 PolarDB物理復制刷臟約束問題和解決
PolarDB物理復制刷臟約束問題和解決
目前物理復制到了ro 開始刷120s apply_lsn 不推進的信息以后, 即使壓力停下來也無法恢復, 為什么?
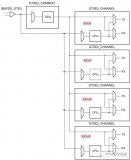
如下圖所示:
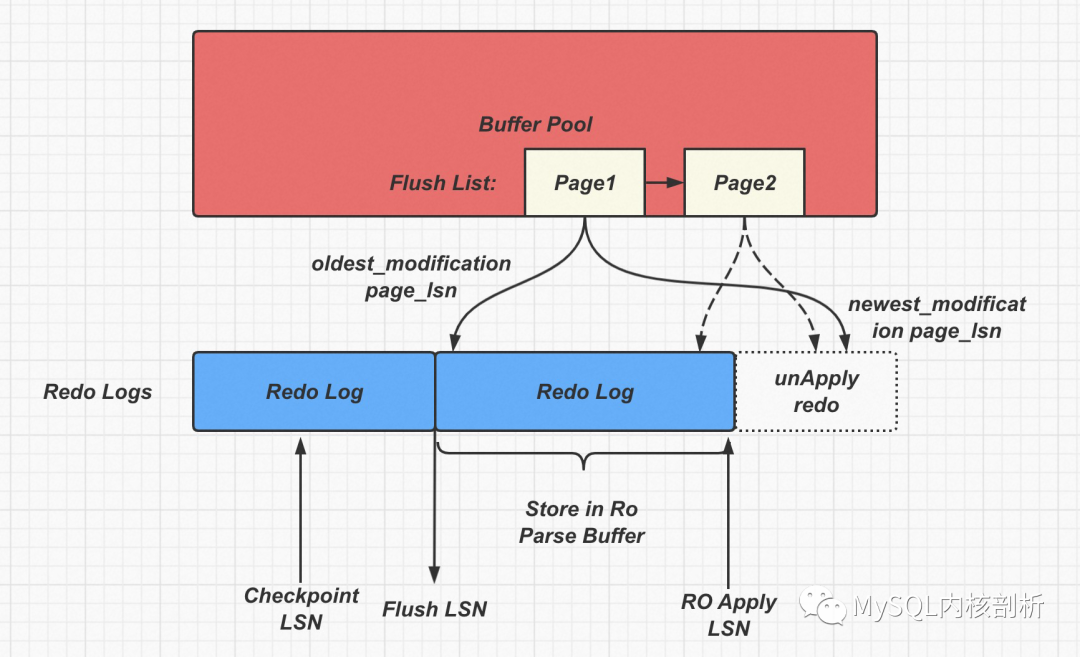
這里最極端的場景是如果rw 上面最老的page1, 也就是在flush list 上根據 oldest_modification_lsn 排在最老的位置page_lsn 已經大于ro 上面的apply_lsn 了, 那么刷臟是無法進行的, 因為物理復制需要保證page 已經被解析到ro parse buffer才可以進行刷臟. 另外想Page2 這樣的Page 雖然newest_modification 和 oldest_modification 沒有差很多也無法進行刷臟了. 因為Parse buffer 已經滿了.
但是這個時候ro 節點的apply_lsn 已經不推進了, 因為上面的parse buffer 已經滿了, parse buffer 推進需要等rw 節點把老的page 刷下去, 老的parse buffer chunk 才可以釋放. 但是由于上面rw 節點已經最老的page 都無法刷臟, 那么parse buffer chunk 肯定就沒機會釋放了.
那么此時就形成了死循環了. 即使寫入壓力停下來, ro 也是無法恢復的.
所以只要rw 上面最老page 超過了 parse buffer 的大小, 也就是最老page newest_modification_page lsn > ro apply_lsn 之時, 那么死鎖就已經形成, 后續都無法避免了
這里copy_page 為何沒有生效?
目前copy_page 的機制是刷臟的時候進行的, 在下圖中copy page copy 出來的page newest_modification 也是大于ro apply_lsn 的, 所以也是無法刷臟的, 所以這個時候其實這個copy_page 機制是無效的機制.
正確的做法是: 在發現Page newest_modification 有可能超過一定的大小, 那么就應該讓該page 進行copy page強行刷臟, 否則到后面在進行刷臟就來不及了.
開啟了多版本LogIndex 版本為什么可以規避這個問題?
在因為parse buffer 滿導致的刷臟約束中, 如上圖所示, Page1, Page2 無法進行刷臟, 但是其他的Page 如果newest_modification < ro apply_lsn 是可以刷臟的, 因此rw 節點buffer pool 里面臟頁其實不多.
開啟了LogIndex 以后, ro 就可以隨意丟棄自己的parse buffer 了, 當然也就不會crash.
但是依然有一個問題是如果Page1 一直修改, 這個Page1 的newest_modification lsn 一直在更新, 那么即使開啟LogIndex 也無法將該Page 刷下去, 帶來的問題是rw checkpoint 是無法推進, 但是由于有了LogIndex, 其他page 可以隨意刷臟, 所以不會出現rw 臟頁數不夠的問題. 那Page1 刷臟如何解決呢?
通過copy page 解決.
如果rw 開啟了copy page 以后, 雖然上圖中的Page1 剛剛被copy 出來的時候無法flush, 但是因為開啟LogIndex, ro apply_lsn 可以隨意推進, 隨著ro apply_lsn 的推進, 過一段時間一定可以刷這個copy page, 也就避免了這個問題了.
所以目前版本答案是 LogIndex + copy page 解決了幾乎所有問題
另外驗證了刷臟約束兩種場景
大量寫入場景
有熱點頁場景
其實大量寫入場景即使導致了刷臟約束, 后面還是可以恢復的, 只有熱點頁場景才無法恢復. 很多時候熱點頁不一定是用戶修改的page, 而是Btree 上面的一些其他page, 比如root page 等等, 我們很難發現的.
另外驗證了如果page 以及 redo log 寫入延遲都升高, 是不會特別出現刷臟約束問題, 只有出現熱點頁的場景才會有問題.
上圖可以看到
ro parse buffer = ro appply_lsn - rw flush_lsn
apply_lsn 是ro 節點讀取redo 并應用推進的速度
flush_lsn 是rw 節點page 刷臟推進的速度
由于IO 延遲同時影響了 redo 和 page, 從公式可以看到, 那么ro parse buffer 不會快速增長的.
從公式里面可以看到, 如果redo 推進速度加快, page 刷臟速度減慢, 那么是最容易出現刷臟約束的. 也就是redo IO 速度不變, Page IO 速度變慢, 就容易出現把RO parse buffer 打滿的情況, 但是一樣需要出現熱點頁才能出現parse buffer 被打滿的死鎖.
如果沒有熱點頁, 這個時候由于parse buffer 還是再推進, 所以不會自動crash, 反而會出現rw 由于被限制了刷臟, buffer pool 里面大量的臟頁, 最后找不到空閑Page 的情況. rw crash 的情況.
多版本或者Aurora 如何解決這個問題?
剛才上面的分析有兩個鏈條互相依賴
約束1: rw 的刷臟依賴ro 節點apply_lsn 的推進
約束2: ro 節點釋放old parse buffer 依賴rw 節點刷臟
多版本/Aurora 都把約束2 給去掉了, ro 節點可以隨意釋放old parse buffer. 那么就不會有parse buffer 滿的問題, 那么如果ro 節點訪問到rw 還未刷下去page, 但是ro 節點已經把Parse buffer 釋放了, 那么會通過磁盤上的 logIndex + 磁盤上page 生成想要的版本.
但是這里依然還要去解決約束1 的問題, rw 的刷臟會被ro 給限制. rw 刷臟時候判斷 page newest_modification_lsn > ro apply_lsn, 那么在Aurora 里面這個Page 也是無法進行Apply 的, 但是Aurora 和我們區別在于Aurora 可以把這個Page 丟出buffer pool, 但是我們是無法把這樣的page 丟出Buffer Pool, 依然會造成Buffer Pool 里面大量的臟頁, 最后找不到空閑Page 的情況. 在多版本引擎里面支持把Page newest_modification_lsn > ro apply_lsn 這樣的Page 在Buffer Pool 中釋放也很重要.
-
節點
+關注
關注
0文章
218瀏覽量
24428 -
PAGE
+關注
關注
0文章
11瀏覽量
20182
原文標題:PolarDB 物理復制刷臟約束問題和解決
文章出處:【微信號:inf_storage,微信公眾號:數據庫和存儲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
物理約束實踐:I/O約束

FPGA物理約束之布局約束

物理約束之布局約束
云棲干貨回顧 | 云原生數據庫POLARDB專場“硬核”解析
【MiniStar FPGA開發板】配套視頻教程——Gowin進行物理和時序約束
Adam Taylor玩轉MicroZed系列74:物理約束
Polardb數據庫模擬控制智能家居測試案例






 工商網監
工商網監
評論