 etcd的原理和應用
etcd的原理和應用
etcd介紹
etcd是什么
etcd 是云原生架構中重要的基礎組件,由 CNCF 孵化托管。etcd 在微服務和 Kubernates 集群中不僅可以作為服務注冊于發現,還可以作為 key-value 存儲的中間件。
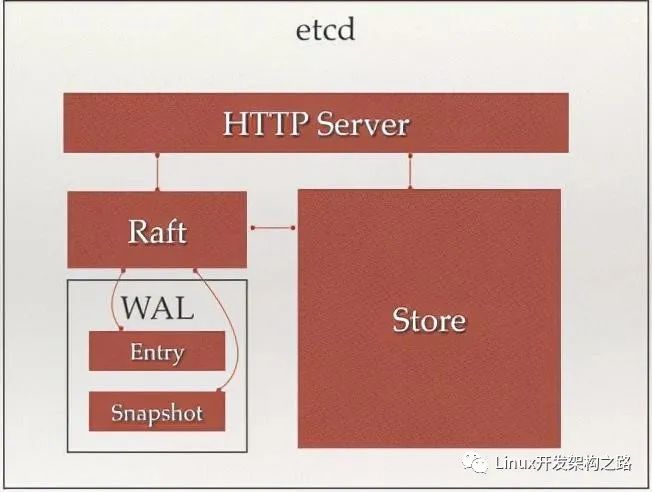
http server:用于處理用戶發送的API請求及其他etcd節點的同步與心跳信息請求
store:用于處理etcd支持的各類功能的事務,包括:數據索引、節點狀態變更、監控與反饋、事件處理與執行等等,是etcd對用戶提供大多數API功能的具體實現
raft:強一致性算法,是etcd的核心
wal(write ahead log):預寫式日志,是etcd的數據存儲方式。除了在內存中存有所有數據的狀態及節點的索引外,還通過wal進行持久化存儲。
- 在wal中,所有的數據提交前都會事先記錄日志
- entry是存儲的具體日志內容
- snapshot是為了防止數據過多而進行的狀態快照
etcd的特點
etcd的目標是構建一個高可用的分布式鍵值(key-value)數據庫。具有以下特點:
- 簡單:安裝配置簡單,而且提供了 HTTP API 進行交互,使用也很簡單
- 鍵值對存儲:將數據存儲在分層組織的目錄中,如同在標準文件系統中
- 監測變更:監測特定的鍵或目錄以進行更改,并對值的更改做出反應
- 安全:支持 SSL 證書驗證
- 快速:根據官方提供的 benchmark 數據,單實例支持每秒 2k+ 讀操作
- 可靠:采用 raft 算法,實現分布式系統數據的可用性和一致性
etcd 采用 Go 語言編寫,它具有出色的跨平臺支持,很小的二進制文件和強大的社區。etcd 機器之間的通信通過 raft 算法處理。
etcd的功能
etcd 是一個高度一致的分布式鍵值存儲,它提供了一種可靠的方式來存儲需要由分布式系統或機器集群訪問的數據。它可以優雅地處理網絡分區期間的 leader 選舉,以應對機器的故障,即使是在 leader 節點發生故障時。
從簡單的 Web 應用程序到 Kubernetes 集群,任何復雜的應用程序都可以從 etcd 中讀取數據或將數據寫入 etcd。
etcd的應用場景
最常用于服務注冊與發現,作為集群管理的組件使用
也可以用于K-V存儲,作為數據庫使用
關于etcd的存儲
etcd 是一個鍵值存儲的組件,其他的應用都是基于其鍵值存儲的功能展開。
etcd 的存儲有如下特點:
1、采用kv型數據存儲,一般情況下比關系型數據庫快。
2、支持動態存儲(內存)以及靜態存儲(磁盤)。
3、分布式存儲,可集成為多節點集群。
4、存儲方式,采用類似目錄結構。
- 只有葉子節點才能真正存儲數據,相當于文件。
- 葉子節點的父節點一定是目錄,目錄不能存儲數據。
服務注冊與發現
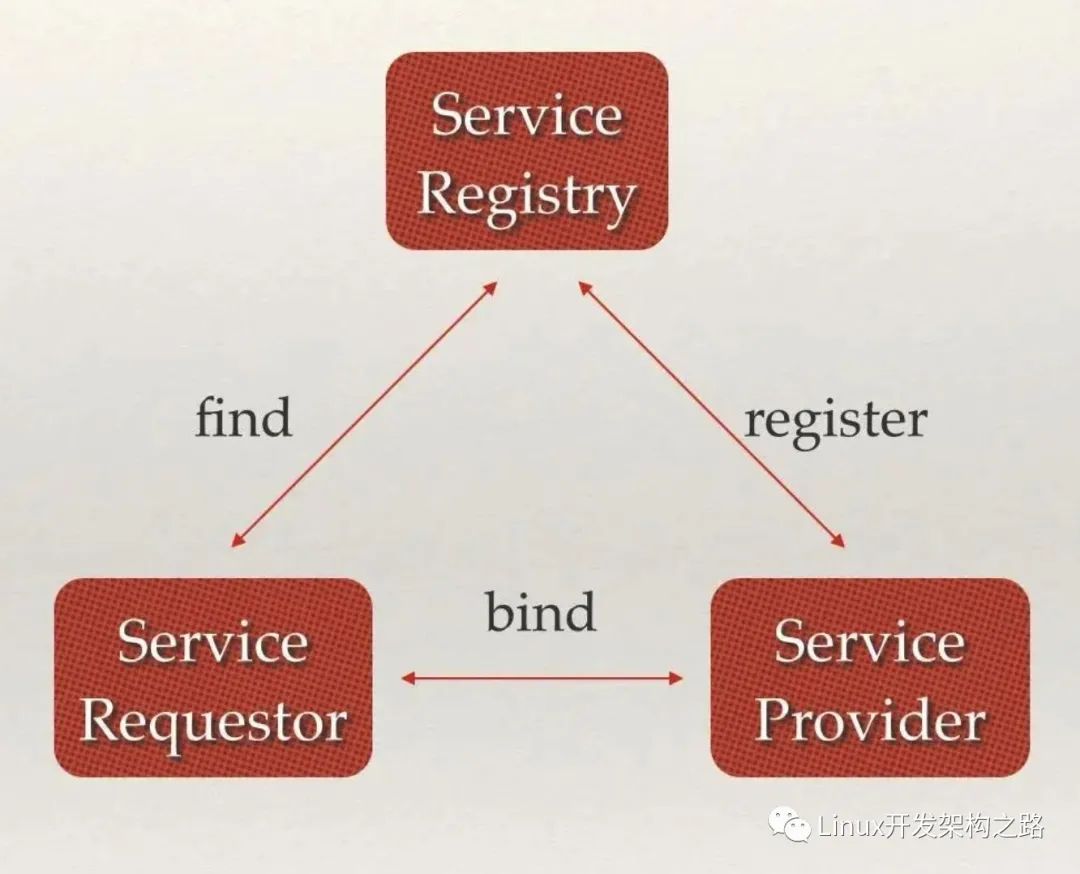
分布式系統中最常見的問題之一:在同一個分布式集群中的進程或服務如何才能找到對方并建立連接
服務發現就可以解決此問題。
從本質上說,服務發現就是要了解集群中是否有進程在監聽 UDP 或者 TCP 端口,并且通過名字就可以進行查找和鏈接
服務發現的三大支柱
強一致性、高可用的服務存儲目錄。基于 Raft 算法的 etcd 天生就是這樣一個強一致性、高可用的服務存儲目錄。
一種注冊服務和服務健康狀況的機制。用戶可以在 etcd 中注冊服務,并且對注冊的服務配置 key TTL,定時保持服務的心跳以達到監控健康狀態的效果。
一種查找和連接服務的機制。通過在 etcd 指定的主題下注冊的服務業能在對應的主題下查找到。為了確保連接,我們可以在每個服務機器上都部署一個 Proxy 模式的 etcd,這樣就可以確保訪問 etcd 集群的服務都能夠互相連接。
etcd2 中引入的 etcd/raft 庫,是目前最穩定、功能豐富的開源一致性協議之一。作為 etcd、TiKV、CockcorachDB、Dgraph 等知名分布式數據庫的核心數據復制引擎,etcd/raft 驅動了超過十萬個集群,是被最為廣泛采用一致性協議實現之一
消息發布與訂閱
在多節點、分布式系統中,最適用的一種組件間通信方式就是消息發布與訂閱,即:
- 即構建一個配置共享中心,數據提供者在這個配置中心發布消息,而消息使用者則訂閱他們關心的主題,一旦主題有消息發布,就會實時通知訂閱者。通過這種方式可以做到分布式系統配置的集中式管理與動態更新

應用中用到的一些配置信息放到etcd上進行集中管理。這類場景的使用方式通常是:
- 應用在啟動的時候主動從etcd獲取一次配置信息。
- 同時,在etcd節點上注冊一個Watcher并等待
- 以后每次配置有更新的時候,etcd都會實時通知訂閱者,以此達到獲取最新配置信息的目的
分布式搜索服務中,索引的元信息和服務器集群機器的節點狀態存放在etcd中,供各個客戶端訂閱使用。使用etcd的key TTL功能可以確保機器狀態是實時更新的。
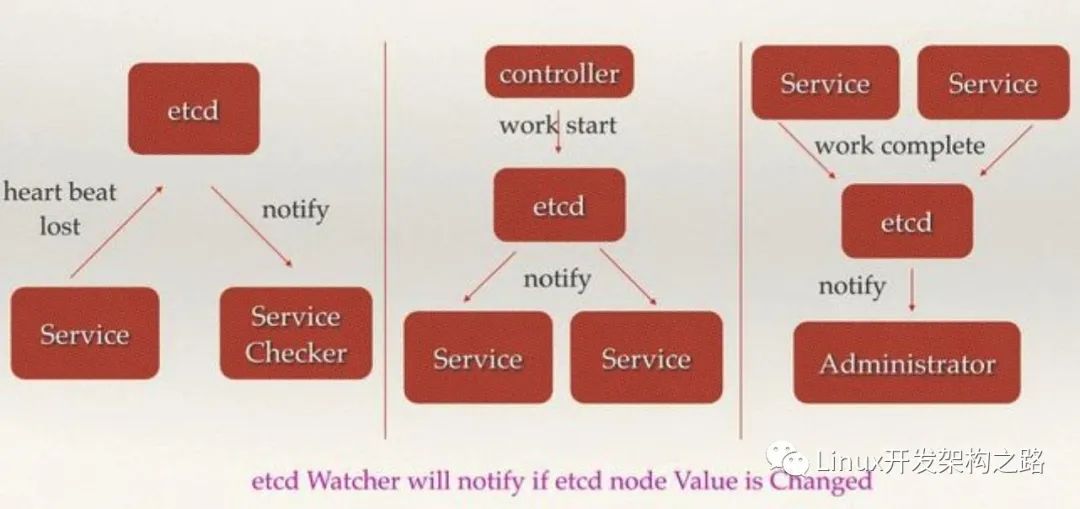
etcd中使用了Watcher機制,通過注冊與異步通知機制,實現分布式環境下不同系統之間的通知與協調,從而對數據變更做到實時處理。實現方式:
- 不同系統都在etcd上對同一個目錄進行注冊,同時設置Watcher觀測該目錄的變化(如果對子目錄的變化也有需要,可以設置遞歸模式)
- 當某個系統更新了etcd的目錄,那么設置了Watcher的系統就會收到通知,并作出相應處理。
etcd集群的部署
為了整個集群的高可用,etcd一般都會進行集群部署,以避免單點故障。
引導etcd集群的啟動有以下三種機制:
- 靜態
- etcd動態發現
- DNS發現
靜態啟動etcd集群
單機安裝
如果想要在一臺機器上啟動etcd集群,可以使用 goreman 工具(go語言編寫的多進程管理工具,是對Ruby下官方使用的foreman的重寫)
操作步驟:
- 安裝Go運行環境
- 安裝goreman:go get github.com/mattn/goreman
- 配置goreman的配置加農本 Procfile:

etcd1: etcd --name infra1 --listen-client-urls http://127.0.0.1:12379 --advertise-client-urls http://127.0.0.1:12379 --listen-peer-urls http://127.0.0.1:12380 --initial-advertise-peer-urls http://127.0.0.1:12380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
etcd2: etcd --name infra2 --listen-client-urls http://127.0.0.1:22379 --advertise-client-urls http://127.0.0.1:22379 --listen-peer-urls http://127.0.0.1:22380 --initial-advertise-peer-urls http://127.0.0.1:22380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
etcd3: etcd --name infra3 --listen-client-urls http://127.0.0.1:32379 --advertise-client-urls http://127.0.0.1:32379 --listen-peer-urls http://127.0.0.1:32380 --initial-advertise-peer-urls http://127.0.0.1:32380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
參數說明:
- –name:etcd集群中的節點名,這里可以隨意,可區分且不重復即可
- –listen-peer-urls:監聽的用于節點之間通信的url,可監聽多個,集群內部將通過這些url進行數據交互(如選舉,數據同步等)
- –initial-advertise-peer-urls:建議用于節點之間通信的url,節點間將以該值進行通信。
- –listen-client-urls:監聽的用于客戶端通信的url,同樣可以監聽多個。
- –advertise-client-urls:建議使用的客戶端通信 url,該值用于 etcd 代理或 etcd 成員與 etcd 節點通信。
- –initial-cluster-token:etcd-cluster-1,節點的 token 值,設置該值后集群將生成唯一 id,并為每個節點也生成唯一 id,當使用相同配置文件再啟動一個集群時,只要該 token 值不一樣,etcd 集群就不會相互影響。
- –initial-cluster:也就是集群中所有的 initial-advertise-peer-urls 的合集。
- –initial-cluster-state:new,新建集群的標志
啟動:goreman -f /opt/etcd/etc/procfile start
docker啟動集群
etcd 使用
gcr.io/etcd-development/etcd 作為容器的主要加速器, quay.io/coreos/etcd 作為輔助的加速器:
- docker pull bitnami/etcd:3.4.7
- docker image tag bitnami/etcd:3.4.7 quay.io/coreos/etcd:3.4.7
鏡像設置好之后,啟動 3 個節點的 etcd 集群,腳本命令如下:
- 該腳本是部署在三臺機器上,每臺機器置行對應的腳本即可。
REGISTRY=quay.io/coreos/etcd
# For each machine
ETCD_VERSION=3.4.7
TOKEN=my-etcd-token
CLUSTER_STATE=new
NAME_1=etcd-node-0
NAME_2=etcd-node-1
NAME_3=etcd-node-2
HOST_1= 192.168.202.128
HOST_2= 192.168.202.129
HOST_3= 192.168.202.130
CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380
DATA_DIR=/var/lib/etcd
# For node 1
THIS_NAME=${NAME_1}
THIS_IP=${HOST_1}
docker run
-p 2379:2379
-p 2380:2380
--volume=${DATA_DIR}:/etcd-data
--name etcd ${REGISTRY}:${ETCD_VERSION}
/usr/local/bin/etcd
--data-dir=/etcd-data --name ${THIS_NAME}
--initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://0.0.0.0:2380
--advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://0.0.0.0:2379
--initial-cluster ${CLUSTER}
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
# For node 2
THIS_NAME=${NAME_2}
THIS_IP=${HOST_2}
docker run
-p 2379:2379
-p 2380:2380
--volume=${DATA_DIR}:/etcd-data
--name etcd ${REGISTRY}:${ETCD_VERSION}
/usr/local/bin/etcd
--data-dir=/etcd-data --name ${THIS_NAME}
--initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://0.0.0.0:2380
--advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://0.0.0.0:2379
--initial-cluster ${CLUSTER}
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
# For node 3
THIS_NAME=${NAME_3}
THIS_IP=${HOST_3}
docker run
-p 2379:2379
-p 2380:2380
--volume=${DATA_DIR}:/etcd-data
--name etcd ${REGISTRY}:${ETCD_VERSION}
/usr/local/bin/etcd
--data-dir=/etcd-data --name ${THIS_NAME}
--initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://0.0.0.0:2380
--advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://0.0.0.0:2379
--initial-cluster ${CLUSTER}
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
動態發現啟動etcd集群
在實際環境中,集群成員的ip可能不會提前知道。這種情況下需要使用自動發現來引導etcd集群,而不是事先指定靜態配置
協議原理
discovery service protocol 幫助新的 etcd 成員使用共享 URL 在集群引導階段發現所有其他成員。
該協議使用新的發現令牌來引導一個唯一的 etcd 集群。一個發現令牌只能代表一個 etcd 集群。只要此令牌上的發現協議啟動,即使它中途失敗,也不能用于引導另一個 etcd 集群。
獲取 discovery 的 token:
- 生成將標識新集群的唯一令牌:UUID=$(uuidgen)
- 指定集群的大小:curl -X PUT http://:2379/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83/_config/size -d value=3
- 將該url地址,作為 --discovery 參數來啟動etcd,節點會自動使用該url目錄進行etcd的注冊和發現服務。
在完成了集群的初始化后,當再需要增加節點時,需要使用etcdctl進行操作,每次啟動新的etcd集群時,都使用新的token進行注冊。
DNS自發現模式
etcd核心API
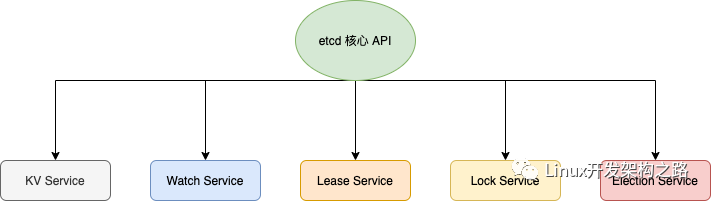
- KV 服務,創建,更新,獲取和刪除鍵值對。
- 監視,監視鍵的更改。
- 租約,消耗客戶端保持活動消息的基元。
- 鎖,etcd 提供分布式共享鎖的支持。
- 選舉,暴露客戶端選舉機制。
etcd典型應用場景(K8s)
什么是k8s?
開源的,用于管理云平臺中多個主機上的容器化應用。
與傳統應用部署方式的區別:
傳統部署:
- 通過插件或腳本的方式安裝應用。這樣做的缺點是應用的運行、配置、管理、所有生存周期將與當前操作系統綁定,不利于應用的升級更新、回滾等操作。
- 由于資源利用不足而無法擴展,并且組織維護大量物理服務器的成本很高。
虛擬化部署:
- 虛擬化功能,允許在單個物理服務器的cpu上運行多個虛擬機(VM)
- 應用程序在VM之間隔離,提供安全級別
- 虛擬機非常重,可移植性、擴展性差
容器化部署:
- 通過容器的方式實現部署,每個容器之間相互隔離,每個容器有自己的文件系統,容器之間進程不會相互影響,能區分計算資源。
- 相對于虛擬機,容器能快速部署,由于容器與底層設施、機器文件系統是解耦的,所以它能在不同的云、不同版本操作系統之間進行遷移。
- 容器占用資源少、部署快,每個應用都可以被打包成一個容器鏡像,每個應用與容器之間形成一對一的關系。每個應用不需要與其余的應用堆棧組合,也不依賴于生產環境的基礎結構,這使得從研發–>測試–>生產能提供一致的環境。
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(
img-fm4iUxNG-1607939778399)(https://d33wubrfki0l68.cloudfront.net/26a177ede4d7b032362289c6fccd448fc4a91174/eb693/images/docs/container_evolution.svg)]
K8s提供了一個可彈性運行分布式系統的框架,可以滿足實際生產環境所需要的擴展要求、故障轉移、部署模式等
K8s提供如下功能:
- 服務發現與負載均衡
- 存儲編排
- 自動部署和回滾
- 自動二進制打包:K8s允許指定每個容器所需CPU和內存(RAM),當容器制定了資源請求時,K8s可以做出更好的決策來管理容器的資源。
- 自我修復:K8s重新啟動失敗的容器,替換容器,殺死不響應用戶定義的運行狀況檢查的容器,并且在準備好服務之前將其通告給客戶端
- 密鑰與配置管理
K8s的特點
可移植: 支持公有云,私有云,混合云,多重云(multi-cloud)
可擴展: 模塊化,插件化,可掛載,可組合
自動化: 自動部署,自動重啟,自動復制,自動伸縮/擴展
K8s組件
master(主節點)組件:
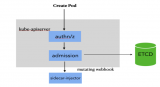
kube-apiserver:對外提供調用的開放接口服務
ETCD:提供默認的存儲系統,保存所有集群數據
kube-controller-manager:運行管理控制器,是集群中處理常規任務的后臺線程,包括:
- 節點控制器:
- 副本控制器:負責維護系統中每個副本中的pod(pod是最小的,管理,創建,計劃的最小單元)
- 端點控制器:填充endpoints對象(連接service 和 pods)
- service account和token控制器:
cloud-controller-manager:云控制器管理器負責與底層云提供商的平臺交互
kube-scheduler:監視新創建沒有分配到node的pod,為pod選擇一個node
插件 addons:實現集群pod和service功能
- DNS
- 用戶界面
- 容器資源監測
- Cluster-level Logging
node(計算節點)組件:
kubelet:主要的節點代理,它會監視已分配給節點的pod
kube-proxy:通過在主機上維護網絡規則并執行連接轉發來實現k8s服務抽象
docker:運行容器
RKT:運行容器,作為docker工具的替代方案
supervisord:一個輕量級監控系統,用于保障kubelet和docker的運行
fluentd:守護進程,可提供cluster-level logging
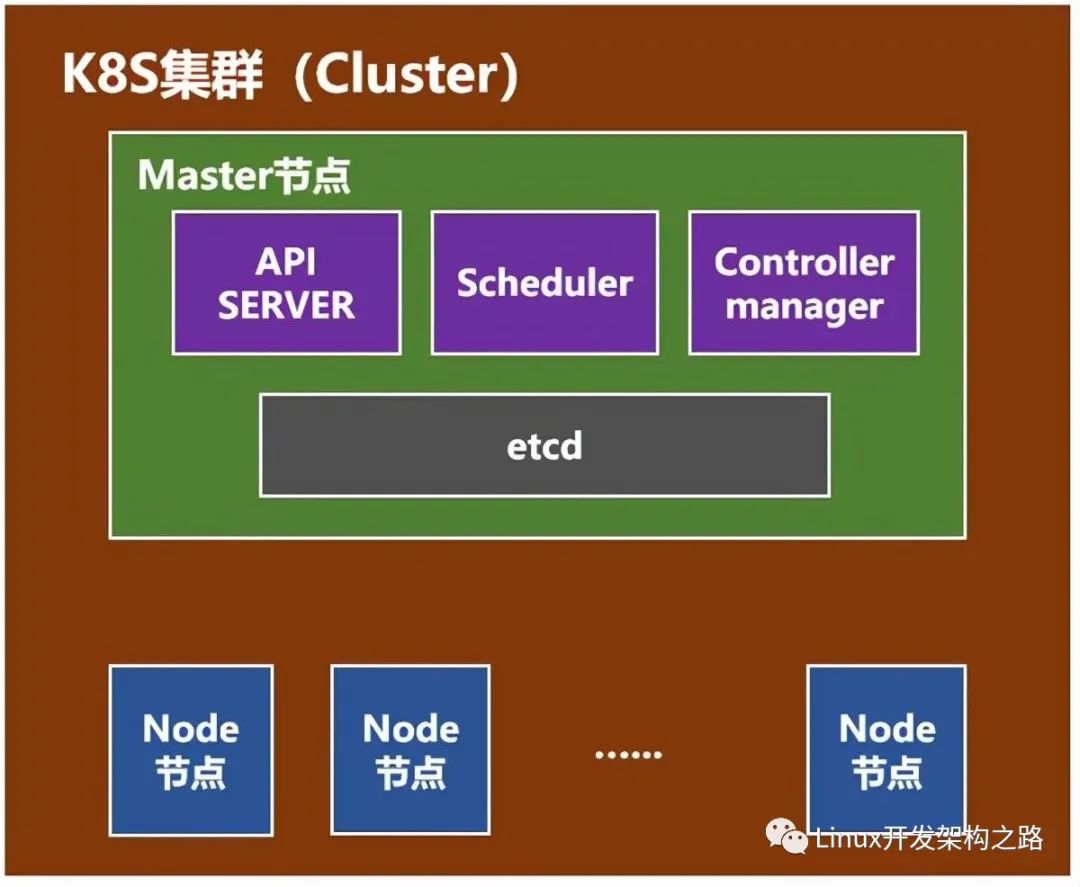
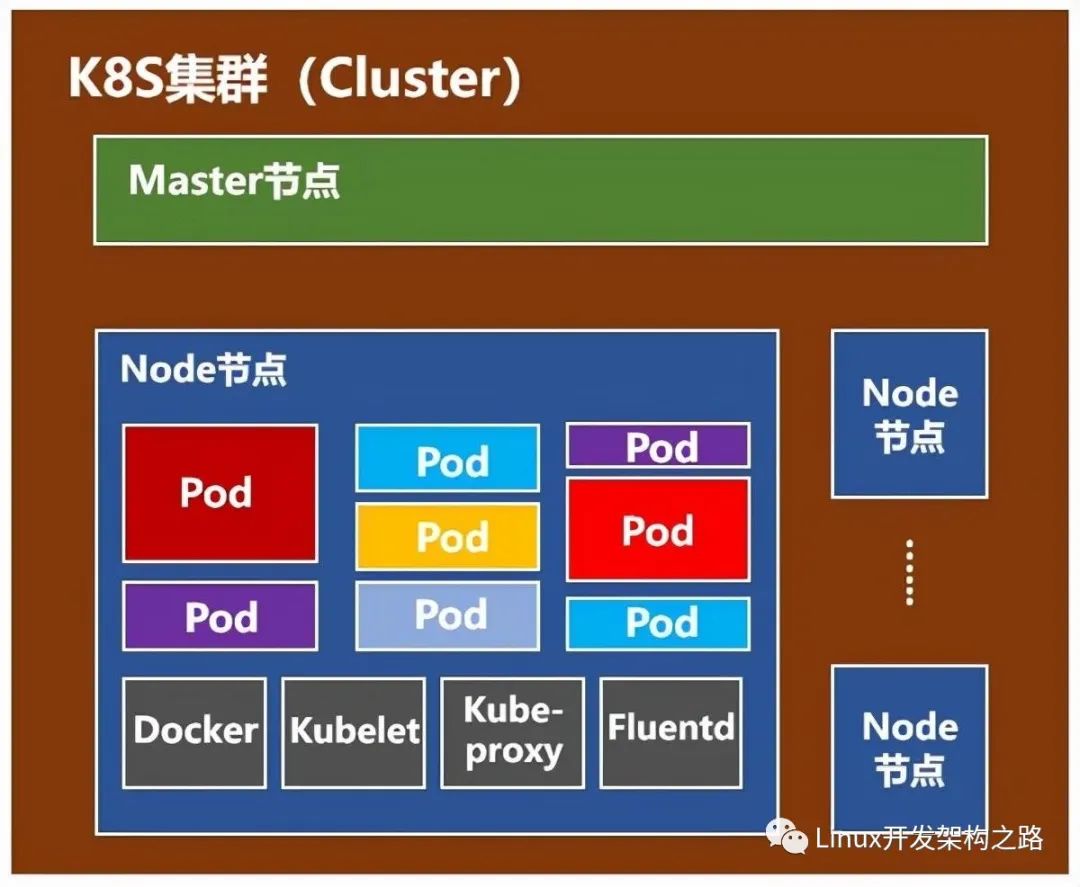
K8s典型架構圖
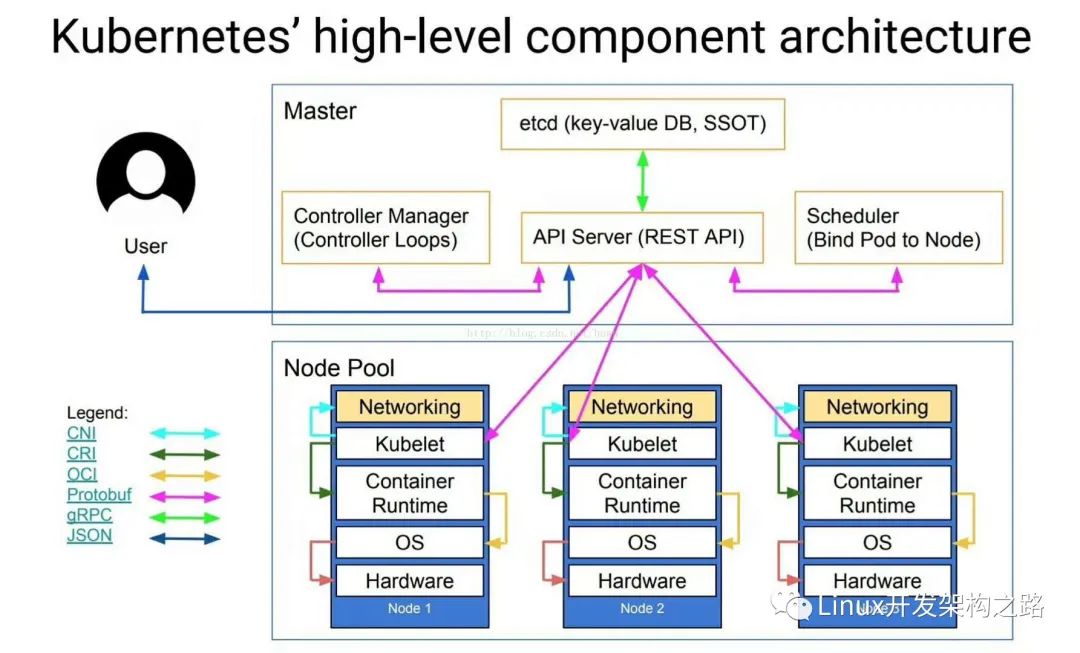
說明:
CNI:CNI(容器網絡接口)是Cloud Native Computing Foundation項目,由一個規范和庫(用于編寫用于在Linux容器中配置網絡接口的插件)以及許多受支持的插件組成。CNI僅涉及容器的網絡連接以及刪除容器時刪除分配的資源,通過json的語法定義了CNI插件所需要的輸入和輸出。
CRI:容器運行時接口,一個能讓kubelet無需編譯就可以支持多種容器運行時的插件接口。CRI包含了一組protocol buffer。gRPC API相關的庫。
OCI:主要負責是容器的生命周期管理,OCI的runtime spec標準中對于容器狀態的描述,以及對容器的創建、刪除、查看等操作進行了定義。runc是對OCI標準的一個參考實現
-
API
+關注
關注
2文章
1505瀏覽量
62168 -
數據存儲
+關注
關注
5文章
977瀏覽量
50957 -
CNC
+關注
關注
7文章
313瀏覽量
35222
發布評論請先 登錄
相關推薦
降低 80% 的讀寫響應延遲!我們測評了 etcd 3.4 新特性(內含讀寫發展史)
ARM Neoverse IP的AWS實例上etcd分布式鍵對值存儲性能提升
在arm機器上如何編譯vitess并運行local用例呢
比較AWS M6g實例與M5實例上的etcd吞吐量和延遲性能
基于DOCKER容器的ELK日志收集系統分析
阿里巴巴持續投入,etcd 正式加入 CNCF
ETCD集群的工作原理和高可用技術細節介紹

快速了解kubernetes
公司為啥用ETCD作為配置中心呢
關于K8S集群如何優化的?
多層面分析 etcd 與 PostgreSQL數據存儲方案的差異
深度解析Istio Proxy邊車容器的功能與能力





 工商網監
工商網監
評論