 Linux下各種鎖的理解
Linux下各種鎖的理解
一.鎖
鎖出現的原因
臨界資源是什么: 多線程執行流所共享的資源
鎖的作用是什么, 可以做原子操作, 在多線程中針對臨界資源的互斥訪問... 保證一個時刻只有一個線程可以持有鎖對于臨界資源做修改操作...
任何一個線程如果需要修改,向臨界資源做寫入操作都必須持有鎖,沒有持有鎖就不能對于臨界資源做寫入操作.
鎖 : 保證同一時刻只能有一個線程對于臨界資源做寫入操作 (鎖地功能)
再一個直觀地代碼引出問題,再從指令集的角度去看問題
#include < stdio.h >
#include < stdlib.h >
#include < unistd.h >
#include < sys/types.h >
#include < pthread.h >
void* Routine(void* arg) {
int *pcount = (int*)arg;
for (int i = 0; i < 20000000; ++i) {
(*pcount)++;
}
return (void*)0;
}
int main() {
int count = 0;
pthread_t tid1, tid2, tid3;
pthread_create(&tid1, NULL, Routine, (void*)&count);
pthread_create(&tid2, NULL, Routine, (void*)&count);
pthread_create(&tid3, NULL, Routine, (void*)&count);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
//看一看結果
printf("count: %dn", count);
return 0;
}

上述一個及其奇怪的結果,這個結果每一次運行都可能是不一樣的,Why ? 按照我們本來的想法是每一個線程 + 20000000 結果肯定應該是60000000呀,可以就是達不到這個值
為何? (深入匯編指令來看) 一定將過程放置到匯編指令上去看就可以理解這個過程了.
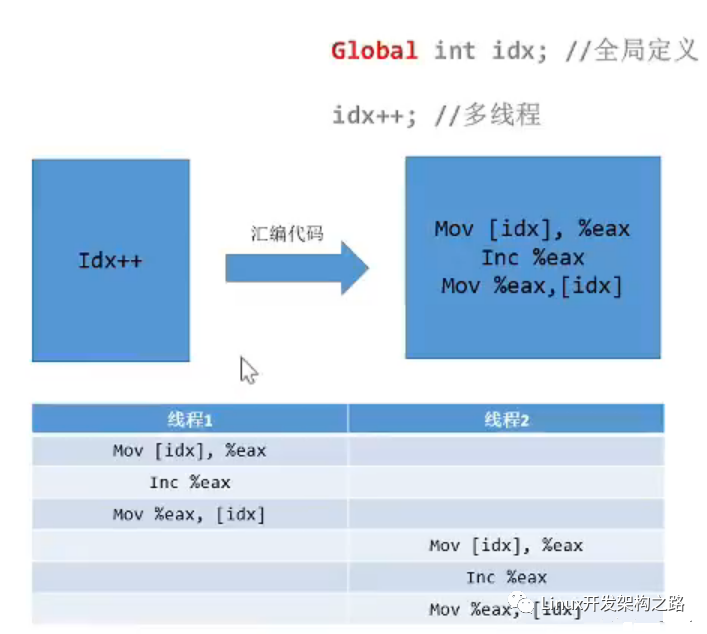
a++; 或者 a += 1; 這些操作的匯編操作是幾個步驟?
其實是三個步驟:
- 將數據從內存讀取到寄存器中
- 在寄存器中進行對應的運算
- 將數據運算結果從寄存器寫回內存
正常情況下,數據少,操作的線程少,問題倒是不大,想一想要是這樣的情況下,操作次數大,對齊操作的線程多,有些線程從中間切入進來了,在運算之后還沒寫回內存就另外一個線程切入進來同時對于之前的數據進行++ 再寫回內存, 啥效果,多次++ 操作之后結果確實一次加加操作后的結果。 這樣的操作 (術語叫做函數的重入) 我覺得其實就是重入到了匯編指令中間了,還沒將上一次運算的結果寫回內存就重新對這個內存讀取再運算寫入,結果肯定和正常的邏輯后的結果不一樣呀
來一幅圖片解釋一下
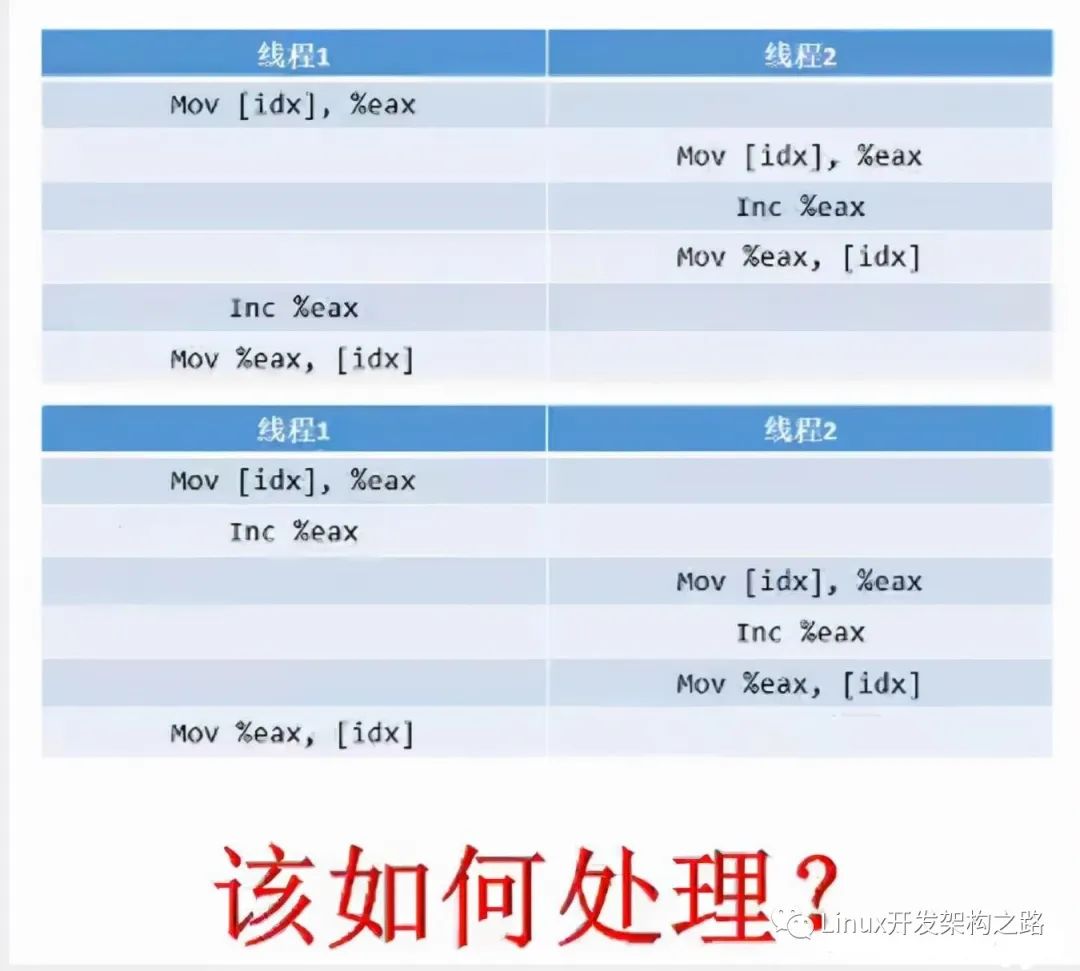
咋辦? 其實問題很清楚,我們只需要處理的是多條匯編指令不能讓它中間被插入其他的線程運算. (要想自己在執行匯編指令的時候別人不插入進來) 將多條匯編指令綁定成為一條指令不就OK了嘛。
也就是原子操作!!!
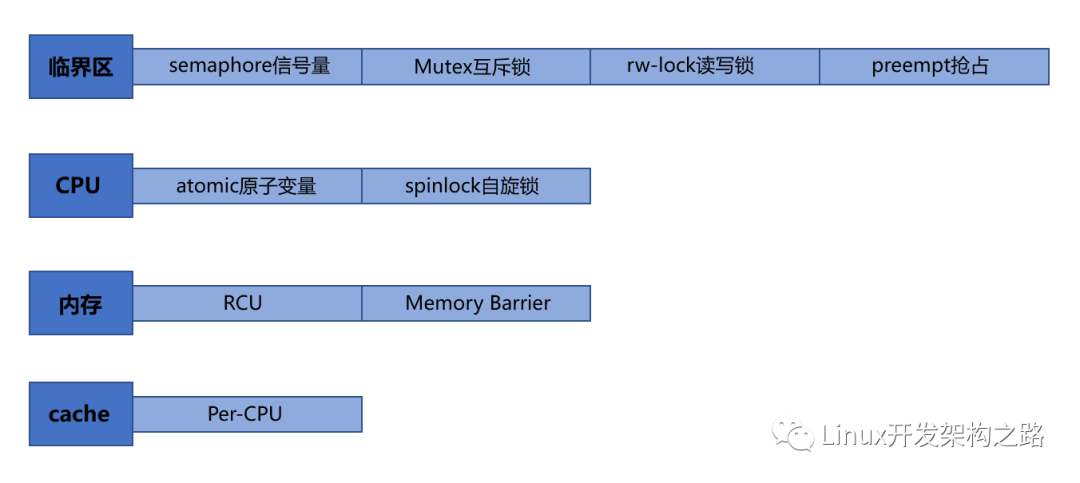
不會原子操作?操作系統給咱提供了線程的 綁定方式工具呀:mutex 互斥鎖(互斥量), 自旋鎖(spinlock), 讀寫鎖(readers-writer lock) 他們也稱作悲觀鎖. 作用都是一個樣,將多個匯編指令鎖成為一條原子操作 (此處的匯編指令也相當于如下的臨界資源)
悲觀鎖:鎖如其名,每次都悲觀地認為其他線程也會來修改數據,進行寫入操作,所以會在取數據前先加鎖保護,當其他線程想要訪問數據時,被阻塞掛起
樂觀鎖:每次取數據的時候,總是樂觀地認為數據不會被其他線程修改,因此不上鎖。但是在更新數據前, 會判斷其他數據在更新前有沒有對數據進行修改。
互斥鎖
最為常見使用地鎖就是互斥鎖, 也稱互斥量. mutex
特征,當其他線程持有互斥鎖對臨界資源做寫入操作地時候,當前線程只能掛起等待,讓出CPU,存在線程間切換工作
解釋一下存在線程間切換工作 : 當線程試圖去獲取鎖對臨界資源做寫入操作時候,如果鎖被別的線程正在持有,該線程會保存上下文直接掛起,讓出CPU,等到鎖被釋放出來再進行線程間切換,從新持有CPU執行寫入操作
互斥鎖需要進行線程間切換,相比自旋鎖而言性能會差上許多,因為自旋鎖不會讓出CPU, 也就不需要進行線程間切換的步驟,具體原理下一點詳述

#include < stdio.h >
#include < stdlib.h >
#include < unistd.h >
#include < sys/types.h >
#include < pthread.h >
pthread_mutex_t mtx;
void* Routine(void* arg) {
int *pcount = (int*)arg;
for (int i = 0; i < 20000000; ++i) {
pthread_mutex_lock(&mtx);
(*pcount)++;
pthread_mutex_unlock(&mtx);
}
return (void*)0;
}
int main() {
pthread_mutex_init(&mtx, NULL);
int count = 0;
pthread_t tid1, tid2, tid3;
pthread_create(&tid1, NULL, Routine, (void*)&count);
pthread_create(&tid2, NULL, Routine, (void*)&count);
pthread_create(&tid3, NULL, Routine, (void*)&count);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
//看一看結果
printf("count: %dn", count);
pthread_mutex_destroy(&mtx);//銷毀鎖
return 0;
}

加互斥量(互斥鎖)確實可以達到要求,但是會發現運行時間非常的長,因為線程間不斷地切換也需要時間, 線程間切換的代價比較大.
自旋鎖
spinlock.自旋鎖.
對比互斥量(互斥鎖)而言,獲取自旋鎖不需要進行線程間切換,如果自旋鎖正在被別的線程占用,該線程也不會放棄CPU進行掛起休眠,而是恰如其名的在哪里不斷地循環地查看自旋鎖保持者(持有者)是否將自旋鎖資源釋放出來... (自旋地原來就是如此)
口語解釋自旋:持有自旋鎖的線程不釋放自旋鎖,那也沒有關系呀,我就在這里不斷地一遍又一遍地查詢自旋鎖是否釋放出來,一旦釋放出來我立馬就可以直接使用 (因為我并沒有掛起等待,不需要像互斥鎖還需要進行線程間切換,重新獲取CPU,保存恢復上下文等等操作)
哪正是因為上述這些特點,線程嘗試獲取自旋鎖,獲取不到不會采取休眠掛起地方式,而是原地自旋(一遍又一遍查詢自旋鎖是否可以獲取)效率是遠高于互斥鎖了. 那我們是不是所有情況都使用自旋鎖就行了呢,互斥鎖就可以放棄使用了嗎????
解釋自旋鎖地弊端:如果每一個線程都僅僅只是需要短時間獲取這個鎖,那我自旋占據CPU等待是沒啥問題地。要是線程需要長時間地使用占據(鎖)。。。 會造成過多地無端占據CPU資源,俗稱站著茅坑不拉屎... 但是要是僅僅是短時間地自旋,平衡CPU利用率 + 程序運行效率 (自旋鎖確實是在有些時候更加合適)
自旋鎖需要場景:內核可搶占或者SMP(多處理器)情況下才真正需求 (避免死鎖陷入死循環,瘋狂地自旋,比如遞歸獲取自旋鎖. 你獲取了還要獲取,但是又沒法釋放)
自旋鎖的使用函數其實和互斥鎖幾乎是一摸一樣地,僅僅只是需要將所有的mutex換成spin即可
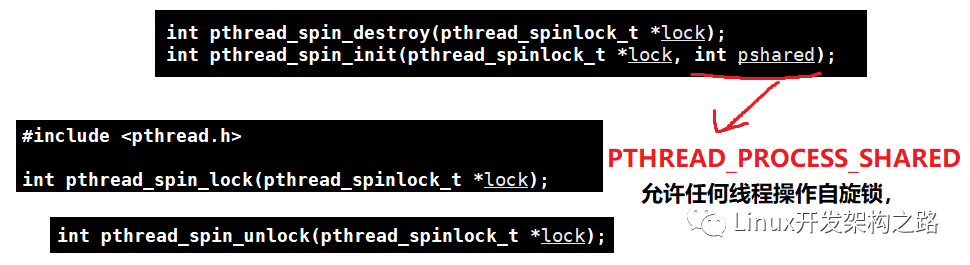
僅僅只是在init存在些許不同
#include < stdio.h >
#include < stdlib.h >
#include < unistd.h >
#include < sys/types.h >
#include < pthread.h >
pthread_spinlock_t mtx;
void* Routine(void* arg) {
int *pcount = (int*)arg;
for (int i = 0; i < 20000000; ++i) {
pthread_spin_lock(&mtx);
(*pcount)++;
pthread_spin_unlock(&mtx);
}
return (void*)0;
}
int main() {
pthread_spin_init(&mtx, PTHREAD_PROCESS_SHARED);
int count = 0;
pthread_t tid1, tid2, tid3;
pthread_create(&tid1, NULL, Routine, (void*)&count);
pthread_create(&tid2, NULL, Routine, (void*)&count);
pthread_create(&tid3, NULL, Routine, (void*)&count);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
//看一看結果
printf("count: %dn", count);
pthread_spin_destroy(&mtx);//銷毀鎖
return 0;
}
- 解決上述地問題地方式二, 不是使用std=c99 而是直接將 int i 放置到for循環外面
- 讀寫鎖 + 讀者寫者模式:
- 主要是處理讀多寫少地情況,和本文后序關聯不大,需要的可自行查閱了解
二.epoll驚群問題地理解
何為驚群,池塘一堆, 我瞄準一條插過去,但是好似所有的都像是覺著自己正在被插一樣的四處逃竄。 這個就是驚群的生活一點的理解
驚群現象其實一點也不少,比如說 accept pthread_cond_broadcast 還有多個線程共享epoll監視一個listenfd 然后此刻 listenfd 說來 SYN了,放在了SYN隊列中,然后完成了三次握手放在了 accept隊列中了, 現在問題是這個connect我應該交付給哪一個線程處理呢.
多個epoll監視準備工作的線程 就是這群 (),然后connet就是魚叉,這一叉下去肯定是所有的 epoll線程都會被驚醒 (多線程共享listenfd引發的epoll驚群)
同樣如果將上述的多個線程換成多個進程共享監視 同一個 listenfd 就是(多進程的epoll驚群現象)
咱再畫一個草圖再來理解一下這個驚群:
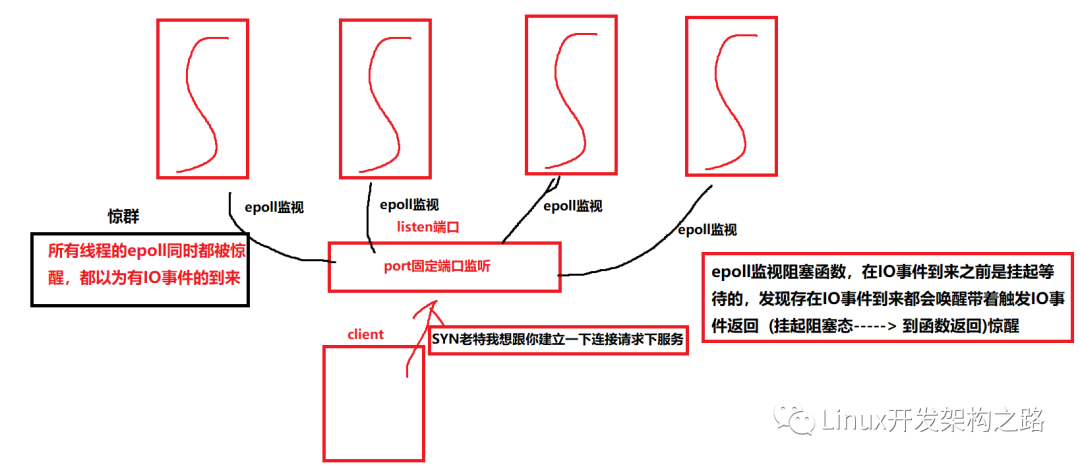
如果是多進程道理是一樣滴,僅僅只是將所有的線程換成進程就OK了
三. epoll驚群問題地解決
終是來到了今天的正題了: epoll驚群問題地解決上面了...
首先 先說說accept的驚群問題,沒想到吧accept 平時大家寫它的多線程地時候,多個線程同時accept同一個listensock地時候也是會存在驚群問題地,但是accept地驚群問題已經被Linux內核處理了: 當有新的連接進入到accept隊列的時候,內核喚醒且僅喚醒一個進程來處理
但是對于epoll的驚群問題,內核卻沒有直接進行處理。哪既然內核沒有直接幫我們處理,我們應該如何針對這種現象做出一定的措施呢?
驚群效應帶來的弊端: 驚群現象會造成epoll的偽喚醒,本來epoll是阻塞掛起等待著地,這個時候因為掛起等待是不會占用CPU地。。。 但是一旦喚醒就會占用CPU去處理發生地IO事件, 但是其實是一個偽喚醒,這個就是對于線程或者進程的無效調度。然而進程或者線程地調取是需要花費代價地,需要上下文切換。需要進行進程(線程)間的不斷切換... 本來多核CPU是用來支持高并發地,但是現在卻被用來無效地喚醒,對于多核CPU簡直就是一種浪費 (浪費系統資源) 還會影響系統的性能.
解決方式(一般是兩種)
Nginx的解決方式:
加鎖:驚群問題發生的前提是多個進程(線程)監聽同一個套接字(listensock)上的事件,所以我們只讓一個進程(線程)去處理監聽套接字就可以了。
// 是否開啟 accept 鎖,
// 開啟則需要搶鎖,以防驚群,默認是關閉的。
if (ngx_use_accept_mutex) {
if (ngx_accept_disabled > 0) {
// ngx_accept_disabled 的值是經過算法計算出來的,
// 當值大于 0 時,說明此進程負載過高,不再接收新連接。
ngx_accept_disabled--;
} else {
// 嘗試搶 accept 鎖,發生錯誤直接返回
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
// 搶到鎖,設置事件處理標識,后續事件先暫存隊列中。
flags |= NGX_POST_EVENTS;
} else {
// 未搶到鎖,修改阻塞等待時間,使得下一次搶鎖不會等待太久
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
}
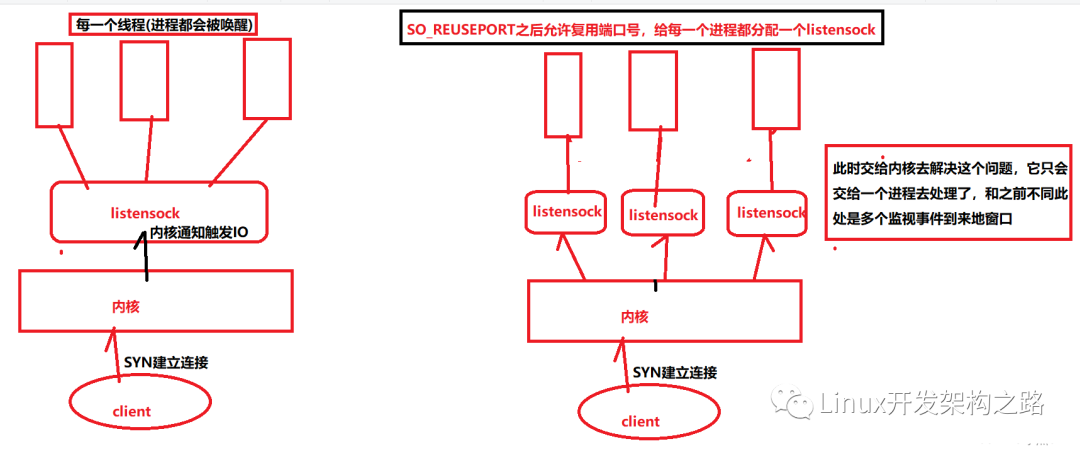
方式2:使用 設置SO_REUSEPORT:使得端口號可以復用, 如此多個進程或者線程便可以綁定同一個端口號了 這樣相當于是每一個進程或線程都監視一個listensock
畫兩張圖來理解一下:
四、代碼演示:
#include < stdio.h >
#include < sys/epoll.h >
#include < stdlib.h >
#include < unistd.h >
#include < sys/socket.h >
#include < string.h >
#include < arpa/inet.h >
#include < pthread.h >
#include < sys/types.h >
#include < fcntl.h >
typedef struct sockaddr SA;
#define CLIENTSIZE 1000
#define BUFFSIZE 256
#define SERVE_PORT 8080
#define ERR_EXIT(m)
do { perror(m); close(EXIT_FAILURE); } while(0)
int CreateSocket() {
int listensock = socket(AF_INET, SOCK_STREAM, 0);
int reuseport = 1;
if (-1 == setsockopt(listensock, SOL_SOCKET, SO_REUSEPORT, &reuseport, sizeof(reuseport))) {
ERR_EXIT("setsocketopt");
}
struct sockaddr_in serveAdd;
//確定服務端協議地址簇
memset(&serveAdd, 0, sizeof(serveAdd));//清空
serveAdd.sin_family = AF_INET;
serveAdd.sin_addr.s_addr = htonl(INADDR_ANY);//其實就是0.0.0.0 通配地址
serveAdd.sin_port = htons(SERVE_PORT);
if (-1 == bind(listensock, (SA*)&serveAdd, sizeof(serveAdd))) {
ERR_EXIT("bind");
}
if (-1 == listen(listensock, 5)) {
ERR_EXIT("listen");
}
return listensock;
}
void setnoblock(int fd) {
int oldflag;
oldflag = fcntl(fd, F_GETFL); //獲取flag
if (-1 == fcntl(fd, F_SETFL, oldflag | O_NONBLOCK)) {
ERR_EXIT("fcnl");
}
}
//像epfd中增加監視事件,將監視事件掛在到紅黑樹上
void addfd(int epfd, int fd) {
struct epoll_event ev;
ev.data.fd = fd;
ev.events = EPOLLIN | EPOLLERR | EPOLLET;
if (-1 == epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev)) {
ERR_EXIT("epoll_ctl");
}
setnoblock(fd);
//設置非阻塞IO,因為是ET
}
void delfd(int epfd, int fd) {
struct epoll_event ev;
if (-1 == epoll_ctl(epfd, EPOLL_CTL_DEL, fd, &ev)) {
ERR_EXIT("epoll_ctl");
}
}
//使用多線程去演示
void* Routine(void* arg) {
struct epoll_event* evs = (struct epoll_event*)calloc(CLIENTSIZE, sizeof(struct epoll_event));
char buff[BUFFSIZE];
//每一個線程都創建一個新地監視窗口,但是其實監視在一個port上
//將問題拋給內核處理,
int listensock = (int)arg;
int epfd = epoll_create(CLIENTSIZE);
int i;
addfd(epfd, listensock);
int count = 1; //記錄監視IO事件地數目
while (1) {//循環監視
int nready = epoll_wait(epfd, evs, count,-1);
printf("tid: %d 線程被喚醒處理IO事件n", pthread_self());
sleep(2000);
for (i = 0; i < nready; ++i) {
if (evs[i].events & EPOLLERR) {
//處理錯誤斷開連接等等操作
} else if ((evs[i].events & EPOLLIN) && evs[i].data.fd == listensock) {
socklen_t clientLen;
struct sockaddr_in clientAdd;
//處理accept操作
int connectsock = accept(listensock, (SA*)&clientAdd, &clientLen);
if (connectsock == -1) {
ERR_EXIT("accept");
}
printf("accept sucess and fd is %dn", connectsock);
//增加監視事件
addfd(epfd, connectsock);
} else if (evs[i].events & EPOLLIN) {
//read
//decode
//compute
//encode
//修改成監視寫事件
} else if (evs[i].events & EPOLLOUT) {
//write
//改成讀事件
}
}
}
free(evs); //釋放資源
}
int main() {
pthread_t tid;
int i;
//此處顯示多個線程共享一個listensock 看看效果
int listensock = CreateSocket();
for (i = 0; i < 10; ++i) { //簡單地開十個線程
//int listensock = CreateSocket();
pthread_create(&tid, NULL, Routine, (void*)listensock);
pthread_detach(tid);//分離線程
}
while (1); //主線程等待子線程結束
return 0;
}
上述還沒有進行一個每一個進程都對應一個listensock 而是多線程共享一個listensock 運行結果如下
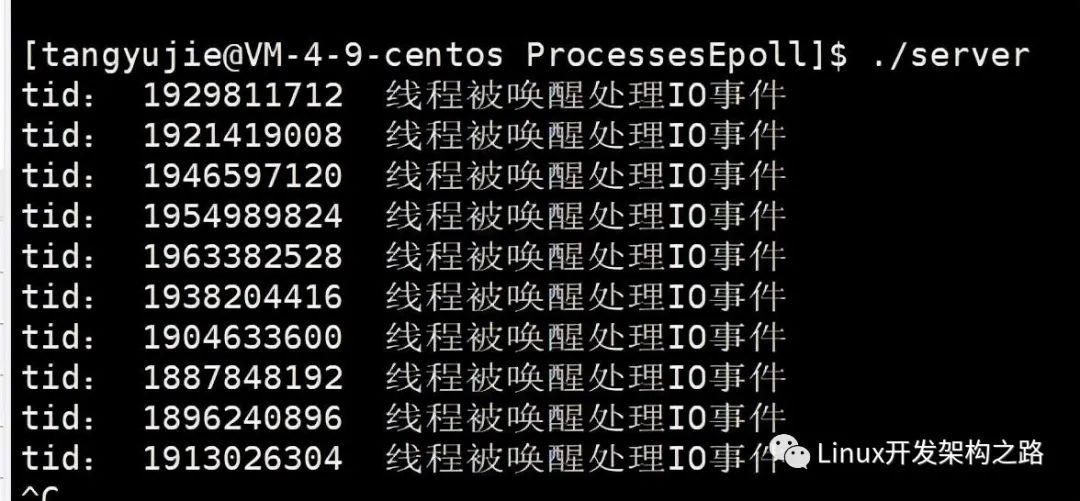
所有的線程同時被喚醒了,但是實際上會處理連接的僅僅只是一個線程,
int main() {
pthread_t tid;
int i;
//int listensock = CreateSocket();
for (i = 0; i < 10; ++i) { //簡單地開十個線程
int listensock = CreateSocket();
pthread_create(&tid, NULL, Routine, (void*)listensock);
pthread_detach(tid);//分離線程
}
while (1); //主線程等待子線程結束
return 0;
}
咱僅僅只是將主線程做如上這樣一個簡單的修改,每一個線程對應一個listensock;每一個線程一個獨有的監視窗口,將問題拋給內核去處理,讓內核去負載均衡 : 結果如下

僅僅喚醒一個線程來進行處理連接,解決了驚群問題
五. 總結本章:
本文通過介紹兩種鎖入手,以及為什么需要鎖,鎖本質就是為了保護,持有鎖你就有權力有能力操作寫入一定的臨界保護資源,沒有鎖你就不行需要等待,本質其實是將多條匯編指令綁定成原子操作
然后介紹了驚群現象,通過一個巧妙地例子,扔一顆石子,只是瞄準一條魚扔過去了,但是整池魚都被驚醒了,
對應我們地實際問題就是, 多個線程或者進程共同監視同一個listensock。。。。然后IO連接事件到來地時候本來僅僅只是需要一個線程醒過來處理即可,但是卻會使得所有地線程(進程)全部醒過來,造成不必要地進程線程間切換,多核CPU被浪費喔,系統資源被浪費
處理方式 一。 Nginx 源碼加互斥鎖處理。。 二。設置SO_REUSEPORT, 使得多個進程線程可以同時連接同一個port , 為每一個進程線程搞一個listensock... 將問題拋給內核去處理,讓他去負載均衡地僅僅將IO連接事件分配給一個進程或線程
-
寄存器
+關注
關注
31文章
5357瀏覽量
120619 -
Linux
+關注
關注
87文章
11316瀏覽量
209812 -
多線程
+關注
關注
0文章
278瀏覽量
20016 -
代碼
+關注
關注
30文章
4798瀏覽量
68728
發布評論請先 登錄
相關推薦
Linux讀寫鎖邏輯解析—Linux為何會引入讀寫鎖?
linux下各種格式的壓縮包的解壓方法總結
Linux下多線程編程總結
LINUX系統教程之如何在Linux系統下進行編程

ADC的各種指標如何理解如何提高ADC轉換精度
如何理解Linux的工作原理

Go語言sync包中的鎖都在什么場景下用
嵌入式linux報警,嵌入式Linux下LED報警燈驅動設計及編程.doc

Linux中的傷害/等待互斥鎖介紹
介紹一下Linux內核中的各種鎖
Linux實例:多線程和互斥鎖到底該如何使用
Linux內核中的各種鎖介紹





 工商網監
工商網監
評論