 全球首款支持 8K(8192)輸入長度的開源向量模型發布
全球首款支持 8K(8192)輸入長度的開源向量模型發布
作為多模態人工智能技術領域的翹楚,Jina AI 的愿景是鋪平通往多模態 AI 的未來之路。今天,Jina AI 在向著該愿景前進的路上,達成了一個重要里程碑。我們正式發布了自主研發的第二代文本向量模型:jina-embeddings-v2,是全球唯一能支持 8K(8192)輸入長度的開源向量模型。
據 MTEB 排行榜顯示,jina-embeddings-v2 與 OpenAI 的專有模型 text-embedding-ada-002 在性能方面不相上下。目前,僅 OpenAI 與 Jina AI 兩家人工智能技術公司推出了 8k 長度的 Embedding 模型。
自該模型發布,迅速登上 HackerNews 榜首,并長時間霸榜,在全球范圍內引發了業內人士的廣泛討論。
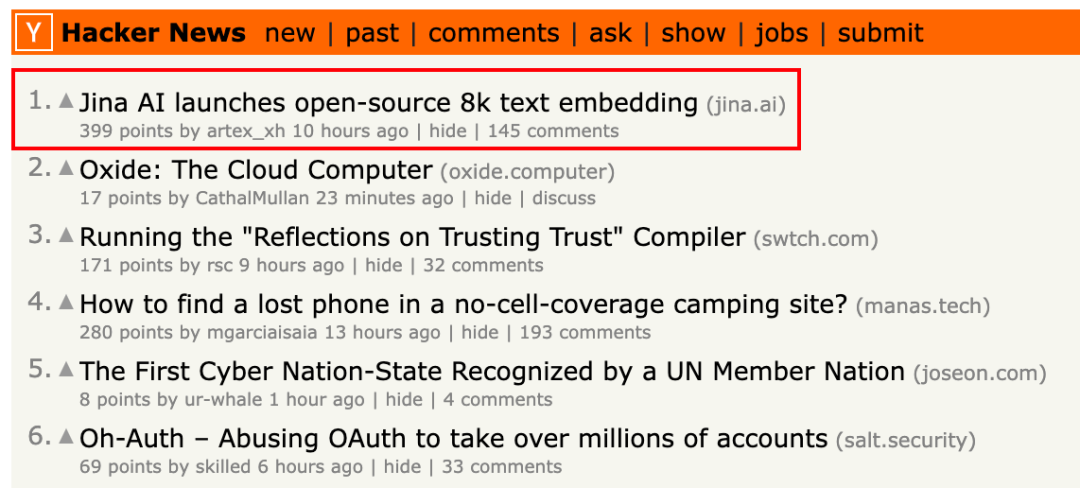
其中,“8K 長度”和“開源”這兩點特別受到業界的矚目,正如 HackerNews 上讀者的評論所言,支持 8k 輸入長度的 jina-embeddings-v2在表達能力和計算效率之間取得了可喜的平衡,而其中的關鍵,就在于它的獨特優勢 —— 用更小的維度來實現高效的表征。

雖然 text-embedding-ada-002 已經廣泛應用于各種不同場景,但其 1536 維度的輸出對于數據量巨大和價格敏感的開發者來說并不友好。jina-embeddings-v2 通過提供 768(base)和 512(small)兩種輸出維度的選擇,賦予了開發者更大的靈活性。這更意味著開發者可以實現更低的計算和存儲成本,適用于更多的實際落地的場景。

在 Jina AI,我們堅信開源技術之于創新、合作與社區力量的催化作用,所以 我們第一時間將模型開源,期待和社區一起共同打造開源 AI 生態。
向量模型與 8k 輸入長度
在傳統的自然語言處理任務中,通常會將文本轉化為一組數字進行表示,也就是向量。向量模型用于生成向量表示,被廣泛應用于檢索、分類、聚類或語義匹配等任務。
在大模型時代,向量模型的重要性進一步增強。尤其是在檢索增強生成(RAG)場景中,它成為了一個核心組件,用于解決大模型的上下文長度限制、幻覺問題和知識注入問題。因為大模型通常有上下文長度的限制,我們需要一個有效的方法來壓縮、存儲和查詢大量的信息。這就是向量模型的用武之地。在 RAG 系統中,文檔首先被轉化為向量。隨后,大模型可以快速地查詢這些向量,找到與當前上下文相關的文檔,再基于這些文檔生成回復。
然而,目前的大部分開源向量模型都是僅支持最大 512 長度(大約 500 個漢字)的輸入長度,這使得開發者無法表征長文本的語義。jina-embeddings-v2 支持最大 8k 長度的輸入,突破了長文本向量表示的瓶頸,讓開發者可以更自由的對文本信息進行不同語義顆粒度的完整表示,從而更精準的表示文本語義。這不僅可以幫助開發者提高 RAG 場景下大模型回復的準確性,而且適用于各種處理長文本的場景,例如處理數十頁的報告綜述、長篇故事推薦等。
與 text-embedding-ada-002 模型對比測試
與 OpenAI 的 text-embedding-ada-002 相比,jina-embeddings-v2 展現出不俗的實力。下表為兩模型的性能對比。
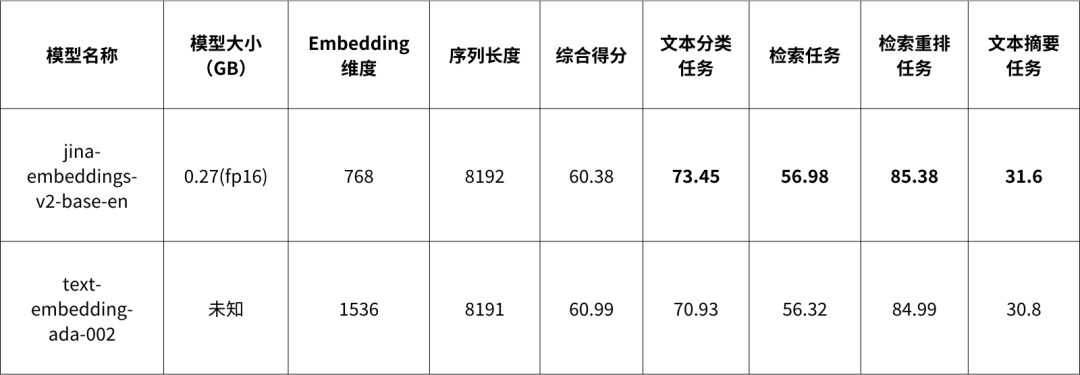
值得注意的是,jina-embeddings-v2 在文本分類任務、檢索任務、檢索重排任務、和文本摘要任務上的得分都超過了 text-embedding-ada-002。
擁抱開源
OpenAI 已經為我們展示了 8K 上下文長度模型的潛力,但 jina-embeddings-v2 不僅與其齊頭并進,還做出了更大膽的決策:完全開源!這意味著任何人都可以使用、修改和進一步優化這款模型。
不僅如此,當我們與 OpenAI 的模型進行直接比較時,jina-embeddings-v2 在多個關鍵指標上展現出了優越的性能。考慮到 jina-embeddings-v2 是開源的,我們堅信通過社區的集體智慧和努力,我們將有機會超越目前的標桿。
正是因為我們堅信開放和共享的價值,我們希望與全球的研究者、工程師和 AI 愛好者共同努力,不斷完善和推進這款模型。我們也在計劃中繼續拓展功能,例如提供更多語言的支持,以及開發更為強大的 API 平臺。
特點和優勢
全新的向量模型發布,再次證明了我們在技術創新上面的決心,jina-embeddings-v2 并非對前代模型的簡單修訂,而是經過了深入研發和優化后的全新設計,我們團隊付出了很多努力,從數據收集、處理再到模型調優,使得 v2 模型在性能表現上有了質的飛躍。
此外,jina-embeddings-v2 支持 8K 輸入長度,與其他領先的向量模型相比,在長文本任務中展現出了明顯的優勢,突顯了其擴展上下文長度的實際價值。這一特點也為很多實際應用提供了更多可能性,比如法律文件解讀、醫學文獻研究、深入的文學分析、金融數據洞察和聊天機器人的應答優化等等。
對于想要使用 jina-embeddings-v2 的開發者和研究者,我們在 Huggingface 平臺上提供了兩種規模的模型,以適應不同場景和需求:
jina-embeddings-v2-base-en
大小:0.27G(fp16),0.54G(fp32)
參數數量:1.37 億
適用場景:適合處理需要高精度的大型任務
jina-embeddings-v2-small-en
大小:0.07G
參數數量:0.33 億
適用場景:特別為輕量級的應用場景設計,如移動端應用或那些計算能力有限的設備上的任務
回顧本次發布歷程,Jina AI 創始人兼 CEO 肖涵博士說:
“在 AI 技術快速發展的今天,始終保持前沿并向公眾開放最新研究成果是我們的核心追求。有了 jina-embeddings-v2,我們達成了一個重要的里程碑。我們不僅開發了全球首款開源 8K 上下文長度的模型,而且其性能能夠與 OpenAI 這樣的行業巨頭相匹敵。Jina AI 的目標很明確:我們希望推動 AI 民主化,讓更多的人能夠使用且受益,而不只是那些擁有大量資源的大公司。今天,我可以很自豪地說,我們朝著這一愿景邁出了堅實的一步。”
展望未來
Jina AI 深信開源的魔力,并致力于為 AI 社區構建前沿且易于接入的工具。接下來,我們還會推動以下幾項重要工作:
分享學術成果:為了讓社區更好地了解 jina-embeddings-v2 的性能和特點,團隊將很快發布一篇詳細的學術文章,深入介紹模型的技術細節,以及和其他模型的比較分析。
API 平臺:我們正在努力構建一個 Embedding API 平臺,其功能和 OpenAI 類似,幫助用戶能夠根據自己的需求,更輕松地使用我們的向量模型。
多語言支持:Jina AI 正著手引入多語種,下一步計劃推出德文/英文以及中文/英文雙語模型,并進一步增強我們模型的能力。
編輯:黃飛
-
API
+關注
關注
2文章
1500瀏覽量
62014 -
聊天機器人
+關注
關注
0文章
339瀏覽量
12312 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13561 -
OpenAI
+關注
關注
9文章
1087瀏覽量
6509
原文標題:Jina AI 推出全球首款開源 8K 向量模型,比肩 OpenAI
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論