") TorchScript model與eager model的性能區(qū)別
TorchScript model與eager model的性能區(qū)別
JIT Trace
torch.jit.trace使用eager model和一個(gè)dummy input作為輸入,tracer會(huì)根據(jù)提供的model和input記錄數(shù)據(jù)在模型中的流動(dòng)過(guò)程,然后將整個(gè)模型轉(zhuǎn)換為TorchScript module。看一個(gè)具體的例子:
我們使用BERT(Bidirectional Encoder Representations from Transformers)作為例子。
from transformers import BertTokenizer, BertModel
import numpy as np
import torch
from time import perf_counter
def timer(f,*args):
start = perf_counter()
f(*args)
return (1000 * (perf_counter() - start))
# 加載bert model
native_model = BertModel.from_pretrained("bert-base-uncased")
# huggingface的API中,使用torchscript=True參數(shù)可以直接加載TorchScript model
script_model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
script_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', torchscript=True)
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = script_tokenizer.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = '[MASK]'
indexed_tokens = script_tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
然后分別在CPU和GPU上測(cè)試eager mode的pytorch推理速度。
# 在CPU上測(cè)試eager model推理性能
native_model.eval()
np.mean([timer(native_model,tokens_tensor,segments_tensors) for _ in range(100)])
# 在GPU上測(cè)試eager model推理性能
native_model = native_model.cuda()
native_model.eval()
tokens_tensor_gpu = tokens_tensor.cuda()
segments_tensors_gpu = segments_tensors.cuda()
np.mean([timer(native_model,tokens_tensor_gpu,segments_tensors_gpu) for _ in range(100)])
再分別在CPU和GPU上測(cè)試script mode的TorchScript模型的推理速度
# 在CPU上測(cè)試TorchScript性能
traced_model = torch.jit.trace(script_model, [tokens_tensor, segments_tensors])
# 因模型的trace時(shí),已經(jīng)包含了.eval()的行為,因此不必再去顯式調(diào)用model.eval()
np.mean([timer(traced_model,tokens_tensor,segments_tensors) for _ in range(100)])
# 在GPU上測(cè)試TorchScript的性能
最終運(yùn)行結(jié)果如表
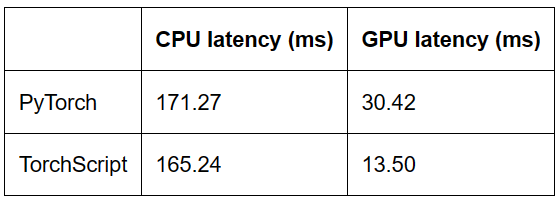
我使用的硬件規(guī)格是google colab,cpu是Intel(R) Xeon(R) CPU @ 2.00GHz,GPU是Tesla T4。
從結(jié)果來(lái)看,在CPU上,TorchScript比pytorch eager快了3.5%,在GPU上,TorchScript比pytorch快了55.6%。
然后我們?cè)儆肦esNet做一個(gè)測(cè)試。
import torchvision
import torch
from time import perf_counter
import numpy as np
def timer(f,*args):
start = perf_counter()
f(*args)
return (1000 * (perf_counter() - start))
# Pytorch cpu version
model_ft = torchvision.models.resnet18(pretrained=True)
model_ft.eval()
x_ft = torch.rand(1,3, 224,224)
print(f'pytorch cpu: {np.mean([timer(model_ft,x_ft) for _ in range(10)])}')
# Pytorch gpu version
model_ft_gpu = torchvision.models.resnet18(pretrained=True).cuda()
x_ft_gpu = x_ft.cuda()
model_ft_gpu.eval()
print(f'pytorch gpu: {np.mean([timer(model_ft_gpu,x_ft_gpu) for _ in range(10)])}')
# TorchScript cpu version
script_cell = torch.jit.script(model_ft, (x_ft))
print(f'torchscript cpu: {np.mean([timer(script_cell,x_ft) for _ in range(10)])}')
# TorchScript gpu version
script_cell_gpu = torch.jit.script(model_ft_gpu, (x_ft_gpu))
print(f'torchscript gpu: {np.mean([timer(script_cell_gpu,x_ft.cuda()) for _ in range(100)])}')
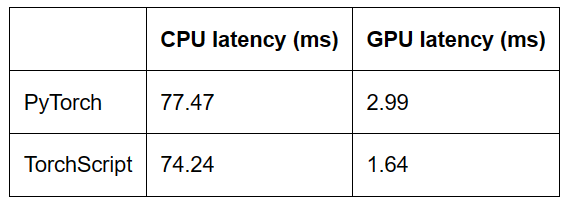
TorchScript相比PyTorch eager model,CPU性能提升4.2%,GPU性能提升45%。與Bert的結(jié)論一致。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
cpu
+關(guān)注
關(guān)注
68文章
10889瀏覽量
212396 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7102瀏覽量
89285 -
模型
+關(guān)注
關(guān)注
1文章
3279瀏覽量
48972
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦

Java開(kāi)發(fā):Web開(kāi)發(fā)模式——ModelⅠ#Java
JAVAModel
學(xué)習(xí)硬聲知識(shí)
發(fā)布于 :2022年11月16日 13:25:45

Java開(kāi)發(fā):Web開(kāi)發(fā)模式——ModelⅡ#Java
JAVAModel
學(xué)習(xí)硬聲知識(shí)
發(fā)布于 :2022年11月16日 13:26:13
PSpice如何利用Model Editor建立模擬用的Model
PSpice 提供Model Editor 建立組件的Model,從組件供貨商那邊拿該組件的Datasheet,透過(guò)描點(diǎn)的方式就可以簡(jiǎn)單的建立組件的Model,來(lái)做電路的模擬。PSpice 如何利用
發(fā)表于 03-31 11:38
IC設(shè)計(jì)基礎(chǔ):說(shuō)說(shuō)wire load model
說(shuō)起wire load model,IC設(shè)計(jì)EDA流程工程師就會(huì)想到DC的兩種工具模式:線負(fù)載模式(wire load mode)和拓?fù)淠J?topographicalmode)。為什么基本所有深亞
發(fā)表于 05-21 18:30
Model B的幾個(gè)PCB版本
盡管樹(shù)莓派最新版的型號(hào)Model B+目前有著512 MB的內(nèi)存和4個(gè)USB端口,但這些都不會(huì)是一成不變的。除了Model B+外,標(biāo)準(zhǔn)的Model B還有兩個(gè)變種的型號(hào)。如果你買到的是一個(gè)雙面的樹(shù)莓派
發(fā)表于 08-08 07:17
Model3電機(jī)是什么
—Model3電機(jī)拆解 汽車攻城獅交流異步電機(jī)交流異步電機(jī)也叫感應(yīng)電機(jī),由定子和轉(zhuǎn)子組成。定子鐵芯一般由硅鋼片疊壓而成,有良好的導(dǎo)磁性能,定子鐵芯的內(nèi)圓上有分布均勻的槽口,這個(gè)槽口是用來(lái)安放定子繞組的
發(fā)表于 08-26 09:12
Cycle Model Studio 9.2版用戶手冊(cè)
高性能可鏈接對(duì)象,稱為Cycle Model,它既精確于循環(huán),又精確于寄存器。循環(huán)模型提供了與驗(yàn)證環(huán)境對(duì)接的功能。
此外,Cycle Model Studio可以編譯與特定設(shè)計(jì)平臺(tái)兼容的模型,如SoC
發(fā)表于 08-12 06:26
性能全面升級(jí)的特斯拉Model S/Model X到來(lái)
據(jù)外媒7月3日消息,在全新車型Model 3即將上市之際,特斯拉公布了對(duì)其現(xiàn)有兩款車型Model S和Model X的一系列升級(jí),旨在提高其非性能車型的加速能力。
發(fā)表于 07-06 09:13
?1491次閱讀
Model Y車型類似Model3 但續(xù)航里程會(huì)低于Model3
馬斯克在連續(xù)發(fā)布了Model3標(biāo)準(zhǔn)版上市、關(guān)閉線下門店等多項(xiàng)重大消息之后,繼續(xù)放大招,在Twitter上,馬斯克表示,將于3月14日在洛杉磯發(fā)布旗下跨界SUV Model Y純電動(dòng)汽車根據(jù)馬斯克此前
發(fā)表于 03-05 16:17
?2265次閱讀
仿真器與Model的本質(zhì)區(qū)別
仿真器所需的“時(shí)間”和“精度”怎么協(xié)調(diào)?想快就向Digital仿真器靠攏;想準(zhǔn)就向Analog靠攏。做Model不是做加法、就是做減法。做Analog出身的熟悉Schematic
特斯拉再次調(diào)整Model 3/Model Y長(zhǎng)續(xù)航版的售價(jià)
2月22日消息,據(jù)國(guó)外媒體報(bào)道,在對(duì)標(biāo)準(zhǔn)續(xù)航升級(jí)版和Performance高性能版價(jià)格進(jìn)行調(diào)整后,特斯拉再次調(diào)整Model 3/Model Y長(zhǎng)續(xù)航版的起售價(jià)。
特斯拉Model Y高性能版國(guó)內(nèi)正式交付
近日,首批特斯拉Model Y高性能版車型已經(jīng)正式啟動(dòng)交付,新款特斯拉Model Y在動(dòng)力方面比標(biāo)準(zhǔn)版和長(zhǎng)續(xù)航版更強(qiáng)。目前Model Y已經(jīng)取得了不錯(cuò)的銷量,特斯拉
TorchScript的重要特性和用途
PyTorch支持兩種模式:eager模式和script模式。eager模式主要用于模型的編寫、訓(xùn)練和調(diào)試,script模式主要是針對(duì)部署的,其包含PytorchJIT和TorchScript(一種





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論