訓練。
除了上述深度學習框架提供的資源外,其他框架如PyTorch、TensorFlow、MXNet、PaddlePaddle、MindSpore 和OneFlow也提供并行算法支持,通常用于訓練大規模模型。
四、數據收集
LLM 需要高質量數據進行預訓練,其模型能力也依賴預處理方式和預訓練語料庫。下面主要討論預訓練數據的收集和處理,包括數據來源、預處理方法以及對 LLM 性能的影響分析。
1、數據來源
開發有能力的LLM關鍵在于收集大量自然語言語料庫。現有LLM混合各種公共文本數據集作為預訓練語料庫,來源分為通用文本和專用文本。通用文本數據(如網頁、書籍和對話文本等)規模大、多樣性強且易于獲取,被大多數 LLM 所利用,可增強其語言建模和泛化能力。專用數據集(如多語言數據、科學數據和代碼等)可賦予 LLM 解決專用任務的能力。
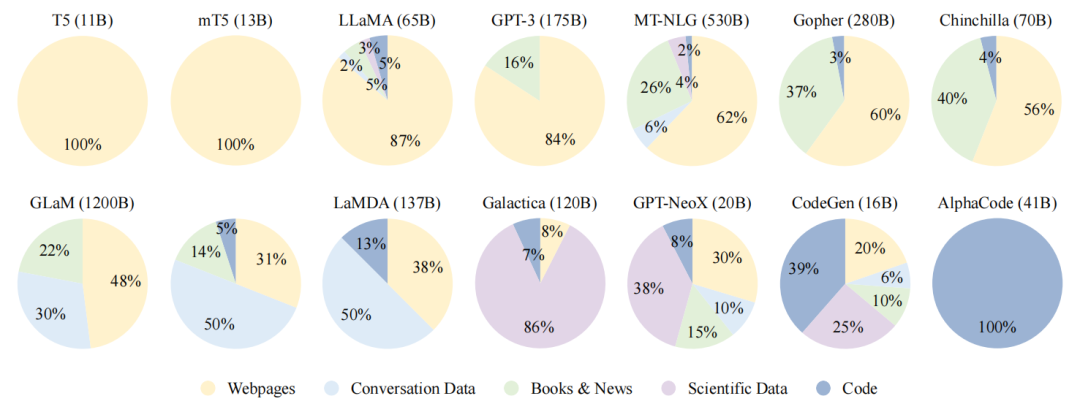
現有 LLM 預訓練數據中各種數據來源的比率
1)通用文本數據
通用預訓練數據是LLM模型中不可或缺的部分,提供豐富的文本資源和多樣的主題。其中,三種重要的通用文本數據包括網頁、對話文本和書籍。
網頁包括維基百科、新聞網站等,但需要過濾低質量內容。為提高數據質量,研究人員通常使用網絡爬蟲工具從互聯網上抓取大量數據,如CommonCrawl。這些數據可能同時包含高質量和低質量的文本,因此需要進行過濾和處理。
對話文本可以增強 LLM 的對話能力和問答任務的表現。研究人員可以利用公共對話語料庫的子集或從在線社交媒體收集對話數據。由于對話數據通常涉及多個參與者之間的討論,因此一種有效的處理方法是將對話轉換成樹形結構,將每句話與回應它的話語相連。通過這種方式,可以將多方之間的對話樹劃分為預訓練語料庫中的多個子對話。但是,過度引入對話數據可能會導致指令錯誤地被認為是對話的開始,從而降低指令的有效性。
書籍是另一種重要的通用文本數據來源,相對于其他語料庫,書籍提供更正式的長文本。這對于LLM學習語言知識、建模長期依賴關系以及生成敘述性和連貫的文本具有潛在的好處。現有的開源數據集包括Books3和Bookcorpus2,這些數據集可以在Pile數據集中獲得。
2)專用文本數據
專用數據集對提高LLM在特定任務中的能力非常有用。三種專用數據類型包括多語言文本、科學文本和代碼。
? 多語言文本:整合多語言語料庫可以增強模型的多語言理解和生成能力。例如,BLOOM和PaLM在其預訓練語料庫中收集包含46種和122種語言的多語言數據,這些模型在多語言任務中展現出色的性能,如翻譯、多語言摘要和多語言問答,并且與在目標語言上微調的最先進的模型具有可比性甚至更好的性能。
? 科學文本:科學出版物的不斷增長見證了人類對科學的探索。為增強LLM對科學知識的理解,可以將科學語料庫納入模型的預訓練語料,通過在大量科學文本上進行預訓練,LLM可以在科學和推理任務中取得出色的性能。現有的工作主要收集arXiv 論文、科學教材、數學網頁和其他相關的科學資源。由于科學領域數據的復雜性,例如數學符號和蛋白質序列,通常需要特定的標記化和預處理技術來將這些不同格式的數據轉換為可以被語言模型處理的統一形式。
?代碼:程序編寫在學術界和PLM應用中受到廣泛關注,但生成高質量和準確的程序仍具有挑戰性。最近研究顯示,在大量代碼語料庫上預訓練LLM可以提高編程質量,通過單元測試用例或解決競賽編程問題。預訓練LLM的代碼語料庫主要有兩種來源:編程問答社區和開源軟件倉庫。與自然語言文本不同,代碼以編程語言格式呈現,對應著長距離依賴和準確的執行邏輯。最近研究表明,訓練代碼可能是復雜推理能力的來源,并且將推理任務格式化為代碼的形式還可以幫助 LLM 生成更準確的結果。
2、數據預處理
收集大量文本數據后,對數據進行預處理是必要的,特別是消除噪聲、冗余、無關和潛在有害的數據,因為這些數據可能會影響 LLM 的能力和性能。下面將回顧提高數據質量的數據預處理策略。預處理 LLM 的預訓練數據的典型流程已在圖中說明。
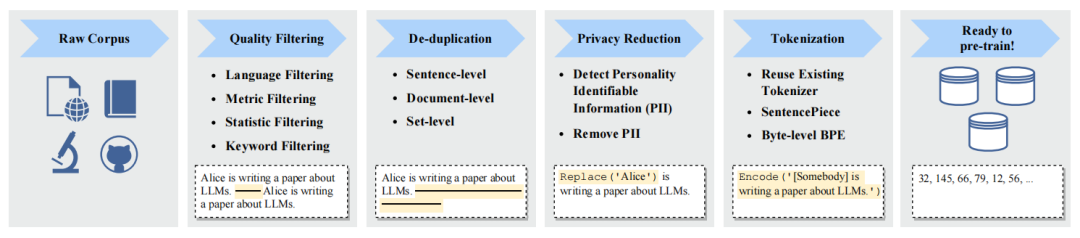
一個典型的預處理預訓練數據的流程圖
1)質量過濾
為刪除低質量數據,現有工作通常采用基于分類器或基于啟發式的方法。基于分類器的方法使用高質量文本訓練分類器,并預測每個數據的分數,從而過濾低質量數據。但這些方法可能會刪除方言、口語和社會語言的高質量文本,導致偏見和減少多樣性。基于啟發式的方法則通過設計一組規則來消除低質量文本,這些規則可以總結為:去除重復、無關或不完整的文本;去除拼寫錯誤、語法錯誤或非常規用詞的文本;去除缺乏上下文信息的文本等。
2)去重
現有研究發現,語料庫中的重復數據會影響模型多樣性和訓練過程穩定性,因此需要對預訓練語料庫進行去重處理。具體而言,可以在句子級、文檔級和數據集級等不同粒度上去重。在句子級別上,應刪除包含重復單詞和短語的低質量句子;在文檔級別上,可通過檢測重疊比率來刪除相似內容的重復文檔;同時,還需防止訓練集和評估集之間的重疊。這三個級別的去重都有助于改善 LLM 的訓練,應該共同使用。
3)隱私去除
大多數預訓練文本數據來自網絡來源,包括用戶生成內容涉及敏感或個人信息,可能增加隱私泄露風險。因此,需要從預訓練語料庫中刪除可識別個人信息(PII)。一種直接有效的方法是采用基于規則的方法,例如關鍵字識別,來檢測和刪除 PII 等敏感信息。此外,研究人員還發現,LLM 在隱私攻擊下的脆弱性可能歸因于預訓練語料庫中存在的重復 PII 數據。因此,去重也可以降低隱私風險。
4)分詞
分詞是數據預處理的關鍵步驟,將原始文本分割成詞序列,作為 LLM 的輸入。雖然已有的分詞器方便,但使用專為預訓練語料庫設計的分詞器更有效,特別是對于多領域、語言和格式的語料庫。最近的幾個LLM使用SentencePiece為預訓練語料庫訓練定制化的分詞器,并利用BPE算法確保信息不會丟失。但需要注意歸一化技術可能會降低分詞性能。
3、預訓練數據對大語言模型的影響
與小規模的PLM不同,大規模LLM通常無法進行多次預訓練迭代,因此在訓練之前準備充分的預訓練語料庫非常重要。下面將探討預訓練語料庫的質量、分布等因素如何影響LLM的性能。
1)混合來源
來自不同領域或場景的預訓練數據具有不同的語言特征或語義知識,混合不同來源的數據時需要仔細設置預訓練數據的分布。Gopher實驗表明增加書籍數據比例可以提高模型從文本中捕捉長期依賴的能力,增加C4數據集比例則會提升在C4驗證數據集上的性能。但單獨訓練過多某個領域的數據會影響LLM在其他領域的泛化能力。因此,建議研究人員應確定預訓練語料庫中來自不同領域的數據的比例,以開發更符合需求的 LLM。
2)預訓練數據的數量
為預訓練一個有效的 LLM,收集足夠的高質量數據很重要。現有研究發現,隨著 LLM參數規模的增加,需要更多的數據來訓練模型。許多現有的LLM由于缺乏充足的預訓練數據而遭受次優訓練的問題。通過廣泛的實驗表明,在給定的計算預算下,采用相等規模的模型參數和訓練token是必要的。LLaMA 研究表明,使用更多的數據和進行更長時間的訓練,較小的模型也可以實現良好的性能。因此,建議研究人員在充分訓練模型時,關注高質量數據的數量。
3)預訓練數據的質量
研究表明,對低質量的語料庫進行預訓練可能會損害模型性能。為了開發表現良好的 LLM,收集的訓練數據的數量和質量都至關重要。最近的研究已經表明數據質量對下游任務性能的影響。通過比較在過濾和未過濾的語料庫上訓練的模型的性能,得到了相同的結論,即在清理后的數據上預訓練LLM可以提高性能。更具體地說,數據的重復可能會導致“雙下降現象”,甚至可能會使訓練過程不穩定。此外,重復的數據會降低 LLM 從上下文中復制的能力,進一步影響 LLM 在 ICL 中的泛化能力。因此,研究人員有必要仔細地對預訓練語料庫進行預處理來提高訓練過程的穩定性,并避免其對模型性能的影響。
五、大語言模型的適配微調
預訓練后的LLM可以獲得解決各種任務的通用能力,LLM 的能力可以進一步適配到特定的目標。下面將介紹兩種適配預訓練后的 LLM 的方法:指令微調和對齊微調。前者旨在增強 LLM 的能力,后者則旨在將LLM的行為與人類價值觀或偏好對齊。
1、指令微調
指令微調是在自然語言格式的實例集合上微調預訓練后的 LLM 的方法。收集或構建指令格式的實例后,使用有監督的方式微調LLM,例如使用序列到序列的損失進行訓練。微調后LLM 可以展現出泛化到未見過任務的能力,即使在多語言場景下也有不錯表現。
1)格式化實例的構建
指令格式的實例包括任務描述、輸入輸出和示例。現有研究已經發布帶標注的自然語言格式的數據,是重要的公共資源。
格式化已有數據集:早期的幾項研究工作是在不同領域收集實例,創建有監督的多任務訓練數據集以進行多任務學習。即利用人類撰寫的自然語言任務描述來為這些數據集添加格式化,以指導語言模型理解不同的任務。例如,每一個問答任務都添加了"請回答以下問題"的描述。指令被證明是影響語言模型任務泛化能力的關鍵因素。為了指令調優生成更好的標注數據,一些工作采用逆向輸入輸出的方法,即反轉已有的輸入輸出設計指令。還有一些工作利用啟發式模板將大量無標注文本轉換為帶標注的實例。
格式化人類需求:盡管已經通過添加指令格式化了大量訓練數據,但這些數據主要來自公共NLP數據集,缺乏多樣性和與真實需求的匹配。為了解決這個問題,一些工作采用了用戶提交給OpenAI API的真實查詢作為任務描述。這些用自然語言表達的查詢很適合引導語言模型遵循指令的能力。此外,還讓標注者為真實生活中的任務編寫各種指令,如開放式生成、問答、頭腦風暴和聊天等。然后讓其他標注者直接根據這些指令作為輸出進行回答。最后,將指令和期望輸出配對作為一個訓練實例。值得注意的是,這些真實世界任務還被用于對齊微調。另外一些工作將現有實例輸入語言模型生成指令和數據,以減輕人工標注的負擔,構建更多樣性的訓練數據。
構建實例的關鍵因素:指令實例的質量對模型的性能有重要影響。在此討論了一些實例構建中的關鍵因素。
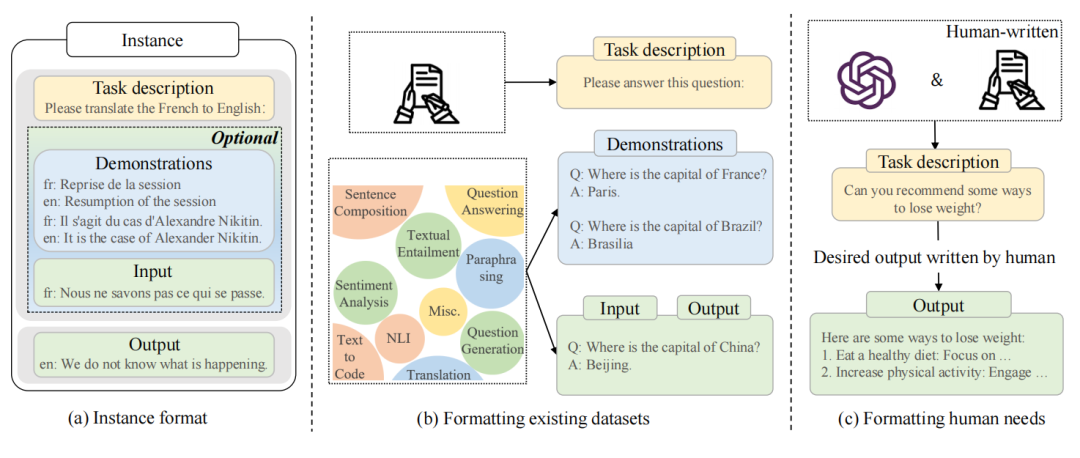
格式化實例和兩種構造指令格式實例的方式的示意圖
增加指令數量:大量研究結果表明,擴充任務數量可以顯著提高大語言模型的泛化能力。隨著任務數量的增加,模型性能一開始持續提高,但當任務數量達到一定水平后,模型性能提升變得微乎其微。一個合理的猜想是,一定數量的代表性任務就可以提供相對充足的知識,繼續添加更多任務收益有限。此外,從任務描述的長度、結構、創造性等多個維度增強任務的多樣性也是有益的。關于每個任務需要的實例數量,已有研究發現少量實例通常就可以使模型達到泛化性能飽和。然而,對某些任務大幅增加實例數量(例如數百個)可能會導致過擬合,影響模型性能。
指令格式的設計也很重要:通常可以在輸入輸出對中添加任務描述和示例。適當數量的示例有助于模型理解,也降低了對指令工程的敏感性。但是過多無關內容的添加反而可能適得其反。含有鏈式推理的指令可以提高模型的推理能力。
2)指令微調策略
與預訓練不同,指令微調由于只需要少量實例進行訓練,因此通常更加高效。指令微調可以視為一個有監督的訓練過程,其優化過程與預訓練存在一些區別,例如訓練目標函數(如序列到序列的損失函數)和優化參數設置(如更小的批量大小和學習率)。這些細節在實踐中需要特別注意。除了優化參數設置,指令微調還需要考慮以下兩個重要方面:
數據分布平衡:由于涉及多種任務混合,需要平衡不同任務的數據比例。一種方法是將所有數據合并后按比例采樣。通常會給高質量數據如FLAN更高的采樣比例,并設置最大容量限制樣本總數,防止大數據集占據采樣集合。
結合預訓練:一些方法在指令微調中加入預訓練數,作為正則化。還有方法不分階段,而是從頭用多任務學習方式同時訓練預訓練數據和指令格式數據。一些模型也將指令數據作為預訓練語料的一小部分來進行預訓,以同時獲得預訓練和指令微調的優勢。
3)指令微調的效果
指令微調對語言模型有以下兩個主要影響:
性能改進:指令微調可以顯著提高不同規模語言模型的能力,即使在小數據集上微調也有明顯效果。微調過的小模型有時甚至優于原大模型。指令微調提供了一種提升現有語言模型能力的通用高效方法。
任務泛化:指令微調賦予模型遵循人類自然語言指令完成任務的能力,即使是未見過的任務也可以泛化執行。已證實它能增強模型在見過和未見過任務上的表現。指令微調還能幫助緩解語言模型的一些弱點,提高解決真實世界任務的能力。經微調的模型可以將英文任務的能力泛化到其他語言相關任務上,甚至只用英文指令就能取得可滿意的多語言任務表現。
2、對齊微調
這部分首先介紹對齊微調的背景,包括定義和評估標準;然后重點討論用于對齊語言模型的人類反饋數據的收集方法;最后探討利用人類反饋進行強化學習以實現對齊微調的關鍵技術。
1)對齊微調的背景和標準
語言模型在許多自然語言處理任務上展示了強大的能力,但有時也可能表現出不符合預期的行為,如生成虛假信息、追求不準確的目標以及產生有害、誤導或帶有偏見的輸出。預訓練語言模型的目標是語言建模,沒有考慮到人類的價值觀,因此需要進行對齊微調以使模型行為符合人類期望。
對齊微調的標準與預訓練和其他微調不同,更加主觀和復雜,如有用性、誠實性和無害性。這些標準難以直接作為優化目標,需要采用特定的技術實現。有用性要求模型用簡明高效的方式解決用戶的問題和回答問題,并展示提出恰當問題獲取更多信息的能力。定義和測量有用性具有挑戰性;誠實性要求提供準確內容而不捏造,需要傳達不確定性。相對更客觀,依賴人力可能更少;無害性要求不生成冒犯或歧視語言,檢測并拒絕惡意請求,依賴于使用背景。
2)人類反饋的收集
選擇合適的標注人員很重要,需要教育水平高、英語能力強的母語使用者,最好有相關學歷。還需要評估標注員產出與研究人員預期的一致性,選擇一致性最高的人員進行標注工作,并在標注過程中提供詳細指導。主要有以下三種方法收集人類反饋:
基于排序的方法:讓標注員對模型生成的多個候選輸出結果進行排序,得到一個偏好排名,根據這個排名調整模型傾向排名較高的輸出。相比只選擇單個最佳輸出,可以獲取更豐富的偏好信息。
基于問題的方法:研究人員設計特定的問題,標注員需要回答這些問題對模型輸出進行評估,問題設計需要覆蓋各種對齊標準。可以獲得比排序更詳細的反饋信息。
基于規則的方法:研究人員制定一系列規則,測試模型輸出是否違反這些規則,標注員需要對違反程度進行定量的規則評分。可以直接獲得是否符合對齊標準的反饋。
強化學習是對齊微調中一個重要的技術,可以學習并優化模型根據人類反饋達到對齊標準。下面將詳細討論基于人類反饋的強化學習方法。
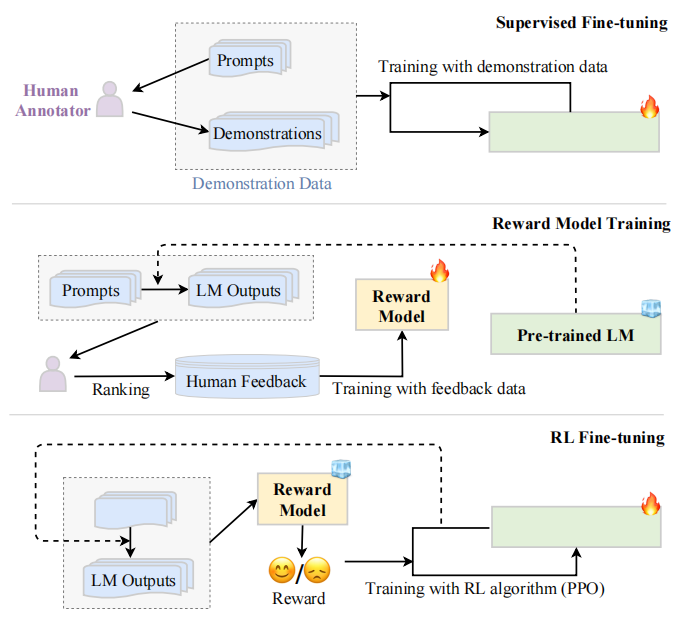
RLHF 算法工作流
3)基于人類反饋的強化學習
為了確保 LLM 與人類價值觀一致,人們提出了使用收集到的人類反饋數據對 LLM 進行微調的方法,稱為 RLHF。這種方法采用強化學習算法(如 PPO),通過學習獎勵模型使 LLM 適應人類反饋。這種方法將人類納入訓練循環中,以開發良好的 LLM,如 InstructGPT。
基于人類反饋的強化學習系統:PLM 通常是一個生成模型,使用現有的 PLM 參數進行初始化。獎勵模型提供指導信號,反映人類對 LM (Language Model)生成文本的偏好。現有工作通常采用與要對齊的 LM(Language Model) 具有不同參數尺度的獎勵模型。最后,為了使用來自獎勵模型的信號優化 PLM,設計了一種特定的 RL 算法用于大規模模型的微調。具體來說,PPO 是一種在現有工作中廣泛使用的 RL 對齊算法。
基于人類反饋的強化學習的關鍵步驟:
3、高效微調
本節將討論如何對大模型(如 Transformer)進行高效微調。下面將回顧幾種代表性的參數高效微調方法,并總結現有關于參數高效微調 LLM 的工作。
1)參數高效微調方法
Transformer語言模型參數高效微調的幾種主要方法:
適配器微調:在Transformer模型中插入小型的適配器模塊,可以壓縮并映射特征向量。適配器可以串行或并行連接在注意力層和前饋層之后。在微調時只優化適配器參數,固定原始語言模型參數。
前綴微調:在每個Transformer層前面添加一組可訓練的前綴向量,作為額外的任務特定參數。使用重參數化技巧學習映射前綴的小矩陣,而不是直接優化。只優化前綴參數以適配下游任務。
提示微調:在輸入層加入軟提示token,以嵌入的形式加到輸入文本中。只優化提示嵌入來適配特定任務。利用提示的自由格式設計。
低秩適配:用低秩分解矩陣來近似每層的網絡參數更新矩陣。固定原始參數,只訓練低秩分解中的兩小型可適配矩陣。
各方法優勢不同,但共同點是只優化很少的參數來適配下游任務,固定語言模型大部分參數,實現參數高效的微調。
2)大語言模型上的參數高效微調
隨著大語言模型(LLM)的興起,研究者們越來越關注高效微調方法,以開發更輕量級適用于各種下游任務的適配方法。其中,LoRA方法在開源LLM(如LLaMA和BLOOM)中得到廣泛應用,用于實現參數高效微調。LLaMA及其變體因其參數高效微調而備受關注。例如,Alpaca-LoRA是Alpaca的輕量級微調版本,Alpaca是一個經過微調的70億參數的LLaMA模型,包含5.2萬個人類指示遵循演示。對于Alpaca-LoRA,已經在不同語言和模型大小方面進行了廣泛的探索。
此外,LLaMA-Adapter方法在每個Transformer層中插入可學習的提示向量,其中提出了零初始化的注意力,以減輕欠擬合提示向量的影響,從而改善訓練效果。此方法還被擴展到多模態設置,如視覺問答。
六、總結與未來方向
理解和解釋語言模型的涌現能力是一個重要而又有挑戰的問題。隨著模型規模的擴大,像鏈式推理這樣的能力會突然出現,但其機制還不清楚。探索涌現能力的影響因素和理論解釋是當前的研究熱點。然而,更多正式的理論和原理還需建立,比如從復雜系統的角度解釋語言模型。解讀語言模型的能力和行為仍是一個值得探討的基本問題,也是發展下一代模型的關鍵所在。需要跨學科視角,以期獲得更深入的理解和解釋。
構建更高效的Transformer變體和減輕災難性遺忘是未來改進語言模型架構的兩個重要方向。由于標準自注意力復雜度高,需要探索更高效的注意力機制。另外,微調語言模型時原有知識很容易被新數據覆蓋并遺忘。所以需要通過引入更靈活的機制或模塊,支持模型進行數據更新和任務專用化,同時保留原有通用能力。擴展現有架構使其既適應新任務又不遺忘舊知識是語言模型面臨的關鍵挑戰。
盡管能力強大,大語言模型仍面臨小模型類似的安全性挑戰,如產生錯誤信息、被利用產生有害內容等。主要的對策是通過人類反饋進行對齊優化,但目前的強化學習方法嚴重依賴大量高質量人類標注。
隨著大規模語言模型(LLM)在各種任務中展現出強大的能力,正在廣泛應用于現實世界的各種應用中,包括遵循自然語言指令的特定任務。ChatGPT作為一個重要的進步,已經改變了人們獲取信息的方式,并在"New Bing"發布中得到了體現。在不久的將來,可以預見LLM將對信息檢索技術產生重大影響,包括搜索引擎和推薦系統。此外,智能信息助手的開發和使用將隨著LLM技術的升級而得到廣泛推廣。從更廣泛的視角來看,這一技術創新浪潮將形成一個以LLM為支持的應用生態系統,例如ChatGPT對插件的支持,與人類的生活息息相關。
我國算力發展的現狀
為了推動算力基礎設施建設,促進各行各業的數字化轉型,工業和信息化部與寧夏回族自治區人民政府于8月18日至19日在寧夏銀川舉辦了2023中國算力(基礎設施)大會。該大會旨在持續推動數字經濟與實體經濟的深度融合,為高質量發展注入強勁動力。
一、AI 發展持續深化,帶動算力基礎設施建設加速推進
工信部近年來一直致力于推動算力基礎設施建設,并持續加強算力頂層設計。他們發布了多項政策文件,如《“十四五”信息通信行業發展規劃》和《新型數據中心發展三年行動計劃》,以優化全國算力布局,推動算力基礎設施建設和應用。工信部還計劃根據算力行業的最新發展情況,出臺政策文件,促進算力基礎設施的高質量發展,提升算力供給能力。這些舉措加速了算力基礎設施建設,為數字經濟的發展奠定了堅實的基礎。
在2023中國算力大會上指出兩個重要方面的發展需求。一方面,要增強自主創新能力,推動計算架構、計算方式和算法的創新,加強CPU、GPU和服務器等關鍵產品的研發,加快新技術和新產品的應用。另一方面,要加強算力相關軟硬件生態系統的建設,提升產業基礎的高級化水平,推動產業鏈上下游的協同發展,共同構建良好的發展生態。
截至2022年底,我國擁有超過650萬架標準機架,總算力規模達到180EFLOPS,僅次于美國,存儲總規模超過1000EB(1萬億GB)。在人工智能AI發展的浪潮下,我國不斷加強CPU、GPU和服務器等關鍵產品的研發,算力發展的動能有望持續增強,國產算力產業鏈上下游有望共同迎來快速發展。
中國人工智能應用場景發展
中國人工智能行業在2022年取得顯著的進展,應用滲透度不斷提高,應用場景也在不斷拓寬,特別是在金融和電信等行業,人工智能的應用滲透度明顯增加。智能客服、實體機器人、智慧網點和云上網點等場景的廣泛應用,使金融行業的人工智能滲透率提高到62%;而電信行業的滲透度從45%增長到51%,人工智能技術為下一代智慧網絡建設提供了重要支持。據國際數據公司(IDC)預測,到2023年年底,中國制造業供應鏈環節中將有50%采用人工智能技術。隨著時間的推移,智能化場景在各行業的落地將呈現出更加深入、更加廣泛的趨勢。
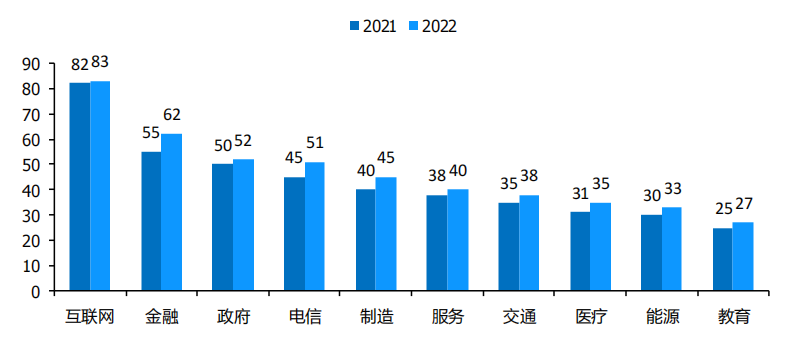
人工智能行業滲透率(%)
隨著大模型在人工智能領域的崛起,智能算力需求呈現幾何級增長的趨勢。中國的互聯網巨頭和科技巨頭紛紛推出自主研發的大模型,如百度的文心大模型、華為的盤古大模型、阿里巴巴的通義大模型等。這些大模型具有數千億甚至萬億級別的參數,需要大量高質量的訓練數據以及龐大的算力支持。隨著大模型的復雜性不斷提高、數據規模的迅速增長以及應用場景的持續拓展和深化,智能算力的需求和規模必將在未來幾年迎來爆發式增長。根據OpenAI的估算,自2012年以來,全球頂尖AI模型訓練所需算力每3-4個月翻一番,每年的增長幅度高達10倍。

大模型訓練算力需求
智能算力的規模正在持續擴大,同時建設算力基礎設施已成為共識。根據IDC與浪潮信息聯合發布的《2022-2023中國人工智能計算力發展評估報告》,中國的人工智能計算力將快速持續增長。截至2022年,中國的智能算力規模已達到268百億億次/秒(EFLOPS),預計到2026年,中國的智能算力規模將達到1271.4EFLOPS,未來五年的復合增長率預計為52.3%,而通用算力規模的復合增長率為18.5%。在國家層面上,已經啟動了在8個地區建設國家算力樞紐節點的計劃,并規劃10個國家數據中心集群,以實現資源的有效整合,促進產業結構調整,構建更加健全的算力和算法基礎設施。
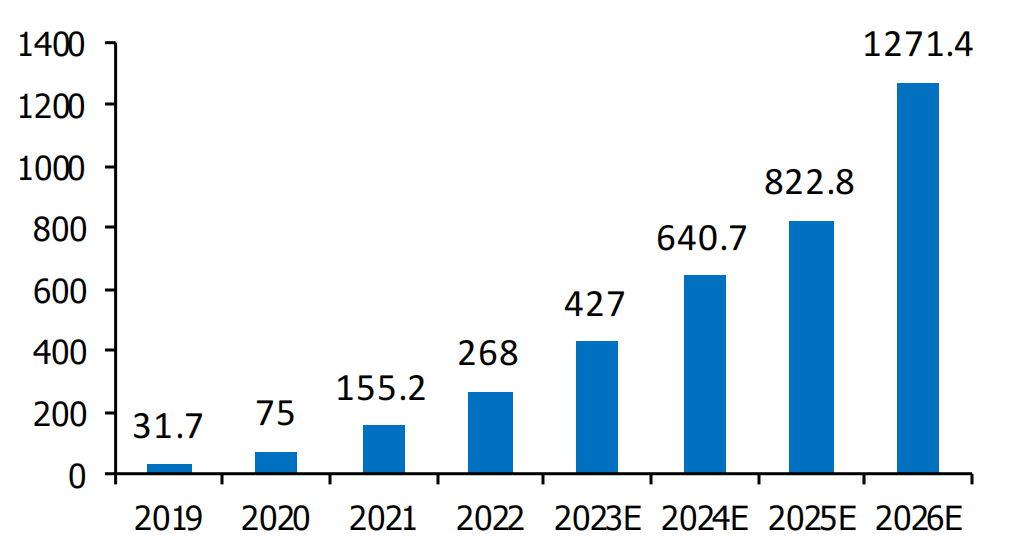
中國智能算力規模及預測(EFLOPS)
二、算力需求與芯片能力存在剪刀差,AI 發展將對芯片性能提出更高要求
由于多樣化的人工智能應用場景的需求,傳統以CPU為主的通用計算能力已經不足以滿足要求。因此,采用CPU與AI芯片(如GPU、FPGA、ASIC)組成的異構計算方案已成為當前和未來智能計算的主要解決方案。異構計算方案需要大量的AI芯片,這些芯片具有出色的并行計算能力和高互聯帶寬,能夠最大化支持AI計算的效能。根據前瞻產業研究院的預測,中國的人工智能芯片市場規模將在2023年至2027年持續增長。到2024年,中國的人工智能芯片市場規模將突破1000億元;到2027年,市場規模將達到2881.9億元。
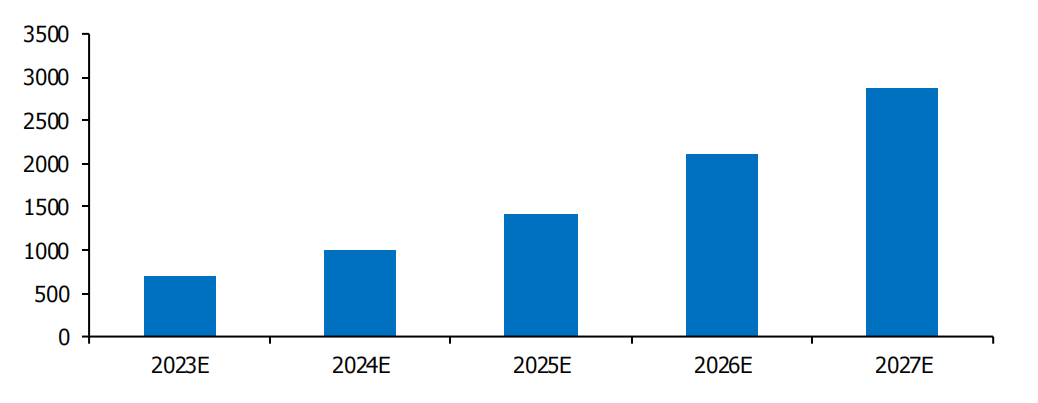
2023-2027 中國人工智能芯片市場規模預測(億元)
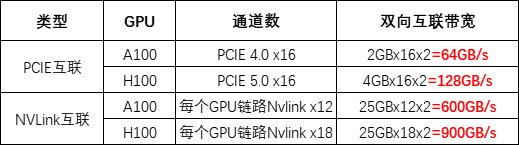
AI芯片算力競賽正如火如荼地展開,各家公司紛紛推出新產品。在6月13日,AMD發布了全新的人工智能GPU Instinct MI300,并計劃在今年晚些時候向一部分客戶發貨。這款處理器是AMD專為大型語言模型進行優化的版本,擁有驚人的1530億個晶體管數量,192GB內存和5.2TB/s的內存帶寬,以及896GB/s的Infinity Fabric帶寬。而在8月8日,英偉達則宣布推出下一代NVIDIA GH200 Grace Hopper平臺,這是全球首款配備HBM3e內存的GPU芯片。HBM3e內存將使下一代GH200在運行AI模型時速度比當前快3.5倍。這些高容量的GPU有助于降低AI訓練成本。
英偉達 GH200
行業龍頭以歐美日等為主,國產化替代勢在必行。根據中研普華產業研究院數據顯示, 目前全球人工智能芯片行業前十以歐美韓日等企業為主,其中前三為 Nvidia、Intel 及 IBM。國內芯片企業如華為海思排 12 位,寒武紀排 23 位,地平線機器人排 24 位。當前競爭格局下,隨著國內外大模型的加速發展及垂類融合,國內 AI 算力芯片廠商將迎來產業發展機會。
三、3方協同助力算力基礎設施,深化構建“東數西算”工程
在2023年中國算力大會新聞發布會上,工業和信息化部副部長張云明介紹了近年來在構建高質量算力供給體系方面所取得的積極成果。為了提升算力基礎設施的綜合能力,各方積極合作,采取多種措施,取得了三個方面的積極成效。
1)算力發展規劃政策相繼出臺,制度保障有力有效。工信部、發改委等部門聯合印發了《全國一體化大數據中心協同創新體系算力樞紐實施方案》,并批復同意在8個地區建設10個國家算力樞紐節點。同時,還出臺了《新型數據中心發展三年行動計劃(2021-2023年)》,以持續優化全國算力的整體布局。
2)算力基礎設施建設扎實推進,發展動能持續增強。為了支撐數字經濟的發展,產業各方緊密協同,加快了基礎設施建設、算力體系構建和綠色發展。從2018年開始,我國數據中心的機架數量年復合增長率超過30%。截至2022年底,標準機架數量超過650萬架,總算力規模達到180EFLOPS,僅次于美國。同時,存儲總規模超過1000EB(1萬億GB)。這些數據表明,我國在算力底座方面取得了顯著的成就。
3)算力賦能傳統產業轉型升級,融合應用加速涌現。目前,我國的算力產業已經初步形成規模,并且產業鏈上的企業在中下游之間展開了協同合作,形成了良性互動。算力不僅成為傳統產業轉型升級的重要支撐點,還催生了一批新的經濟增長點。根據中國信息通信研究院的測算,2022年我國算力核心產業規模達到了1.8萬億元。每投入1元的算力,將帶動3至4元的GDP經濟增長。這些數據表明,算力產業在我國的發展前景非常廣闊,并具有巨大的經濟潛力。
寧夏將擴大其算力樞紐的影響力,通過舉辦西部數字賦能大會和第二屆“西部數谷”算力產業大會來實現。作為西部地區首個以數字賦能為主題的產業大會,首屆“西部數谷”算力大會在2022年簽約了24個項目,總投資金額達727億元,目前已有18個項目開始實施。寧夏作為“東數西算”算力樞紐節點,在2023年6月已經建設了34.9萬架的數據中心標準機架,互聯網省際出口帶寬達到20.6Tbps,網絡水平在西部地區處于領先地位。
目前,算力結構以通算和存儲業務為主,占比達到61%。國家正在推進“東數西算”工程,通過構建新型算力網絡體系,將東部的算力需求有序引導到西部,優化數據中心建設布局,促進東西部的協同發展。8個國家算力樞紐節點將成為我國算力網絡的關鍵連接點,推動數據中心集群的發展,促進數據中心與網絡、云計算和大數據之間的協同建設,同時也是國家“東數西算”工程的戰略支點,推動算力資源有序向西部轉移。
藍海大腦大模型訓練平臺
藍海大腦大模型訓練平臺提供強大的算力支持,包括基于開放加速模組高速互聯的AI加速器。配置高速內存且支持全互聯拓撲,滿足大模型訓練中張量并行的通信需求。支持高性能I/O擴展,同時可以擴展至萬卡AI集群,滿足大模型流水線和數據并行的通信需求。強大的液冷系統熱插拔及智能電源管理技術,當BMC收到PSU故障或錯誤警告(如斷電、電涌,過熱),自動強制系統的CPU進入ULFM(超低頻模式,以實現最低功耗)。致力于通過“低碳節能”為客戶提供環保綠色的高性能計算解決方案。主要應用于深度學習、學術教育、生物醫藥、地球勘探、氣象海洋、超算中心、AI及大數據等領域。
一、為什么需要大模型?
1、模型效果更優
大模型在各場景上的效果均優于普通模型
2、創造能力更強
大模型能夠進行內容生成(AIGC),助力內容規模化生產
3、靈活定制場景
通過舉例子的方式,定制大模型海量的應用場景
4、標注數據更少
通過學習少量行業數據,大模型就能夠應對特定業務場景的需求
二、平臺特點
1、異構計算資源調度
一種基于通用服務器和專用硬件的綜合解決方案,用于調度和管理多種異構計算資源,包括CPU、GPU等。通過強大的虛擬化管理功能,能夠輕松部署底層計算資源,并高效運行各種模型。同時充分發揮不同異構資源的硬件加速能力,以加快模型的運行速度和生成速度。
2、穩定可靠的數據存儲
支持多存儲類型協議,包括塊、文件和對象存儲服務。將存儲資源池化實現模型和生成數據的自由流通,提高數據的利用率。同時采用多副本、多級故障域和故障自恢復等數據保護機制,確保模型和數據的安全穩定運行。
3、高性能分布式網絡
提供算力資源的網絡和存儲,并通過分布式網絡機制進行轉發,透傳物理網絡性能,顯著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用嚴格的權限管理機制,確保模型倉庫的安全性。在數據存儲方面,提供私有化部署和數據磁盤加密等措施,保證數據的安全可控性。同時,在模型分發和運行過程中,提供全面的賬號認證和日志審計功能,全方位保障模型和數據的安全性。
三、常用配置
1、處理器,CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
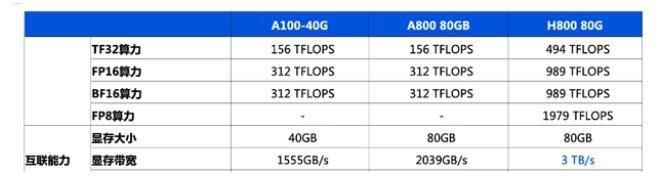
2、顯卡,GPU:
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 8-GPU 80GB
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW×8
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
4991瀏覽量
103138 -
gpu
+關注
關注
28文章
4742瀏覽量
128980 -
英偉達
+關注
關注
22文章
3778瀏覽量
91177 -
大模型
+關注
關注
2文章
2474瀏覽量
2775
發布評論請先 登錄
相關推薦
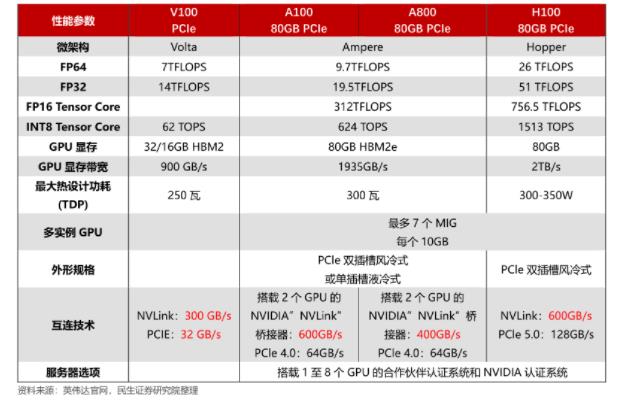
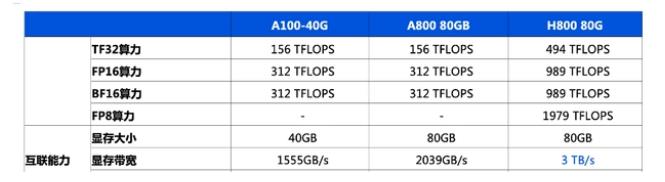
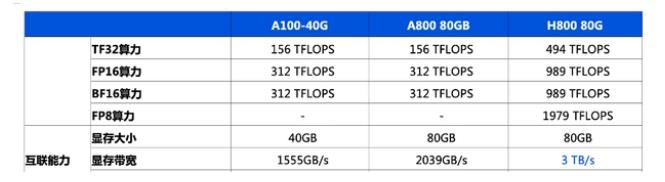
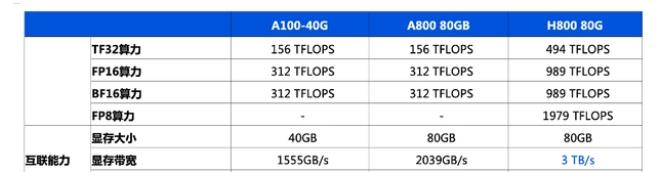
通往AGI之路:揭秘英偉達A100、A800、H800、V100在高性能計算與大模型訓練中的霸主地位

英偉達a100和h100哪個強?英偉達A100和H100的區別
英偉達將向中國推出芯片A800可替代被禁的A100
英偉達推出A800 GPU,為了能賣給中國客戶,對A100“砍了一刀”...
深度學習模型部署與優化:策略與實踐;L40S與A100、H100的對比分析





 工商網監
工商網監
評論