

自動駕駛系統在實際應用中需要面對各種復雜的場景,尤其是Corner Case(極端情況)對自動駕駛的感知和決策能力提出了更高的要求。Corner Case指的是在實際駕駛中可能出現的極端或罕見情況,如交通事故、惡劣天氣條件或復雜的道路狀況。BEV技術通過提供全局視角來增強自動駕駛系統的感知能力,從而有望在處理這些極端情況時提供更好的支持。本文將探討BEV(Bird‘s Eye View,俯視視角)技術如何幫助自動駕駛系統應對Corner Case,提高系統的可靠性和安全性。
Transformer 作為你一種基于自注意力機制的深度學習模型,最早應用于自然語言處理任務。其核心思想是通過自注意力機制捕捉輸入序列中的長距離依賴關系,從而提高模型在處理序列數據上的能力。
將以上兩者進行有效結合也是在自動駕駛策略中相當吃香的一門新興技術。
BEV的技術優勢分析
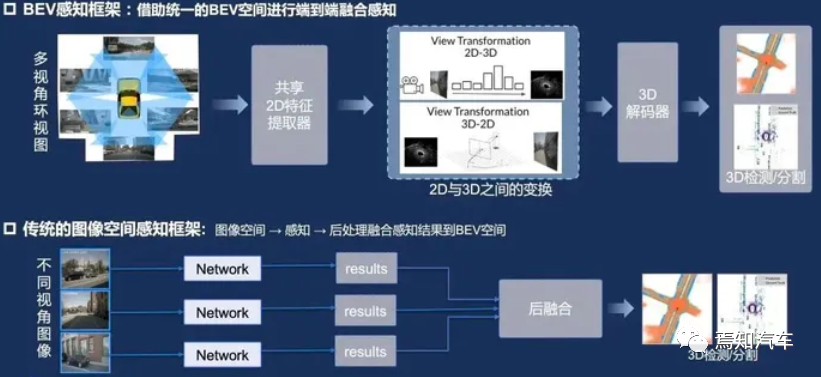
BEV是一種將三維環境信息投影到二維平面的方法,以俯視視角展示環境中的物體和地形。在自動駕駛領域,BEV 可以幫助系統更好地理解周圍環境,提高感知和決策的準確性。在環境感知階段,BEV 可以將激光雷達、雷達和相機等多模態數據融合在同一平面上。這種方法可以消除數據之間的遮擋和重疊問題,提高物體檢測和跟蹤的精度。同時,BEV 可以為后續的預測和決策階段提供清晰的環境表示,有利于提高系統的整體性能。
1、Lidar與BEV技術的比較:
首先,BEV技術能提供全局視角的環境感知,有助于提高自動駕駛系統在復雜場景下的表現。然而,激光雷達在距離和空間信息方面具有更高的精度。
其次,BEV技術通過攝像頭捕捉圖像,可以獲取顏色和紋理信息,而激光雷達在這方面的性能較弱。
此外,BEV技術的成本相對較低,適用于大規模商業化部署。
2、BEV技術與傳統單視角攝像頭的比較
傳統單視角攝像頭是一種常用的車輛感知設備,可以捕捉車輛周圍的環境信息。然而,單視角攝像頭在視野和信息獲取方面存在一定局限性。BEV技術整合多個攝像頭的圖像,提供全局視角,可以更全面地了解車輛周圍的環境。

BEV技術在復雜場景和惡劣天氣條件下,相對于單視角攝像頭具有更好的環境感知能力,因為BEV能夠融合來自不同角度的圖像信息,從而提高系統對環境的感知。
BEV技術可以幫助自動駕駛系統更好地處理Corner Case,如復雜道路狀況、狹窄或遮擋的道路等,而單視角攝像頭在這些情況下可能表現不佳。
當然在成本和資源占用情況方面,由于BEV需要進行各個視角下的圖像感知,重建和拼接,因此是比較耗費算力和存儲資源的。雖然BEV技術需要部署多個攝像頭,但總體成本仍低于激光雷達,且相對于單視角攝像頭在性能上有明顯提升。
綜上所述,BEV技術在自動駕駛領域與其他感知技術相比具有一定優勢。尤其是在處理Corner Case方面,BEV技術可以提供全局視角的環境感知,有助于提高自動駕駛系統在復雜場景下的表現。然而,為了充分發揮BEV技術的優勢,仍需要進一步研究和開發,以提高圖像處理能力、傳感器融合技術以及異常行為預測等方面的性能。同時,結合其他感知技術(如激光雷達)以及深度學習和機器學習算法,可以進一步提升自動駕駛系統在各種場景下的穩定性和安全性。
基于 Transformer 和 BEV 的自動駕駛系統
與此同時,Bird’s Eye View (BEV) 作為一種有效的環境感知方法,在自動駕駛系統中發揮著重要作用。結合 Transformer 和 BEV 的優勢,我們可以構建一個端到端的自動駕駛系統,實現高精度的感知、預測和決策。本文也將同時探討 Transformer 和 BEV 在自動駕駛領域如何進行有效結合和應用,以提高系統性能。
具體步驟如下:
1、數據預處理:
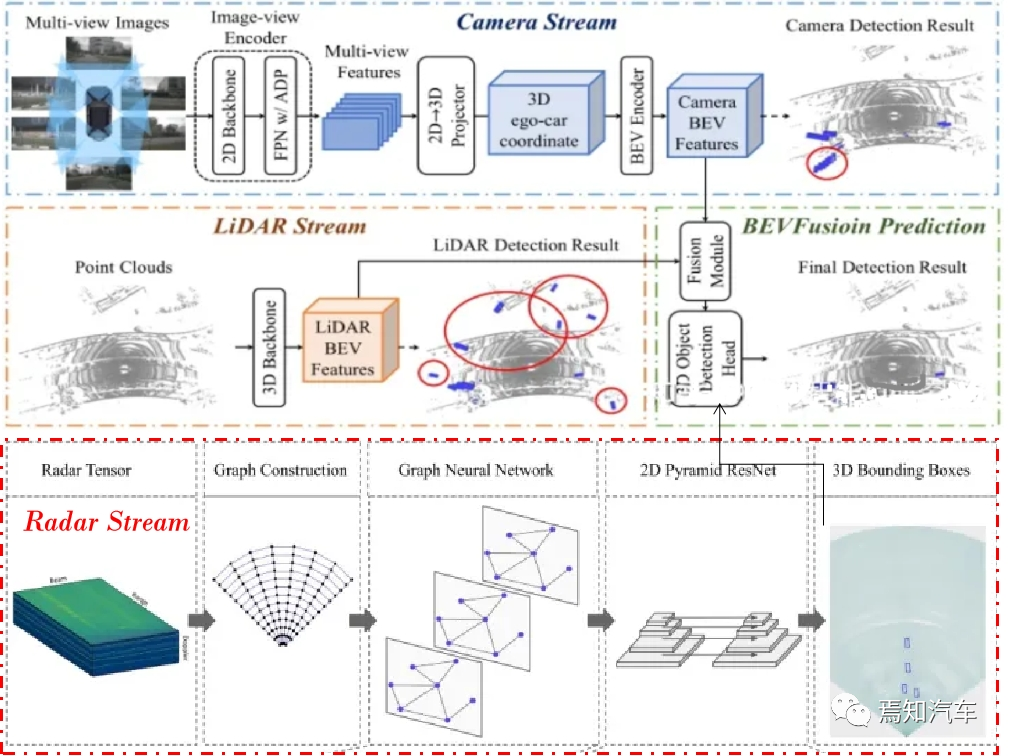
將激光雷達、雷達和相機等多模態數據融合為 BEV 格式,并進行必要的預處理操作,如數據增強、歸一化等。
首先,我們需要將激光雷達、雷達和相機等多模態數據轉換為 BEV 格式。對于激光雷達點云數據,我們可以將三維點云投影到一個二維平面上,然后對該平面進行柵格化,以生成一個高度圖;對于雷達數據,我們可以將距離、角度信息轉換為笛卡爾坐標,然后在 BEV 平面上進行柵格化;對于相機數據,我們可以將圖像數據投影到 BEV 平面上,生成一個顏色或強度圖。
2、感知模塊:
在自動駕駛的感知階段,Transformer 模型可以用于提取多模態數據中的特征,如激光雷達點云、圖像、雷達數據等。通過對這些數據進行端到端的訓練,Transformer 能夠自動學習到這些數據的內在結構和相互關系,從而有效地識別和定位環境中的障礙物。
利用 Transformer 模型對 BEV 數據進行特征提取,實現障礙物的檢測和定位。
將這些 BEV 格式的數據疊加在一起,形成一個多通道的 BEV 圖像。設激光雷達的 BEV 高度圖為 H(x, y),雷達的 BEV 距離圖為 R(x, y),相機的 BEV 強度圖為 I(x, y),則多通道的 BEV 圖像可以表示為:
B(x, y) = [H(x, y), R(x, y), I(x, y)]
其中 B(x, y) 表示多通道 BEV 圖像在坐標 (x, y) 處的像素值,[] 表示通道疊加。
3、預測模塊:
基于感知模塊的輸出,使用 Transformer 模型預測其他交通參與者的未來行為和軌跡。通過學習歷史軌跡數據,Transformer 能夠捕捉到交通參與者的運動模式和相互影響,從而為自動駕駛系統提供更準確的預測結果。
具體的講,我們首先使用 Transformer 對多通道 BEV 圖像進行特征提取。設輸入 BEV 圖像為 B(x, y),我們可以通過多層自注意力機制和位置編碼來提取特征 F(x, y):
F(x, y) = Transformer(B(x, y))
其中 F(x, y) 表示特征圖,在坐標 (x, y) 處的特征值。
然后,我們利用提取到的特征 F(x, y) 預測其他交通參與者的行為和軌跡。可以采用 Transformer 的解碼器來生成預測結果,如下所示:
P(t) = Decoder(F(x, y), t)
其中 P(t) 表示在時間 t 處的預測結果,Decoder 表示 Transformer 解碼器。
通過以上步驟,我們可以實現基于 Transformer 和 BEV 的數據融合與預測。具體的 Transformer 結構和參數設置可以根據實際應用場景進行調整,以達到最佳性能。
4、決策模塊:
根據預測模塊的結果,結合交通規則和車輛動力學模型,采用 Transformer 模型生成合適的駕駛策略。
通過將環境信息、交通規則和車輛動力學模型整合到模型中,Transformer 能夠學習到高效且安全的駕駛策略。如路徑規劃、速度規劃等。此外,利用 Transformer 的多頭自注意力機制,可以有效地平衡不同信息源之間的權重,從而在復雜環境中做出更為合理的決策。
以下是采用該方法的具體步驟:
1、數據收集與預處理:
首先,需要收集大量的駕駛數據,包括車輛狀態信息(如速度、加速度、方向盤角度等)、路況信息(如道路類型、交通標志、車道線等)、周圍環境信息(如其他車輛、行人、自行車等)以及駕駛員采取的操作。對這些數據進行預處理,包括數據清洗、標準化和特征提取。
2、數據編碼與序列化:
將收集到的數據編碼成適合 Transformer 模型輸入的形式。這通常包括將連續的數值數據進行離散化,并將離散化的數據轉換成向量形式。同時,需要將數據序列化,以便 Transformer 模型能夠處理時序信息。
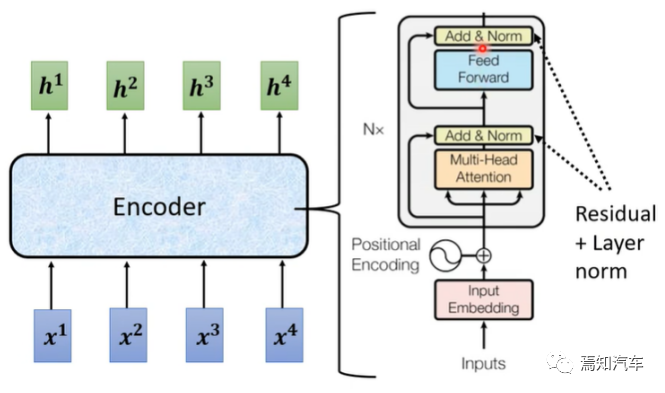
2.1、Transformer 編碼器
Transformer 編碼器由多層相同的子層組成,每個子層包含兩個部分:多頭自注意力(Multi-Head Attention)和前饋神經網絡(Feed-Forward Neural Network)。
多頭自注意力:首先將輸入序列分為 h 個不同的頭,分別計算每個頭的自注意力,然后將這些頭的輸出拼接在一起。這樣可以捕捉輸入序列中不同尺度的依賴關系。
多頭自注意力的計算公式為:
MHA(X) = Concat(head_1, head_2, 。.., head_h) * W_O
其中 MHA(X) 表示多頭自注意力的輸出,head_i 表示第 i 個頭的輸出,W_O 是輸出權重矩陣。
前饋神經網絡:接下來,將多頭自注意力的輸出傳遞給前饋神經網絡。前饋神經網絡通常包含兩層全連接層和一個激活函數(如 ReLU)。前饋神經網絡的計算公式為:
FFN(x) = max(0, xW_1 + b_1) * W_2 + b_2
其中 FFN(x) 表示前饋神經網絡的輸出,W_1 和 W_2 是權重矩陣,b_1 和 b_2 是偏置向量,max(0, x) 表示 ReLU 激活函數。
此外,編碼器中的每個子層都包含殘差連接和層歸一化(Layer Normalization),這有助于提高模型的訓練穩定性和收斂速度。
2.2、Transformer 解碼器
與編碼器類似,Transformer 解碼器也由多層相同的子層組成,每個子層包含三個部分:多頭自注意力、編碼器-解碼器注意力(Encoder-Decoder Attention)和前饋神經網絡。
多頭自注意力:與編碼器中的多頭自注意力相同,用于計算解碼器輸入序列中各個元素之間的關聯程度。
編碼器-解碼器注意力:用于計算解碼器輸入序列與編碼器輸出序列之間的關聯程度。其計算方法與自注意力類似,只是查詢向量來自解碼器輸入序列,而鍵向量和值向量來自編碼器輸出序列。
前饋神經網絡:與編碼器中的前饋神經網絡相同。解碼器中的每個子層同樣包含殘差連接和層歸一化。通過多層編碼器和解碼器的堆疊,Transformer 能夠處理具有復雜依賴關系的序列數據。
3、構建 Transformer 模型:
構建一個適用于自動駕駛場景的 Transformer 模型,包括設置合適的層數、頭數和隱藏層大小。此外,還需要根據任務需求對模型進行微調,如使用駕駛策略生成任務的損失函數。
首先將特征向量通過MLP得到低維向量,傳遞到由GRU實現的自動回歸路徑點網絡,并用其初始化GRU的隱狀態。此外當前位置和目標位置也被輸入,使網絡關注隱狀態的相關上下文。
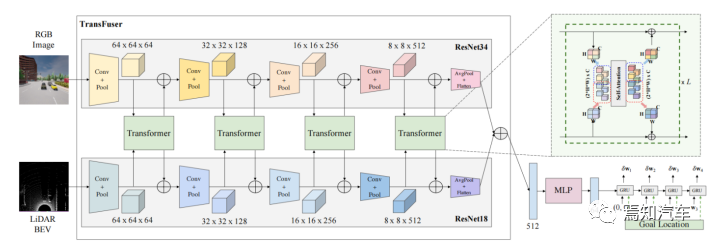
使用單層GRU,用線性層從隱狀態預測路徑點偏移量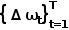 ,得到預測路徑點
,得到預測路徑點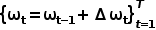 。GRU的輸入是原點。
。GRU的輸入是原點。
控制器根據預測路徑點,使用兩個PID控制器分別進行橫向和縱向控制,獲得轉向、剎車和油門值。將連續幀路徑點向量進行加權平均,則縱向控制器的輸入為其模長,橫向控制器的輸入為其朝向。
計算當前幀自車坐標系下的專家軌跡路徑點和預測軌跡路徑點的L1損失,即
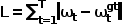
4、訓練與驗證:
使用收集到的數據集對 Transformer 模型進行訓練。在訓練過程中,需要對模型進行驗證以檢查其泛化能力。可以將數據集劃分為訓練集、驗證集和測試集,以便對模型進行評估。
5、駕駛策略生成:
在實際應用中,根據當前車輛狀態、路況信息和周圍環境信息輸入預訓練的 Transformer 模型。模型將根據這些輸入生成駕駛策略,如加速、減速、轉向等。
6、駕駛策略執行與優化:
將生成的駕駛策略傳遞給自動駕駛系統,以控制車輛。同時,收集實際執行過程中的數據,用于模型的進一步優化和迭代。
通過以上步驟,可以采用基于 Transformer 模型的方法在自動駕駛決策階段生成合適的駕駛策略。需要注意的是,由于自動駕駛領域的安全性要求較高,實際部署時需確保模型在各種場景下的性能和安全性。
Transformer+BEV技術解決Corner Case的實例
在本部分中,我們將詳細介紹三個BEV技術解決Corner Case的實例,分別涉及復雜道路狀況、惡劣天氣條件和預測異常行為。如下圖分別表示了自動駕駛中的一些Cornercase場景。采用Transformer+BEV的技術可以有效的識別及應對大部分當前所能識別出的邊緣場景。

1、處理復雜道路狀況
在復雜道路狀況下,如交通擁堵、復雜的路口或者不規則的路面,Transformer+BEV技術可以提供更全面的環境感知。通過整合車輛周圍多個攝像頭的圖像,BEV生成一個連續的俯視視角,使得自動駕駛系統能夠清晰地識別車道線、障礙物、行人和其他交通參與者。例如,在一個復雜的路口,BEV技術能幫助自動駕駛系統準確識別各個交通參與者的位置和行駛方向,從而為路徑規劃和決策提供可靠依據。
2、應對惡劣天氣條件
在惡劣天氣條件下,如雨、雪、霧等,傳統的攝像頭和激光雷達可能會受到影響,降低自動駕駛系統的感知能力。Transformer+BEV技術在這些情況下仍具有一定優勢,因為它可以融合來自不同角度的圖像信息,從而提高系統對環境的感知。為了進一步增強Transformer+BEV技術在惡劣天氣條件下的性能,可以考慮采用紅外攝像頭或者熱成像攝像頭等輔助設備,以補充可見光攝像頭在這些情況下的不足。
3、預測異常行為
在實際道路環境中,行人、騎行者和其他交通參與者可能會出現異常行為,如突然穿越馬路、違反交通規則等。BEV技術可以幫助自動駕駛系統更好地預測這些異常行為。借助全局視角,BEV可以提供完整的環境信息,使得自動駕駛系統能夠更準確地跟蹤和預測行人和其他交通參與者的動態。此外,結合機器學習和深度學習算法,Transformer+BEV技術可以進一步提高對異常行為的預測準確性,從而使自動駕駛系統在復雜場景中做出更為合理的決策。
4、狹窄或遮擋的道路
在狹窄或遮擋的道路環境中,傳統的攝像頭和激光雷達可能難以獲取足夠的信息來進行有效的環境感知。然而,Transformer+BEV技術可以在這些情況下發揮作用,因為它可以整合多個攝像頭捕獲的圖像,生成一個更全面的視圖。這使得自動駕駛系統能夠更好地了解車輛周圍的環境,識別狹窄通道中的障礙物,從而安全地通過這些場景。
5、并車和交通合流
在高速公路等場景中,自動駕駛系統需要應對并車和交通合流等復雜任務。這些任務對自動駕駛系統的感知能力提出了較高要求,因為系統需要實時評估周圍車輛的位置和速度,以確保安全地進行并車和交通合流。借助Transformer+BEV技術,自動駕駛系統可以獲得一個全局視角,清晰地了解車輛周圍的交通狀況。這將有助于自動駕駛系統制定合適的并車策略,確保車輛安全地融入交通流。
6、緊急情況應對
在緊急情況下,如交通事故、道路封閉或突發事件,自動駕駛系統需要快速做出決策以確保行駛安全。在這些情況下,Transformer+BEV技術可以為自動駕駛系統提供實時、全面的環境感知,幫助系統迅速評估當前的道路狀況。結合實時數據和先進的路徑規劃算法,自動駕駛系統可以制定合適的應急策略,避免潛在的風險。
通過這些實例,我們可以看到Transformer+BEV技術在應對Corner Case時具有很大的潛力。然而,為了充分發揮Transformer+BEV技術的優勢,仍需要進一步研究和開發,以提高圖像處理能力、傳感器融合技術以及異常行為預測等方面的性能。
結論
本文總結了Transformer和BEV技術在自動駕駛中的原理和應用,特別是如何解決Corner Case問題。通過提供全局視角和準確的環境感知,Transformer+BEV技術有望提高自動駕駛系統在面對極端情況時的可靠性和安全性。然而,當前的技術仍存在一定的局限性,例如在惡劣天氣條件下的性能下降。未來的研究應繼續關注BEV技術的改進和與其他感知技術的融合,以實現更高水平的自動駕駛安全性。
-
傳感器
+關注
關注
2557文章
51931瀏覽量
760152 -
編碼器
+關注
關注
45文章
3729瀏覽量
136156 -
自動駕駛
+關注
關注
788文章
14059瀏覽量
168275 -
Transformer
+關注
關注
0文章
147瀏覽量
6243
原文標題:利用Transformer BEV解決自動駕駛Corner Case的技術原理
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
玻璃反光也能誤識別?當自動駕駛遇到千奇百怪的corner case
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
【話題】特斯拉首起自動駕駛致命車禍,自動駕駛的冬天來了?
自動駕駛真的會來嗎?
自動駕駛的到來
自動駕駛技術的實現
玻璃反光也能誤識別?當自動駕駛遇到千奇百怪的corner case
基于BEV(Birds Eye View)的自動駕駛方案
BEV+Transformer對智能駕駛硬件系統有著什么樣的影響?
淺談自動駕駛BEV感知方案
自動駕駛領域中,什么是BEV?什么是Occupancy?

自動駕駛中一直說的BEV+Transformer到底是個啥?

淺析基于自動駕駛的4D-bev標注技術






 工商網監
工商網監

評論