 跨語言提示:改進跨語言零樣本思維推理
跨語言提示:改進跨語言零樣本思維推理
論文名稱:Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages
論文作者:覃立波,陳麒光,車萬翔等
原創作者:陳麒光
論文鏈接:https://arxiv.org/abs/2310.14799
出處:哈工大SCIR
最后一個名額:帶你沖刺ACL2024
0. Take-away messages
?本文引入了簡單有效的Cross-Lingual Prompting (CLP),其中包含cross-lingual alignment prompting (CAP) 和 task-specific solver prompting (TSP),它們能夠幫助思維鏈(CoT)范式在不同語言間進行有效地對齊,共同改進了跨語言的零樣本 CoT 推理。
?進一步地,提出了Cross-Lingual Self-consistent Prompting (CLSP),利用不同語言專家的知識和不同語言間更加多樣的思考方式,集成了多個推理路徑,顯著地提高了self-consistency的跨語言性能。CLSP 都能夠在CLP的基礎上更進一步地有效提高零樣本跨語言 CoT 性能。
?對多個基準的廣泛評估表明,CLP 在各類任務上甚至取得了比機器翻譯用戶請求更加優異的性能(在各個多語言數據集上平均準確率至少提高了1.8%)。在此基礎上,CLSP能夠進一步地提高CLP的性能,在多個基準上都取得了超過6%的提升。
1. 背景與動機
1.1 背景
LLM能夠在訓練和測試過程中無需修改模型參數,實現零樣本推理,受到越來越多的關注。具體來說,零樣本思維鏈 (CoT) 只需要附加提示 Let's think step by step! ,就可以從大型語言模型中誘導強大的推理能力,并在各種任務上展示出驚人的性能,包括算術推理、常識推理甚至具身規劃。

圖 1:傳統單語言CoT示例 以傳統CoT為例,提供提示 Let's think step by step! 針對英文請求以進行分步推理。最終,LLM通過多步推理給出了相應的答案68 years。
1.2 動機
全世界有200多個國家和7000多種語言。隨著全球化的加速,迫切需要將當前的CoT推廣到不同的語言中。盡管零樣本CoT取得了顯著的成功,但其推理能力仍然難以推廣到不同的語言。

圖 2:跨語言CoT示例 與請求的語言和 CoT 輸出相同的傳統 CoT 場景不同,跨語言 CoT 要求 LLM 通過提供觸發語句Let's think in English step by step!。 當前零樣本跨語言推理仍處于一個非常早期的階段,沒有考慮跨語言間的顯式對齊。為了更好地將CoT零樣本地泛化到不同語言上,我們提出了cross-lingual-prompting (CLP),旨在有效地彌合不同語言之間的差距。具體來說,CLP 由兩個部分組成:(1) cross-lingual alignment prompting (CAP) 和(2) task-specific solver prompting (TSP)。在第一步中,CLP首先要求模型逐步地理解英語任務,對齊了不同語言之間的表示。在第二步中,CLP要求模型根據上一步理解的內容逐步地完成最終的任務。此外,受self-consistency工作的啟發,我們提出了Cross-Lingual Self-consistent Prompting (CLSP),使模型能夠集成不同語言專家的不同推理路徑。 總的來說,簡單而有效的CLP和CLSP方法可以極大地增強跨語言場景的推理能力。
2. Prompting設計
2.1 CLP設計
為了激發LLM的跨語言推理能力,我們引入了跨語言提示(CLP)作為解決方案。具體來說,CLP 由兩個部分組成:(1) cross-lingual alignment prompting (CAP) 和 (2) task-specific solver prompting (TSP)。

圖 3:Cross-Lingual Prompting (CLP) 示意圖
2.1.1 Cross-lingual Alignment Prompting (CAP)
跨語言對齊是跨語言遷移的核心挑戰。因此,為了更好地捕獲對齊信息,我們首先引入了cross-lingual alignment prompting。該prompt的表述如下:

圖 4:跨語言對齊提示 (CAP) 示意圖 具體來說,給定請求句子 X,我們首先要求 LLM 扮演 在多語言理解方面的專家,來理解跨語言問題。此外,對齊提示將從源語言 Ls 到目標語言 Lt 進行逐步地對齊。
2.1.2 Task-specific Solver Prompting (TSP)
實現跨語言對齊后,我們進一步提出task-specific solver prompting 以促進多語言環境中的多步推理。

圖 5:Task-specific Solver Prompting (TSP) 示意圖 具體來說,給定 目標語言 和從上一步獲得的對齊文本 ,我們提示 LLM 參與解析目標任務。LLM嘗試根據之前對齊的跨語言理解進行進一步的多步推理以確定最終結果。此外,我們提供了一個答案提取的指令來格式化模型的答案,其定義為:

圖 6:答案提取指令示意圖
2.2 CLSP設計
在我們的研究中,我們觀察到LLM在不同語言中表現出不同的推理路徑。受Self-consistency的啟發,我們提出了一種Cross-lingual Self-consistent Prompting (CLSP) 來整合不同語言的推理知識(如圖7所示)。
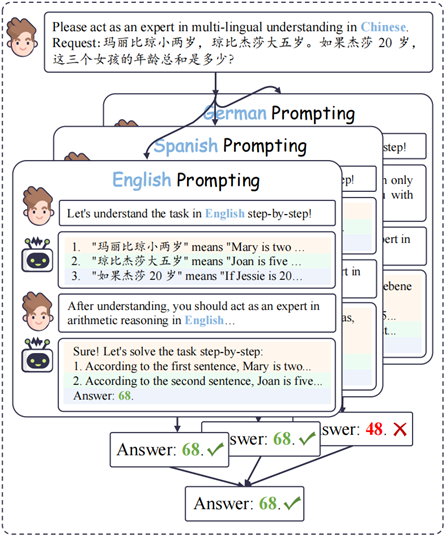
圖 7:Cross-lingual Self-consistent Prompting (CLSP) 示意圖 具體來說,對于推理過程中的每個步驟,我們要求LLM以不同的目標語言生成跨語言對齊的回復,并分別在各自目標語言上進行推理。我們通過投票機制保留在推斷推理結果中表現出高度一致性的答案。然后將這些一致推斷的答案視為最終結果。
3 主實驗分析
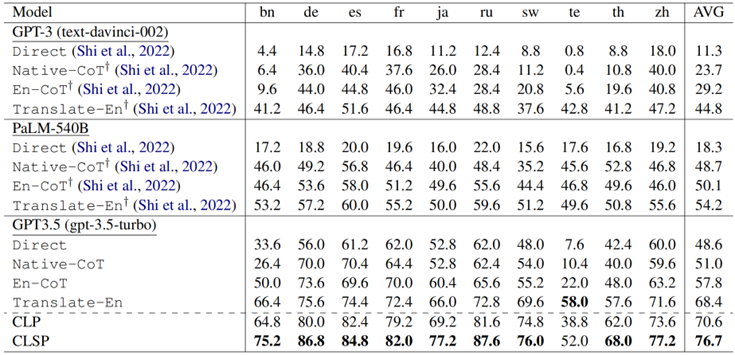
表 1:在MGSM基準上主實驗的推理表現 從表1結果來看,我們有以下觀察結果:
GPT-3.5 表現出顯著的跨語言推理優勢。在各種設置下,GPT-3.5 均大幅超越了 PaLM-540B 和 GPT-3 的少樣本結果。具體來說,與少樣本 PaLM-540B相比,零樣本GPT-3.5實現了 30.3%、2.3%、7.7% 和 14.2%的改進。我們認為是多語言SFT 和 RLHF 技術帶來了跨語言推理性能的顯著提高。
CLP 實現了最先進的性能。CLP 超越了之前的所有基線,特別是優于少樣本的PALM-540B(Translate-En),提高了 16.4%。這一改進不能僅僅歸功于 GPT-3.5,因為CLP 的平均準確度甚至比擁有額外知識的高質量機器翻譯(Translate-En) 高 2.2%。這些發現表明 CLP 超越了原始的文本翻譯,提供了自己的理解,能夠并進一步增強了模型固有的跨語言理解能力。
CLSP 進一步顯著提高了性能。CLSP 在所有語言中都比 CLP 表現出顯著的優越性(平均準確率提高了 6.1%)。這一觀察結果表明,整合不同語言的知識和不同語言間的思考路徑可以有效提高跨語言CoT的推理性能,驗證了CLSP 的有效性。
4 CLP 分析
4.1 CLP能夠擁有更好的推理質量
為了進一步研究CLP為何有效,我們采用Roscoe 框架來評估模型思想鏈中推理路徑的質量。
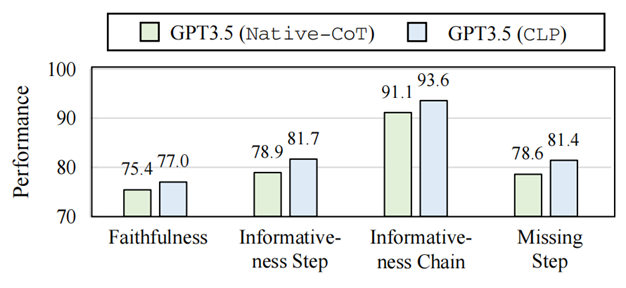
圖 8:Native-CoT 和 CLP 的推理路徑質量 如圖8所示,我們發現CLP的推理路徑表現出更高的忠實度,在推理過程中與關鍵步驟表現出更好的一致性。具體來說,CLP的推理路徑優勢可以總結為:
推理幻覺更少:CLP的推理路徑的Faithfulness得分提高了 1.6%,表明模型更好地理解了問題陳述,并確保了清晰的推理鏈,而不會生成不相關或誤用的信息,更加可信。
推理更有依據:此外,我們觀察到“Step”和“Chain”的Informativeness指標分別提高了 2.8% 和 2.5%。它表明模型的推理在跨語言對齊之后可以提供更有根據的推理步驟。
邏輯鏈更完整:此外,CLP 在 Miss-step 指標中也增強了 2.8%,表明模型的推理可以包含完整的邏輯鏈,從而帶來更好的性能。
4.2 二階段交互式提示比單輪提示效果更好
由于之前CLP分為了兩個階段,本節將探討兩階段交互式提示的有效性。
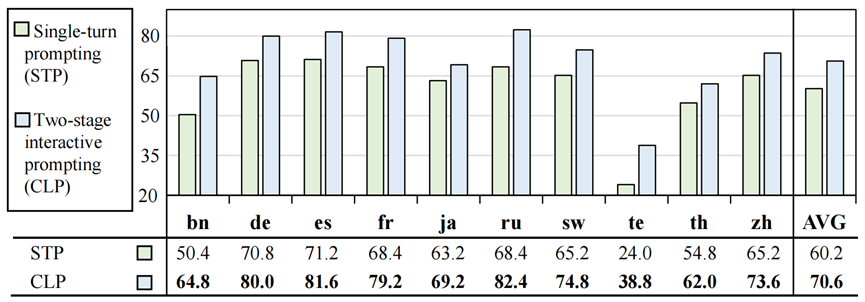
圖 9:二階段和單輪的CoT效果比較 與兩階段交互式提示(CLP)相比,我們觀察到單輪提示性能平均顯著下降 10.4%。我們認為兩階段的交互提示可以更好地引出LLM強大的對話交互能力,從而提高表現。
4.3 CLP 并不是簡單的翻譯
如表1 所示,我們可以發現CLP的平均準確率甚至比機器翻譯請求高出2.2%,這表明CLP不是普通翻譯,而是利用了語言之間的語義對齊。 為了進一步了解 CLP 為何比翻譯效果更好,我們隨機選擇了 200 個來自不同語言的樣本進行細粒度探索。首先,我們發現CLP會自動地采取7種不同的策略,大部分策略一定程度上都對最終的性能做出了貢獻,這證明了CLP的有效性。
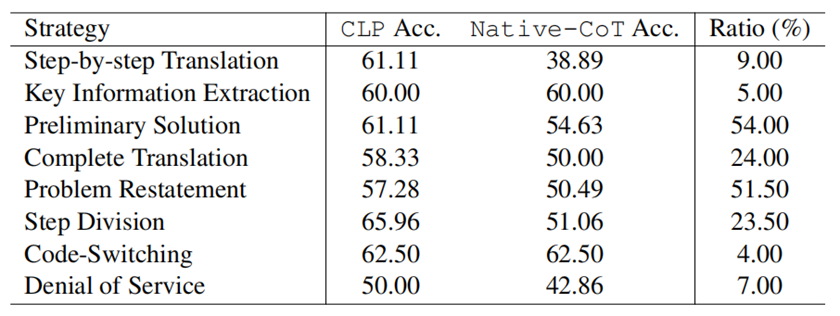
表 2:CLP自動使用的策略的占比以及性能影響 此外,我們發現進一步分解第一階段有助于改進。將第 1 階段的行動分解為 2-4 個策略可以顯著提高性能(至少 6.45%)。例如,通過將對齊過程分解為“問題重述”和“解決初步解決”,就可以獲得優異的性能,達到 64.71%(與 Native-CoT 相比提高了 11.77%)。
4.4 Prompt的選擇如何影響CLP?
我們利用不同的表述的跨語言對齊提示以驗證CLP零樣本跨語言CoT的魯棒性。表3說明了 4 種意思相同但表述不同的跨語言對齊提示的性能。
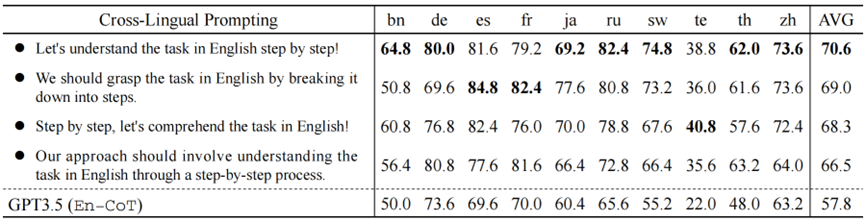
表 3:不同表述的CAP對CLP的影響分析 實驗結果表明,雖然AVG Acc. 存在一定的波動(最大差異超過4%)。但所有跨語言對齊提示相比En-CoT仍然可以提高性能。這進一步驗證了CLP的有效性。
4.5 CLP的泛化性分析
為了進一步研究我們工作的通用性,我們從兩個方面驗證CLP的泛化性:
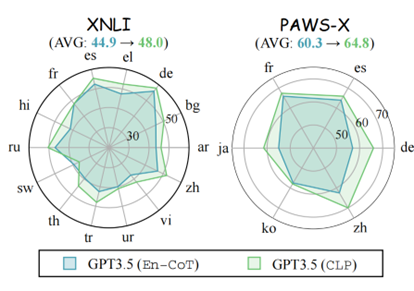
圖 10:在其他多語言數據集上的準確率表現
CLP 在其他多語言基準上效果優異。我們在其他廣泛使用的多語言推理數據集(即 XNLI 和 PAWS-X)上進行了實驗。從表4中的結果來看,我們觀察到 CLP 在大多數語言中都可以獲得更好的性能。與En-CoT相比,我們觀察到 XNLI 的平均改進為 3.1%,PAWS-X 的平均改進為 4.5%。
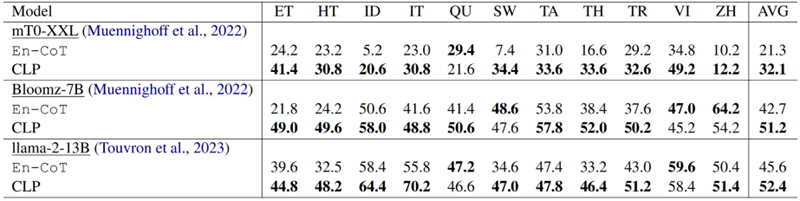
表 4:在其他開源/較小的LLM上的準確率表現
CLP 在其他 LLM 上表現優異。為了更好地理解模型泛化,我們在具有較小 LLM 的 XCOPA 上進行了實驗。實驗結果(如表X所示)表明,在較小的法學碩士上,CLP 與 En-CoT 相比至少實現了 6.8% 的改進。
4.6 CLP能夠通過上下文學習策略進一步提升
近年來,上下文學習(ICL)取得了驚人的結果,為了進一步探索 CLP 在 ICL 框架內的效果,我們進行了一系列實驗。對實證結果的后續分析得出以下觀察結果(實驗在1000條抽樣結果上進行):

表 5:CLP各個階段在ICL設置下的表現
在CAP中使用 ICL 可以顯著提高推理性能。如表5所示,CLP 比 MGSM 上的零樣本設置表現出顯著的 6.9% 改進。這進一步強調了我們的方法作為即插即用模塊的優勢,與 ICL 方法正交,以提高性能。
在TSP中使用 ICL 可以進一步提高推理性能。如表5所示,結果顯示,在 Task-specific Solver Prompting (TSP) 中結合 Complex-CoT時,性能額外提高了 1.1%。與其他 CoT 優化方法相比,這進一步鞏固了我們的方法的獨特性,強調了其適應性以及為下游 CoT 推理技術提供更廣泛支持的能力。
CAP階段的示例選擇起著關鍵作用。我們對ICL策略的各種組合進行了實驗。如表5所示,如果依賴單一策略,則模型的平均性能顯著下降至63.5%,甚至遠低于零樣本的效果。相反,當在少樣本示例中采用更多樣化的策略時,模型的性能顯示出顯著的改進,達到 75.9%。它表明更多樣化的策略樣本可以帶來更好的性能提升。

表 6:在示例中不同對齊策略數量對準確率的影響(策略按照表2中的占比從大到小選取)
5. CLSP Analysis
5.1 CLSP 超越了原始的Self-consistency
為了驗證 CLSP 的有效性,我們對原始的Self-consistency(VSC)進行了實驗。原始的Self-consistency 是指利用不同Temperature生成多條推理路徑,并通過投票的方式確定最終的答案。如圖11所示,與VSC相比,CLSP平均提高了大約 4.5%,驗證了CLSP的有效性。
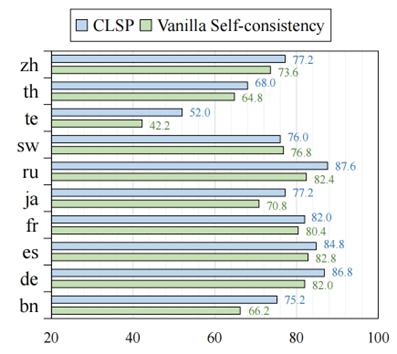
圖 11:CLSP和VSC在MGSM上各個語言的準確率表現 此外,我們嘗試探索 CLSP 為何有效。我們使用所有正確的預測結果和手動注釋的 CoT 推理路徑來評估跨語言 CoT 推理路徑(包括 CLSP 和 VSC)之間的對齊分數。
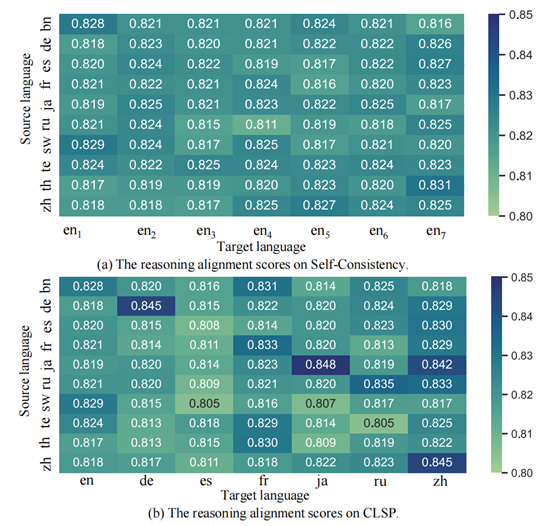
圖 12:CLSP和VSC的不同的推理路徑與標準推理路徑的對齊分數 如圖12所示,CLSP生成的對齊分數的方差明顯高于VSC。它表明 CLSP 更好地集成了語言知識,從而提高了最終的跨語言 CoT 性能。
5.2 集成更多的語言并不能帶來更多的提升
一個自然出現的問題是,“在CLSP中集成大量語言是否會帶來更好的整體表現?”為了回答這個問題,我們探討了CoT表現與集成的語言數量之間的關系。
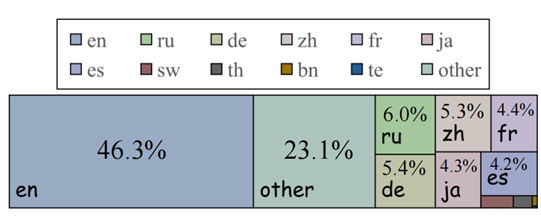
圖 13:Common Crawl 2021數據集語言分布 一些研究表明LLM的表現與每種語言的預訓練數據比例高度相關。因此,我們檢查了廣泛使用的多語言預訓練數據集 Common Crawl 2021 中的語言分布(如圖13所示)。
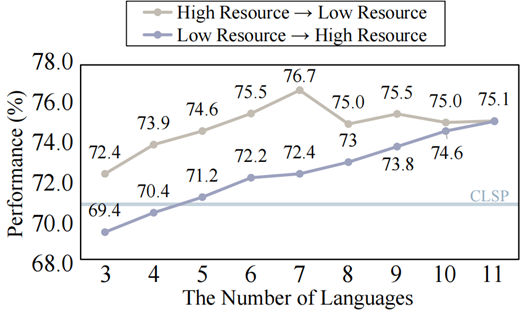
圖 14:集成語言數量對最終性能的影響 根據比例,我們按照語言的降序和升序逐步整合每種語言。各自的比例。圖14中的結果表明,在高資源設置中,隨著添加更多語言,性能會提高。然而,當合并低資源語言時,性能會隨著語言數量的增加而下降。 這些發現表明,語言整合的有效性不僅僅取決于整合的語言數量。每種語言的預訓練數據量,尤其是高資源語言,起著至關重要的作用。考慮到可用資源和影響,平衡多種語言至關重要。
5.3 CLSP泛化性研究
為了進一步驗證 CLSP 的有效性,我們在 XCOPA 數據集上進行了實驗,這是一個廣泛采用的基準,用于評估 11 種不同語言的常識推理技能。
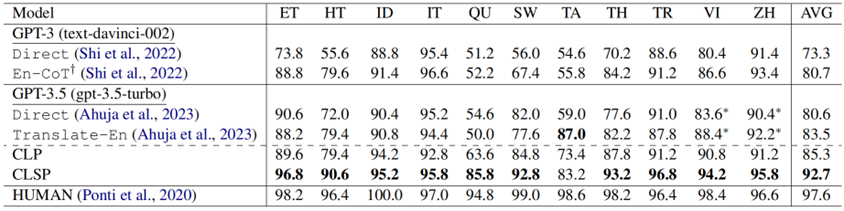
表 7:XCOPA上CLSP的表現 正如表7 中所示的結果所示,與基線相比,我們觀察到 CLP 性能平均顯著提高了 4.7%。此外,與 CLP 相比,CLSP 的性能進一步提高了 7.4%。這些結果表明,除了在數學推理方面表現出色之外,CLSP 在解決常識推理任務方面也表現出顯著的有效性。
6. 結論
在這項工作中,我們引入了跨語言思維鏈的Cross-lingual Prompting (CLP)。具體來說,CLP 由 cross-lingual alignment prompting 和 task-specific solver prompting 組成,用于跨語言對齊表示并在跨語言設置中生成最終推理路徑。
此外,我們提出了Cross-Lingual Self-consistent Prompting (CLSP)來有效利用跨語言的知識,這進一步提高了 CLP 的性能。
大量實驗表明,CLP 和 CLSP 在跨語言 CoT 中都能取得良好的性能。
歡迎感興趣的同學閱讀我們的論文,對于cross-lingual alignment prompting中不同策略的思考,該問題對跨語言的相關研究是非常有價值的。
-
CLP
+關注
關注
0文章
5瀏覽量
7147 -
模型
+關注
關注
1文章
3261瀏覽量
48914 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14914
原文標題:6. 結論
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于機器翻譯增加的跨語言機器閱讀理解算法
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
【大語言模型:原理與工程實踐】大語言模型的應用
AKI跨語言調用庫神助攻C/C++代碼遷移至HarmonyOS NEXT
JAVA語言為什么能跨平臺?
DevEco Studio新特性分享-跨語言調試,讓調試更便捷高效
基于預訓練視覺-語言模型的跨模態Prompt-Tuning

ACL2021的跨視覺語言模態論文之跨視覺語言模態任務與方法
融合零樣本學習和小樣本學習的弱監督學習方法綜述

一個通用的自適應prompt方法,突破了零樣本學習的瓶頸

基于多語言的跨平臺靜態測試解決方案

基于多語言的跨平臺靜態測試解決方案
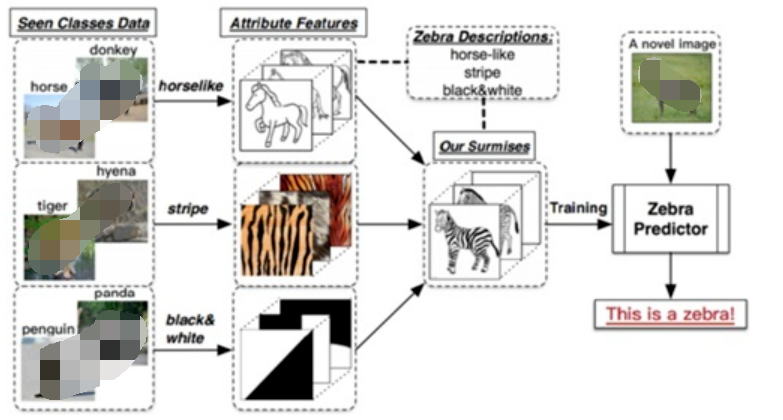
什么是零樣本學習?為什么要搞零樣本學習?





 工商網監
工商網監
評論