 無需管理底層基礎設施,亞馬遜云科技向量數據庫輕松創建ML增強的搜索體驗和應用程序
無需管理底層基礎設施,亞馬遜云科技向量數據庫輕松創建ML增強的搜索體驗和應用程序
當我們進入一家圖書館時,圖書館的入口處會有幾臺電腦供你檢索相關的書籍,你可以檢索你想要的書籍的名字例如:《百年孤獨》、《悲慘世界》等等,你也可以檢索作者例如:川端康成、魯迅、加繆等等,當然你也可以檢索分類,例如:歷史、哲學、文學等等,這就是傳統的關系型數據庫,檢索這樣簡單關系的數據是沒有任何問題的。但當你只能記起書里的某個章節或者人物的某個特征而想檢索到這本書時,你就無能為力了,甚至我們可以把視野放的更大一點,你想檢索一段音頻或者一張偶然拍下的花朵時,傳統的關系型數據庫恐怕對這樣的要求就捉襟見肘了,也正是基于解決這樣問題的要求,向量數據庫應運而生。
那么什么是向量數據庫?它的原理是怎么樣的?又為什么說未來是向量數據庫的天下呢?
要想了解什么是向量數據庫我們就必須得明白一個高中的數學知識:向量。在數學中,向量是有大小和方向的量,可以使用帶箭頭的線段表示,箭頭指向即為向量的方向,線段的長度表示向量的大小。兩個向量的距離或者相似性可以通過歐式距離、余弦距離等得到,這就是向量數據庫運行的基本數學原理。
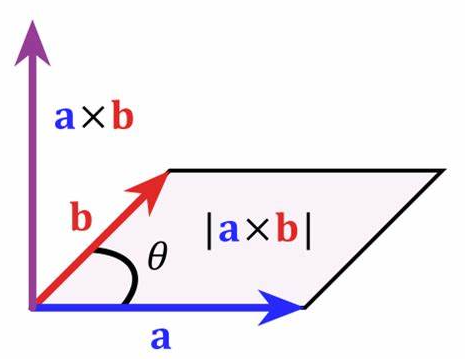
接下來就可以介入向量數據的元素了,前面舉到的圖書館的示例只是將一群事物進行類別上標簽的歸類,但對于復雜的事物就難以簡單地打標簽了,而且想要進行更復雜的運算和檢索過程就必須將一個具體的事物數據化。向量數據就是根據事物的各項特征進行向量得的賦予,例如我們想要在數據世界區別梅西和C羅,就可以從具體的特征出發比如身高、發色、鼻梁高低、眼睛大小、聲音響度高低等等方面,賦予他們向量,就能發現兩個人的區別。
而這種向量當賦予全球80多億人時就會發現,每個人都不盡相同,而且給予向量的特征角度越多,那么數據就會越準確。這從數學理論方面建立了每個人的模型,利用這個模型,我們就能在二進制世界中建立另一個現實世界,這樣我們就可以將一本小說、一首音樂、一段視頻、一張照片數據化,這就是向量數據。
當我們想要檢索某一事物時,只需要盡可能多的提供的某些特征,電腦就會將這些特征轉化為向量,向量空間中會進行相似度計算和索引,而向量數據庫可以實現高效的數據檢索和分析,例如檢索雙胞胎中的某一個時,另一個就會最快出現。而當你檢索一本小說中的某一橋段時,這本小說也會最快的被匹配到從而被檢索出。
那么接下來就可以真正了解向量數據庫了,向量數據庫就是一種特殊類型的數據庫,用于存儲和索引向量數據。在傳統數據庫中,數據是以表格的形式進行組織和存儲的,而向量數據庫則專注于處理和查詢向量數據,這些數據通常表示為多維數值數組。向量數據庫的主要目的是支持高效的向量相似性搜索和查詢。向量數據庫廣泛應用于人臉識別、圖像搜索、視頻分析、語音識別、推薦系統等領域。通過在向量空間中計算向量之間的距離和相似度,可以快速找到與目標向量最相似的數據對象,從而實現高效的搜索和匹配。值得注意的是,向量數據庫主要適用于處理高維度的向量數據,而且在處理大規模數據集時通常能提供更高的查詢性能和可擴展性。因此,在某些特定的應用場景下,向量數據庫可以作為傳統數據庫的補充或替代選擇。
之所以說未來是向量數據庫的天下,是因為向量數據庫讓大模型有了"記憶"的功能,在初始的大語言模型中,世界知識和語義理解被壓縮為靜態參數,模型不會隨著交互記住用戶的聊天記錄和喜好,也無法調用額外知識信息來輔助判斷,因此模型只能根據歷史訓練數據回答問題,并且經常產生幻覺,給出與事實相悖的答案。也就是說大數據模型是一個計算力恐怖的大腦,但是這個大腦的記憶力奇差,而向量數據庫就相當于給這個大腦裝配上了海馬體,讓這個大腦真正的像人一樣,能計算還能根據過去的記憶計算,從而使返回結果更精準,這也就是這幾年AI科技發展速度奇快的原因之一。
2023年8月1日,亞馬遜云科技推出了Amazon OpenSearch Serverless向量引擎預覽版,為用戶提供了一種簡單、可擴展且高性能的相似性搜索功能,使用戶能夠輕松地創建現代化機器學習(ML)增強的搜索體驗和生成式AI應用程序,同時無需管理底層的向量數據庫基礎設施。
那么Amazon OpenSearch Serverless向量引擎的優勢又有哪些呢?
1、構建于Amazon OpenSearch Serverless的向量引擎天然具備魯棒性(這個詞挺抽象的,可以理解為系統更加穩健,性能更強)。因為亞馬遜云科技向量引擎可自動調整資源,來適應不斷變化的工作負載模式和需求,從而提供始終如一的快速性能和適當規模。用戶也就不必擔心后端基礎設施的選型、調優和擴展問題。
2、Amazon OpenSearch Serverless向量引擎由開源OpenSearch項目中的k近鄰(即kNN,可以理解為物以類聚算法,向量數據越接近越容易被檢索)搜索功能提供支持,該功能能夠提供可靠而精確的結果。簡單來說,就是兼容了很多種算法,降低了復雜性,提升了可維護性,并且避免了數據重復、版本兼容性難題和許可問題,有效地簡化了應用程序棧。
3、向量引擎支持不同領域的廣泛用例,包括圖像搜索、文檔搜索、音樂檢索、產品推薦、視頻搜索、基于位置的搜索、欺詐檢測以及異常檢測。
在向量引擎正式版可用前,亞馬遜云科技計劃提供兩項功能來降低客戶使用向量引擎的成本。第一項功能是開發——測試選項,讓用戶可以在不創建備份或副本的情況下啟動集合,從而減少了50%的入門成本。第二項功能是初始配置0.5個OCU資源,根據用戶實際工作需要來擴展資源,這可以幫助用戶進一步節約成本。除此之外,亞馬遜云科技還將降低支持用戶首個集合所需的最低OCU數量,從每小時4個降至每小時1個,以減少用戶的成本支出。
總的來說,亞馬遜云科技的向量引擎具有強大的性能和可擴展性,可以滿足各種應用程序的需求。
審核編輯 黃宇
-
數據庫
+關注
關注
7文章
3826瀏覽量
64509 -
ML
+關注
關注
0文章
149瀏覽量
34670 -
亞馬遜
+關注
關注
8文章
2669瀏覽量
83436
發布評論請先 登錄
相關推薦
Looker Studio連接器:一個連接器從多個數據庫和云應用獲取數據
超級應用程序Grab選擇亞馬遜云科技為首選云服務商
有云服務器還需要租用數據庫嗎?

華納云:MySQL初始化操作如何創建新的數據庫
DTCC2024前瞻:天翼云數據庫專家共話TeleDB發展藍圖
搭載英偉達GPU,全球領先的向量數據庫公司Zilliz發布Milvus2.4向量數據庫





 工商網監
工商網監
評論