 為什么要有TIME_WAIT狀態
為什么要有TIME_WAIT狀態
TCP的新建連接,斷開連接的流程和各個狀態,如下圖所示
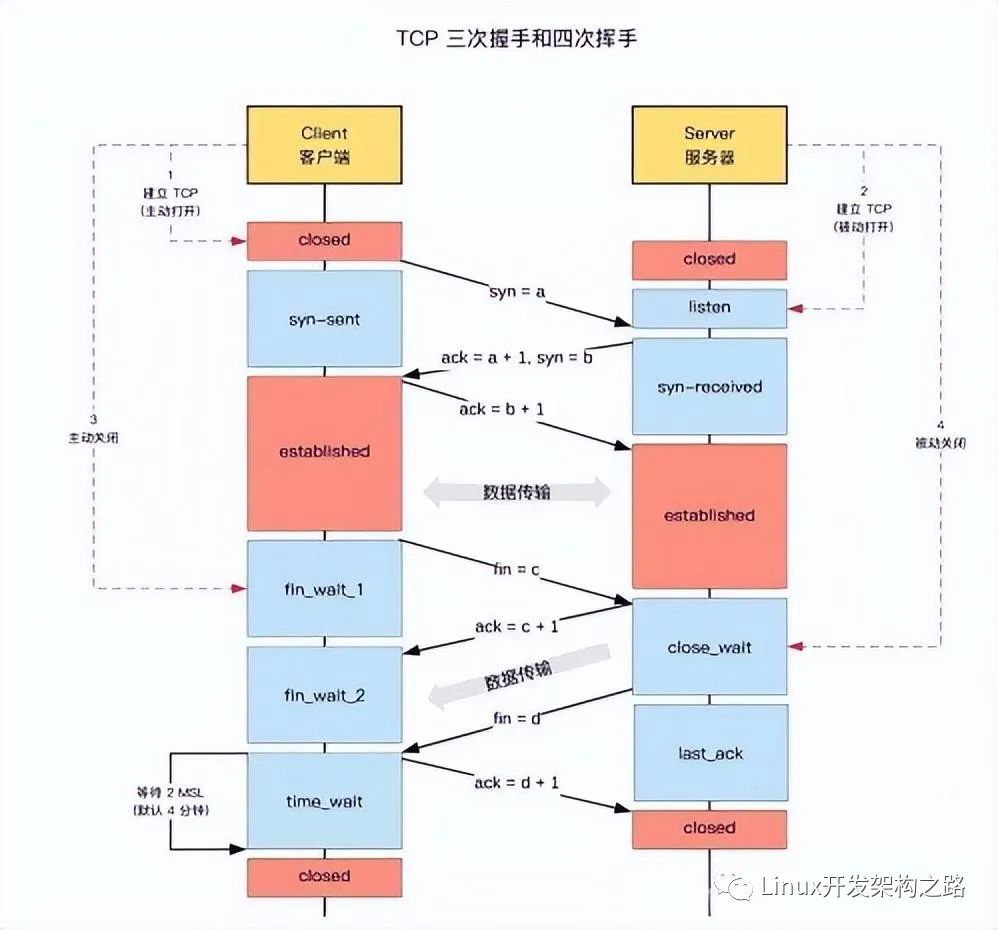
由上圖可知:TIME_WAIT 是主動斷開連接的一方會出現的,客戶端,服務器都有可能出現
當客戶端主動斷開連接時,發出最后一個ACK后就會處于 TIME_WAIT狀態
當服務器主動斷開連接時,發出最后一個ACK后就會處于 TIME_WAIT狀態
結論:TIME_WAIT 是必然會出現的狀態,是正常現象,且會定時回收
TIME_WAIT 狀態持續2MSL時間,MSL就是maximum segment lifetime(最大報文段的生命期),這是一個IP數據包能在互聯網上生存的最長時間,超過這個時間將在網絡中消失(被丟棄)。RFC 793中規定MSL為2分鐘,實際應用中,可能為30S,1分鐘,2分鐘。
我的系統是ubuntu,輸入如下命令后可以看到,時間為60秒

請注意兩個狀態,一個是TIME_WAIT,一個是CLOSE_WAIT,完全不同的兩個狀態
TIME_WAIT 出現在主動斷開方,發出最后一個ACK后
CLOSE_WAIT 出現在被動斷開方,收到主動斷開方的FIN,發出自己的ACK后
問題:為什么要有TIME_WAIT狀態?
- 為了可靠地關閉TCP連接
舉例:我們把主動斷開連接的一方稱為C端,被動斷開連接的一方稱為S端,由于網絡不可靠,C端發送的最后一個ACK報文可能沒成功發送到S端,那么S端就會重新發上一個報文即FIN,如果C端處于TIME_WAIT狀態下,就可以重新發送報文ACK,然后重新計時2MSL時間才會進入CLOSED狀態,S端收到ACK后就可以正常關閉TCP連接了。反之,如果這時C端處于 CLOSED 狀態 ,就會響應 RST報文而不是ACK報文,那S端會認為這是一個錯誤,只能異常關閉TCP連接
- 防止上一次連接中的包,迷路后重新出現,影響新連接
由于網絡的不可靠,TCP分節可能因為路由器異常而“迷途”,在迷途期間,TCP發送端會因確認超時而重發這個分節,這個分節最終被發送到對方時,對方可能已經是一個新的連接了,由此造成混亂。舉例:關閉一個TCP鏈接后,馬上又創建了一個相同的IP地址和端口之間的TCP鏈接,后一個鏈接被稱為前一個鏈接的化身(incarnation),那么此時有可能出現這種狀況,前一個鏈接的迷途重復分節在前一個鏈接終止后出現了,從而被誤解成從屬于新的連接的數據。為了不出現這種混亂,TCP不容許處于TIME_WAIT狀態的連接立即啟動一個新連接,由于TIME_WAIT狀態持續2MSL,就能夠保證當成功創建一個TCP鏈接的時候,來自前一個連接的迷途重復分節已經在網絡中消逝
注意close() 和 shutdown()的區別
close()其實只是將socket fd的引用計數減1,只有當該socket fd的引用計數減至0時,TCP傳輸層才會發起4次握手從而真正關閉連接。而shutdown則可以直接發起關閉連接所需的4次握手,而不用受到引用計數的限制
close()會終止TCP的雙工鏈路。由于TCP連接的全雙工特性,可能會存在這樣的應用場景:local peer不會再向remote peer發送數據,而remote peer可能還有數據需要發送過來,在這種情況下,如果local peer想要通知remote peer自己不會再發送數據但還會繼續收數據這個事實,用close()是不行的,而shutdown()可以完成這個任務
服務器短時間內大量的TIME_WAIT出現,才是問題
會引發以下問題
- 由于處于TIME_WAIT狀態,連接并未關閉,占據了大量的CPU,內存,文件描述符等,造成新的連接無法建立,客戶端表現就是連接失敗
- 如果服務器上同時有nginx,且nginx由于反向代理,那么還會占用很多端口(S端處于TIME_WAIT,該連接的另一方即C端需獨占一個端口,C端是由nginx代理建立的),要知道端口是有限的,最多65535,一旦端口占用完,無論服務器配置如何高,新連接都無法建立了,客戶端表現仍然是連接失敗
短時間內大量TIME_WAIT出現的根本原因:高并發且持續的短連接
- 業務上使用了持續且大量的短連接,純屬設計缺陷,例如爬蟲服務器就有可能出現這樣的問題
- http請求中connection的值被設置成close,因為服務器處理完http請求后會主動斷開連接,然后這個連接就處于TIME_WAIT狀態了。持續時間長且量級較大的話,問題就顯現出來了。http洗衣1.0中,connection默認為close,但在http1.1中connection默認行為是keep-alive,就是因為這個原因
- 服務器被攻擊了,攻擊方采用了大量的短連接
重點:解決辦法
- 代碼層修改,把短連接改為長連接,但代價較大
- 修改 ip_local_port_range,增大可用端口范圍,比如1024 ~ 65535
- 客戶端程序中設置socket的 SO_LINGER 選項
- 打開 tcp_tw_recycle 和tcp_timestamps 選項,有一定風險,且linux4.12之后被廢棄
- 打開 tcp_tw_reuse 和 tcp_timestamps 選項
- 設置 tcp_max_tw_buckets 為一個較小的值
下面我們開始對各個辦法進行詳細講解
辦法1:代碼層修改,把短連接改為長連接
由于TIME_WAIT出現的根本原因是高并發且持續的短連接,所以如果能把短連接改成長連接,就能徹底解決問題。比如http請求中的connection設置為keep-alive。只是代碼層的修改往往會比較大,不再啰嗦
辦法2. 修改 ip_local_port_range,增大可用端口范圍
我這里linux系統是ubuntu,輸入如下命令可查看可用的端口范圍
默認差不多有3萬個,我們可以修改這個值,但是注意最小不能小于1024,最大不能大于65535,也就是說改完之后最多有6萬多個可用端口
只是一般線上遇到大量的TIME_WAIT,都是高并發且持續的短連接,單純擴大端口范圍并不能從根本上解決問題,只是能多撐一會兒
辦法3. 客戶端程序中設置socket的 SO_LINGER 選項
SO_LINGER 選項可以用來控制調用close函數關閉連接后的行為,linger的定義如下
struct linger {
int l_onoff; /* 0 = off, nozero = on */
int l_linger; /* linger time */
有三種情況
- 設置 l_onoff 為0,l_linger的值會被忽略,也是內核缺省的情況,和不設置沒區別。close調用會立即返回給調用者,TCP模塊負責嘗試發送殘留的緩沖區數據,會經過通常四分組終止序列(FIN/ACK/FIN/ACK),不能解決任何問題
- 設置 l_onoff 為1,l_linger為0,則連接立即終止,TCP將丟棄殘留在發送緩沖區中的任何數據并發送一個RST報文給對方,而不是通常的四分組終止序列。對方收到RST報文后直接進入CLOSED狀態,從根本上避免了TIME_WAIT狀態
- 設置 l_onoff 為1,l_linger > 0,有兩種情況
a. 如果socket為阻塞的,則close將阻塞等待l_linger 秒的時間。如果在l_linger秒時間內TCP模塊成功發送完殘留在緩沖區的數據,則close返回0,表示成功。如果l_linger時間內TCP模塊沒有成功發送殘留的緩沖區數據,則close返回-1,表示失敗,并將errno設置為EWOULDBLOCK
b. 如果socket為非阻塞的,那么close立即返回,此時需要根據close返回值以及errno來判斷TCP模塊是否成功發送殘留在緩沖區的數據
第3中情況,其實就是第1種和第2種的折中處理,且當socket為非阻塞的場景下是沒有作用的
綜上所述:第2種情況,也就是l_onoff為1,l_linger不為0,可以用于解決服務器大量TIME_WAIT的問題
只是Linux上測試的時候,并未發現發送了RST報文,而是正常進行了四步關閉流程,
初步推斷是“只有在丟棄數據的時候才發送RST”,如果沒有丟棄數據,則走正常的關閉流程
查看Linux源碼,確實有這么一段注釋和源碼
/* As outlined in RFC 2525, section 2.17, we send a RST here because
* data was lost. To witness the awful effects of the old behavior of
* always doing a FIN, run an older 2.1.x kernel or 2.0.x, start a bulk
* GET in an FTP client, suspend the process, wait for the client to
* advertise a zero window, then kill -9 the FTP client, wheee...
* Note: timeout is always zero in such a case.
*/
if (data_was_unread) {
/* Unread data was tossed, zap the connection. */
NET_INC_STATS_USER(sock_net(sk), LINUX_MIB_TCPABORTONCLOSE);
tcp_set_state(sk, TCP_CLOSE);
tcp_send_active_reset(sk, sk- >sk_allocation);
}
從原理上來說,這個選項有一定的危險性,可能導致丟數據,使用的時候要小心一些
從實測情況來看,打開這個選項后,服務器TIME_WAIT連接數為0,且不受網絡組網(例如是否虛擬機等)的影響
辦法4. 打開 tcp_tw_recycle 和tcp_timestamps 選項,有一定風險,且linux4.12之后被廢棄
官方文檔中解釋如下:
tcp_tw_recycle 選項作用為:Enable fast recycling TIME-WAIT sockets. Default value is 0.
tcp_timestamps 選項作用為:Enable timestamps as defined in RFC1323. Default value is 1
這兩個選項是linux內核提供的控制選項,和具體的應用程序沒有關系,而且網上也能夠查詢到大量的相關資料,但信息都不夠完整,最主要的幾個問題如下;
1)快速回收到底有多快?
2)有的資料說只要打開tcp_tw_recycle即可,有的又說要tcp_timestamps同時打開,到底是哪個正確?
3)為什么從虛擬機NAT出去發起客戶端連接時選項無效,非虛擬機連接就有效?為了搞清楚上面的疑問,只能看代碼,看出一些相關的代碼供大家參考:
=====linux-2.6.37 net/ipv4/tcp_minisocks.c 269======
void tcp_time_wait(struct sock *sk, int state, int timeo)
{
struct inet_timewait_sock *tw = NULL;
const struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcp_sock *tp = tcp_sk(sk);
int recycle_ok = 0;
// 判斷是否快速回收,這里可以看出tcp_tw_recycle和tcp_timestamps兩個選項都打開的時候才進行快速回收,
//且還有進一步的判斷條件,后面會分析,這個進一步的判斷條件和第三個問題有關
if (tcp_death_row.sysctl_tw_recycle && tp- >rx_opt.ts_recent_stamp)
recycle_ok = icsk- >icsk_af_ops- >remember_stamp(sk);
if (tcp_death_row.tw_count < tcp_death_row.sysctl_max_tw_buckets)
tw = inet_twsk_alloc(sk, state);
if (tw != NULL) {
struct tcp_timewait_sock *tcptw = tcp_twsk((struct sock *)tw);
//計算快速回收的時間,等于 RTO * 3.5,回答第一個問題的關鍵是RTO(RetransmissionTimeout)大概是多少
const int rto = (icsk- >icsk_rto < < 2) - (icsk- >icsk_rto > > 1);
//。。。。。。此處省略很多代碼。。。。。。
if (recycle_ok)
{
//設置快速回收的時間
tw- >tw_timeout = rto;
}
else
{
tw- >tw_timeout = TCP_TIMEWAIT_LEN;
if (state == TCP_TIME_WAIT)
timeo = TCP_TIMEWAIT_LEN;
}
//。。。。。。此處省略很多代碼。。。。。。
}
這里講下RTO(Retransmission Time Out):重傳超時時間,即從數據發送時刻算起,超過這個時間便執行重傳
RFC中有關于RTO計算的詳細規定,一共有三個:RFC-793、RFC-2988、RFC-6298,Linux的實現是參考RFC-2988。
對于這些算法的規定和Linux的實現,有興趣的同學可以自己深入研究,實際應用中我們只要記住Linux如下兩個邊界值:
=====linux-2.6.37 net/ipv4/tcp.c 126================
#define TCP_RTO_MAX ((unsigned)(120*HZ))
#define TCP_RTO_MIN ((unsigned)(HZ/5))
==========================================
這里的HZ是1s,因此可以得出RTO最大是120s,最小是200ms,對于局域網的機器來說,正常情況下RTO基本上就是200ms,因此3.5 RTO就是700ms
也就是說,快速回收是TIME_WAIT的狀態持續700ms,而不是正常的2MSL
實測結果也驗證了這個推論,不停的查看TIME_WAIT狀態的連接,偶爾能看到1個
最后一個問題是為什么從虛擬機發起的連接即使設置了tcp_tw_recycle和tcp_timestamps,也不會快速回收,繼續看代碼:
tcp_time_wait函數中的代碼行:recycle_ok = icsk->icsk_af_ops->remember_stamp(sk);對應的實現如下:
=====linux-2.6.37 net/ipv4/tcp_ipv4.c 1772=====
int tcp_v4_remember_stamp(struct sock *sk)
{
//。。。。。。此處省略很多代碼。。。。。。
//當獲取對端信息時,進行快速回收,否則不進行快速回收
if (peer)
{
if ((s32)(peer- >tcp_ts - tp- >rx_opt.ts_recent) <= 0 ||
((u32)get_seconds() - peer- >tcp_ts_stamp > TCP_PAWS_MSL &&
peer- >tcp_ts_stamp <= (u32)tp- >rx_opt.ts_recent_stamp))
{
peer- >tcp_ts_stamp = (u32)tp- >rx_opt.ts_recent_stamp;
peer- >tcp_ts = tp- >rx_opt.ts_recent;
}
if (release_it)
inet_putpeer(peer);
return 1;
}
return 0;
}
上面這段代碼應該就是測試的時候虛擬機環境不會釋放的原因,當使用虛擬機NAT出去的時候,服務器無法獲取隱藏在NAT后的機器信息。
生產環境也出現了設置了選項,但TIME_WAIT連接數達到4W多的現象,可能和虛擬機有關,也可能和組網有關。
總結一下:
1)快速回收到底有多快?
答:局域網環境下,700ms就回收
2)有的資料說只要打開tcp_tw_recycle即可,有的又說要tcp_timestamps同時打開,到底是哪個正確?
答:需要同時打開,但默認情況下tcp_timestamps就是打開的,所以會有人說只要打開tcp_tw_recycle即可
3)為什么從虛擬機發起客戶端連接時選項無效,非虛擬機連接就有效?
答:和網絡組網有關系,無法獲取對端信息時就不進行快速回收。
注意1
NAT環境下,打開 tcp_tw_recycle選項可能會引發其他問題,tcp_tw_recycle是依賴tcp_timestamps參數的。例如辦公室的外網地址只有一個,所有人訪問后臺都會通過路由器做SNAT將內網地址映射為公網IP,由于服務端和客戶端都啟用了tcp_timestamps,因此TCP頭部中增加時間戳信息,而在服務器看來,同一客戶端的時間戳必然是線性增長的,但是,由于我的客戶端網絡環境是NAT,因此每臺主機的時間戳都是有差異的,在啟用tcp_tw_recycle后,一旦有客戶端斷開連接,服務器可能就會丟棄那些時間戳較小的客戶端的SYN包,這也就導致了網站訪問極不穩定。
簡單來說就是,Linux會丟棄所有來自遠端的timestramp時間戳小于上次記錄的時間戳(由同一個遠端發送的)的任何數據包。也就是說要使用該選項,則必須保證數據包的時間戳是單調遞增的。同時從4.10內核開始,官方修改了時間戳的生成機制,所以導致 tcp_tw_recycle 和新時間戳機制工作在一起不那么友好,同時 tcp_tw_recycle 幫助也不那么的大。
此處的時間戳并不是我們通常意義上面的絕對時間,而是一個相對時間。很多情況下,我們是沒法保證時間戳單調遞增的,比如業務服務器之前部署了NAT,LVS等情況。相信很多小伙伴上班的公司大概率實用實用各種公有云,而各種公有云的 LVS 網關都是 FullNAT 。所以可能導致在高并發的情況下,莫名其妙的 TCP 建聯不是那么順暢或者丟連接
主機A SIP:P1 (時間戳T0) —> Server
主機A斷開后
主機B SIP:P1 (時間戳T1) T1 < T0 —> Server 丟棄
注意2
在linux內核版本從4.12之后,tcp_tw_recycle已經被廢棄了
我的linux機器是ubuntu,查看內核版本如下

linux 內核版本已經4.15了,如果開發tcp_tw_recycle,執行命令刷新的話,就會有如下報錯

提示得很明確,這個文件不存在
sysctl: cannot stat /proc/sys/net/ipv4/tcp_tw_recycle: No such file or directory
綜上
可以看出這種方法不是很保險,在實際應用中可能受到虛擬機、網絡組網、防火墻之類的影響從而導致不能進行快速回收。
辦法5. 打開tcp_tw_reuse和tcp_timestamps選項
官方文檔中解釋如下:
tcp_tw_recycle選項:Allow to reuse TIME-WAIT sockets for new connections when it is
safe from protocol viewpoint. Default value is 0
這里的關鍵在于“協議什么情況下認為是安全的”,由于環境限制,沒有辦法進行驗證,通過看源碼簡單分析了一下
=====linux-2.6.37 net/ipv4/tcp_ipv4.c 114=====
int tcp_twsk_unique(struct sock *sk, struct sock *sktw, void *twp)
{
const struct tcp_timewait_sock *tcptw = tcp_twsk(sktw);
struct tcp_sock *tp = tcp_sk(sk);
/* With PAWS, it is safe from the viewpoint
of data integrity. Even without PAWS it is safe provided sequence
spaces do not overlap i.e. at data rates <= 80Mbit/sec.
Actually, the idea is close to VJ's one, only timestamp cache is
held not per host, but per port pair and TW bucket is used as state
holder.
If TW bucket has been already destroyed we fall back to VJ's scheme
and use initial timestamp retrieved from peer table.
*/
//從代碼來看,tcp_tw_reuse選項和tcp_timestamps選項也必須同時打開;否則tcp_tw_reuse就不起作用
//另外,所謂的“協議安全”,從代碼來看應該是收到最后一個包后超過1s
if (tcptw- >tw_ts_recent_stamp &&
(twp == NULL || (sysctl_tcp_tw_reuse &&
get_seconds() - tcptw- >tw_ts_recent_stamp > 1)))
{
tp- >write_seq = tcptw- >tw_snd_nxt + 65535 + 2;
if (tp- >write_seq == 0)
tp- >write_seq = 1;
tp- >rx_opt.ts_recent = tcptw- >tw_ts_recent;
tp- >rx_opt.ts_recent_stamp = tcptw- >tw_ts_recent_stamp;
sock_hold(sktw);
return 1;
}
return 0;
}
總結一下:
- tcp_tw_reuse選項和tcp_timestamps選項也必須同時打開;
- 重用TIME_WAIT的條件是收到最后一個包后超過1s。
官方手冊有一段警告:
It should not be changed without advice/request of technical experts.
對于大部分局域網或者公司內網應用來說,滿足條件都是沒有問題的,因此官方手冊里面的警告其實也沒那么可怕
辦法6:設置tcp_max_tw_buckets為一個較小的值,要比可用端口范圍小,比如可用端口范圍為6萬,這個值可以設置為5.5萬
tcp_max_tw_buckets - INTEGER
官方文檔解釋如下
Maximal number of timewait sockets held by system simultaneously. If this number is exceeded time-wait socket is immediately destroyed and warning is printed.
翻譯一下:內核持有的狀態為TIME_WAIT的最大連接數。如果超過這個數字,新的TIME_WAIT的連接會被立即銷毀,并打印警告
官方文檔沒有說明默認值,通過幾個系統的簡單驗證,初步確定默認值是180000
源碼如下
void tcp_time_wait(struct sock *sk, int state, int timeo)
{
struct inet_timewait_sock *tw = NULL;
const struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcp_sock *tp = tcp_sk(sk);
int recycle_ok = 0;
if (tcp_death_row.sysctl_tw_recycle && tp- >rx_opt.ts_recent_stamp)
recycle_ok = icsk- >icsk_af_ops- >remember_stamp(sk);
// 這里判斷TIME_WAIT狀態的連接數是否超過上限
if (tcp_death_row.tw_count < tcp_death_row.sysctl_max_tw_buckets)
tw = inet_twsk_alloc(sk, state);
if (tw != NULL)
{
//分配成功,進行TIME_WAIT狀態處理,此處略去很多代碼
}
else
{
//分配失敗,不進行處理,只記錄日志: TCP: time wait bucket table overflow
/* Sorry, if we're out of memory, just CLOSE this
* socket up. We've got bigger problems than
* non-graceful socket closings.
*/
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPTIMEWAITOVERFLOW);
}
tcp_update_metrics(sk);
tcp_done(sk);
}
官方手冊中有一段警告:
This limit exists only to prevent simple DoS attacks, you must not lower the limit artificially,
but rather increase it (probably, after increasing installed memory), if network conditions require more than default value.
基本意思是這個用于防止Dos攻擊,我們不應該人工減少,如果網絡條件需要的話,反而應該增加。
但其實對于我們的局域網或者公司內網應用來說,這個風險并不大。
-
IP
+關注
關注
5文章
1708瀏覽量
149554 -
TCP
+關注
關注
8文章
1353瀏覽量
79077 -
TIME
+關注
關注
0文章
13瀏覽量
14325 -
流程
+關注
關注
0文章
4瀏覽量
3603
發布評論請先 登錄
相關推薦
Java中sleep和wait的區別
CC3200 socket狀態如何查詢?
WEB CLOSE_WAIT socket不釋放如何解決呢
建立時間和保持時間(setup time 和 hold time)
分析在java中sleep和wait的不同
服務器產生大量的TIME_WAIT究竟是因為什么
請問一下RPB是干啥用的
學習Linux命令的正確姿勢

圖解Java多線程中的wait()和notify()方法
KUKA機器人WAIT FOR運用條件
TCP和UDP分別是什么 TCP和UDP協議各有什么特點
TIME_WAIT狀態的優化思路
TIME_WAIT是什么





 工商網監
工商網監
評論