 YOLOv5網絡結構訓練策略詳解
YOLOv5網絡結構訓練策略詳解
前言
前面已經講過了Yolov5模型目標檢測和分類模型訓練流程,這一篇講解一下yolov5模型結構,數據增強,以及訓練策略。
網絡結構
Yolov5發布的預訓練模型,包含yolov5l.pt、yolov5l6.pt、yolov5m.pt、yolov5m6.pt、yolov5s.pt、yolov5s6.pt、yolov5x.pt、yolov5x6.pt等。
針對不同大小的網絡整體架構(n, s, m, l, x)都是一樣的,只不過會在每個子模塊中采用不同的深度和寬度,分別應對yaml文件中的depth_multiple和width_multiple參數。下面以yolov5l.yaml繪制的網絡整體結構為例。
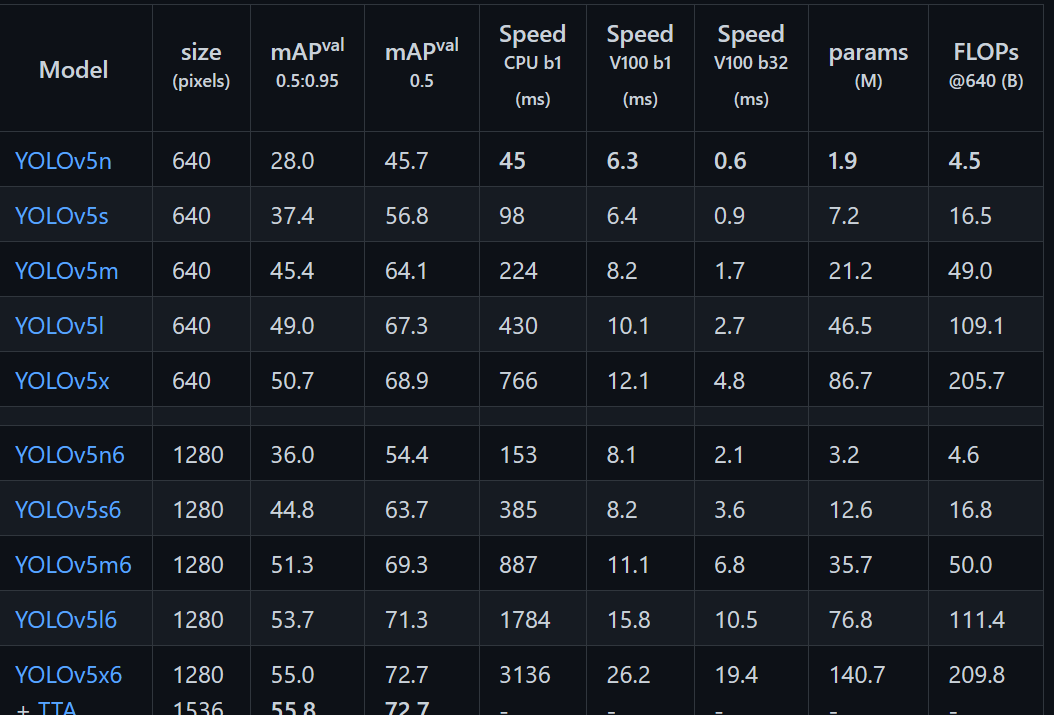
網絡結構圖:
網絡結構主要由以下幾部分組成:
(1)輸入端:Mosaic數據增強、自適應錨框計算、自適應圖片縮放
(2) Backbone: New CSP-Darknet53
(3)Neck: SPPF, New CSP-PAN
(4)輸出端:Head
官方網絡結構圖:
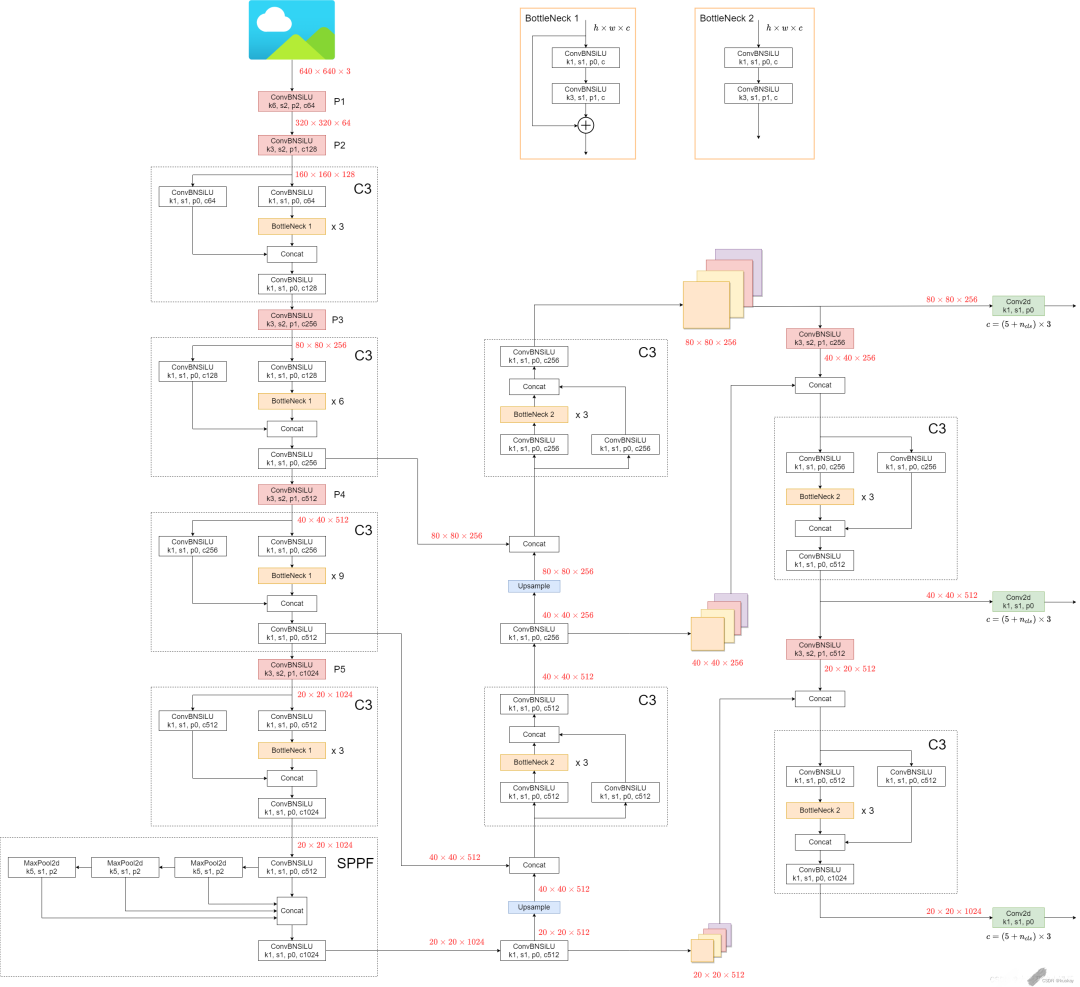
v5.x網絡結構:

v6.x網絡結構:
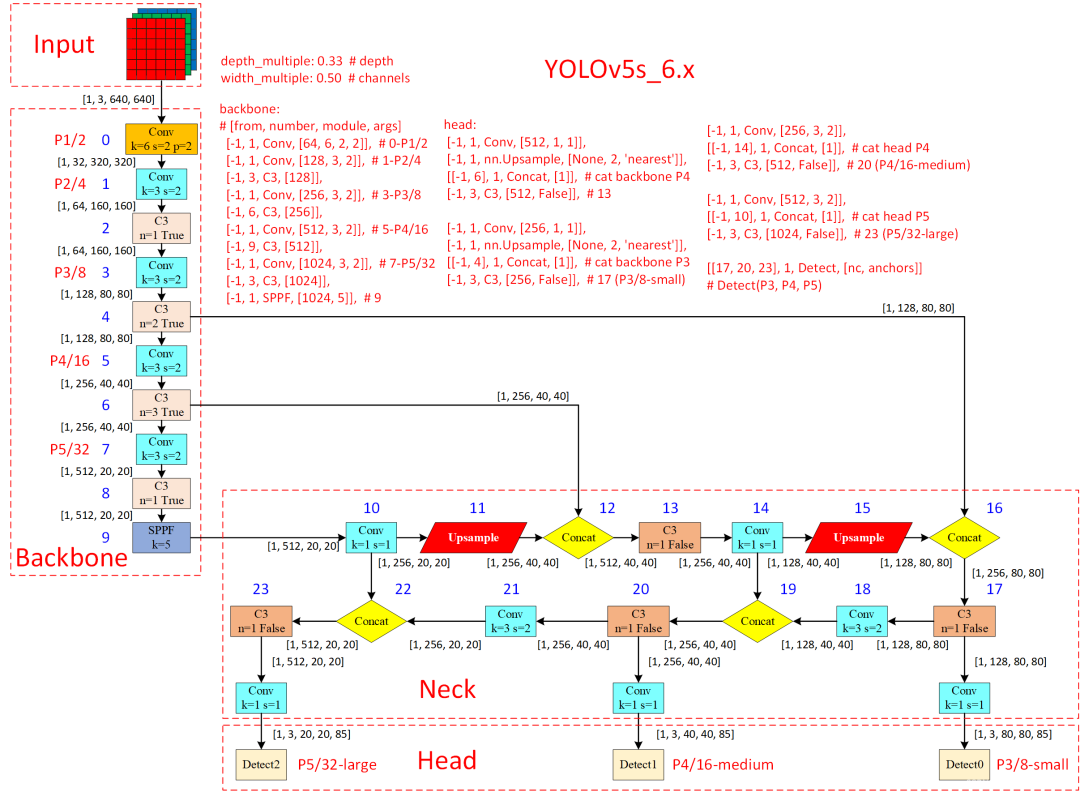
可以看出,相比于之前v5.x,最新版的v6.x網絡結構更加精簡(以提高速度和推理性能),主要有以下更新:
?Conv(k=6, s=2, p=2) 替換Focus,便于導出其他框架(for improved exportability)
?SPPF代替SPP,并且將SPPF放在主干最后一層(for reduced ops)
?主干中的C3層重復次數從9次減小到6次(for reduced ops)
?主干中最后一個C3層引入shortcut
yolov5s.yaml文件內容:
nc: 80 # number of classes 數據集中的類別數 depth_multiple: 0.33 # model depth multiple 模型層數因子(用來調整網絡的深度) width_multiple: 0.50 # layer channel multiple 模型通道數因子(用來調整網絡的寬度) # 如何理解這個depth_multiple和width_multiple呢?它決定的是整個模型中的深度(層數)和寬度(通道數。 anchors: # 表示作用于當前特征圖的Anchor大小為 xxx # 9個anchor,其中P表示特征圖的層級,P3/8該層特征圖縮放為1/8,是第3層特征 - [10,13, 16,30, 33,23] # P3/8, 表示[10,13],[16,30], [33,23]3個anchor - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5s v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5s v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
nc是類別數;
depth_multiple表示channel的縮放系數,就是將配置里面的backbone和head部分有關通道的設置,全部乘以該系數即可;
而width_multiple表示BottleneckCSP模塊的層縮放系數,將所有的BottleneckCSP模塊的number系數乘上該參數就可以最終的層個數;如果希望大一點,就把這個數字改大一點,網絡就會按比例變深、變寬;如果希望小一點,就把這個數字改小一點,網絡就會按比例變淺、變窄。
anchors 解讀
yolov5 初始化了 9 個 anchors,分別在三個特征圖 (feature map)中使用,每個 feature map 的每個 grid cell 都有三個 anchor 進行預測。分配規則:
?尺度越大的 feature map 越靠前,相對原圖的下采樣率越小,感受野越小, 所以相對可以預測一些尺度比較小的物體(小目標),分配到的 anchors 越小。
?尺度越小的 feature map 越靠后,相對原圖的下采樣率越大,感受野越大, 所以可以預測一些尺度比較大的物體(大目標),所以分配到的 anchors 越大。
?即在小特征圖(feature map)上檢測大目標,中等大小的特征圖上檢測中等目標, 在大特征圖上檢測小目標。
backbone & head解讀
[from, number, module, args] 參數
四個參數的意義分別是:
?第一個參數 from :從哪一層獲得輸入,-1表示從上一層獲得,[-1, 6]表示從上層和第6層兩層獲得。
?第二個參數 number:表示有幾個相同的模塊,如果為9則表示有9個相同的模塊。
?第三個參數 module:模塊的名稱,這些模塊寫在common.py中。
?第四個參數 args:類的初始化參數,用于解析作為 moudle 的傳入參數,即[ch_out, kernel, stride, padding, groups][輸出通道數量,卷積核尺寸,步長,padding],這里連ch_in都省去了,因為輸入都是上層的輸出(初始ch_in為3)
Backbone骨干網絡
骨干網絡是指用來提取圖像特征的網絡,它的主要作用是將原始的輸入圖像轉化為多層特征圖,以便后續的目標檢測任務使用。
在Yolov5中,使用的是CSPDarknet53或ResNet骨干網絡。Backbone中的主要結構有Conv模塊、C3模塊、SPPF模塊。
Conv
Conv模塊是卷積神經網絡中常用的一種基礎模塊,它主要由卷積層、BN層和激活函數組成。下面對這些組成部分進行詳細解析。
?卷積層是卷積神經網絡中最基礎的層之一,用于提取輸入特征中的局部空間信息。
?BN層是在卷積層之后加入的一種歸一化層,用于規范化神經網絡中的特征值分布。
?激活函數是一種非線性函數,用于給神經網絡引入非線性變換能力。常用的激活函數包括sigmoid、ReLU、LeakyReLU、ELU等。
C3模塊
C3模塊是YOLOv5網絡中的一個重要組成部分,其主要作用是增加網絡的深度和感受野,提高特征提取的能力。
C3模塊是由三個Conv塊構成的,其中第一個Conv塊的步幅為2,可以將特征圖的尺寸減半,第二個Conv塊和第三個Conv塊的步幅為1。C3模塊中的Conv塊采用的都是3x3的卷積核。在每個Conv塊之間,還加入了BN層和LeakyReLU激活函數,以提高模型的穩定性和泛化性能。
Neck特征金字塔
在Neck部分的變化還是相對較大的,首先是將SPP換成成了SPPF,其次是New CSP-PAN了,在YOLOv4中,Neck的PAN結構是沒有引入CSP結構的,但在YOLOv5中作者在PAN結構中加入了CSP。
SPPF模塊
SPP
SPP模塊是何凱明大神在2015年的論文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》中被提出。
SPP全程為空間金字塔池化結構,主要是為了解決兩個問題:
?有效避免了對圖像區域裁剪、縮放操作導致的圖像失真等問題;
?解決了卷積神經網絡對圖相關重復特征提取的問題,大大提高了產生候選框的速度,且節省了計算成本。
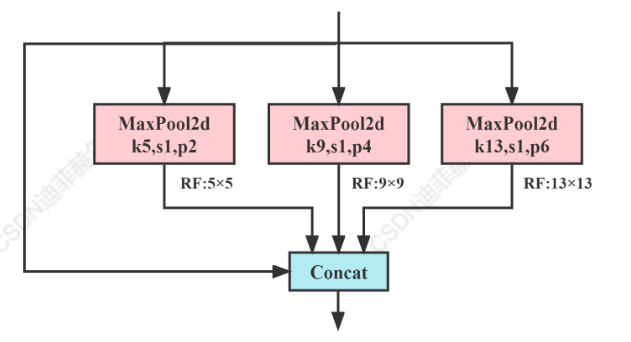
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
SPPF
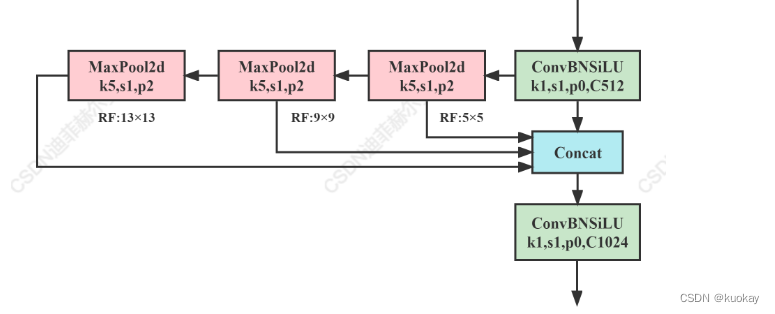
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
CSP-PAN
在Neck部分另外一個不同點就是New CSP-PAN了,在YOLOv4中,Neck的PAN結構是沒有引入CSP結構的,但在YOLOv5中作者在PAN結構中加入了CSP。
CSP
YOLOv5s的CSP結構是將原輸入分成兩個分支,分別進行卷積操作使得通道數減半,然后一個分支進行Bottleneck * N操作,然后concat兩個分支,使得BottlenneckCSP的輸入與輸出是一樣的大小,這樣是為了讓模型學習到更多的特征。
YOLOv5中的CSP有兩種設計,分別為CSP1_X結構和CSP2_X結構。
PAN
Yolov5 的 Neck 部分采用了 PANet 結構,Neck 主要用于生成特征金字塔。特征金字塔會增強模型對于不同縮放尺度對象的檢測,從而能夠識別不同大小和尺度的同一個物體。
PANet 結構是在FPN的基礎上引入了 Bottom-up path augmentation 結構。
PANet[1]最大的貢獻是提出了一個自頂向下和自底向上的雙向融合骨干網絡,同時在最底層和最高層之間添加了一條“short-cut”,用于縮短層之間的路徑。PANet還提出了自適應特征池化(Adaptive Features Pooling)和全連接融合(Fully-connected Fusion)兩個模塊。其中自適應特征池化可以用于聚合不同層之間的特征,保證特征的完整性和多樣性,而通過全連接融合可以得到更加準確的預測mask。
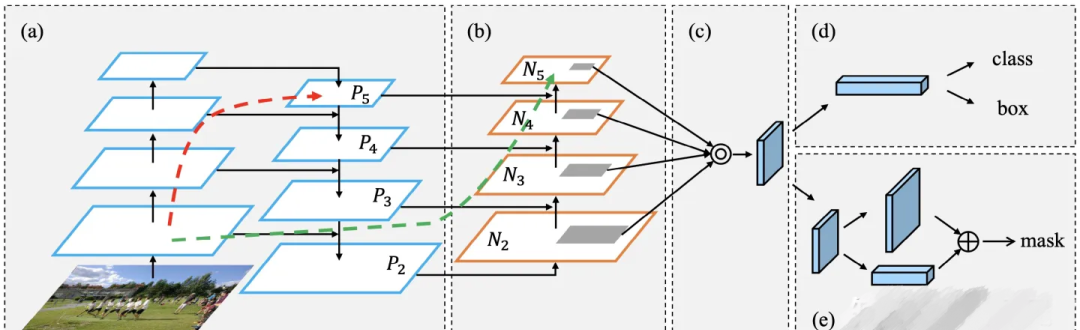
Head目標檢測頭
目標檢測頭是用來對特征金字塔進行目標檢測的部分,它包括了一些卷積層、池化層和全連接層等。
head中的主體部分就是三個Detect檢測器,即利用基于網格的anchor在不同尺度的特征圖上進行目標檢測的過程。
head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
數據增強
1.Mosaic數據增強
將四張圖片拼成一張圖片,采用隨機縮放、隨機裁剪、隨機排布的方式進行拼接。
優點:
1. 豐富數據集
2. 減少GPU
2.Copy paste數據增強
將部分目標隨機的粘貼到圖片中,前提是數據要有segments數據才行,即每個目標的實例分割信息。
3. Random affine仿射變換
yolov5的仿射變換包含隨機旋轉、平移、縮放、錯切操作,和yolov3-spp一樣,代碼都沒有改變。據配置文件里的超參數發現只使用了Scale和Translation即縮放和平移。
4. MixUp數據增強
就是將兩張圖片按照一定的透明度融合在一起。
5. HSV(Augment HSV(Hue, Saturation, Value))隨機增強圖像
隨機調整色度,飽和度以及明度。
6.Random horizontal flip隨機水平翻轉
隨機上下左右的水平翻轉
7. Cutout數據增強
Cutout是一種新的正則化方法。訓練時隨機把圖片的一部分減掉,這樣能提高模型的魯棒性。它的來源是計算機視覺任務中經常遇到的物體遮擋問題。通過cutout生成一些類似被遮擋的物體,不僅可以讓模型在遇到遮擋問題時表現更好,還能讓模型在做決定時更多地考慮環境。
Cutout數據增強在之前也見過很多次了。在yolov5的代碼中默認也是不啟用的。
8. Albumentations數據增強工具包
該工具最大的好處是會根據你使用的數據增強方法自動修改標注框信息!
albumentations 是一個給予 OpenCV的快速訓練數據增強庫,擁有非常簡單且強大的可以用于多種任務(分割、檢測)的接口,易于定制且添加其他框架非常方便。
它可以對數據集進行逐像素的轉換,如模糊、下采樣、高斯造點、高斯模糊、動態模糊、RGB轉換、隨機霧化等;也可以進行空間轉換(同時也會對目標進行轉換),如裁剪、翻轉、隨機裁剪等。
YOLOV5的訓練技巧
1.訓練預熱 Warmup
剛開始訓練時,模型的權重是隨機初始化的,此時若選擇一個較大的學習率,可能帶來模型的不穩定(振蕩)。選擇Warmup預熱學習率的方式可以使得開始訓練的幾個epoches或者一些steps內學習率較小,在預熱的小學習率下,模型可以慢慢趨于穩定,等模型相對穩定后再選擇預先設置的學習率進行訓練,使得模型收斂速度變得更快,模型效果更佳。
常見Warmup類型
1. Constant Warmup
在前面100epoch里,學習率線性增加,大于100epoch以后保持不變
2. Constant Warmup
在前面100epoch里,學習率線性增加,大于100epoch以后保持不變
3. Constant Warmup
在前面100epoch里,學習率線性增加,大于100epoch以后保持不變
超參數設置
在yolov5中data/hyps/hyp.scratch-*.yaml三個文件中,都存在著warmup_epoch代表訓練預熱輪次
2. 自動調整錨定框——Autoanchor
預定義邊框就是一組預設的邊框,在訓練時,以真實的邊框位置相對于預設邊框的偏移來構建(也就是我們打下的標簽)
訓練樣本。這就相當于,預設邊框先大致在可能的位置“框“出來目標,然后再在這些預設邊框的基礎上進行調整。
一個Anchor Box可以由:邊框的縱橫比和邊框的面積(尺度)來定義,相當于一系列預設邊框的生成規則,根據Anchor Box,可以在圖像的任意位置,生成一系列的邊框
3.超參數進化
yolov5提供了一種超參數優化的方法–Hyperparameter Evolution,即超參數進化。超參數進化是一種利用 遺傳算法(GA) 進行超參數優化的方法,我們可以通過該方法選擇更加合適自己的超參數。
提供的默認參數也是通過在COCO數據集上使用超參數進化得來的。由于超參數進化會耗費大量的資源和時間,如果默認參數訓練出來的結果能滿足你的使用,使用默認參數也是不錯的選擇。
4.凍結訓練——Freeze training
凍結訓練的作用:當我們已有部分預訓練權重,這部分預訓練權重所應用的那部分網絡是通用的,如骨干網絡,那么我們可以先凍結這部分權重的訓練,將更多的資源放在訓練后面部分的網絡參數,這樣使得時間和資源利用都能得到很大改善。然后后面的網絡參數訓練一段時間之后再解凍這些被凍結的部分,這時再全部一起訓練。
5.多尺度訓練——multi-scale training
當前的多尺度訓練(Multi Scale Training,MST)通常是指設置幾種不同的圖片輸入尺度,訓練時從多個尺度中隨機選取一種尺度,將輸入圖片縮放到該尺度并送入網絡中,是一種簡單又有效的提升多尺度物體檢測的方法。
雖然一次迭代時都是單一尺度的,但每次都各不相同,增加了網絡的魯棒性,又不至于增加過多的計算量。而在測試時,為了得到更為精準的檢測結果,也可以將測試圖片的尺度放大,例如放大4倍,這樣可以避免過多的小物體。
6. 加權圖像策略
圖像加權策略可以解決樣本不平衡的,具體操作步驟圖下:
根據樣本種類分布使用圖像調用頻率不同的方法解決。
1. 讀取訓練樣本中的GT,保存為一個列表;
2. 計算訓練樣本列表中不同類別個數,然后給每個類別按相應目標框數的倒數賦值,數目越多的種類權重越小,形成按種類的分布直方圖;
3. 對于訓練數據列表,訓練時按照類別權重篩選出每類的圖像作為訓練數據。使用random.choice(population, weights=None, *, cum_weights=None, k=1)更改訓練圖像索引,可達到樣本均衡的效果。
7.矩形推理——Rectangular Inference
通常YOLO系列網絡的輸入都是預處理后的方形圖像數據,如416 * 416、608 * 608。當原始圖像為矩形時,會將其填充為方形(如下圖:方形輸入),但是填充的灰色區域其實就是冗余信息,不論是在訓練還是推理階段,這些冗余信息都會增加耗時。
為了減少圖像的冗余數據,輸入圖像由方形改為矩形(如下圖:矩形輸入):將長邊resize為固定尺寸(如416),短邊按同樣比例resize,然后把短邊的尺寸盡量少地填充為32的倍數。
這種方法在推理階段稱為矩形推理(Rectangular Inference),在訓練階段則稱為矩形訓練(Rectangular Training)。推理階段直接對圖像進行resize和pad就行,但是訓練階段輸入的是一個批次的圖像集合,需要保持批次內的圖像尺寸一致,因此處理邏輯相對復雜一些。
8.非極大值抑制——NMS
在目標檢測的預測階段時,會輸出許多候選的anchor box,其中有很多是明顯重疊的預測邊界框都圍繞著同一個目標,這時候我就可以使用NMS來合并同一目標的類似邊界框,或者說是保留這些邊界框中最好的一個。
9. 斷點訓練
在用yolov5訓練數據的過程中由于突發情況訓練過程突然中斷,從頭訓練耗時,想接著上次訓練繼續訓練怎么辦。放心,在yolov5中給我們提供現成的參數–resume
10.早停機制(Early Stopping)
patience:訓練了多少個epoch,如果模型效果未提升,就讓模型提前停止訓練。
fitness監控的是增大的數值,例如mAP,如果mAP在連續訓練patience次內沒有增加就停止訓練。
11.多GPU訓練
審核編輯:湯梓紅
-
模型
+關注
關注
1文章
3279瀏覽量
48970 -
目標檢測
+關注
關注
0文章
210瀏覽量
15638 -
網絡結構
+關注
關注
0文章
48瀏覽量
11140
原文標題:YOLOv5網絡結構訓練策略詳解
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Yolov5算法解讀

在RK3568教學實驗箱上實現基于YOLOV5的算法物體識別案例詳解
龍哥手把手教你學視覺-深度學習YOLOV5篇
怎樣使用PyTorch Hub去加載YOLOv5模型
YOLOv5網絡結構解析
請問從yolov5訓練出的.pt文件怎么轉換為k210可以使用的.kmodel文件?
基于YOLO-V5的網絡結構及實現行人社交距離風險提示

在C++中使用OpenVINO工具包部署YOLOv5模型
使用旭日X3派的BPU部署Yolov5

淺析基于改進YOLOv5的輸電線路走廊滑坡災害識別
【教程】yolov5訓練部署全鏈路教程

yolov5和YOLOX正負樣本分配策略






 工商網監
工商網監
評論