 谷歌重磅新作PaLI-3:視覺語言新模型!更小、更快、更強
谷歌重磅新作PaLI-3:視覺語言新模型!更小、更快、更強
在多模態(視覺語言)大模型領域,拼參數贏性能的同時,追求參數更小、速度更快、性能更強是另一條研究路徑。
在大模型時代,視覺語言模型(VLM)的參數已經擴展到了數百甚至數千億,使得性能持續增加。與此同時,更小規模的模型仍然很重要,它們更易于訓練和服務,更加環境友好,并為模型設計提供更快的研究周期。
在該領域,谷歌研究院在去年推出了一個名為 PaLI(Pathways Language and Image)的模型。作為一個多模態大模型,PaLI 的關鍵結構之一是復用大型單模態基干進行語言和視覺建模,在語言方面復用 13B 參數的 mT5-XXL,在視覺方面復用 2B 參數的 ViT-G 和 4B 參數的 ViT-e。當時 PaLI 實現了優于多數新舊模型的性能。
此后谷歌繼續專注于更小規模的建模,并于近日提出 PaLI-3,這是 PaLI 系列的第三代模型。通過一個僅有 5B 參數的預訓練基線模型,他們優化了訓練方法,并在多個 VLM 基準上實現了有競爭力以及新的 SOTA 結果。
該方法主要由三部分組成,分別是在 web 規模的圖像文本數據上對圖像編碼器的對比預訓練、用于 PaLI 多模態訓練的改進后的混合數據集,以及更高分辨率的訓練。

作者來自谷歌研究院、谷歌DeepMind和谷歌云。
論文地址:https://arxiv.org/abs/2310.09199
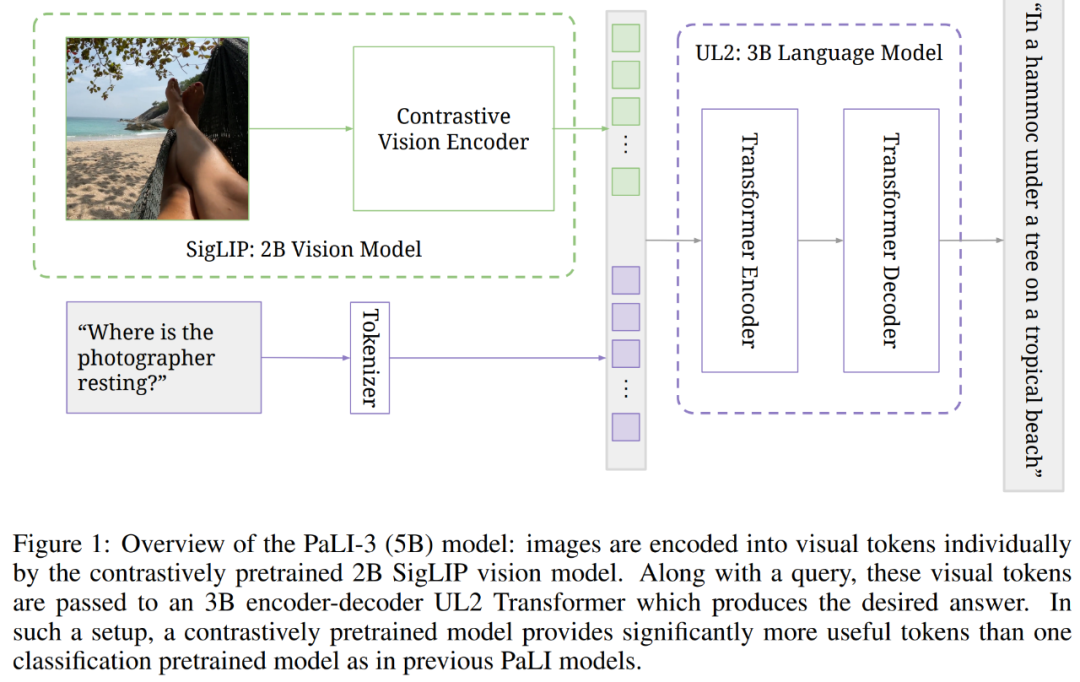
下圖為 5B PaLI-3 模型概覽,其中通過對比預訓練的 2B SigLIP 視覺模型,圖像被單獨地編碼成了視覺 token。接著與 query 一起,這些視覺 token 被傳遞給了 3B 編碼器 - 解碼器結構的 UL2 Transformer,它生成了預期答案。在這樣的設置下,與之前 PaLI 模型中單個分類預訓練的模型,對比預訓練的模型提供了明顯更有用的 token。
效果怎么樣呢?PaLI-3 在需要視覺定位文本理解和目標定位的任務上實現了新的 SOTA,包括 RefCOCO 數據集上的 8 個視覺定位文本理解任務和參考表達分割任務。PaLI-3 也在一系列分類視覺任務上有出色的表現。
此外研究者還專門做了消融實驗以與分類預訓練的 ViT 基線模型比較,并進一步確認了預訓練視覺編碼器在有噪聲 web 規模的圖像文本數據上的可行性,從而成為在分類數據上進行訓練的優先替代方案。
除了 5B PaLI-3 模型之外,研究者還利用最近提出的 SigLIP 方法,構建了一個參數擴展到 2B 的 SOTA 多語言對比視覺模型。
模型介紹
架構
在更高的層面,PaLI-3 的架構遵循了 Chen et al. (2023b;a):ViT 模型將圖像編碼為 token,并與問題、提示和指令等文本輸入一起被傳遞到編碼器 - 解碼器結構的 transformer,從而生成文本輸出。
先看視覺組件。研究者使用 SigLIP 訓練方法,從對比預訓練的 ViT-G/14 模型(參數約為 2B)初始化出 PaLI-3 的視覺基干。簡而言之,他們訓練了圖像嵌入 ViT-G/14 模型和文本嵌入 transformer 模型來分別嵌入圖像和文本,這樣一來,使用圖像和文本嵌入點積的 sigmoid 交叉熵的二元分類器,能夠準確地分類各自的圖像和文本是否相互對應。
這類似于 CLIP 和 ALIGN,但更加高效、可擴展和穩健。同時這種方法是為了預訓練 ViT 圖像嵌入組件,因此當將 ViT 插入到 PaLI 時,文本嵌入 transformer 會被丟棄。
再來看完整的 PaLI 模型。ViT 圖像編碼器的輸出在池化之前形成了視覺 token,并線性地映射和添加到嵌入的輸入文本 token。接著這些 token 被傳遞到了預訓練的 3B UL2 編碼器 - 解碼器模型,從而生成文本輸出。該模型的文本輸入通常包含有描述任務類型的提示,并為該任務編碼必要的文本輸入。
訓練
訓練過程包含多個階段。
階段 0:單峰預訓練。圖像編碼器按照 SigLIP 訓練協議,圖像編碼器的訓練分辨率為 224×224 ;文本編碼器 - 解碼器是一個 3B UL2 模型,按照 Tay 等人描述的混合降噪程序進行訓練。
階段 1:多模態訓練。將圖像編碼器與文本編碼器 - 解碼器相結合,然后,將這個組合得到的 PaLI 模型在多模態任務和數據上進行訓練,此時,圖像編碼器保持凍結,分辨率還是 224×224。通過對文本質量進行啟發式過濾,并使用 SplitCap 訓練目標,再次從 WebLI 數據集派生出主要的混合組件。
階段 2:提升分辨率。高分辨率輸入是一種被廣泛接受的提高性能的方法,這既是因為可以感知圖像中的更多細節,也是因為通過增加序列長度來提高模型能力。本文通過解凍圖像編碼器來提高 PaLI-3 的分辨率,將檢查點保持在 812×812 和 1064×1064 分辨率。
任務遷移。最后,對于每個單獨的任務(基準),本文使用凍結的 ViT 圖像編碼器在任務的訓練數據上微調 PaLI-3 模型;對于大多數任務,本文微調 812×812 分辨率檢查點,但對于兩個文檔理解任務,本文將分辨率提高到 1064×1064。
實驗及結果
實驗首先比較了在 PaLI 框架下不同 ViT 模型的結果對比,研究者考慮了兩種 ViT 模型:Classif 和 SigLIP。
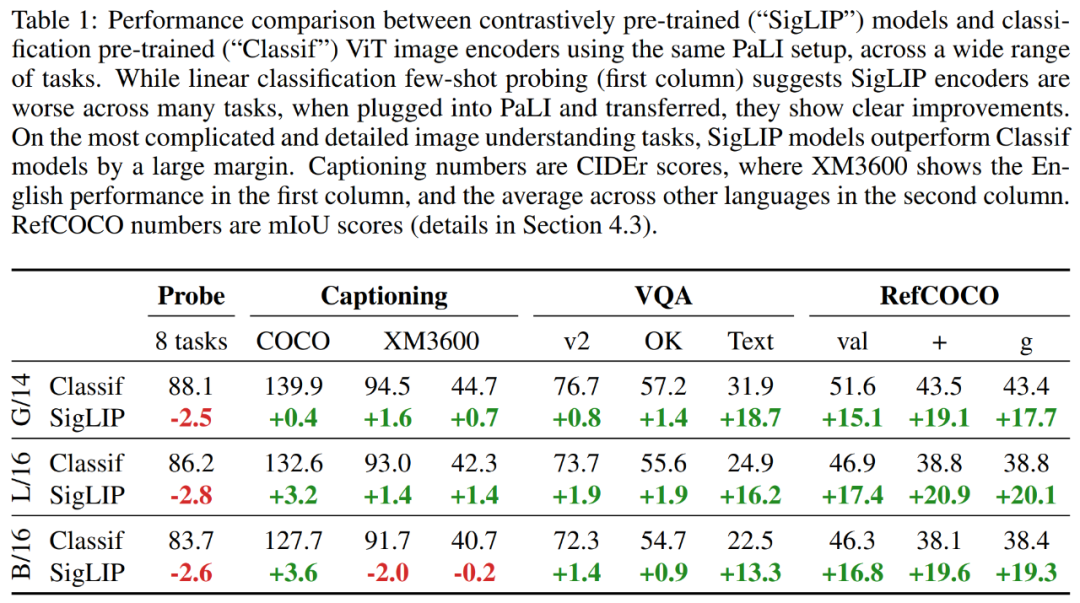
結果如表 1 所示,表明雖然 SigLIP 模型的少樣本線性分類有些落后,但通過使用 PaLI-3,SigLIP 模型在更簡單的任務上(例如字幕和問答)提供了適度的增益,并且在更復雜的場景即文本和空間理解任務上取得了巨大增益。
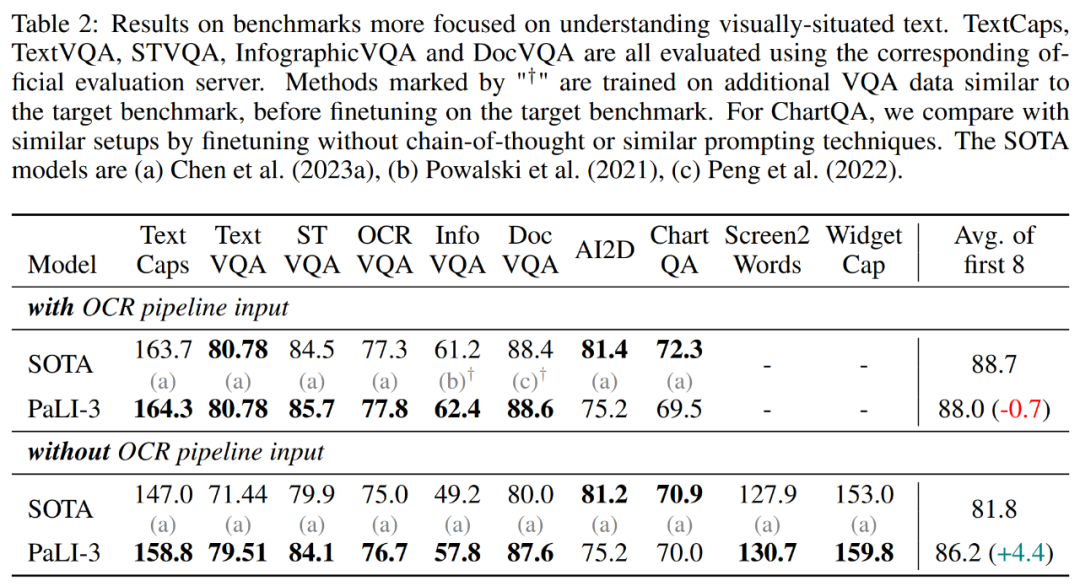
此外,研究者還在 TextCaps、TextVQA、STVQA、OCRVQA、InfographicVQA、DocVQA、ChartQA、Scree2Words、 WidgetCap 數據集上評估了 PaLI-3。結果如表 2 所示,在使用外部 OCR 系統的情況下,PaLI-3 僅比 SOTA 方法低 0.7 分。然而,在沒有這種外部系統的情況下,PaLI-3 比所有 SOTA 方法的組合高出 4.4 分。對于 TextCaps、TextVQA、InfographicVQA 和 DocVQA,PaLI-3 的優勢超多 8 分甚至更多。
參考表達分割
研究者擴展了 PaLI-3,使其能夠通過類語言輸出來預測分割掩碼。為此,他們利用了 Ning et al. (2023) 的向量量化變分自編碼器(VQ-VAE)。VQ-VAE 經過訓練可以學習 128 個掩碼 token,其編碼器可以將 64 × 64 像素的分割掩碼標記為 16 個掩碼 token,解碼器可以轉換回來。
研究者訓練 PaLI-3 來預測單個分割掩碼,首先輸出 4 個坐標作為文本,并表示為邊界框。接著是 16 個掩碼 token,表示邊界框內的掩碼。
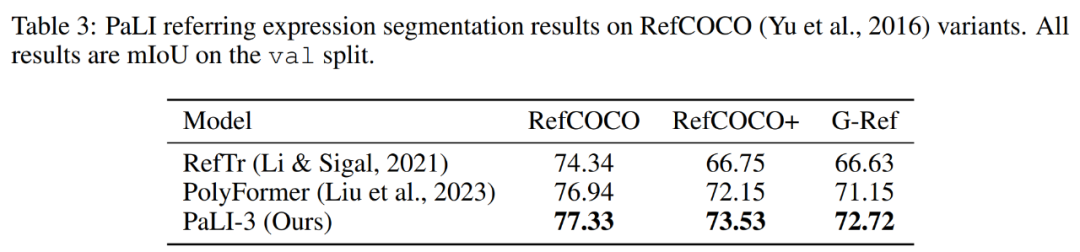
表 1 表明對于此類定位任務,對比預訓練比分類預訓練更有效。下表 3 顯示,完整的 PaLI-3 模型在參考表達分割方面略微優于現有技術。
圖像理解
接下來研究者在一般視覺語言理解任務上評估了 PaLI-3。與之前的工作一樣,他們沒有使用外部 OCR 模塊,因為這些基準測試很少涉及圖像中的文本。
結果表明,與最近的 SOTA 模型相比,PaLI-3 的尺寸要小得多,但它在這些基準測試中表現出了非常強大的性能。對于 COCO,PaLI-3 優于除 BEiT-3 以及 17B 和 55B PaLI 之外的所有模型。在 VQAv2 和 TallyQA 上,PaLI-3 超過了除 PaLI-X 之外的所有先前模型。對于 OKVQA 任務,PaLI-3 僅落后于 PaLM-E (562B) 和 PaLI-X (55B),但仍然優于 32-shot Flamingo (80B) 模型。

視頻字幕和問答
該研究在 4 個視頻字幕基準上對 PaLI-3 模型進行了微調和評估:MSR-VTT、VATEX、ActivityNet Captions 和 Spoken Moments in Time。此外,該研究在 3 個視頻問答基準上進行了同樣的操作:NExT-QA、MSR-VTT-QA 和 ActivityNet-QA。
盡管沒有使用視頻數據進行預訓練,PaLI-3 仍以較小的模型尺寸實現了出色的視頻 QA 結果:在 MSR-VTT-QA 和 ActivityNet-QA 上實現了最先進的性能,并在 NextQA 上取得了具有競爭力的結果。在圖像和視頻 QA 上的持續改進凸顯了采用對比 ViT 的好處。
此外,PaLI-3 還取得了非常好的視頻字幕結果,平均僅比 SOTA 結果低 3 個 CIDEr 點。考慮到模型尺寸,PaLI-3 在性能和實用性方面似乎都是一個絕佳的選擇。
直接圖像編碼器評估
研究者還評估了 ViT-G 模型,ViT-G 可以理解為不是完整的 PaLI-3,結果如表 6 所示。
首先,該研究使用標準的 ImageNet 基準測試及其兩個最流行的變體來測試圖像分類功能。結果表明,SigLIP 在 top-1 和 v2 準確率方面略有落后,但在 ReaL 方面結果相當。
其次,該研究報告了不同模型在 Crossmodal-3600 基準上的結果。結果表明 SigLIP ViT-G 模型明顯優于較大的 ViT-e 模型。
最后,該研究還報告了線性 probing 結果,結果表明 SigLIP 不及其他模型。
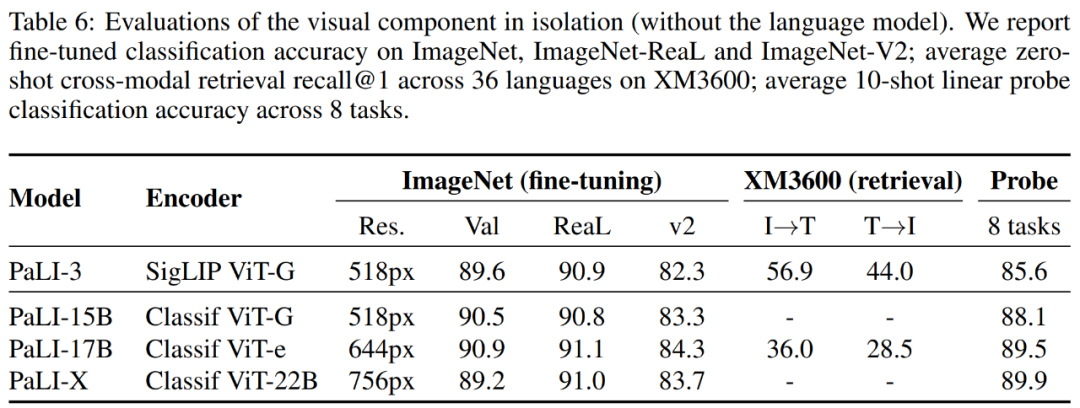
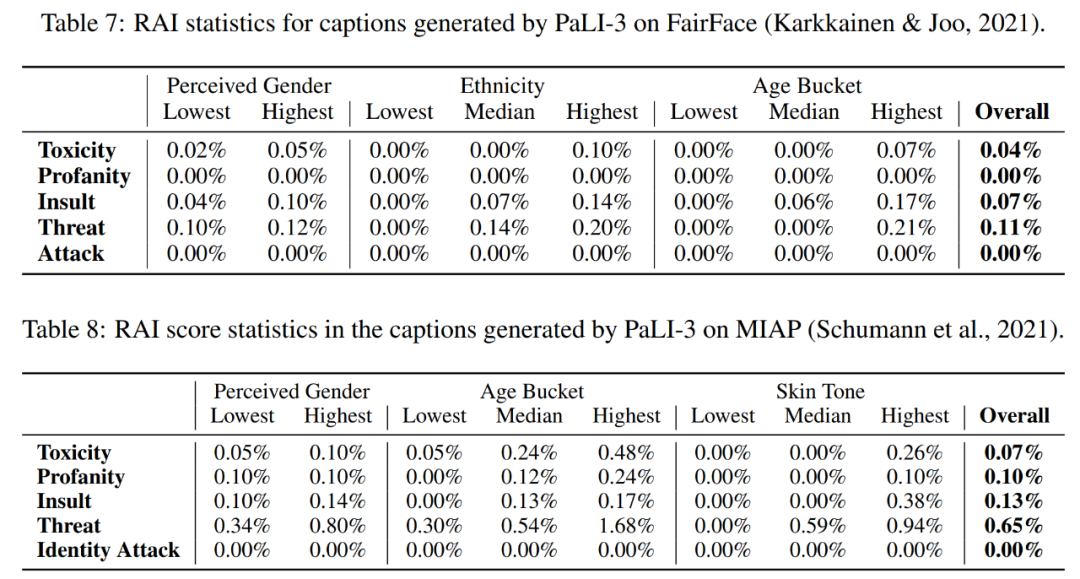
表 7 和表 8 評估了模型的公平性、偏差和其他潛在問題。
-
編碼器
+關注
關注
45文章
3643瀏覽量
134525 -
語言模型
+關注
關注
0文章
524瀏覽量
10277 -
大模型
+關注
關注
2文章
2451瀏覽量
2714
原文標題:谷歌重磅新作PaLI-3:視覺語言新模型!更小、更快、更強
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的基礎技術

微型光纜的發展趨勢:更小、更快、更強韌

谷歌提出MorphNet:網絡規模更小、速度更快!

谷歌推出1.6萬億參數的人工智能語言模型,打破GPT-3記錄
谷歌開發出超過一萬億參數的語言模型,秒殺GPT-3

谷歌多模態大模型PaLI研究神經網絡
谷歌提出PaLI:一種多模態大模型,刷新多個任務SOTA!
【機器視覺】歡創播報 | 谷歌發布人工智能語言模型PaLM 2
機器人基于開源的多模態語言視覺大模型






 工商網監
工商網監
評論