 借助亞馬遜云科技大語言模型等多種服務打造下一代企業知識庫
借助亞馬遜云科技大語言模型等多種服務打造下一代企業知識庫
背景
知識庫需求在各行各業中普遍存在,例如制造業中歷史故障知識庫、游戲社區平臺的內容知識庫、電商的商品推薦知識庫和醫療健康領域的掛號推薦知識庫系統等。為保證推薦系統的實效性和準確性,需要大量的數據/算法/軟件工程師的人力投入和包括硬件在內的物力投入。其次,為了進一步提高搜索準確率,如何引導用戶搜索描述更加準確和充分利用用戶行為優化搜索引擎也是常見的用戶痛點。此外,如何根據企業知識庫直接給出用戶提問的答案也是眾多企業中會遇見的技術瓶頸。
本文旨在介紹一些企業知識庫的典型實用場景,以及如何使用智能搜索,結合大語言模型,針對企業知識庫提供基于搜索的精準問答。
各行各業中有很多場景需要基于企業知識庫進行搜索和問答
1.構建裝備維護知識庫和問答系統:使用歷史維保記錄和維修手冊構建企業知識庫,維修人員可依靠該知識庫,快速地進行問題定位和維修。
2.構建IT/HR系統智能問答系統:使用企業內部IT/HR使用手冊構建企業知識庫,企業內部員工可通過該知識庫快速解決在IT/HR上遇到的問題。
3.構建電商平臺的搜索和問答系統:使用商品信息構建商品數據庫,消費者可通過檢索+問答的方式快速了解商品的詳細信息。
4.構建游戲社區自動問答系統:使用游戲的信息(例如游戲介紹,游戲攻略等)構建社區知識庫,可根據該知識庫自動回復社區成員提供的問題。
5.構建智能客戶聊天機器人系統:通過與呼叫中心/聊天機器人服務結合,可自動基于企業知識庫就客戶提出的問題進行聊天回復。
6.構建智能教育輔導系統:使用教材和題庫構建不同教育階段的知識庫,模擬和輔助老師/家長對孩子進行教學。
為解決上述場景需求,可通過結合搜索和大語言模型的方式來實現。首先,可以利用企業自身積累的數據資產建立一個知識庫。其次,對于特定的問答任務,可以使用搜索功能對知識庫進行有效的召回,然后將召回的知識進行利用,增強大語言模型。通過這一方法,可以實現對問答任務的解決。
在企業知識庫建立和搜索服務方面,亞馬遜云科技擁有云端托管式搜索服務Amazon OpenSearch和基于AI/ML的智能企業搜索服務Amazon Kendra。雖然上述服務能夠提供基本的搜索引擎和框架,解決了用戶在硬件投入大和管理難的痛點,然而上述服務并且不能夠滿足基于文檔的進行問答需求。為了解決用戶需求和亞馬遜云科技服務之間的差距,借助亞馬遜云科技的服務,構建了基于智能搜索的大語言模型增強方案。該方案以Amazon OpenSearch/Amazon Kendra為基礎構建搜索引擎,結合托管到Amazon SageMaker上的大語言模型,提供一站式的智能知識庫搜索問答平臺。
基于智能搜索的大語言模型增強方案介紹
架構圖
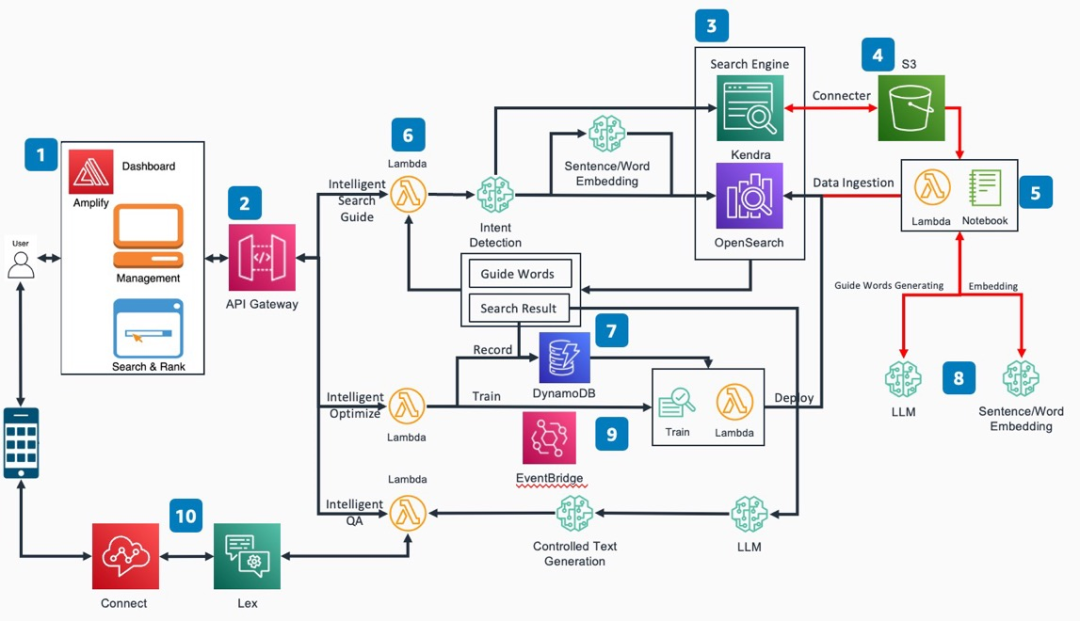
該平臺將包括五大核心內容
1. 智能搜索
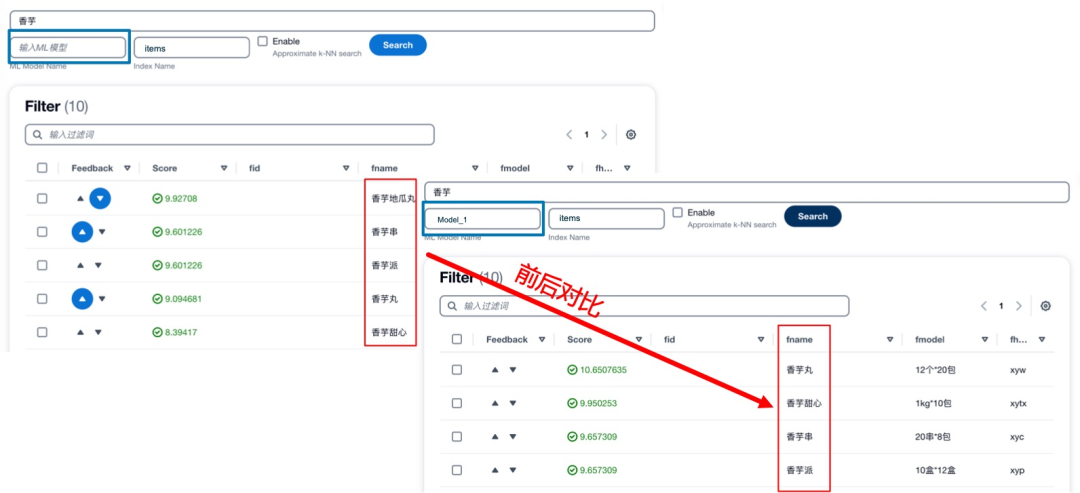
傳統僅依靠關鍵詞匹配的分詞搜索的方式在很多場景下可以提供快速有效的查詢,但是也存在一些固有的局限性。例如匹配一些包括停用詞在內的無關詞匯,無法識別同義詞和缺乏抽象能力。為了解決這些問題,本方案中一方面使用意圖識別模型,對關鍵信息進行提取,從而可以有效的避免停用詞等無法詞匯對搜索造成的干擾。另一方面,引入AI/ML的方法來輔助實現語意搜索。具體來講,使用同一個向量編碼的模型對搜索語句和文檔數據庫進行語意編碼,在檢索的過程中,使用knn方法進行向量匹配。以下是一個傳統分詞搜索與語意向量搜索的對比展示。可以看到,使用向量搜索功能后,可以召回更多自然語意上相近而關鍵詞無關的內容,增加召回范圍和提升搜索準確性。
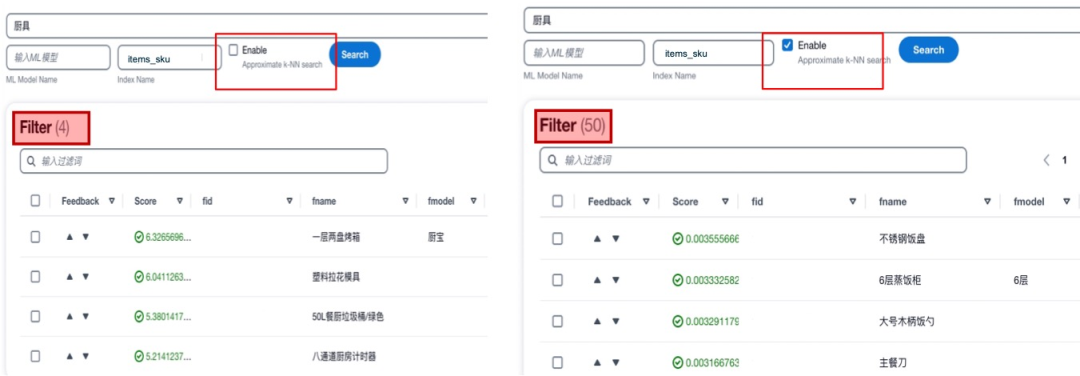
在本方案中,以Amazon OpenSearch和Amazon Kendra為基礎構建搜索引擎。提供分詞搜索,模糊查詢和AI/ML輔助搜索功能。不在局限于某一種搜索方式,而是將所有搜索方法取長補短,進行有機的整合。
智能引導
造成搜索不準確的原因,一方面是由于搜索引擎本身的能力不足,另外一方面的原因是因為搜索的語句不夠準確和具體。因此,本方案中提出了一種引導式的搜索機制來幫助檢索人員逐步豐富輸入的搜索語句,最終達到提升搜索準確性的目的。
以下面制造業大型設備維保知識庫的搜索流程為例。該知識庫存儲歷史維修記錄,包括故障現象,故障原因,維修方案等字段。
當用戶輸入檢索詞“電路”后,除了從知識庫中返回與電路相關的條目之外,還會給予一些提示詞,例如“門系統”、“控制系統”等,這些詞代表與“電路”相關的故障往往伴隨可能出現問題的系統,提示用戶進一步豐富當前的搜索描述。
當用戶進一步輸入“主板”后,會將“電路”和“主板”進行聯合查詢,返回相關的條目,并進一步給出新的提示詞。
用戶可以重復以上過程,直到搜索出來更為精準的結果。

提示詞的獲取:根據實際情況,可以采用人工打標、無監督聚類、有監督分類、大語言模型(LLM)等方法進行提取,并提前注入到數據庫中。
智能優化
通常情況下,由于知識庫的迭代更新,檢索的準確率可能會隨時時間的推薦逐步降低,一方面是因為我們往往不能保證,數據庫和搜索引擎一次性構建完成后就達到很好的效果。另外一方面是因為對于過時的知識沒有進行有效的處理。因此,本方案提出以用戶行為對搜索引擎進行持續優化。
具體來講包括兩個步驟:
用戶行為收集:將歷史用戶的行為進行收集,例如用戶對某個搜索詞條的打分。
模型訓練和部署:通過用戶行為,整理得到搜索詞條和知識庫之間的相關度。使用該相關度訓練和部署一個重排模型,該重排模型可以根據歷史的用戶行為,給予用戶更加偏好的內容更高的權重得分。
值得注意的是,該模型是基于傳統機器學習模型xgboost的,所以所需要的訓練數據量和推理所需要的資源都是很小的(例如只需要幾十條數據和t3.small機型),因此可以基于不同的用戶/用戶群訓練不同的重排模型,達到千人千面,個性化搜索的目的。
4.智能問答
基于私有知識庫進行問答是另外一個廣泛應用的場景,例如智能客戶聊天機器人系統,IT/HR系統智能問答系統等。
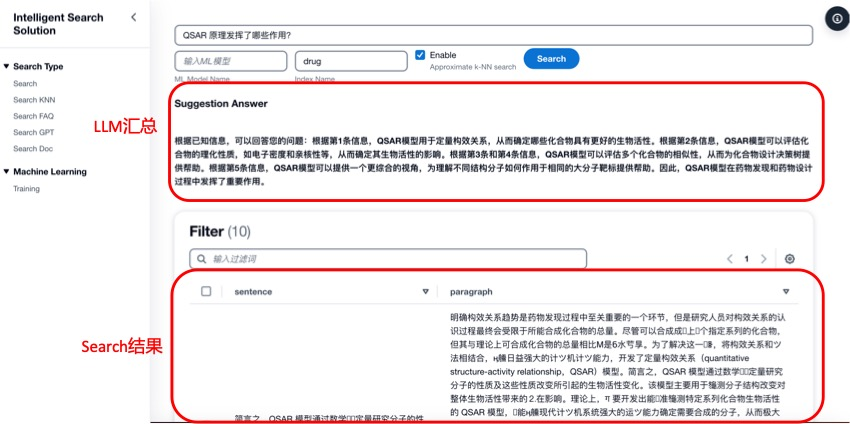
如果僅使用搜索引擎,只能基于問題從數據庫中提取與該問題相關的內容,而不能直接給出答案。
如果僅使用大語言模型(Large Language Model,LLM),不能基于私有知識庫進行問答。一種可行的方式是將私有知識庫和問題直接以prompt的形式直接一次性給到LLM,然后讓LLM給出回答。但是受限于LLM Token的限制,無法一次性輸入過多的知識庫。
因此,在本方案中,將兩者結合。如下圖所示,當用戶提出一個問題后,首先使用搜索提取與問題相關的知識,然后再將問題和提取的知識給到LLM進行總結,最后直接給出問題答案。
5. 非結構化數據注入
可供搜索引擎進行檢索的企業知識庫是一種結構化的數據,但往往企業的原始知識都是以非結構化的數據進行存儲的,來自多個渠道,也包含了多種格式,例如Words,PDF,Excel等。
為了能夠幫助企業快速將這些結構化數據利用起來,本方案提供了非結構化數據注入功能,該功能將企業的知識文檔進行自動段落拆分和向量編碼,建立結構化企業知識庫。
模型技術細節
LLM
最近半年,大語言模型(LLM)在自然語言處理領域取得了飛速的發展。大語言模型通常基于Transformer架構,在大規模的網絡文本數據上進行訓練,其核心是使用一個自我監督的目標來預測部分句子中的下一個單詞。亞馬遜云科技已推出大語言模型Titan和大語言模型平臺Amazon Bedrock,另外還有許多研究機構推出開源大語言模型,如斯坦福大學的Alpaca和清華大學的ChatGLM等。這些大語言模型都具備強大的文本處理能力,廣泛應用在智能問答、文本總結、文本生成等場景。
Embedding
各類非結構化數據廣泛存在于我們的生活和工作場景,如文本、圖片、視頻等,為了處理這些非結構化數據,亞馬遜云科技通常使用Embedding模型提取這些數據的特征,并把數據特征轉化成向量,通過特征向量對這些非結構化數據進行分析和檢索。通用的預訓練語言模型都有把文本進行向量化的功能,可以根據不同的場景和語種,選用合適的預訓練模型作為Embedding模型。
Intent Detection
搜索意圖識別主要功能是分析用戶的核心搜索需求,例如在電商場景,用戶找的電子產品,是電腦類的,還是手機類的,是家庭場景用的,還是戶外場景用的等等,如果意圖識別不準,會有很多不相關的商品展現給用戶,導致產生非常差的用戶體驗,因此精準的意圖識別非常重要。意圖識別主要包括類目預測和實體識別模型,類目預測模型主要采用文本多分類模型,根據平臺的用戶行為數據,將查詢文本預測屬于各個類目的概率。實體識別模型將查詢文本中的實體詞識別出來,實體詞是描述商品的維度信息,如品牌、顏色、材質等,通過實體識別模型識別出查詢文本的實體詞后,再到搜索引擎進行精準查詢。
可控文本生成是在傳統文本生成的基礎上,增加對生成文本的控制,如指定生成文本的關鍵詞、格式、風格等,從而使生成的文本符合我們的預期,比如生成與某人相同風格的文本,生成有固定內容格式的報告,根據簡單的故事線生成完整的小說等等。可控文本生成有對預訓練模型finetune、重新訓練文本生成模型和重構預訓練模型輸出結果等方式。在大語言模型推出后,目前可以方便的通過Prompt提示詞,指導大語言模型進行可控文本生成,針對不同的場景和文本生成目標,設計不同格式和內容的提示詞,生成滿足需求的文本。
審核編輯 黃宇
-
機器人
+關注
關注
211文章
28566瀏覽量
207713 -
AI
+關注
關注
87文章
31294瀏覽量
269647 -
數據庫
+關注
關注
7文章
3841瀏覽量
64545 -
語言模型
+關注
關注
0文章
533瀏覽量
10300 -
亞馬遜
+關注
關注
8文章
2673瀏覽量
83460
發布評論請先 登錄
相關推薦
華為云 Flexus 云服務器 X 實例部署 Trilium Notes 知識庫工具
騰訊ima升級知識庫功能,上線小程序實現共享與便捷問答
Grab選定亞馬遜云科技為首選云服務商
從零開始訓練一個大語言模型需要投資多少錢?

亞馬遜云科技上線Meta Llama 3.2模型
【實操文檔】在智能硬件的大模型語音交互流程中接入RAG知識庫
言犀智能體平臺上線了!趕緊來試試!連接大模型與企業應用的“最后一公里”
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
北京靈奧科技基于亞馬遜云科技打造大模型中間件
如何手擼一個自有知識庫的RAG系統
亞馬遜云科技宣布多項舉措賦能企業數字化轉型與AI創新

【大語言模型:原理與工程實踐】大語言模型的應用
英特爾集成顯卡+ChatGLM3大語言模型的企業本地AI知識庫部署





 工商網監
工商網監
評論