1. OpenAI DALL·E 3來(lái)了,集成ChatGPT,生圖效果太炸了
原文:https://mp.weixin.qq.com/s/P4HwP3VwzSnndD5LSt8pXw
終于,OpenAI 的文生圖 AI 工具 DALL-E 系列迎來(lái)了最新版本 DALL?E 3,而上個(gè)版本 DALL?E 2 還是在去年 4 月推出的。
OpenAI 表示,「DALL?E 3 比以往系統(tǒng)更能理解細(xì)微差別和細(xì)節(jié),讓用戶(hù)更加輕松地將自己的想法轉(zhuǎn)化為非常準(zhǔn)確的圖像。」

是不是真如 OpenAI 所說(shuō)的那樣呢?眼見(jiàn)為實(shí),我們來(lái)看以下 DALL?E 3 與 DALL?E 2 的生成效果比較,同樣的 prompt「一幅描繪籃球運(yùn)動(dòng)員扣籃的油畫(huà),并伴以爆炸的星云」,左圖 DALL?E 2 在細(xì)節(jié)、清晰度、明亮度等方面顯然遜于右圖 DALL?E 3。(說(shuō)實(shí)話,讓我想起了布洛芬....)
除了炸裂的生圖效果之外,此次 DALL?E 3 的最大特點(diǎn)是與 ChatGPT 的集成,它原生構(gòu)建在 ChatGPT 之上,用 ChatGPT 來(lái)創(chuàng)建、拓展和優(yōu)化 prompt。這樣一來(lái),用戶(hù)無(wú)需在 prompt 上花費(fèi)太多時(shí)間。具體來(lái)講,通過(guò)使用 ChatGPT,用戶(hù)不必絞盡腦汁地想出詳細(xì)的 prompt 來(lái)引導(dǎo) DALL?E 3 了。當(dāng)輸入一個(gè)想法時(shí),ChatGPT 會(huì)自動(dòng)為 DALL?E 3 生成量身定制的、詳細(xì)的 prompt。同時(shí)用戶(hù)也可以使用自己的 prompt。至于集成 ChatGPT 后的效果怎么樣?OpenAI CEO 山姆?奧特曼興奮地展示了 DALL?E 3 的連續(xù)性生成結(jié)果,簡(jiǎn)直稱(chēng)得上完整的「故事片」。
ChatGPT 集成并不是 DALL?E 3 唯一的新特點(diǎn),它還能生成更高質(zhì)量的圖像,更準(zhǔn)確地反映提示內(nèi)容。DALL?E 將文本 prompt 轉(zhuǎn)換成圖像。即使是 DALL?E 2 ,也會(huì)經(jīng)常忽略特定的措辭導(dǎo)致出錯(cuò)。但 OpenAI 的研究人員說(shuō),最新版本能更好地理解上下文,并且處理較長(zhǎng)的 prompt 效果會(huì)更好。此外,它還能更好地處理向來(lái)困擾圖像生成模型的內(nèi)容,如文本和人手。
可以看到在上圖將 prompt 中的每一個(gè)細(xì)節(jié)都表現(xiàn)出來(lái)了。半透明的質(zhì)感、畫(huà)面底部的波濤洶涌、陽(yáng)光與厚厚的云層、心臟中的宇宙景象,以及難倒很多圖像生成模型的文字展現(xiàn),DALL?E 3 都順利地完成了這些任務(wù)。那么,DALL?E 3 能不能成為 Midjourney 「殺手」呢?推特用戶(hù) @MattGarciaEth 已經(jīng)將二者生成的圖片進(jìn)行了很多比較。大家覺(jué)得哪個(gè)更好呢?
目前,DALL?E 3 處于研究預(yù)覽版本。OpenAI 計(jì)劃將 DALL?E 3 的發(fā)布時(shí)間錯(cuò)開(kāi), 將于 10 月份首先向 ChatGPT Plus 和 ChatGPT Enterprise 用戶(hù)發(fā)布,隨后在秋季向研究實(shí)驗(yàn)室及其 API 服務(wù)發(fā)布。不過(guò),該公司沒(méi)有透露何時(shí)或者是否計(jì)劃發(fā)布免費(fèi)的公開(kāi)版本。
2. GPT-4終結(jié)人工標(biāo)注!AI標(biāo)注比人類(lèi)標(biāo)注效率高100倍,成本僅1/7
原文:https://mp.weixin.qq.com/s/AwXljsdH1SG0qzNeYTaprA
除了GPU,還有什么是訓(xùn)練一個(gè)高效的大模型必不可少且同樣難以獲取的資源?高質(zhì)量的數(shù)據(jù)。OpenAI正是借助基于人類(lèi)標(biāo)注的數(shù)據(jù),才一舉從眾多大模型企業(yè)中脫穎而出,讓ChatGPT成為了大模型競(jìng)爭(zhēng)中階段性的勝利者。但同時(shí),OpenAI也因?yàn)槭褂梅侵蘖畠r(jià)的人工進(jìn)行數(shù)據(jù)標(biāo)注,被各種媒體口誅筆伐。
而那些參與數(shù)據(jù)標(biāo)注的工人們,也因?yàn)殚L(zhǎng)期暴露在有毒內(nèi)容中,受到了不可逆的心理創(chuàng)傷。
總之,對(duì)于數(shù)據(jù)標(biāo)注,一定需要找到一個(gè)新的方法,才能避免大量使用人工標(biāo)注帶來(lái)的包括道德風(fēng)險(xiǎn)在內(nèi)的其他潛在麻煩。所以,包括谷歌,Anthropic在內(nèi)的AI巨頭和大型獨(dú)角獸,都在進(jìn)行數(shù)據(jù)標(biāo)注自動(dòng)化的探索。

除了巨頭們的嘗試之外,最近,一家初創(chuàng)公司refuel,也上線了一個(gè)AI標(biāo)注數(shù)據(jù)的開(kāi)源處理工具:Autolabel。

Autolabel:用AI標(biāo)注數(shù)據(jù),效率最高提升100倍這個(gè)工具可以讓有數(shù)據(jù)處理需求的用戶(hù),使用市面上主流的LLM(ChatGPT,Claude等)來(lái)對(duì)自己的數(shù)據(jù)集進(jìn)行標(biāo)注。refuel稱(chēng),用自動(dòng)化的方式標(biāo)注數(shù)據(jù),相比于人工標(biāo)注,效率最高可以提高100倍,而成本只有人工成本的1/7!
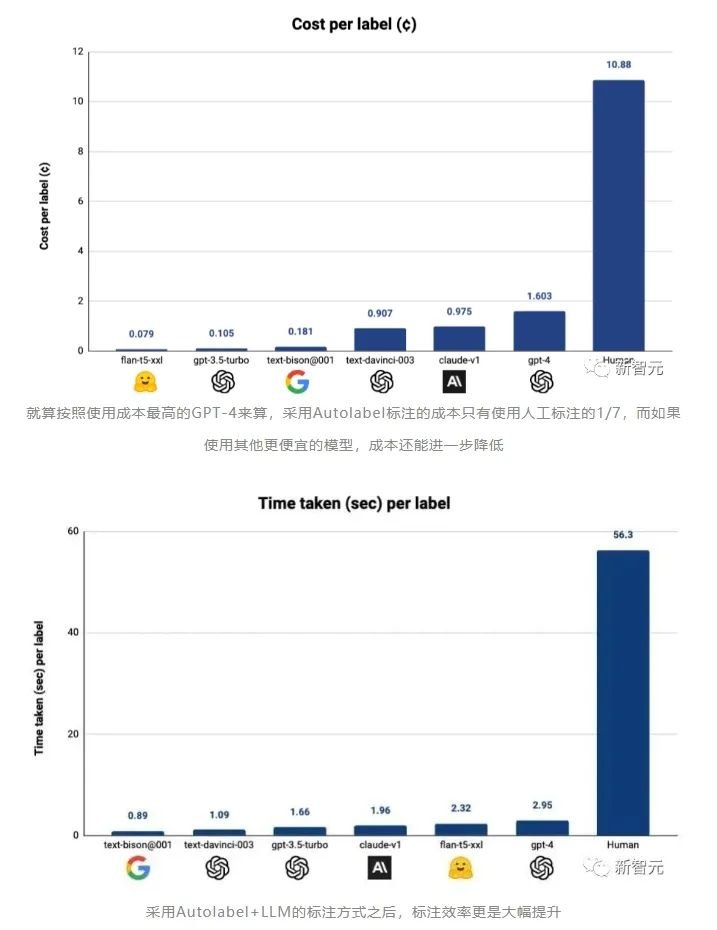
對(duì)于LLM標(biāo)注質(zhì)量的評(píng)估,Autolabel的開(kāi)發(fā)者創(chuàng)立了一個(gè)基準(zhǔn)測(cè)試,通過(guò)將不同的LLM的標(biāo)注結(jié)果和基準(zhǔn)測(cè)試中不同數(shù)據(jù)集中收納的標(biāo)準(zhǔn)答案向比對(duì),就能評(píng)估各個(gè)模型標(biāo)注數(shù)據(jù)的質(zhì)量。
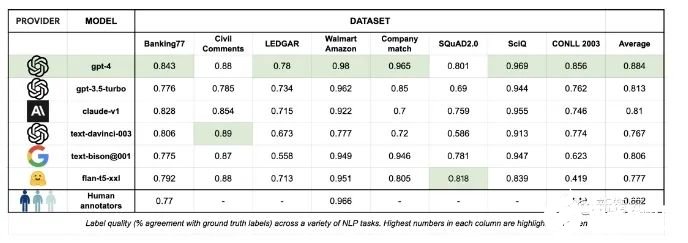
當(dāng)Autolabel采用GPT-4進(jìn)行標(biāo)注時(shí),獲得了最高的準(zhǔn)確率——88.4%,超過(guò)了人類(lèi)標(biāo)注結(jié)果的準(zhǔn)確率86.2%。而且其他比GPT-4便宜得多的模型的標(biāo)注準(zhǔn)確率,相比GPT-4來(lái)說(shuō)也不算低。開(kāi)發(fā)者稱(chēng),在比較簡(jiǎn)單的標(biāo)注任務(wù)中采用便宜的模型,在困難的任務(wù)中采用GPT-4,將可以大大節(jié)省標(biāo)注成本,同時(shí)幾乎不影響標(biāo)注的準(zhǔn)確率。Autolabel支持對(duì)自然語(yǔ)言處理項(xiàng)目進(jìn)行分類(lèi),命名實(shí)體識(shí)別,實(shí)體匹配和問(wèn)答。支持主流的所有LLM提供商:OpenAI、Anthropic 和 Google Palm 等,并通過(guò)HuggingFace為開(kāi)源和私有模型提供支持。用戶(hù)可以嘗試不同的提示策略,例如少樣本和思維鏈提示。只要簡(jiǎn)單更新配置文件即可輕松估計(jì)標(biāo)簽置信度。Autolabel免除了編寫(xiě)復(fù)雜的指南,無(wú)盡地等待外部團(tuán)隊(duì)來(lái)提供數(shù)據(jù)支持的麻煩,用戶(hù)能夠在幾分鐘內(nèi)開(kāi)始標(biāo)注數(shù)據(jù)。可以支持使用本地部署的私有模型在本地處理數(shù)據(jù),所以對(duì)于數(shù)據(jù)隱私敏感度很高的用戶(hù)來(lái)說(shuō),Autolabel提供了成本和門(mén)檻都很低的數(shù)據(jù)標(biāo)注途徑。未來(lái)更新的方向在接下來(lái)的幾個(gè)月中,開(kāi)發(fā)者承諾將向Autolabel添加大量新功能:支持更多LLM進(jìn)行數(shù)據(jù)標(biāo)注。支持更多標(biāo)注任務(wù),例如總結(jié)等。支持更多的輸入數(shù)據(jù)類(lèi)型和更高的LLM輸出穩(wěn)健性。讓用戶(hù)能夠試驗(yàn)多個(gè)LLM和不同提示的工作流程。
3. Transformer+強(qiáng)化學(xué)習(xí),谷歌DeepMind讓大模型成為機(jī)器人感知世界的大腦
原文:https://mp.weixin.qq.com/s/pp9viv9IfdiLMFXgy4h56A
在開(kāi)發(fā)機(jī)器人學(xué)習(xí)方法時(shí),如果能整合大型多樣化數(shù)據(jù)集,再組合使用強(qiáng)大的富有表現(xiàn)力的模型(如 Transformer),那么就有望開(kāi)發(fā)出具備泛化能力且廣泛適用的策略,從而讓機(jī)器人能學(xué)會(huì)很好地處理各種不同的任務(wù)。比如說(shuō),這些策略可讓機(jī)器人遵從自然語(yǔ)言指令,執(zhí)行多階段行為,適應(yīng)各種不同環(huán)境和目標(biāo),甚至適用于不同的機(jī)器人形態(tài)。但是,近期在機(jī)器人學(xué)習(xí)領(lǐng)域出現(xiàn)的強(qiáng)大模型都是使用監(jiān)督學(xué)習(xí)方法訓(xùn)練得到的。因此,所得策略的性能表現(xiàn)受限于人類(lèi)演示者提供高質(zhì)量演示數(shù)據(jù)的程度。這種限制的原因有二。-
第一,我們希望機(jī)器人系統(tǒng)能比人類(lèi)遠(yuǎn)程操作者更加熟練,利用硬件的全部潛力來(lái)快速、流暢和可靠地完成任務(wù)。
-
第二,我們希望機(jī)器人系統(tǒng)能更擅長(zhǎng)自動(dòng)積累經(jīng)驗(yàn),而不是完全依賴(lài)高質(zhì)量的演示。
從原理上看,強(qiáng)化學(xué)習(xí)能同時(shí)提供這兩種能力。近期出現(xiàn)了一些頗具潛力的進(jìn)步,它們表明大規(guī)模機(jī)器人強(qiáng)化學(xué)習(xí)能在多種應(yīng)用設(shè)置中取得成功,比如機(jī)器人抓取和堆疊、學(xué)習(xí)具有人類(lèi)指定獎(jiǎng)勵(lì)的異構(gòu)任務(wù)、學(xué)習(xí)多任務(wù)策略、學(xué)習(xí)以目標(biāo)為條件的策略、機(jī)器人導(dǎo)航。但是,研究表明,如果使用強(qiáng)化學(xué)習(xí)來(lái)訓(xùn)練 Transformer 等能力強(qiáng)大的模型,則更難大規(guī)模地有效實(shí)例化。近日,Google DeepMind 提出了 Q-Transformer,目標(biāo)是將基于多樣化真實(shí)世界數(shù)據(jù)集的大規(guī)模機(jī)器人學(xué)習(xí)與基于強(qiáng)大 Transformer 的現(xiàn)代策略架構(gòu)結(jié)合起來(lái)。

-
論文:https://q-transformer.github.io/assets/q-transformer.pdf
-
項(xiàng)目:https://q-transformer.github.io/
雖然,從原理上看,直接用 Transformer 替代現(xiàn)有架構(gòu)(ResNets 或更小的卷積神經(jīng)網(wǎng)絡(luò))在概念上很簡(jiǎn)單,但要設(shè)計(jì)一種能有效利用這一架構(gòu)的方案卻非常困難。只有能使用大規(guī)模的多樣化數(shù)據(jù)集時(shí),大模型才能發(fā)揮效力 —— 小規(guī)模的范圍狹窄的模型無(wú)需這樣的能力,也不能從中受益。盡管之前有研究通過(guò)仿真數(shù)據(jù)來(lái)創(chuàng)建這樣的數(shù)據(jù)集,但最有代表性的數(shù)據(jù)還是來(lái)自真實(shí)世界。因此,DeepMind 表示,這項(xiàng)研究關(guān)注的重點(diǎn)是通過(guò)離線強(qiáng)化學(xué)習(xí)使用 Transformer 并整合之前收集的大型數(shù)據(jù)集。離線強(qiáng)化學(xué)習(xí)方法是使用之前已有的數(shù)據(jù)訓(xùn)練,目標(biāo)是根據(jù)給定數(shù)據(jù)集推導(dǎo)出最有效的可能策略。當(dāng)然,也可以使用額外自動(dòng)收集的數(shù)據(jù)來(lái)增強(qiáng)這個(gè)數(shù)據(jù)集,但訓(xùn)練過(guò)程是與數(shù)據(jù)收集過(guò)程是分開(kāi)的,這能為大規(guī)模機(jī)器人應(yīng)用提供一個(gè)額外的工作流程。在使用 Transformer 模型來(lái)實(shí)現(xiàn)強(qiáng)化學(xué)習(xí)方面,另一大問(wèn)題是設(shè)計(jì)一個(gè)可以有效訓(xùn)練這種模型的強(qiáng)化學(xué)習(xí)系統(tǒng)。有效的離線強(qiáng)化學(xué)習(xí)方法通常是通過(guò)時(shí)間差更新來(lái)進(jìn)行 Q 函數(shù)估計(jì)。由于 Transformer 建模的是離散的 token 序列,所以可以將 Q 函數(shù)估計(jì)問(wèn)題轉(zhuǎn)換成一個(gè)離散 token 序列建模問(wèn)題,并為序列中的每個(gè) token 設(shè)計(jì)一個(gè)合適的損失函數(shù)。最簡(jiǎn)單樸素的對(duì)動(dòng)作空間離散化的方法會(huì)導(dǎo)致動(dòng)作基數(shù)呈指數(shù)爆炸,因此 DeepMind 采用的方法是按維度離散化方案,即動(dòng)作空間的每個(gè)維度都被視為強(qiáng)化學(xué)習(xí)的一個(gè)獨(dú)立的時(shí)間步驟。離散化中不同的 bin 對(duì)應(yīng)于不同的動(dòng)作。這種按維度離散化的方案讓我們可以使用帶有一個(gè)保守的正則化器簡(jiǎn)單離散動(dòng)作 Q 學(xué)習(xí)方法來(lái)處理分布轉(zhuǎn)變情況。DeepMind 提出了一種專(zhuān)門(mén)的正則化器,其能最小化數(shù)據(jù)集中每個(gè)未被取用動(dòng)作的值。研究表明:該方法既能學(xué)習(xí)范圍狹窄的類(lèi)似演示的數(shù)據(jù),也能學(xué)習(xí)帶有探索噪聲的范圍更廣的數(shù)據(jù)。最后,他們還采用了一種混合更新機(jī)制,其將蒙特卡洛和 n 步返回與時(shí)間差備份(temporal difference backups)組合到了一起。結(jié)果表明這種做法能提升基于 Transformer 的離線強(qiáng)化學(xué)習(xí)方法在大規(guī)模機(jī)器人學(xué)習(xí)問(wèn)題上的表現(xiàn)。總結(jié)起來(lái),這項(xiàng)研究的主要貢獻(xiàn)是 Q-Transformer,這是一種用于機(jī)器人離線強(qiáng)化學(xué)習(xí)的基于 Transformer 的架構(gòu),其對(duì) Q 值使用了按維度的 token 化,并且已經(jīng)可以用于大規(guī)模多樣化機(jī)器人數(shù)據(jù)集,包括真實(shí)世界數(shù)據(jù)。圖 1 總結(jié)了 Q-Transformer 的組件。
DeepMind 也進(jìn)行了實(shí)驗(yàn)評(píng)估 —— 既有用于嚴(yán)格比較的仿真實(shí)驗(yàn),也有用于實(shí)際驗(yàn)證的大規(guī)模真實(shí)世界實(shí)驗(yàn);其中學(xué)習(xí)了大規(guī)模的基于文本的多任務(wù)策略,結(jié)果驗(yàn)證了 Q-Transformer 的有效性。在真實(shí)世界實(shí)驗(yàn)中,他們使用的數(shù)據(jù)集包含 3.8 萬(wàn)個(gè)成功演示和 2 萬(wàn)個(gè)失敗的自動(dòng)收集的場(chǎng)景,這些數(shù)據(jù)是通過(guò) 13 臺(tái)機(jī)器人在 700 多個(gè)任務(wù)上收集的。Q-Transformer 的表現(xiàn)優(yōu)于之前提出的用于大規(guī)模機(jī)器人強(qiáng)化學(xué)習(xí)的架構(gòu),以及之前提出的 Decision Transformer 等基于 Transformer 的模型。
4. Transformer的上下文學(xué)習(xí)能力是哪來(lái)的?
原文:https://mp.weixin.qq.com/s/7eRwSwIE-X-qfjAsOCW1WQ
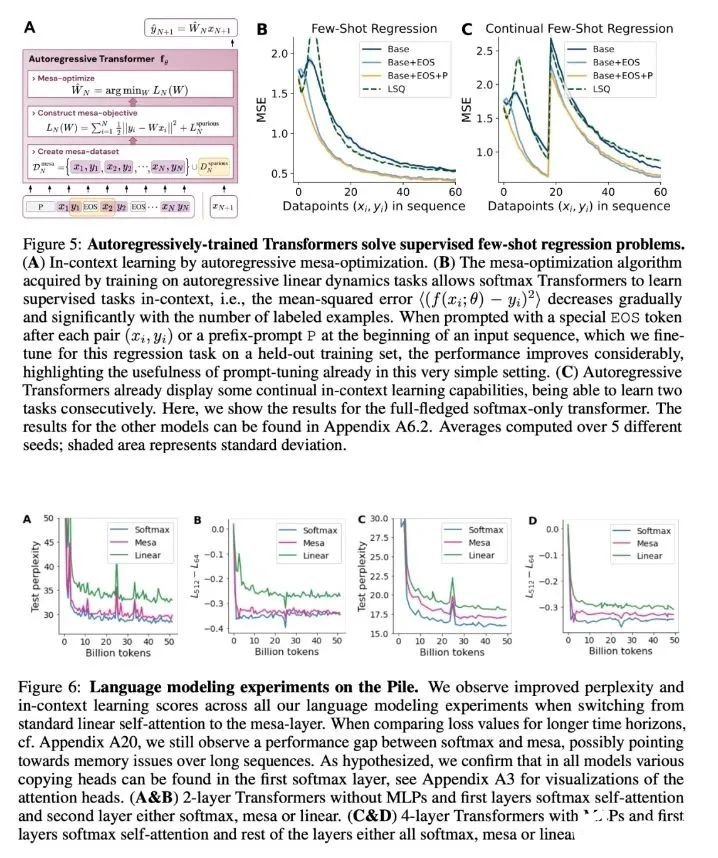
為什么 transformer 性能這么好?它給眾多大語(yǔ)言模型帶來(lái)的上下文學(xué)習(xí) (In-Context Learning) 能力是從何而來(lái)?在人工智能領(lǐng)域里,transformer 已成為深度學(xué)習(xí)中的主導(dǎo)模型,但人們對(duì)于它卓越性能的理論基礎(chǔ)卻一直研究不足。最近,來(lái)自 Google AI、蘇黎世聯(lián)邦理工學(xué)院、Google DeepMind 研究人員的新研究嘗試為我們揭開(kāi)謎底。在新研究中,他們對(duì) transformer 進(jìn)行了逆向工程,尋找到了一些優(yōu)化方法。論文《Uncovering mesa-optimization algorithms in Transformers》:

論文鏈接:https://arxiv.org/abs/2309.05858
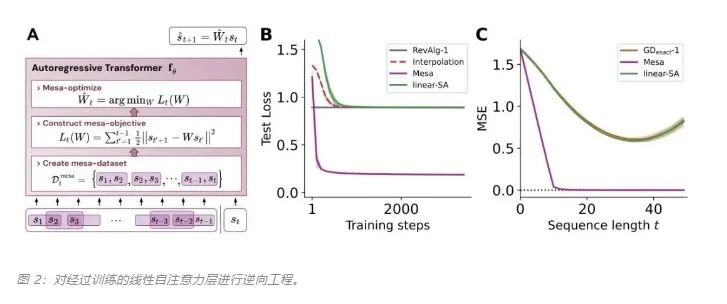
作者證明,最小化通用自回歸損失會(huì)產(chǎn)生在 Transformer 的前向傳遞中運(yùn)行的基于輔助梯度的優(yōu)化算法。這種現(xiàn)象最近被稱(chēng)為「mesa 優(yōu)化(mesa-optimization)」。此外,研究人員發(fā)現(xiàn)所得的 mesa 優(yōu)化算法表現(xiàn)出上下文中的小樣本學(xué)習(xí)能力,與模型規(guī)模無(wú)關(guān)。因此,新的結(jié)果對(duì)此前大語(yǔ)言模型中出現(xiàn)的小樣本學(xué)習(xí)的原理進(jìn)行了補(bǔ)充。研究人員認(rèn)為:Transformers 的成功基于其在前向傳遞中實(shí)現(xiàn) mesa 優(yōu)化算法的架構(gòu)偏差:(i) 定義內(nèi)部學(xué)習(xí)目標(biāo),以及 (ii) 對(duì)其進(jìn)行優(yōu)化。
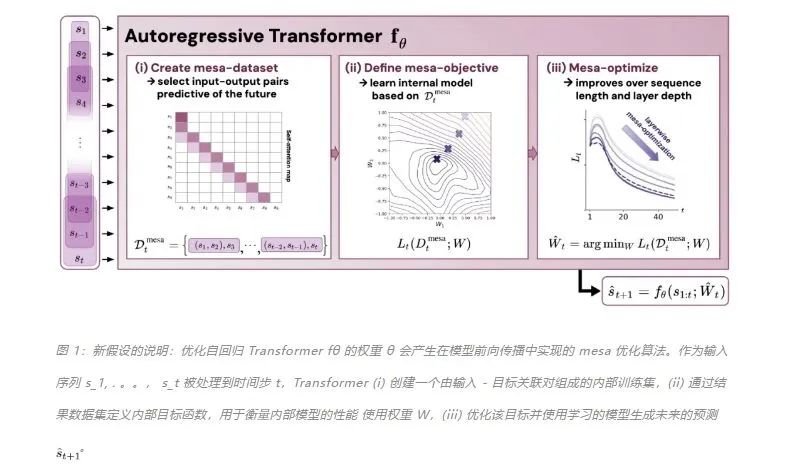
該研究的貢獻(xiàn)包括:-
概括了 von Oswald 等人的理論,并展示了從理論上,Transformers 是如何通過(guò)使用基于梯度的方法優(yōu)化內(nèi)部構(gòu)建的目標(biāo)來(lái)自回歸預(yù)測(cè)序列下一個(gè)元素的。
-
通過(guò)實(shí)驗(yàn)對(duì)在簡(jiǎn)單序列建模任務(wù)上訓(xùn)練的 Transformer 進(jìn)行了逆向工程,并發(fā)現(xiàn)強(qiáng)有力的證據(jù)表明它們的前向傳遞實(shí)現(xiàn)了兩步算法:(i) 早期自注意力層通過(guò)分組和復(fù)制標(biāo)記構(gòu)建內(nèi)部訓(xùn)練數(shù)據(jù)集,因此隱式地構(gòu)建內(nèi)部訓(xùn)練數(shù)據(jù)集。定義內(nèi)部目標(biāo)函數(shù),(ii) 更深層次優(yōu)化這些目標(biāo)以生成預(yù)測(cè)。
-
與 LLM 類(lèi)似,實(shí)驗(yàn)表明簡(jiǎn)單的自回歸訓(xùn)練模型也可以成為上下文學(xué)習(xí)者,而即時(shí)調(diào)整對(duì)于改善 LLM 的上下文學(xué)習(xí)至關(guān)重要,也可以提高特定環(huán)境中的表現(xiàn)。
-
受發(fā)現(xiàn)注意力層試圖隱式優(yōu)化內(nèi)部目標(biāo)函數(shù)的啟發(fā),作者引入了 mesa 層,這是一種新型注意力層,可以有效地解決最小二乘優(yōu)化問(wèn)題,而不是僅采取單個(gè)梯度步驟來(lái)實(shí)現(xiàn)最優(yōu)。實(shí)驗(yàn)證明單個(gè) mesa 層在簡(jiǎn)單的順序任務(wù)上優(yōu)于深度線性和 softmax 自注意力 Transformer,同時(shí)提供更多的可解釋性。

-
在初步的語(yǔ)言建模實(shí)驗(yàn)后發(fā)現(xiàn),用 mesa 層替換標(biāo)準(zhǔn)的自注意力層獲得了有希望的結(jié)果,證明了該層具有強(qiáng)大的上下文學(xué)習(xí)能力。
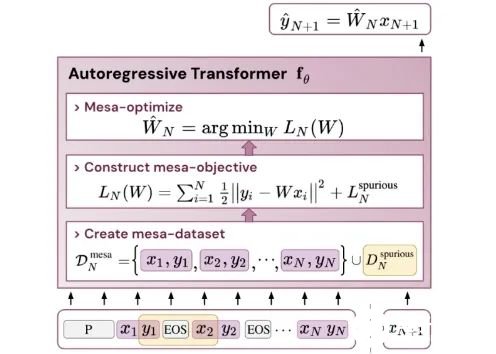
基于最近人們的工作表明,經(jīng)過(guò)明確訓(xùn)練來(lái)解決上下文中的小樣本任務(wù)的 transformer 可以實(shí)現(xiàn)梯度下降(GD)算法。在這里,作者展示了這些結(jié)果可以推廣到自回歸序列建模 —— 這是訓(xùn)練 LLM 的典型方法。首先分析在簡(jiǎn)單線性動(dòng)力學(xué)上訓(xùn)練的 transformer,其中每個(gè)序列由不同的 W* 生成 - 以防止跨序列記憶。在這個(gè)簡(jiǎn)單的設(shè)置中,作者展示了 transformer 創(chuàng)建 mesa 數(shù)據(jù)集,然后使用預(yù)處理的 GD 優(yōu)化 mesa 目標(biāo)。
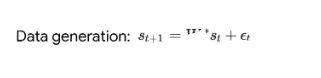
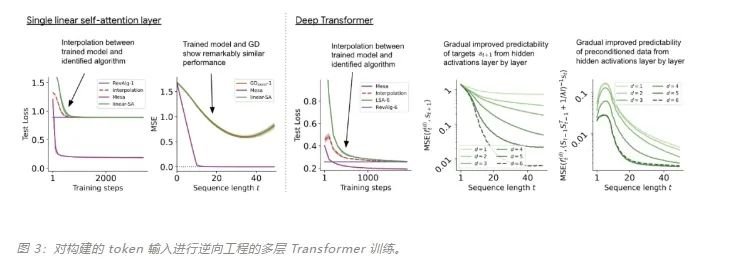
該研究在聚合相鄰序列元素的 token 結(jié)構(gòu)上訓(xùn)練深度 transformer。有趣的是,這種簡(jiǎn)單的預(yù)處理會(huì)產(chǎn)生極其稀疏的權(quán)重矩陣(只有不到 1% 的權(quán)重非零),從而產(chǎn)生逆向工程算法。
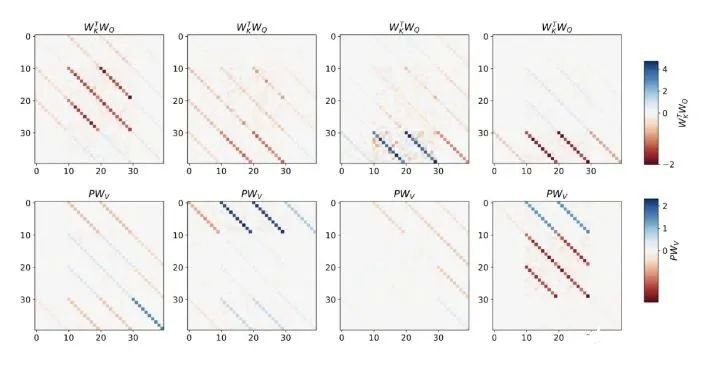
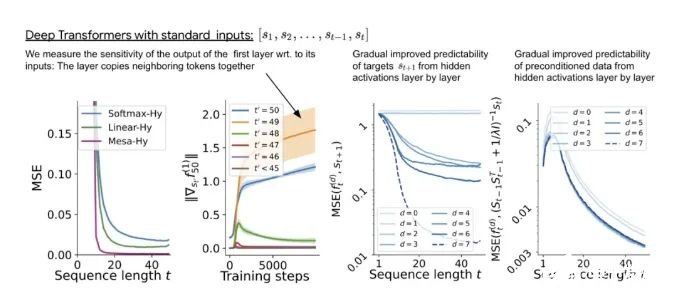
對(duì)于單層線性自注意力,權(quán)重對(duì)應(yīng)一個(gè) GD 步驟。對(duì)于深度 transformer,可解釋性就變得困難。該研究依靠線性探測(cè)并檢查隱藏激活是否可以預(yù)測(cè)自回歸目標(biāo)或預(yù)處理輸入。有趣的是,兩種探測(cè)方法的可預(yù)測(cè)性都會(huì)隨著網(wǎng)絡(luò)深度的增加而逐漸提高。這一發(fā)現(xiàn)表明模型中隱藏著預(yù)處理的 GD。
該研究發(fā)現(xiàn),在構(gòu)建中使用所有自由度時(shí),可以完美地?cái)M合訓(xùn)練層,不僅包括學(xué)習(xí)的學(xué)習(xí)率 η,還包括一組學(xué)習(xí)的初始權(quán)重 W_0。重要的是,如圖 2 所示,學(xué)得的 one-step 算法的性能仍然遠(yuǎn)遠(yuǎn)優(yōu)于單個(gè) mesa 層。我們可以注意到,在簡(jiǎn)單的權(quán)重設(shè)置下,很容易通過(guò)基礎(chǔ)優(yōu)化發(fā)現(xiàn),該層可以最優(yōu)地解決此處研究的任務(wù)。該結(jié)果證明了硬編碼歸納偏差有利于 mesa 優(yōu)化的優(yōu)勢(shì)。憑借對(duì)多層案例的理論見(jiàn)解,先分析深度線性和 softmax 僅注意 Transformer。作者根據(jù) 4 通道結(jié)構(gòu)設(shè)置輸入格式,,這對(duì)應(yīng)于選擇 W_0 = 0。
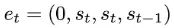
與單層模型一樣,作者在訓(xùn)練模型的權(quán)重中看到了清晰的結(jié)構(gòu)。作為第一個(gè)逆向工程分析,該研究利用這個(gè)結(jié)構(gòu)并構(gòu)建一個(gè)算法(RevAlg-d,其中 d 表示層數(shù)),每個(gè)層頭包含 16 個(gè)參數(shù)(而不是 3200 個(gè))。作者發(fā)現(xiàn)這種壓縮但復(fù)雜的表達(dá)式可以描述經(jīng)過(guò)訓(xùn)練的模型。特別是,它允許以幾乎無(wú)損的方式在實(shí)際 Transformer 和 RevAlg-d 權(quán)重之間進(jìn)行插值。雖然 RevAlg-d 表達(dá)式解釋了具有少量自由參數(shù)的經(jīng)過(guò)訓(xùn)練的多層 Transformer,但很難將其解釋為 mesa 優(yōu)化算法。因此,作者采用線性回歸探測(cè)分析(Alain & Bengio,2017;Akyürek et al.,2023)來(lái)尋找假設(shè)的 mesa 優(yōu)化算法的特征。在圖 3 所示的深度線性自注意力 Transformer 上,我們可以看到兩個(gè)探針都可以線性解碼,解碼性能隨著序列長(zhǎng)度和網(wǎng)絡(luò)深度的增加而增加。因此,基礎(chǔ)優(yōu)化發(fā)現(xiàn)了一種混合算法,該算法在原始 mesa-objective Lt (W) 的基礎(chǔ)上逐層下降,同時(shí)改進(jìn) mesa 優(yōu)化問(wèn)題的條件數(shù)。這導(dǎo)致 mesa-objective Lt (W) 快速下降。此外可以看到性能隨著深度的增加而顯著提高。因此可以認(rèn)為自回歸 mesa-objective Lt (W) 的快速下降是通過(guò)對(duì)更好的預(yù)處理數(shù)據(jù)進(jìn)行逐步(跨層)mesa 優(yōu)化來(lái)實(shí)現(xiàn)的。
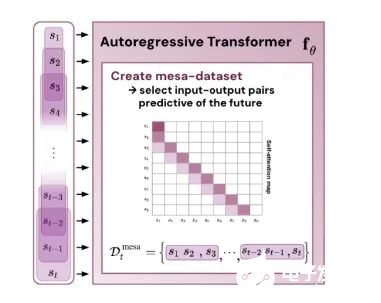
這表明,如果 transformer 在構(gòu)建的 token 上進(jìn)行訓(xùn)練,它就會(huì)通過(guò) mesa 優(yōu)化進(jìn)行預(yù)測(cè)。有趣的是,當(dāng)直接給出序列元素時(shí),transformer 會(huì)自行通過(guò)對(duì)元素進(jìn)行分組來(lái)構(gòu)造 token,研究團(tuán)隊(duì)將其稱(chēng)為「創(chuàng)建 mesa 數(shù)據(jù)集」。
結(jié)論該研究表明,當(dāng)在標(biāo)準(zhǔn)自回歸目標(biāo)下針對(duì)序列預(yù)測(cè)任務(wù)進(jìn)行訓(xùn)練時(shí),Transformer 模型能夠開(kāi)發(fā)基于梯度的推理算法。因此,在多任務(wù)、元學(xué)習(xí)設(shè)置下獲得的最新結(jié)果也可以轉(zhuǎn)化到傳統(tǒng)的自監(jiān)督 LLM 訓(xùn)練設(shè)置中。此外,該研究還發(fā)現(xiàn)學(xué)得的自回歸推理算法可以在無(wú)需重新訓(xùn)練的情況下重新調(diào)整用途,以解決有監(jiān)督的上下文學(xué)習(xí)任務(wù),從而在單個(gè)統(tǒng)一框架內(nèi)解釋結(jié)果。
那么,這些與上下文學(xué)習(xí)(in-context learning)有什么關(guān)系呢?該研究認(rèn)為:在自回歸序列任務(wù)上訓(xùn)練 transformer 后,它實(shí)現(xiàn)了適當(dāng)?shù)?mesa 優(yōu)化,因此可以進(jìn)行少樣本(few-shot)上下文學(xué)習(xí),而無(wú)需任何微調(diào)。
該研究假設(shè) LLM 也存在 mesa 優(yōu)化,從而提高了其上下文學(xué)習(xí)能力。有趣的是,該研究還觀察到,為 LLM 有效調(diào)整 prompt 也可以帶來(lái)上下文學(xué)習(xí)能力的實(shí)質(zhì)性改進(jìn)。
5. 1.5T內(nèi)存挑戰(zhàn)英偉達(dá)!8枚芯片撐起3個(gè)GPT-4,華人AI芯片獨(dú)角獸估值365億
原文:https://mp.weixin.qq.com/s/GjG_OpzlAO7vGwOW7fmE-w
高端GPU持續(xù)缺貨之下,一家要挑戰(zhàn)英偉達(dá)的芯片初創(chuàng)公司成為行業(yè)熱議焦點(diǎn)。8枚芯片跑大模型,就能支持5萬(wàn)億參數(shù)(GPT-4的三倍) 。這是獨(dú)角獸企業(yè)SambaNova剛剛發(fā)布的新型AI芯片SN40L——型號(hào)中40代表是他們第四代產(chǎn)品,L代表專(zhuān)為大模型(LLM)優(yōu)化:高達(dá)1.5T的內(nèi)存,支持25.6萬(wàn)個(gè)token的序列長(zhǎng)度。
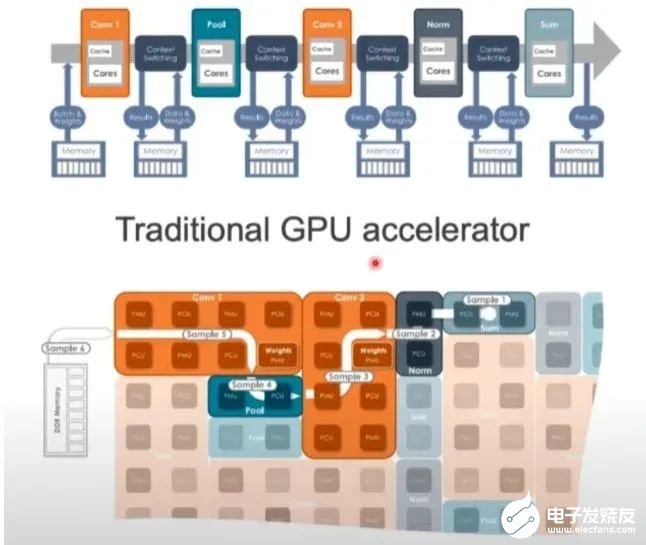
CEO Rodrigo Liang表示,當(dāng)前行業(yè)標(biāo)準(zhǔn)做法下運(yùn)行萬(wàn)億參數(shù)大模型需要數(shù)百枚芯片,我們的方法使總擁有成本只有標(biāo)準(zhǔn)方法的1/25。SambaNova目前估值50億美元(約365億人民幣),累計(jì)完成了6輪總計(jì)11億美元的融資,投資方包括英特爾、軟銀、三星、GV等。他們不僅在芯片上要挑戰(zhàn)英偉達(dá),業(yè)務(wù)模式上也說(shuō)要比英偉達(dá)走的更遠(yuǎn):直接參與幫助企業(yè)訓(xùn)練私有大模型。目標(biāo)客戶(hù)上野心更是很大:瞄準(zhǔn)世界上最大的2000家企業(yè)。 1.5TB內(nèi)存的AI芯片最新產(chǎn)品SN40L,由臺(tái)積電5納米工藝制造,包含1020億晶體管,峰值速度638TeraFLOPS。與英偉達(dá)等其他AI芯片更大的不同在于新的三層Dataflow內(nèi)存系統(tǒng)。
1.5TB內(nèi)存的AI芯片最新產(chǎn)品SN40L,由臺(tái)積電5納米工藝制造,包含1020億晶體管,峰值速度638TeraFLOPS。與英偉達(dá)等其他AI芯片更大的不同在于新的三層Dataflow內(nèi)存系統(tǒng)。-
520MB片上SRAM內(nèi)存
-
65GB的高帶寬HBM3內(nèi)存
-
以及高達(dá)1.5TB的外部DRAM內(nèi)存
與主要競(jìng)品相比,英偉達(dá)H100最高擁有80GB HBM3內(nèi)存,AMD MI300擁有192GB HBM3內(nèi)存。SN40L的高帶寬HBM3內(nèi)存實(shí)際比前兩者小,更多依靠大容量DRAM。Rodrigo Liang表示,雖然DRAM速度更慢,但專(zhuān)用的軟件編譯器可以智能地分配三個(gè)內(nèi)存層之間的負(fù)載,還允許編譯器將8個(gè)芯片視為單個(gè)系統(tǒng)。
除了硬件指標(biāo),SN40L針對(duì)大模型做的優(yōu)化還有同時(shí)提供密集和稀疏計(jì)算加速。他們認(rèn)為大模型中許多權(quán)重設(shè)置為0,像其他數(shù)據(jù)一樣去執(zhí)行操作很浪費(fèi)。他們找到一種軟件層面的加速辦法,與調(diào)度和數(shù)據(jù)傳輸有關(guān),但沒(méi)有透露細(xì)節(jié),“我們還沒(méi)準(zhǔn)備好向公布是如何做到這一點(diǎn)的”。咨詢(xún)機(jī)構(gòu)Gartner的分析師Chirag Dekate認(rèn)為,SN40L的一個(gè)可能優(yōu)勢(shì)在于多模態(tài)AI。
GPU的架構(gòu)非常嚴(yán)格,面對(duì)圖像、視頻、文本等多樣數(shù)據(jù)時(shí)可能不夠靈活,而SambaNova可以調(diào)整硬件來(lái)滿(mǎn)足工作負(fù)載的要求。
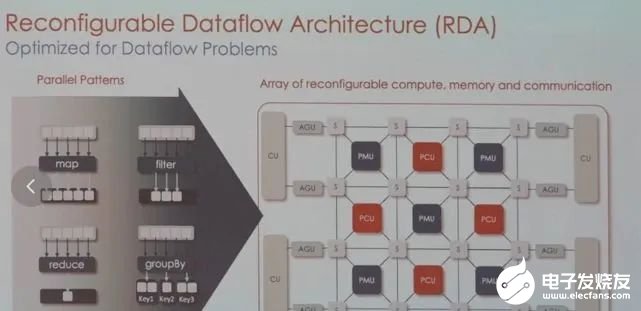
目前,SambaNova的芯片和系統(tǒng)已獲得不少大型客戶(hù),包括世界排名前列的超算實(shí)驗(yàn)室,日本富岳、美國(guó)阿貢國(guó)家實(shí)驗(yàn)室、勞倫斯國(guó)家實(shí)驗(yàn)室,以及咨詢(xún)公司埃森哲等。業(yè)務(wù)模式也比較特別,芯片不單賣(mài),而是出售其定制技術(shù)堆棧,從芯片到服務(wù)器系統(tǒng),甚至包括部署大模型。為此,他們與TogetherML聯(lián)合開(kāi)發(fā)了BloomChat,一個(gè)1760億參數(shù)的多語(yǔ)言聊天大模型。BloomChat建立在BigScience組織的開(kāi)源大模型Bloom之上,并在來(lái)自O(shè)penChatKit、Dolly 2.0和OASST1的OIG上進(jìn)行了微調(diào)。訓(xùn)練過(guò)程中,它使用了SambaNova獨(dú)特的可重配置數(shù)據(jù)流架構(gòu),然后在SambaNova DataScale系統(tǒng)進(jìn)行訓(xùn)練。
這也是這家公司最大被投資者熱捧之外的最大爭(zhēng)議點(diǎn)之一,很多人不看好一家公司既做芯片又做大模型。目前SambaNova包含SN40L芯片的人工智能引擎已上市,但定價(jià)沒(méi)有公開(kāi)。根據(jù)Rodrigo Liang的說(shuō)法,8個(gè)SN40L組成的集群總共可處理5萬(wàn)億參數(shù),相當(dāng)于70個(gè)700億參數(shù)大模型。全球2000強(qiáng)的企業(yè)只需購(gòu)買(mǎi)兩個(gè)這樣的8芯片集群,就能滿(mǎn)足所有大模型需求。
6. 十分鐘,深入淺出理解Transformer
原文:https://mp.weixin.qq.com/s/xtyP6cg6vROOXe1vlPEEew
Transformer是一個(gè)利用注意力機(jī)制來(lái)提高模型訓(xùn)練速度的模型。關(guān)于注意力機(jī)制可以參看這篇文章(https://zhuanlan.zhihu.com/p/52119092),trasnformer可以說(shuō)是完全基于自注意力機(jī)制的一個(gè)深度學(xué)習(xí)模型,因?yàn)樗m用于并行化計(jì)算,和它本身模型的復(fù)雜程度導(dǎo)致它在精度和性能上都要高于之前流行的RNN循環(huán)神經(jīng)網(wǎng)絡(luò)。那什么是transformer呢?你可以簡(jiǎn)單理解為它是一個(gè)黑盒子,當(dāng)我們?cè)谧鑫谋痉g任務(wù)是,我輸入進(jìn)去一個(gè)中文,經(jīng)過(guò)這個(gè)黑盒子之后,輸出來(lái)翻譯過(guò)后的英文。

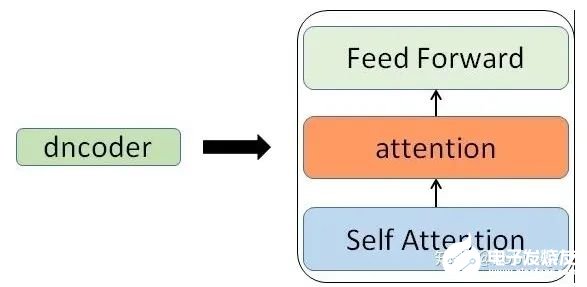
那么在這個(gè)黑盒子里面都有什么呢?里面主要有兩部分組成:Encoder 和 Decoder
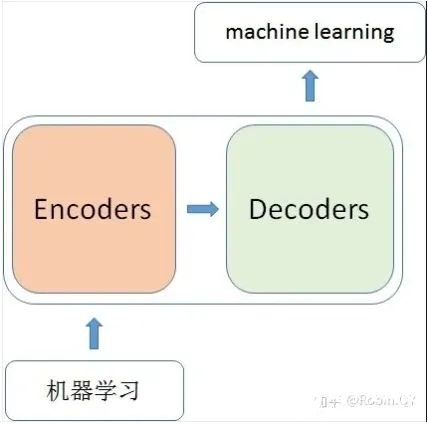
當(dāng)我輸入一個(gè)文本的時(shí)候,該文本數(shù)據(jù)會(huì)先經(jīng)過(guò)一個(gè)叫Encoders的模塊,對(duì)該文本進(jìn)行編碼,然后將編碼后的數(shù)據(jù)再傳入一個(gè)叫Decoders的模塊進(jìn)行解碼,解碼后就得到了翻譯后的文本,對(duì)應(yīng)的我們稱(chēng)Encoders為編碼器,Decoders為解碼器。那么編碼器和解碼器里邊又都是些什么呢?細(xì)心的同學(xué)可能已經(jīng)發(fā)現(xiàn)了,上圖中的Decoders后邊加了個(gè)s,那就代表有多個(gè)編碼器了唄,沒(méi)錯(cuò),這個(gè)編碼模塊里邊,有很多小的編碼器,一般情況下,Encoders里邊有6個(gè)小編碼器,同樣的,Decoders里邊有6個(gè)小解碼器。
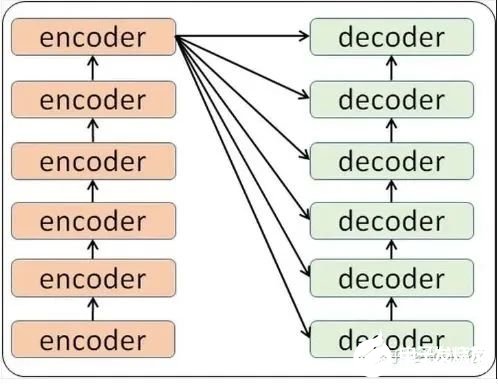
我們看到,在編碼部分,每一個(gè)的小編碼器的輸入是前一個(gè)小編碼器的輸出,而每一個(gè)小解碼器的輸入不光是它的前一個(gè)解碼器的輸出,還包括了整個(gè)編碼部分的輸出。那么你可能又該問(wèn)了,那每一個(gè)小編碼器里邊又是什么呢?我們放大一個(gè)encoder,發(fā)現(xiàn)里邊的結(jié)構(gòu)是一個(gè)自注意力機(jī)制加上一個(gè)前饋神經(jīng)網(wǎng)絡(luò)。
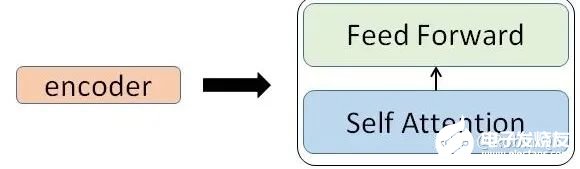
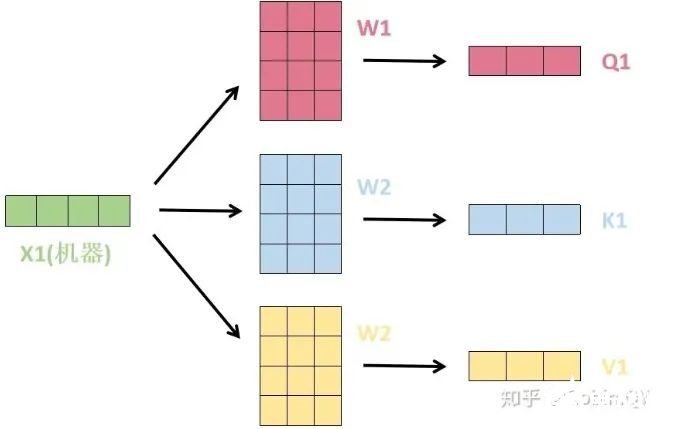
我們先來(lái)看下self-attention是什么樣子的。我們通過(guò)幾個(gè)步驟來(lái)解釋?zhuān)?/strong>1、首先,self-attention的輸入就是詞向量,即整個(gè)模型的最初的輸入是詞向量的形式。那自注意力機(jī)制呢,顧名思義就是自己和自己計(jì)算一遍注意力,即對(duì)每一個(gè)輸入的詞向量,我們需要構(gòu)建self-attention的輸入。在這里,transformer首先將詞向量乘上三個(gè)矩陣,得到三個(gè)新的向量,之所以乘上三個(gè)矩陣參數(shù)而不是直接用原本的詞向量是因?yàn)檫@樣增加更多的參數(shù),提高模型效果。對(duì)于輸入X1(機(jī)器),乘上三個(gè)矩陣后分別得到Q1,K1,V1,同樣的,對(duì)于輸入X2(學(xué)習(xí)),也乘上三個(gè)不同的矩陣得到Q2,K2,V2。
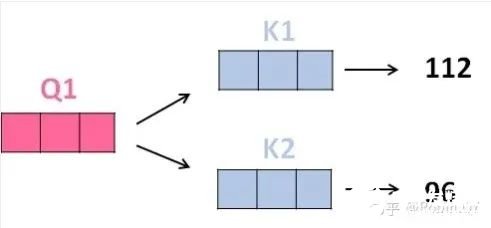
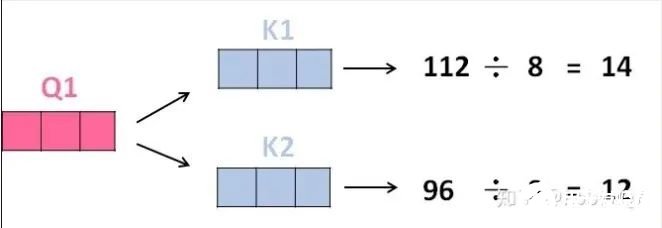
2、那接下來(lái)就要計(jì)算注意力得分了,這個(gè)得分是通過(guò)計(jì)算Q與各個(gè)單詞的K向量的點(diǎn)積得到的。我們以X1為例,分別將Q1和K1、K2進(jìn)行點(diǎn)積運(yùn)算,假設(shè)分別得到得分112和96。
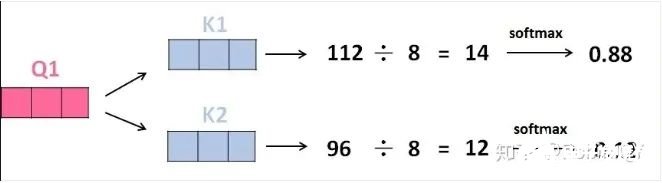
3、將得分分別除以一個(gè)特定數(shù)值8(K向量的維度的平方根,通常K向量的維度是64)這能讓梯度更加穩(wěn)定,則得到結(jié)果如下:
4、將上述結(jié)果進(jìn)行softmax運(yùn)算得到,softmax主要將分?jǐn)?shù)標(biāo)準(zhǔn)化,使他們都是正數(shù)并且加起來(lái)等于1。
5、將V向量乘上softmax的結(jié)果,這個(gè)思想主要是為了保持我們想要關(guān)注的單詞的值不變,而掩蓋掉那些不相關(guān)的單詞(例如將他們乘上很小的數(shù)字)

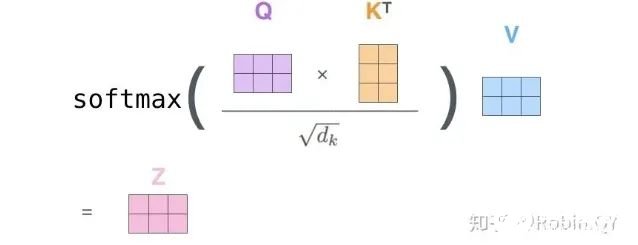
6、將帶權(quán)重的各個(gè)V向量加起來(lái),至此,產(chǎn)生在這個(gè)位置上(第一個(gè)單詞)的self-attention層的輸出,其余位置的self-attention輸出也是同樣的計(jì)算方式。 將上述的過(guò)程總結(jié)為一個(gè)公式就可以用下圖表示:
將上述的過(guò)程總結(jié)為一個(gè)公式就可以用下圖表示:
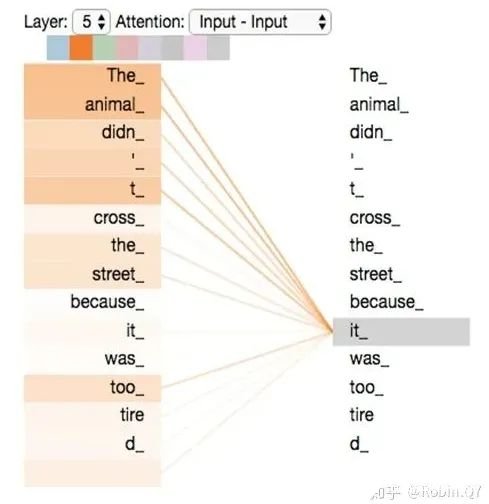
self-attention層到這里就結(jié)束了嗎?還沒(méi)有,論文為了進(jìn)一步細(xì)化自注意力機(jī)制層,增加了“多頭注意力機(jī)制”的概念,這從兩個(gè)方面提高了自注意力層的性能。第一個(gè)方面,他擴(kuò)展了模型關(guān)注不同位置的能力,這對(duì)翻譯一下句子特別有用,因?yàn)槲覀兿胫馈癷t”是指代的哪個(gè)單詞。
第二個(gè)方面,他給了自注意力層多個(gè)“表示子空間”。對(duì)于多頭自注意力機(jī)制,我們不止有一組Q/K/V權(quán)重矩陣,而是有多組(論文中使用8組),所以每個(gè)編碼器/解碼器使用8個(gè)“頭”(可以理解為8個(gè)互不干擾自的注意力機(jī)制運(yùn)算),每一組的Q/K/V都不相同。然后,得到8個(gè)不同的權(quán)重矩陣Z,每個(gè)權(quán)重矩陣被用來(lái)將輸入向量投射到不同的表示子空間。經(jīng)過(guò)多頭注意力機(jī)制后,就會(huì)得到多個(gè)權(quán)重矩陣Z,我們將多個(gè)Z進(jìn)行拼接就得到了self-attention層的輸出:

上述我們經(jīng)過(guò)了self-attention層,我們得到了self-attention的輸出,self-attention的輸出即是前饋神經(jīng)網(wǎng)絡(luò)層的輸入,然后前饋神經(jīng)網(wǎng)絡(luò)的輸入只需要一個(gè)矩陣就可以了,不需要八個(gè)矩陣,所以我們需要把這8個(gè)矩陣壓縮成一個(gè),我們?cè)趺醋瞿兀恐恍枰堰@些矩陣拼接起來(lái)然后用一個(gè)額外的權(quán)重矩陣與之相乘即可。
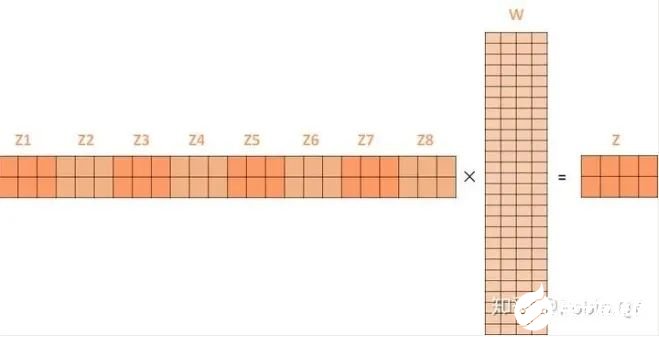
最終的Z就作為前饋神經(jīng)網(wǎng)絡(luò)的輸入。接下來(lái)就進(jìn)入了小編碼器里邊的前饋神經(jīng)網(wǎng)模塊了,關(guān)于前饋神經(jīng)網(wǎng)絡(luò),網(wǎng)上已經(jīng)有很多資料,在這里就不做過(guò)多講解了,只需要知道,前饋神經(jīng)網(wǎng)絡(luò)的輸入是self-attention的輸出,即上圖的Z,是一個(gè)矩陣,矩陣的維度是(序列長(zhǎng)度×D詞向量),之后前饋神經(jīng)網(wǎng)絡(luò)的輸出也是同樣的維度。以上就是一個(gè)小編碼器的內(nèi)部構(gòu)造了,一個(gè)大的編碼部分就是將這個(gè)過(guò)程重復(fù)了6次,最終得到整個(gè)編碼部分的輸出。然后再transformer中使用了6個(gè)encoder,為了解決梯度消失的問(wèn)題,在Encoders和Decoder中都是用了殘差神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),即每一個(gè)前饋神經(jīng)網(wǎng)絡(luò)的輸入不光包含上述self-attention的輸出Z,還包含最原始的輸入。上述說(shuō)到的encoder是對(duì)輸入(機(jī)器學(xué)習(xí))進(jìn)行編碼,使用的是自注意力機(jī)制+前饋神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),同樣的,在decoder中使用的也是同樣的結(jié)構(gòu)。也是首先對(duì)輸出(machine learning)計(jì)算自注意力得分,不同的地方在于,進(jìn)行過(guò)自注意力機(jī)制后,將self-attention的輸出再與Decoders模塊的輸出計(jì)算一遍注意力機(jī)制得分,之后,再進(jìn)入前饋神經(jīng)網(wǎng)絡(luò)模塊。
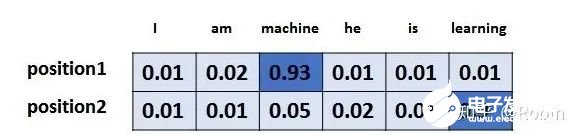
以上,就講完了Transformer編碼和解碼兩大模塊,那么我們回歸最初的問(wèn)題,將“機(jī)器學(xué)習(xí)”翻譯成“machine learing”,解碼器輸出本來(lái)是一個(gè)浮點(diǎn)型的向量,怎么轉(zhuǎn)化成“machine learing”這兩個(gè)詞呢?是個(gè)工作是最后的線性層接上一個(gè)softmax,其中線性層是一個(gè)簡(jiǎn)單的全連接神經(jīng)網(wǎng)絡(luò),它將解碼器產(chǎn)生的向量投影到一個(gè)更高維度的向量(logits)上,假設(shè)我們模型的詞匯表是10000個(gè)詞,那么logits就有10000個(gè)維度,每個(gè)維度對(duì)應(yīng)一個(gè)惟一的詞的得分。之后的softmax層將這些分?jǐn)?shù)轉(zhuǎn)換為概率。選擇概率最大的維度,并對(duì)應(yīng)地生成與之關(guān)聯(lián)的單詞作為此時(shí)間步的輸出就是最終的輸出啦!!假設(shè)詞匯表維度是6,那么輸出最大概率詞匯的過(guò)程如下:
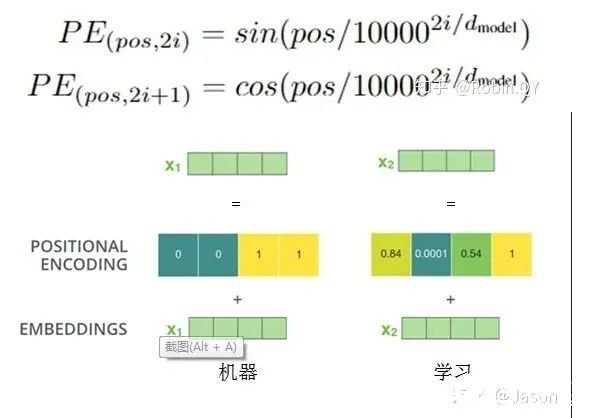
以上就是Transformer的框架了,但是還有最后一個(gè)問(wèn)題,我們都是到RNN中的每個(gè)輸入是時(shí)序的,是又先后順序的,但是Transformer整個(gè)框架下來(lái)并沒(méi)有考慮順序信息,這就需要提到另一個(gè)概念了:“位置編碼”。Transformer中確實(shí)沒(méi)有考慮順序信息,那怎么辦呢,我們可以在輸入中做手腳,把輸入變得有位置信息不就行了,那怎么把詞向量輸入變成攜帶位置信息的輸入呢?我們可以給每個(gè)詞向量加上一個(gè)有順序特征的向量,發(fā)現(xiàn)sin和cos函數(shù)能夠很好的表達(dá)這種特征,所以通常位置向量用以下公式來(lái)表示:
最后祭出這張經(jīng)典的圖,最初看這張圖的時(shí)候可能難以理解,希望大家在深入理解Transformer后再看這張圖能夠有更深刻的認(rèn)識(shí)。
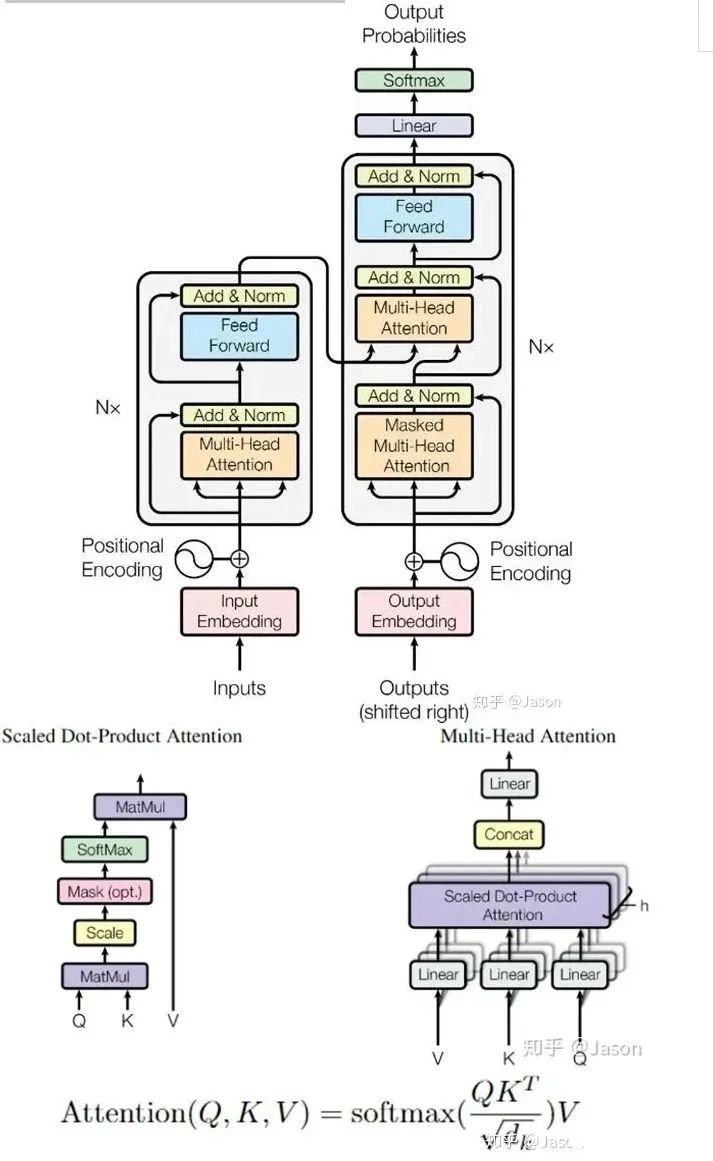
Transformer就介紹到這里了,后來(lái)的很多經(jīng)典的模型比如BERT、GPT-2都是基于Transformer的思想。我們有機(jī)會(huì)再詳細(xì)介紹這兩個(gè)刷新很多記錄的經(jīng)典模型。
聲明:本文內(nèi)容及配圖由入駐作者撰寫(xiě)或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
原文標(biāo)題:【AI簡(jiǎn)報(bào)20230922期】華人AI芯片挑戰(zhàn)英偉達(dá),深入淺出理解Transformer
文章出處:【微信號(hào):RTThread,微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
相關(guān)推薦
巨頭英偉達(dá)展開(kāi)有力競(jìng)爭(zhēng)。 為了加強(qiáng)其領(lǐng)導(dǎo)團(tuán)隊(duì),Rain AI于2024年6月成功聘請(qǐng)前蘋(píng)果公司芯片執(zhí)行官Jean-Didier Allegrucci擔(dān)任硬件工程負(fù)責(zé)人。這一舉措無(wú)疑為R
![的頭像]() 發(fā)表于
發(fā)表于 11-21 11:10
?446次閱讀
英偉達(dá)現(xiàn)身日本人工智能研發(fā)初創(chuàng)公司Sakana AI的A輪融資名單中;據(jù)悉;Sakana AI的A輪融資而完成超過(guò)1億美元,此次融資由New Enterprise Associates
![的頭像]() 發(fā)表于
發(fā)表于 09-05 15:46
?646次閱讀
原創(chuàng)聲明:該文章是個(gè)人在項(xiàng)目中親歷后的經(jīng)驗(yàn)總結(jié)和分享,如有搬運(yùn)需求請(qǐng)注明出處。 這是“深入淺出系列”文章的第一篇,主要記錄和分享程序設(shè)計(jì)的一些思想和方法論,如果讀者覺(jué)得所有受用,還請(qǐng)“一鍵三連
![的頭像]() 發(fā)表于
發(fā)表于 08-09 16:00
?265次閱讀
電子發(fā)燒友網(wǎng)報(bào)道(文/周凱揚(yáng))近日,一家由哈佛輟學(xué)生成立的初創(chuàng)公司Etched,宣布了他們?cè)诖蛟斓囊豢睢皩?zhuān)用”AI芯片Sohu。據(jù)其聲稱(chēng)該芯片的速度將是英偉
![的頭像]() 發(fā)表于
發(fā)表于 07-01 09:03
?1385次閱讀
在全球半導(dǎo)體行業(yè)持續(xù)演進(jìn)的背景下,英偉達(dá)(NVIDIA)的AI芯片需求正迎來(lái)前所未有的增長(zhǎng)。據(jù)悉,英偉達(dá)
![的頭像]() 發(fā)表于
發(fā)表于 06-24 18:05
?1650次閱讀
英偉達(dá)創(chuàng)始人兼CEO黃仁勛近日宣布,公司旗下的Blackwell芯片已正式投入生產(chǎn)。這款芯片是英偉達(dá)
![的頭像]() 發(fā)表于
發(fā)表于 06-04 09:23
?1977次閱讀
佐思汽研發(fā)布《2024年英偉達(dá)AI與汽車(chē)業(yè)務(wù)分析報(bào)告暨 汽車(chē)新四化每周觀察2024年5月第1期》報(bào)告
![的頭像]() 發(fā)表于
發(fā)表于 05-29 10:35
?735次閱讀
近來(lái),以ChatGPT為代表的AI聊天機(jī)器人已經(jīng)導(dǎo)致英偉達(dá)AI芯片供應(yīng)緊張。然而,隨著能夠創(chuàng)造視頻并進(jìn)行近似人類(lèi)交流的新型
![的頭像]() 發(fā)表于
發(fā)表于 05-24 10:04
?505次閱讀
2024年3月19日,[英偉達(dá)]CEO[黃仁勛]在GTC大會(huì)上公布了新一代AI芯片架構(gòu)BLACKWELL,并推出基于該架構(gòu)的超級(jí)芯片GB20
發(fā)表于 05-13 17:16
將雙方數(shù)十年的合作深入擴(kuò)展到新思科技EDA全套技術(shù)棧 摘要: 新思科技攜手英偉達(dá),將其領(lǐng)先的AI驅(qū)動(dòng)型電子設(shè)計(jì)自動(dòng)化(EDA)全套技術(shù)棧部署于英偉
發(fā)表于 03-20 13:43
?277次閱讀

鑒于ChatGPT的廣泛應(yīng)用,引發(fā)了AI算力需求的迅猛增長(zhǎng),使得英偉達(dá)的AI芯片供不應(yīng)求,出現(xiàn)大規(guī)模短缺。如今,
![的頭像]() 發(fā)表于
發(fā)表于 02-27 15:10
?1173次閱讀
近期熱門(mén)的 H100 芯片運(yùn)期短縮數(shù)天后,英偉達(dá)新型 AI 旗艦芯片 B100搭載全新的 Bla
![的頭像]() 發(fā)表于
發(fā)表于 02-25 09:29
?929次閱讀
AI芯片行業(yè)資訊
深圳市浮思特科技有限公司
發(fā)布于 :2024年02月19日 17:54:43
作為全球高端AI芯片市場(chǎng)80%份額的霸主,英偉達(dá)自2023以來(lái)股價(jià)上漲超過(guò)兩倍,2024年市值高達(dá)1.73萬(wàn)億美元。知名公司如微軟、OpenAI、Meta紛紛采購(gòu)
![的頭像]() 發(fā)表于
發(fā)表于 02-18 11:08
?698次閱讀
英偉達(dá)在面臨美國(guó)新規(guī)的挑戰(zhàn)時(shí),迅速為中國(guó)市場(chǎng)開(kāi)發(fā)了特供版AI芯片,旨在滿(mǎn)足中國(guó)對(duì)尖端人工智能技術(shù)的需求。
![的頭像]() 發(fā)表于
發(fā)表于 01-08 17:07
?1180次閱讀
") 【AI簡(jiǎn)報(bào)20230922期】華人AI芯片挑戰(zhàn)英偉達(dá),深入淺出理解Transformer
【AI簡(jiǎn)報(bào)20230922期】華人AI芯片挑戰(zhàn)英偉達(dá),深入淺出理解Transformer






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論