 Dojo對標A100性能強勁,AI應用場景拓展
Dojo對標A100性能強勁,AI應用場景拓展
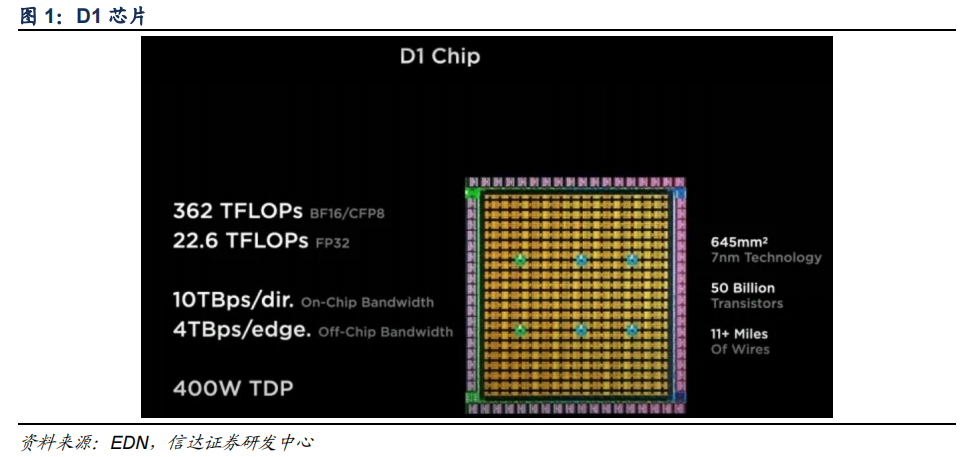
D1 芯片對標英偉達 A100。D1采用臺積電 7nm 制程,面積約為 645mm2,包含 500 億顆晶體管,BF16、CFP8 算力可達 362TFLOPS,FP32 算力可達 22.6TFLOPS。特斯拉D1芯片對標英偉達 A100,英偉達 A100 同樣采用臺積電 7nm 制程,面積為 826mm2,晶體管數量達 542 億顆,FP32 峰值算力為 19.5TFLOPS。
D1 芯片依次組成 Tranining tile、Tray、機柜、ExaPOD。特斯拉并未將 SoC 從晶圓上切下來,而是將所有 SoC 連接。25 個 D1 芯片組成了一個 Training Tile 多晶片模組(MCM),每個 D1 芯片功耗 400W,一個 Training Tile 功耗為 15kW。此外,6 個 Training Tile 組成一個 tray,再由兩個 Tray 組成一個機柜,10 個機柜組成 ExaPOD,BF16/CFP8 峰值算力達到 1.1EFLOPS(百億億次浮點運算),并擁有 1.3TB 高速 SRAM 和 13TB 高帶寬 DRAM。
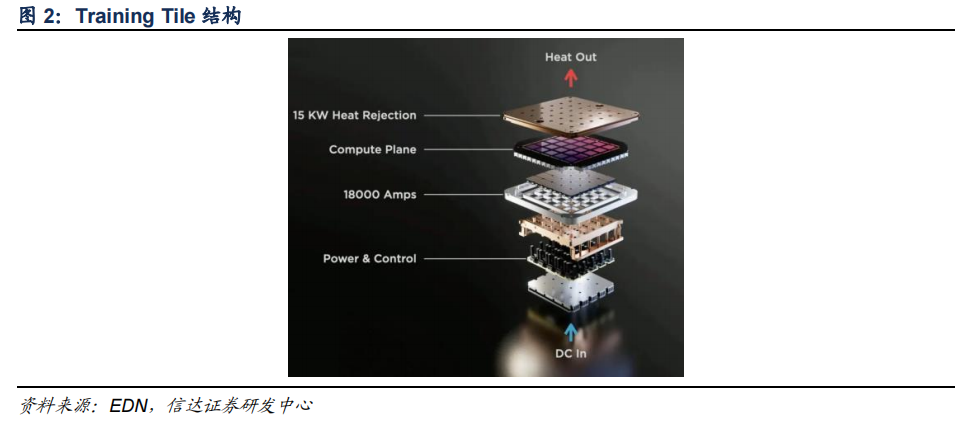

Dojo 的設計思想是通過較高的對稱性來實現 scale out 能力。在單個 Training tile 上,由于并未將芯片切下,為了提高效率和降低成本,特斯拉并未在片上集成 DRAM 等器件,這與許多通用 GPU 有所不同。集群節點之間以 2D mesh 連接,邊緣則通過 Interface-processors負責內存池數據搬運。

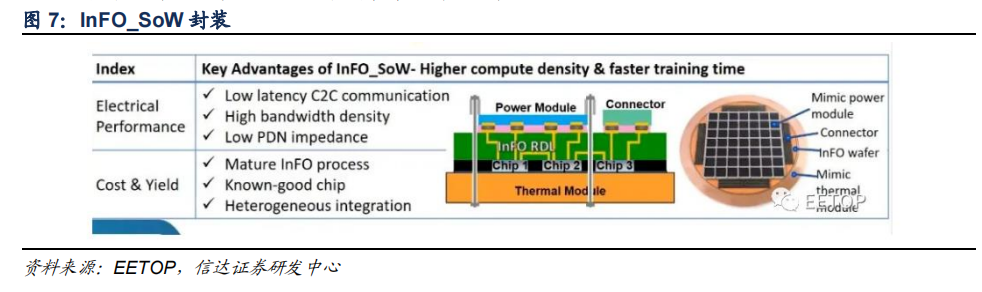
顯而易見,D1 芯片需要高速的互聯來實現,臺積電 SoW 封裝技術提供了這一條件。InFO_SoW 取消了襯底和 PCB 的使用,使得多個芯片陣列使解決方案獲得晶圓級優勢,以獲得低延時、高帶寬等優勢。此外除了異構芯片集成外,其 wafer-field 處理能力還支持基于小芯片的設計,以實現更大的成本節約和設計靈活性。
在部分模型上,Dojo 能實現相對 A100 更高的性能。例如在圖像分類模型 ResNet-50 上,Dojo 可以實現比英偉達 A100 更高的幀率。而在用于預測汽車周圍物體所占空間的神經網絡模型 Occupancy Networks 上,相比英偉達 A100,Dojo 能實現性能的倍增。

特斯拉將大力投資基礎設施,2024 年有望達 100Exa-Flops 算力。特斯拉目前 AI 基礎設施較少,僅約 4000 個 V100 和約 16000 個 A100。而 Microsoft 和 Meta 等公司擁有超過 10萬個 GPU。據特斯拉規劃,2024 年有望達 100Exa-Flops 算力。
特斯拉擁有海量數據庫,數據價值亟待挖掘。Model3 傳包含 8 個攝像頭,1 個毫米波雷達,12 個超聲波雷達,位置分別為:1-車牌的上方裝有一個攝像頭;2-超聲波傳感器(如果配備)位于前后保險杠中;3-各門柱均裝有一個攝像頭;4-后視鏡上方的擋風玻璃上裝有三個攝像頭;5-每塊前翼子板上裝有一個攝像頭;6-雷達(如果配備)安裝在前保險杠后面。特斯拉車型銷量形勢良好,通過傳感器件建立了龐大的數據庫,但受限于硬件限制,無法充分挖掘數據價值,Dojo 量產有望突破瓶頸。
自建 AI 基礎設施,AI 或賦能特斯拉快速成長。特斯拉 Dojo 性能強大,我們認為,除加速自身智駕進程外,或可拓展至其他應用領域,如機器人等。此外,特斯拉也可能成為一家云服務提供商,向相關廠商提供自身算力或模型服務。
-
傳感器
+關注
關注
2552文章
51336瀏覽量
755498 -
AI
+關注
關注
87文章
31359瀏覽量
269762 -
毫米波雷達
+關注
關注
107文章
1052瀏覽量
64459
原文標題:Dojo對標A100性能強勁,AI應用場景拓展
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英偉達a100和h100哪個強?英偉達A100和H100的區別
NanoEdge AI的技術原理、應用場景及優勢
新一代AI ISP視頻處理模組,對標Hi3559A、Hi3519A平臺性能
NVIDIA推出了基于A100的DGX A100
英偉達a100和a800的區別
英偉達a100和a800參數對比





 工商網監
工商網監
評論