 如何快速分析定位 I/O 性能問題
如何快速分析定位 I/O 性能問題
如何快速分析定位 I/O 性能問題
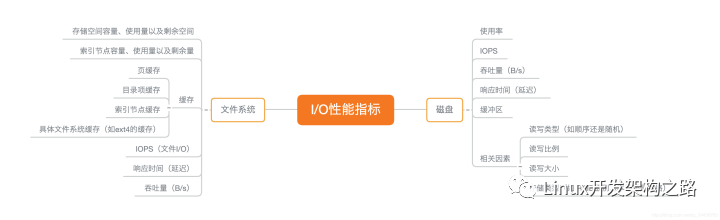
1. 文件系統 I/O性能指標
首先,想到是存儲空間的使用情況,包括容量、使用量、以及剩余空間等。我們通常也稱這些為磁盤空間的用量,但是這只是文件系統向外展示的空間使用,而非在磁盤空間的真實用量,因為文件系統的元數據也會占用磁盤空間。而且,如果你配置了RAID,從文件系統看到的使用量跟實際磁盤的占用空間,也會因為RAID級別不同而不一樣。
除了數據本身的存儲空間,還有一個容易忽略的是索引節點的使用情況,包括容量、使用量、剩余量。如果文件系統小文件數過多,可能會碰到索引節點容量已滿的問題。
其次,緩存使用情況,包括頁緩存、索引節點緩存、目錄項緩存以及各個具體文件系統的緩存。通過使用內存,來臨時緩存文件數據或者文件系統元數據,從而減少磁盤訪問次數。·
最后,文件 I/O的性能指標,包括IOPS(r/s、w/s)、響應時間(延遲)、吞吐量(B/s)等。考察這類指標時,還要結合實際文件讀寫情況,文件大小、數量、I/O類型等,綜合分析文件 I/O 的性能。
2. 磁盤 I/O性能指標
磁盤 I/O的性能指標,主要由四個核心指標:使用率、IOPS、響應時間、吞吐量,還有一個前面提到過,緩沖區。
考察這些指標時,一定要注意綜合 I/O的具體場景來分析,比如讀寫類型(順序讀寫還是隨機讀寫)、讀寫比例、讀寫大小、存儲類型(有無RAID、RAID級別、本地存儲還是網絡存儲)等。
不過考察這些指標時,有一個大忌,就是把不同場景的 I/O指標拿過來作對比。
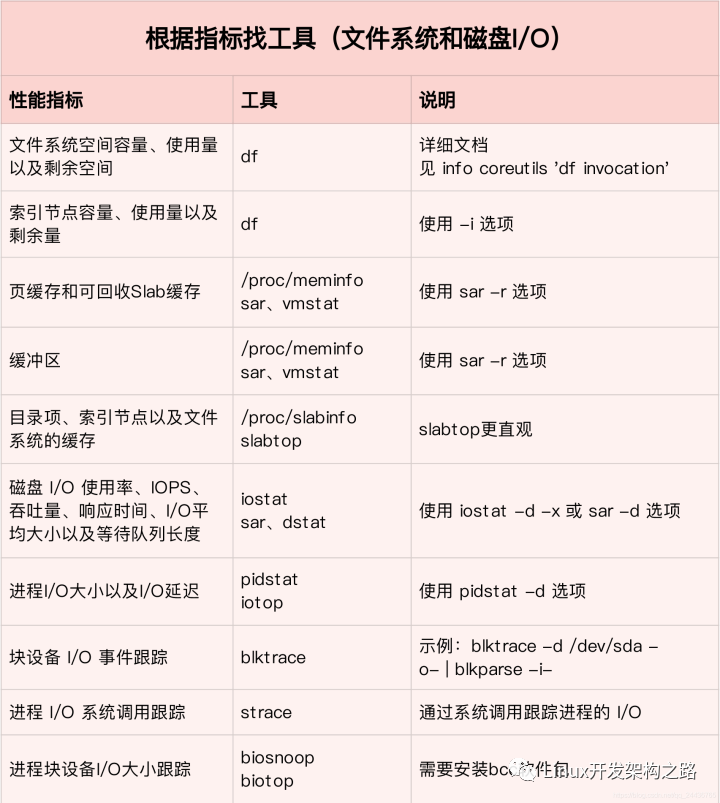
3. 性能工具
二類:/proc/meminfo、/proc/slabinfo、slabtop;
三類:strace、lsof、filetop、opensnoop
4. 性能指標及性能工具之間的關系
5. 如何迅速分析 I/O性能瓶頸
簡單來說,就是找關聯。多種性能指標間,都是存在一定的關聯性。想弄清楚指標之間的關聯性,就要知曉各種指標的工作原理。出現性能問題,基本的分析思路是:
先用 iostat發現磁盤 I/O的性能瓶頸;
再借助 pidstat,定位導致性能瓶頸的進程;
隨后分析進程 I/O的行為;
最后,結合應用程序的原理,分析這些 I/O的來源。
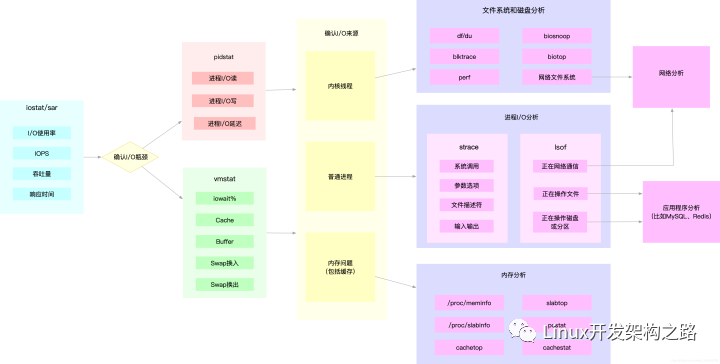
圖中列出最常用的幾個文件系統和磁盤 I/O的性能分析工具,及相應的分析流程。
磁盤 I/O性能優化的幾個思路
1. I/O基準測試
在優化之前,我們要清楚 I/O性能優化的目標是什么?也就是說,我們觀察的這些 I/O指標(IOPS、吞吐量、響應時間等),要達到多少才合適?為了更客觀合理地評估優化效果,首先應該對磁盤和文件系統進行基準測試,得到它們的極限性能。
fio(Flexible I/O Tester),它是常用的文件系統和磁盤 I/O的性能基準測試工具。它提供了大量的可定制化的選項,可以用來測試,裸盤或者文件系統在各種場景下的 I/O性能,包括不同塊大小、不同 I/O引擎以及是否使用緩存等場景。
fio的選項非常多,這里介紹幾個常用的:
# 隨機讀
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 隨機寫
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 順序讀
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 順序寫
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
重點解釋幾個參數:
- direct,是否跳過系統緩存,iodepth1 是跳過。
- iodepth,使用異步 I/O(AIO)時,同時發出的請求上限。
- rw,I/O模式,順序讀 / 寫、隨機讀 / 寫。
- ioengine,I/O引擎,支持同步(sync)、異步(libaio)、內存映射(mmap)、網絡等各種 I/O引擎。
- bs,I/O大小。 4k,默認值。
- filename,文件路徑,可以是磁盤路徑,也可以是文件路徑。不過要注意,用磁盤路徑測試寫,會破壞這個磁盤的文件系統,所以測試前,要注意備份。
下面展示, fio測試順序讀的示例:
read: (g=0): rw=read, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64
fio-3.1
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=16.7MiB/s,w=0KiB/s][r=4280,w=0 IOPS][eta 00m:00s]
read: (groupid=0, jobs=1): err= 0: pid=17966: Sun Dec 30 08:31:48 2018
read: IOPS=4257, BW=16.6MiB/s (17.4MB/s)(1024MiB/61568msec)
slat (usec): min=2, max=2566, avg= 4.29, stdev=21.76
clat (usec): min=228, max=407360, avg=15024.30, stdev=20524.39
lat (usec): min=243, max=407363, avg=15029.12, stdev=20524.26
clat percentiles (usec):
| 1.00th=[ 498], 5.00th=[ 1020], 10.00th=[ 1319], 20.00th=[ 1713],
| 30.00th=[ 1991], 40.00th=[ 2212], 50.00th=[ 2540], 60.00th=[ 2933],
| 70.00th=[ 5407], 80.00th=[ 44303], 90.00th=[ 45351], 95.00th=[ 45876],
| 99.00th=[ 46924], 99.50th=[ 46924], 99.90th=[ 48497], 99.95th=[ 49021],
| 99.99th=[404751]
bw ( KiB/s): min= 8208, max=18832, per=99.85%, avg=17005.35, stdev=998.94, samples=123
iops : min= 2052, max= 4708, avg=4251.30, stdev=249.74, samples=123
lat (usec) : 250=0.01%, 500=1.03%, 750=1.69%, 1000=2.07%
lat (msec) : 2=25.64%, 4=37.58%, 10=2.08%, 20=0.02%, 50=29.86%
lat (msec) : 100=0.01%, 500=0.02%
cpu : usr=1.02%, sys=2.97%, ctx=33312, majf=0, minf=75
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwt: total=262144,0,0, short=0,0,0, dropped=0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: bw=16.6MiB/s (17.4MB/s), 16.6MiB/s-16.6MiB/s (17.4MB/s-17.4MB/s), io=1024MiB (1074MB), run=61568-61568msec
Disk stats (read/write):
sdb: ios=261897/0, merge=0/0, ticks=3912108/0, in_queue=3474336, util=90.09%
這個示例中,重點關注幾行,slat、clat、lat,以及 bw和 iops。前三者,都是指 I/O延遲,但是有不同之處:
slat,是指從 I/O提交到實際執行 I/O的時長;
clat,是指從 I/O提交到 I/O完成的時長;
lat,是指從 fio創建 I/O 到 I/O完成的時長。
這里需要注意的是,對同步 I/O來說,提交和完成是一個動作,slat就是 I/O完成的時間,clat是0;使用異步 I/O時,lat 約等于 slat + clat。
再來看bw,他表示吞吐量,上面的輸出中,平均吞吐量是16MB(17005/1024)。
最后的IOPS,其實是每秒 I/O的次數,上面輸出的平均 IOPS是 4250.
通常情況下,應用程序的IO 讀寫是并行的,每次的 I/O大小也不相同。所以上面的幾個場景并不能精確模擬應用程序的 I/O模式。幸運的是,fio支持 I/O 的重放,需要先用 blktrace,記錄磁盤設備的 I/O訪問情況,再使用 fio,重放 blktrace的記錄。
# 使用blktrace跟蹤磁盤I/O,注意指定應用程序正在操作的磁盤
$ blktrace /dev/sdb
# 查看blktrace記錄的結果
# ls
sdb.blktrace.0 sdb.blktrace.1
# 將結果轉化為二進制文件
$ blkparse sdb -d sdb.bin
# 使用fio重放日志
$ fio --name=replay --filename=/dev/sdb --direct=1 --read_iolog=sdb.bin
2. I/O性能優化思路
應用程序優化
應用程序處于 I/O棧的最上端,可以通過系統調用,來調整 I/O模式(順序還是隨機、同步還是異步),同時也是數據的最終來源。下面總結了幾個方面來優化應用程序性能:
第一,可以用追加寫代替隨機寫,減少尋址開銷,加快 I/O寫的速度。
第二,借助緩存 I/O,充分利用系統緩存,降低實際 I/O的次數。
第三,在應用程序內部構建自己緩存,或者使用Redis這種的外部緩存系統。這樣不僅可以在內部控制緩存的數據和生命周期,而且降低其他應用程序使用緩存對自身的影響。比如,C標準庫,提供的fopen、fread等庫函數,都會利用標準庫緩存,減少磁盤的操作。而如果直接使用open、read等系統調用時,就只能利用操作系統的頁緩存和緩沖區等。
第四,在需要頻繁讀寫同一塊磁盤空間時,可以使用 mmap 代替 read/write,減少內存的拷貝次數。
第五,在需要同步寫的場景中,盡量將寫請求合并,而不是讓每個請求都同步寫磁盤,即可用fsync() 代替 O_SYNC。
第六,在多個應用程序共享相同磁盤時,為了保證 I/O不被某個應用完全占用,推薦使用 cgroups 的 I/O子系統,來限制進程/進程組的 IOPS 以及吞吐量。
最后,在使用CFQ 調度器時,可以用 ionice來調整進程的 I/O調度優先級,特別是提高核心應用的 I/O優先級,他支持三個優先級類:Idle、Best-effort 和 Realtime。其中,后兩者還支持 0-7的級別,數值越小,優先級越高。
文件系統優化
應用程序在訪問普通文件時,是通過文件系統間接負責,文件在磁盤中的讀寫。所以跟文件系統相關的也有很多優化方式。
第一,可以根據實際負載場景的不同,選擇合適的文件系統。比如,Ubuntu默認使用ext4,Centos默認使用 xfs。相比于ext4,xfs支持更大的磁盤分區和更大的文件數量。xfs支持大于 16TB的磁盤,但它的缺點在于無法收縮,而ext4可以。
第二,在選好文件系統后,可以優化文件系統得配置選項。包括文件系統的特性(如 ext_attr、dir_index)、日志模式(如 journal、ordered、writeback等)、掛載選項(如 noatime)等等。比如在使用 tune2fs這個工具,可以調整文件系統的特性,也常用來查看文件系統超級塊的內容。而通過 /etc/fstab,或者mount,來調整文件系統的日志模式和掛載選項等。
第三,優化文件系統的緩存。比如,可以優化 pdflush的臟頁刷新頻率(設置dirty_expire_centisecs 和 dirty_writeback_centisecs)以及臟頁限額(調整 dirty_background_ratio 和 dirty_ratio)。再如,還可以優化內核回收目錄項緩存和索引節點緩存的傾向,及調整 vfs_cache_pressure(
/proc/sys/vm/vfs_cache_pressure,默認值100),數值越大,表示越容易回收。
最后,在不需要持久化時,可以用內存文件系統 tmpfs 以獲得更好的 I/O性能。tmpfs直接把數據保存在內存中,而不是磁盤中。比如 /dev/shm,就是大多數Linux默認配置的一個內存文件系統,它的大小默認為系統總內存的一半。
磁盤優化
數據的持久化,最終要落到物理磁盤上,同時磁盤也是整個 I/O棧的最底層。從磁盤角度出發,也有很多優化方法:
第一,最簡單的就是SSD代替 HDD。
第二,使用 RAID把多塊磁盤組合成一個邏輯磁盤,構成冗余獨立的磁盤陣列,即可以提高數據的可靠性,也可以提升數據的訪問性能。
第三,針對磁盤和應用程序的 I/O模式的特征,可選擇最適合的 I/O調度算法。
第四,可以針對應用程序的數據,進行磁盤級別的隔離。比如,可以為日志、數據庫等 I/O壓力比較重的應用,配置單獨的磁盤。
第五,在順序讀比較多的場景中,可以增大磁盤的預讀數據,可以通過兩種方法,調整 /dev/sdb的預讀大小。一種,調整內核選項,
/sys/block/sdb/queue/read_ahead_kb,默認大小128KB。另一種,blockdev工具,比如,blockdev --setra 8192 /dev/sdb ,注意這里的單位是 512B,所以它的數值總是 read_ahead_kb的兩倍。
第六,優化內核塊設備 I/O的選項。比如,調整磁盤隊列的長度,
/sys/block/sdb/queue/nr_requests,適當增大隊列長度,可以增大磁盤的吞吐量,當然也會增大 I/O延遲。
最后,磁盤本身的硬件錯誤,也會導致 I/O性能急劇下降。比如,查看 dmesg中是否有硬件 I/O故障的日志,還可以使用badblocks、smartctl等工具,檢測磁盤的硬件問題,或用 e2fsck等來檢測文件系統錯誤。如果發現問題,可使用fsck 等工具修復。
-
緩存
+關注
關注
1文章
240瀏覽量
26678 -
磁盤
+關注
關注
1文章
379瀏覽量
25209 -
存儲空間
+關注
關注
0文章
54瀏覽量
10685 -
i/o
+關注
關注
0文章
33瀏覽量
4593
發布評論請先 登錄
相關推薦

UBIFS損耗均衡對系統I/O性能的影響
基于Intel I/O處理器的虛擬磁帶庫設計
播出服務器磁盤I/O與緩存性能分析
XAPP520將符合2.5V和3.3V I/O標準的7系列FPGA高性能I/O Bank進行連接
Java I/O 的相關方法分析

基于FPGA I/O接口的五大優勢與FPGA深層分析


![RA2<b class='flag-5'>快速</b>設計指南 [6] 寄存器寫保護和<b class='flag-5'>I</b>/<b class='flag-5'>O</b>端口配置](https://file1.elecfans.com/web2/M00/A4/8C/wKgaomUDyRmANKEWAABPNEaw3Rg626.jpg)





 工商網監
工商網監
評論