 揭秘編碼器與解碼器語言模型
揭秘編碼器與解碼器語言模型
來源 | OSCHINA 社區
作者 | OneFlow深度學習框架
Transformer 架構的問世標志著現代語言大模型時代的開啟。自 2018 年以來,各類語言大模型層出不窮。
通過 LLM 進化樹(github.com/Mooler0410/LLMsPracticalGuide)來看,這些語言模型主要分為三類:一是 “僅編碼器”,該類語言模型擅長文本理解,因為它們允許信息在文本的兩個方向上流動;二是 “僅解碼器”,該類語言模型擅長文本生成,因為信息只能從文本的左側向右側流動,并以自回歸方式有效生成新詞匯;三 “編碼器 - 解碼器” 組,該類語言模型對上述兩種模型進行了結合,用于完成需要理解輸入并生成輸出的任務,例如翻譯。
本文作者 Sebastian Raschka 對這三類語言模型的工作原理進行了詳細解讀。他是人工智能平臺 Lightning AI 的 LLM 研究員,也是《Machine Learning Q and AI》的作者。
有人希望我能深入介紹一下語言大模型(LLM)的相關術語,并解釋我們現在認為理所當然的一些技術性更強的術語,包括 “編碼器式” 和 “解碼器式” LLM 等。這些術語是什么意思?
編碼器和解碼器架構基本上都使用了相同的自注意力層對單詞詞元(token)進行編碼,然而,不同的是:編碼器被設計為學習可以用于各種預測建模任務(如分類)的嵌入;解碼器被設計用于生成新的文本,例如回答用戶的查詢等。
1原始 Transformer
原始 Transformer 架構("Attention Is All You Need",2017 年)是為英法和英德語言翻譯而開發的,它同時使用了編碼器和解碼器,如下圖所示。
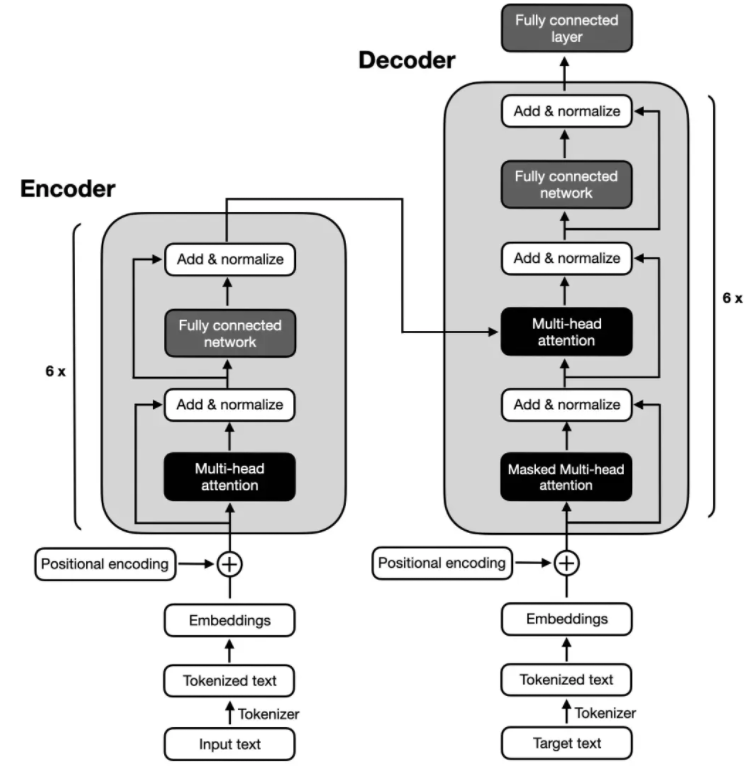
上圖中,輸入文本(即要翻譯的句子)首先被分詞為單獨的單詞詞元,然后通過嵌入層對這些詞元進行編碼,完成后進入編碼器部分。接下來,在每個嵌入的單詞上添加位置編碼向量,之后,這些嵌入會通過多頭自注意力層。多頭注意力層之后會進行殘差與層歸一化(Add & normalize),它進行了一層標準化操作,并通過跳躍連接(skip connection,也稱為殘差連接或快捷連接)添加原始嵌入。最后,進入 “全連接層”(它是由兩個全連接層(全連接層之間有一個非線性激活函數)組成的小型多層感知器)之后,輸出會被再次 " 殘差與層歸一化 ",然后再將輸出傳遞到解碼器模塊的多頭自注意力層。
上圖的解碼器部分與編碼器部分的整體結構十分相似,關鍵區別是它們的輸入和輸出內容。編碼器要接收進行翻譯的輸入文本,而解碼器則負責生成翻譯后的文本。
2編碼器
上圖展示的原始 Transformer 架構中的編碼器部分負責理解和提取輸入文本中的相關信息,它輸出的是輸入文本的一個連續表示(嵌入),然后將其傳遞給解碼器。最終,解碼器根據從編碼器接收到的連續表示生成翻譯后的文本(目標語言)。
多年來,基于原始 Transformer 模型中的編碼器模塊開發了多種僅編碼器架構。其中兩個最具代表性的例子是 BERT( 用于語言理解的深度雙向 Transformer 預訓練 2018)和 RoBERTa(魯棒優化的 BERT 預訓練方法,2018)。
BERT(Bidirectional Encoder Representations from Transformers)是一種基于 Transformer 編碼器模塊的僅編碼器架構,它使用掩碼語言建模(如下圖所示)和下一個句子預測任務,在大型文本語料庫上進行預訓練。

BERT 式 Transformer 中使用的掩碼語言建模預訓練目標圖示。
掩碼語言建模的主要思路是在輸入序列中隨機掩碼(或替換)一些單詞詞元,并訓練模型根據上下文來預測原始的掩碼詞元。
除上圖所示的掩碼語言建模預訓練任務之外,下一個句子預測任務要求模型去預測兩個隨機排列的句子在原始文檔中的語句順序是否正確。例如,兩個用 [SEP] 標記分隔開的隨機句子:
[CLS] Toast is a simple yet delicious food [SEP] It’s often served with butter, jam, or honey.
[CLS] It’s often served with butter, jam, or honey. [SEP] Toast is a simple yet delicious food.
其中,[CLS] 詞元是模型的占位符,提示模型返回一個 True 或 False 標簽,用來表示句子順序是否正確。
掩碼語言和下一個句子預訓練目標使得 BERT 可以大量學習輸入文本的上下文表示,然后可以針對各種下游任務(如情感分析、問答和命名實體識別)對這些表示進行微調。
RoBERTa(Robustly optimized BERT approach)是 BERT 的優化版本。它與 BERT 保持了相同的整體架構,但進行了一些訓練和優化改進,例如更大的 batch 尺寸,更多的訓練數據,并去除了下一個句子預測任務。這些改進使得 RoBERTa 擁有更好的性能,相比 BERT,RoBERTa 能更好地處理各種自然語言理解任務。
3解碼器
回到本節開頭的原始 Transformer 架構,解碼器中的多頭自注意機制與編碼器中的類似,但經過掩碼處理,以防模型關注到未來位置,確保對位置 i 的預測僅基于已知的小于 i 的輸出位置。下圖為解碼器逐詞生成輸出的過程。
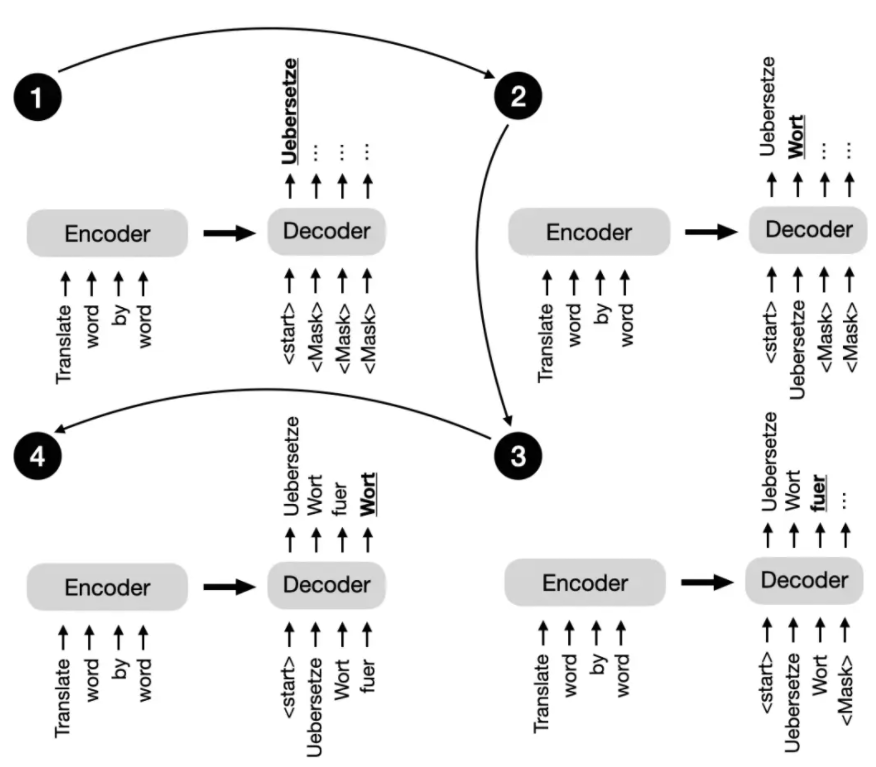
原始 Transformer 中的下一個句子預測任務示意圖。
這種掩碼操作(在上圖中可明確看到,但實際上在解碼器的多頭自注意機制內部發生)對于在訓練和推理過程中保持 Transformer 模型的自回歸特性至關重要。自回歸特性能確保模型逐個生成輸出詞元,并使用先前生成的詞元作為上下文,以生成下一個詞元。
多年來,研究人員在原始編碼器 - 解碼器 Transformer 架構的基礎上進行擴展,開發出了幾種僅解碼器模型,這些模型能高效處理各種自然語言任務,其中最著名的是 GPT(Generative Pre-trained Transformer)系列模型。
GPT 系列模型為僅解碼器模型,它們在大規模無監督文本數據上進行預訓練,然后針對特定任務進行微調,如文本分類、情感分析、問答和摘要生成等。GPT 模型包括 GPT-2、GPT-3(GPT-3 于 2020 年發布,具備少樣本學習能力)以及最新的 GPT-4,這些模型在各種基準測試中展現出了卓越性能,是目前最受歡迎的自然語言處理架構。
GPT 模型最引人注目的特性之一是涌現特性。涌現特性指的是模型在下一個詞預測的預訓練中發展出來的能力和技能。盡管這些模型只是被訓練預測下一個詞,但預訓練后的模型卻能夠執行各種任務,如文本摘要生成、翻譯、問答和分類等。此外,這些模型可通過上下文學習來完成新任務,而無需更新模型參數。
4編碼器 - 解碼器混合模型
BART (Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension, 2019)
and T5 (Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, 2019).
除傳統的編碼器和解碼器架構之外,新型編碼器 - 解碼器模型的發展取得了重大突破,充分發揮了編碼器和解碼器模型的優勢。這些模型融合了新穎技術、預訓練目標或架構修改,以提高在各種自然語言處理任務中的性能表現。下面是一些值得關注的新型編碼器 - 解碼器模型:
BART(用于自然語言生成、翻譯和理解的去噪序列到序列預訓練模型,2019 年發布)
T5(通過統一的文本到文本 Transformer 來探索遷移學習的極限,2019 年發布)。
編碼器 - 解碼器模型通常用于自然語言處理,這些任務涉及理解輸入序列并生成相應的輸出序列。這些序列往往具有不同的長度和結構。這種模型在需要復雜映射以及捕捉輸入序列和輸出序列之間的元素關系的任務中表現出色。編碼器 - 解碼器模型常用于文本翻譯和摘要生成等任務。
5術語和行話
這些模型(包括僅編碼器、僅解碼器和編碼器 - 解碼器模型)都屬于序列到序列模型(通常簡稱為 “seq2seq”)。值得注意的是,雖然我們將 BERT 模型稱為僅編碼器模型,但 “僅編碼器” 這個描述可能會引起誤解,因為這些模型在預訓練期間也會將嵌入解碼為輸出的詞元或文本。
換句話說,僅編碼器和僅解碼器架構都在進行 “解碼”。然而,與僅解碼器和編碼器 - 解碼器架構不同,僅編碼器架構不是以自回歸的方式進行解碼。自回歸解碼是指逐個詞元地生成輸出序列,其中每個詞元都基于先前生成的詞元。相比之下,僅編碼器模型不會以這種方式生成連貫的輸出序列。相反,它們專注于理解輸入文本并生成特定任務的輸出,如標簽預測或詞元預測。
6結論
簡而言之,編碼器模型在學習用于分類任務的嵌入表示方面非常受歡迎,編碼器 - 解碼器模型用于生成任務,這些任務依賴輸入,以生成輸出(例如翻譯和摘要生成),而僅解碼器模型則用于其他類型的生成任務,包括問答。
自首個 Transformer 架構問世以來,已經開發出數百種編碼器、解碼器和編碼器 - 解碼器混合模型,模型概覽如下圖所示:
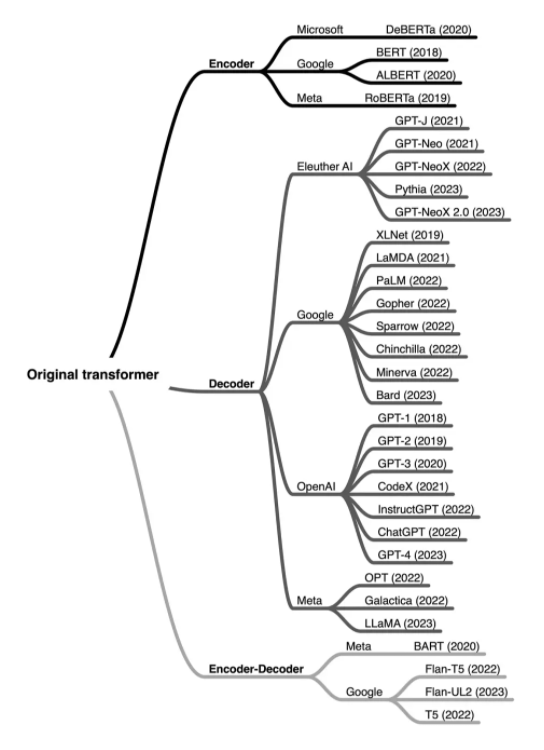
按架構類型和開發者分類的部分最受歡迎的大型語言 Transformer。
盡管僅編碼器模型逐漸失去了關注度,但 GPT-3、ChatGPT 和 GPT-4 等僅解碼器模型在文本生成方面取得了重大突破,并開始廣泛流行。然而,僅編碼器模型在基于文本嵌入進行預測模型訓練方面仍然非常有用,相較于生成文本,它具備獨特優勢。
審核編輯:湯梓紅
-
解碼器
+關注
關注
9文章
1143瀏覽量
40742 -
編碼器
+關注
關注
45文章
3643瀏覽量
134525 -
語言模型
+關注
關注
0文章
524瀏覽量
10277 -
LLM
+關注
關注
0文章
288瀏覽量
338
原文標題:揭秘編碼器與解碼器語言模型
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
怎么理解真正的編碼器和解碼器?
編碼器和解碼器的區別是什么,編碼器用軟件還是硬件好
基于結構感知的雙編碼器解碼器模型
詳解編碼器和解碼器電路:定義/工作原理/應用/真值表

PyTorch教程-10.6. 編碼器-解碼器架構

基于transformer的編碼器-解碼器模型的工作原理
基于 RNN 的解碼器架構如何建模
基于 Transformers 的編碼器-解碼器模型
神經編碼器-解碼器模型的歷史
詳解編碼器和解碼器電路
視頻編碼器與解碼器的應用方案





 工商網監
工商網監
評論