 基于檢索的大語言模型簡介
基于檢索的大語言模型簡介
簡介
簡介章節講的是比較基礎的,主要介紹了本次要介紹的概念,即檢索(Retrieval)和大語言模型(LLM):
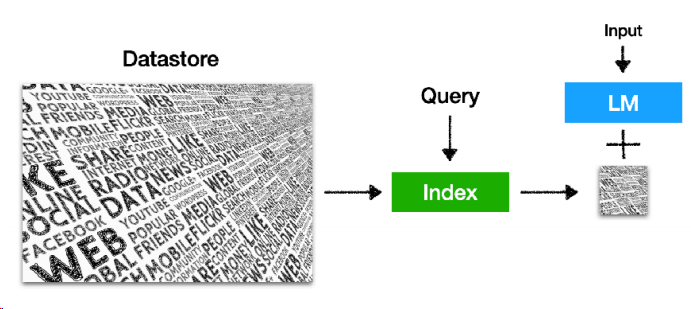
簡單的說,其實就是通過檢索的模式,為大語言模型的生成提供幫助,從而使之生成更符合要求的結果,聽起來,其實就和最近比較火的另一個概念——檢索增強生成(RAG,retrieval augment generation),在我的理解下,就是一件事。
眾所周知,LLM其實已經在很多領域和問題下都取得了很好的效果,那為何還需要依賴檢索做進一步優化,在本文看來,主要有5個原因:
LLM無法記住所有知識,尤其是長尾的。受限于訓練數據、現有的學習方式,對長尾知識的接受能力并不是很高。
LLM的知識容易過時,而且不好更新。只是通過微調,模型的接受能力其實并不高而且很慢,甚至有丟失原有知識的風險。
LLM的輸出難以解釋和驗證。一方面最終的輸出的內容黑盒且不可控,另一方面最終的結果輸出可能會受到幻覺之類的問題的干擾。
LLM容易泄露隱私訓練數據。用用戶個人信息訓練模型,會讓模型可以通過誘導泄露用戶的隱私。
LLM的規模大,訓練和運行的成本都很大。
而上面的問題,都可以通過數據庫檢索快速解決:
數據庫對數據的存儲和更新是穩定的,不像模型會存在學不會的風險。
數據庫的數據更新可以做得很敏捷,增刪改查可解釋,而且對原有的知識不會有影響。
數據庫的內容是明確、結構化的,加上模型本身的理解能力,一般而言數據庫中的內容以及檢索算法不出錯,大模型的輸出出錯的可能就大大降低。
知識庫中存儲用戶數據,為用戶隱私數據的管控帶來很大的便利,而且可控、穩定、準確。
數據庫維護起來,可以降低大模型的訓練成本,畢竟新知識存儲在數據庫即可,不用頻繁更新模型,尤其是不用因為知識的更新而訓練模型。
問題定義
首先,按照文章的定義:
A language model (LM) that uses an external datastore at test time。
關鍵詞兩個:語言模型和數據庫。
語言模型這塊,我們其實都熟悉了,早些年以bert代表的模型,到現在被大量采用的大模型,其實結構都具有很大的相似性,而且已經相對成熟,模型結構這事就不贅述了。更為重要的是,prompt受到關注的這件事,在現在的視角看來是非常關鍵的發現,prompt能讓大模型能完成更多任務,通過引導能讓模型解決不同的問題,同時,效果還是不錯,在現在的應用下,prompt精調已經成為了經濟高效的調優手段了。

至于數據庫,配合大模型,構造成如下的推理結構:
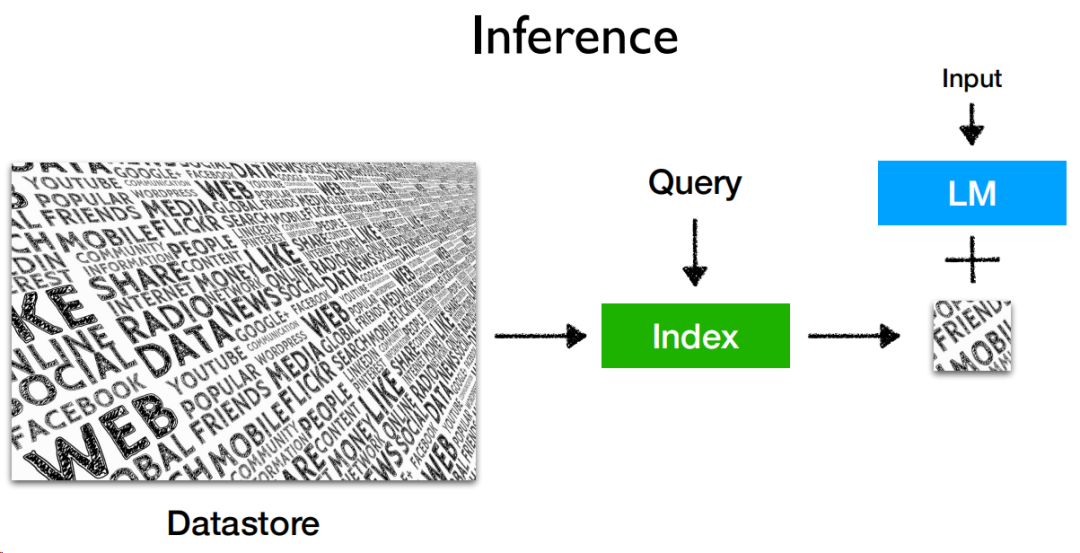
datastore是數據源,構造成索引后,可以接受query進行檢索,檢索結果和大模型配合,就能輸出結果。
架構
此時,就出現一個問題,大模型和檢索查詢之間的關系是什么,拆解下來,就是這幾個問題:
查什么:query如何構造以及檢索的。
如何使用查詢:查詢結果出來后如何跟大模型協同。
何時查:什么時候觸發查詢,或者換個說法,如何構造查詢query。
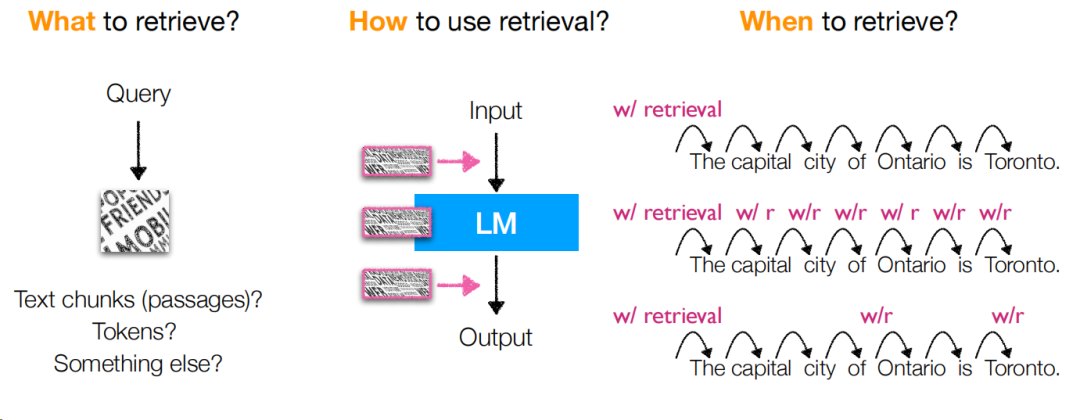
section3中,通過論文講解的方式,討論了多篇論文在解決上述3個問題下的解決方案,并且討論了他們的優缺點。
這里總結一些關鍵要點給大家,讓大家理解這些檢索策略的不一樣會有什么優缺點:
檢索不一定檢索一次,可以切句,例如機械地n個token地切后查詢,會比只查一次要強一些。
RETRO中構造了臨時層對檢索結果進行解析,提升檢索結果的理解和使用能力,但這也意味著這些層需要進行訓練后才可使用,訓練成本是增加的。
KNN-LM在檢索上,從詞降級為token,能對低頻或域外(out of domain)數據有很好的支持,但存儲空間會變大很多,同時該方法缺少輸入和檢索結果的交互信息。
后續的FLARE和Adaptive-LM采用了自適應檢索的方式,能提升檢索的效率,但當然與之對應的檢索策略并不一定是最優的(誤差疊加)。
Entities as Experts直接檢索實體,能提升效率,但這個位置是需要額外的實體識別的。
訓練
在LLM-Retrieval的框架下,訓練除了為了更好地讓LLM做好推理預測,還需要盡可能讓LLM和檢索模塊協同,而顯然,同時訓練LLM和檢索模塊的模型,無疑是成本巨大的,就這個背景,文章總結了4種LLM和檢索模塊的更新策略。(注意,此處我把training翻譯為更新)
首先是獨立更新(Independent training),即兩者各自更新,互不影響。這個應該是目前我看到最常見的一種方式了。
優點:對頻繁更新的索引,大模型不需要頻繁更新,甚至不需要更新;每個模塊可以獨立優化。
缺點:大模型和檢索模型兩者之間并無協同。
然后是依次訓練(Sequential training),即訓練其中一個的時候,另一個固定,等此模塊訓練完訓練完以后再訓另一個。
優點:和獨立更新有相似點,大模型不需要頻繁更新,甚至不需要更新;不同的是,大模型可以進行適配檢索模塊的訓練,反之亦然。
缺點:因為是依次訓練,所以在訓練其中一個時,另一個是固定的,不能做到比較徹底的協同,而且大模型更新的頻率不見得跟得上索引庫的更新,如果緊跟,成本會變高。
第三種是異步索引更新下的聯合訓練,即允許索引過時,定期更新即可。這種方式的難點是需要權衡,索引更新的頻率是多少,太多了則訓練成本昂貴,太少了則索引過時,導致有些問題會出錯。
第四種也是聯合訓練,但考慮到更新索引的頻次問題,所以索引通過批次的方式來更新,當然了,這種方式的同樣會帶來成本的問題,無論是訓練階段,還是索引更新階段。
總結一下,有關訓練階段,兩者協同,有如下優缺點。

應用
應用這塊,通過這幾個月我們的深入使用,大模型給了我們很多的使用空間,到了LLM+檢索的場景,我們需要知道的是有哪些優勢場景,在本文中,作者總結了如下使用場景:
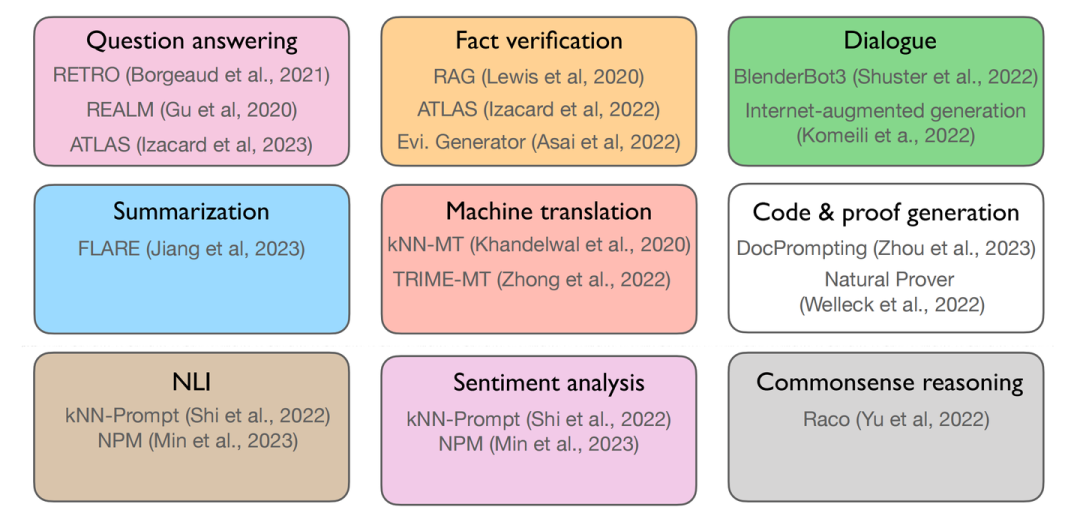
第一行3個任務主要優勢表現在知識密集型的任務中,中間和下面的6個則是比較經典的NLP任務了,中間3個偏向生成,后面3個傾向于分類,此時,我們需要回答兩個問題:
如何把LLM+檢索這個模式應用在這些任務中?
使用LLM+檢索這個模式的時機是什么?
首先是第一個問題,如何應用,這里給出了3種使用方法,分別是微調、強化學習和prompt。我們日常使用的更多的可能是prompt,但是從一些實戰經驗上,可能還有別的模式可能能讓模型更好地利用。
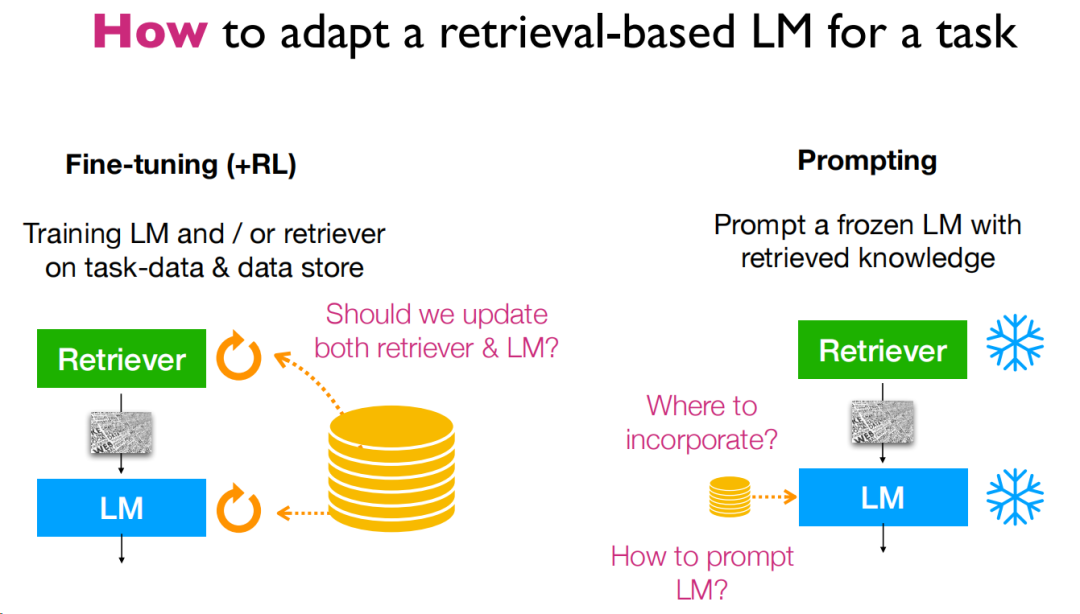
微調方面,只要把整個流程串起來其實就能發現,是完全可行的,ATLAS這篇論文比較典型,再處理知識庫的更新上選擇了相對獨立的策略,從實驗來看,效果還是不錯的,作者的評價是這樣的:
微調能為知識密集型任務提供很大的提升。
對檢索庫本身的微調也十分重要。
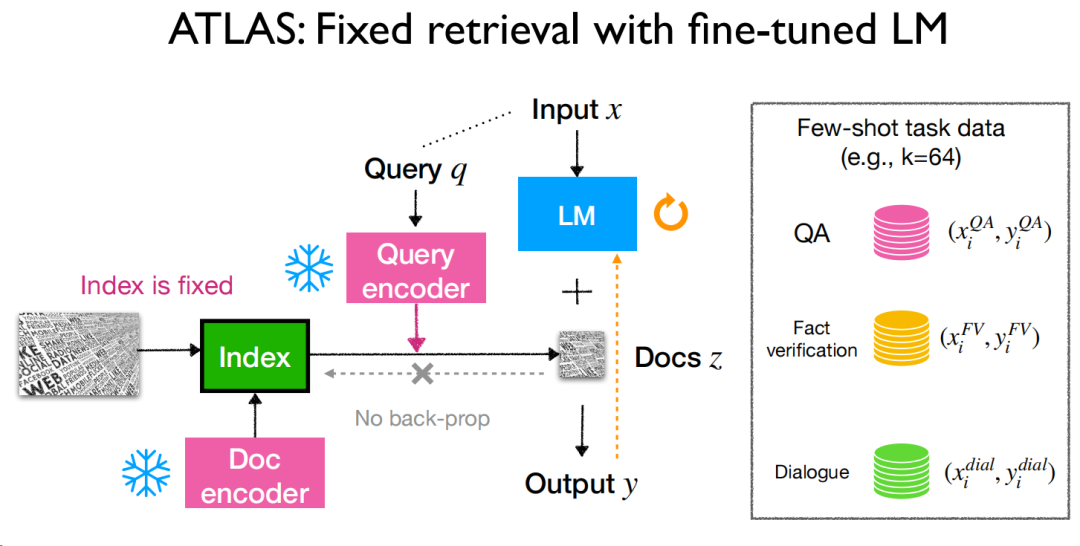
而強化學習,也算是最近比較熱門的研究方向了,RLHF能把全流程串起來,有人工的評價能為結果帶來更多的提升,作者用的是“alignment”,是對齊用戶的偏好,然而實際上,這種人工的數據其實還是比較難獲得并使用的。
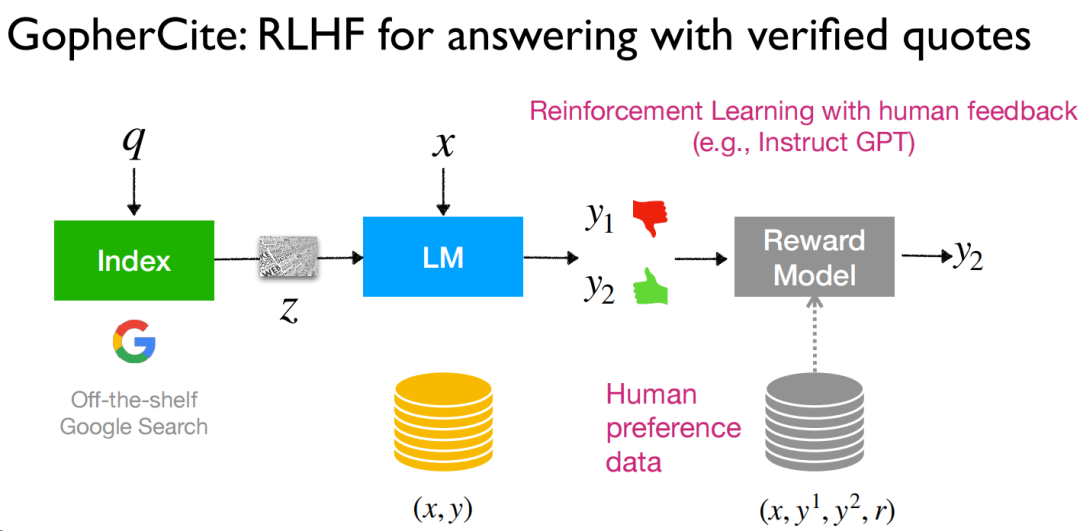
在prompt這塊,作者首先提出一個問題:“What if we cannot train LMs for downstream tasks?”,這個問題很現實,因為很多原因,我們可能沒法訓練模型,只能用開源的或者是固定通用的模型(心法利器[102] | 大模型落地應用架構的一種模式),此時,prompt就是一個非常好用的方案了。從結果層面顯示,這種方案可以說是非常“effective”,同時作者還提及不用訓練和并不差的效果(用的strong),但缺點也比較明顯,可控性還是不夠,相比微調的效果還是要差點。
然后,下一個問題,就是使用檢索這個模式的時機了。說到時機,其實回歸到前面所提到的原因就知道了,即長尾知識、知識過時、內容難驗證、隱私問題和訓練成本問題,經過作者的整理,從使用檢索的原因,轉為提及檢索這個模式的優勢,則是6點:長尾知識、知識更新能力、內容可驗證性、參數效率、隱私以及域外知識的適配性(可遷移性)。
多模態
多模態是讓自然語言處理超越文字本身的窗口了,知識的形式是豐富多樣的,可以是文章、圖譜、圖片、視頻、音頻等,如果能把多種信息進行解析,那對知識的支撐能力無疑是新的提升(畢竟不是所有信息都通過文字傳播),在這章,更多是給了很多知識應用的思路,論文還不少,此處不贅述,大家可以去PPT里面錢問題記得網站上面找參考文獻。
挑戰和展望
總算到了挑戰和展望,本章在總結前文的基礎上,提出了很多新的問題,研究者們可以參考作為新的研究方向。
首先是基于檢索的LLM的規模,第一個問題是小模型+大數據庫,是否能約等于一個大模型,
小模型+大數據庫,是否能約等于一個大模型?兩者在規模上的關系是什么樣的。
兩者的縮放規則是什么樣的,當知識庫能支撐知識層面的需求后,語言模型的參數量、token量對結果有什么影響。
檢索效率問題,一個是速度,另一個是空間。
第二個問題是,需要探索其應用。
開放式文本生成下,基于檢索的大模型在蘊含和推理能力上還有局限性,畢竟光靠相似度的檢索不太夠,同時知識庫大了以后,面對相似但是困難的知識點也會對推理造成干擾。
對于復雜的推理任務,有沒有更好的潛在方案可探索,例如多次檢索、query改寫等策略。
再然后,是一些開放的問題:
基于檢索的LLMs下最優的結構和訓練策略是什么樣的。
對模型的規模,我們無法比較好地去拓展和提升,尤其在具有檢索能力支持的情況下。
下游任務上,需要更多更好的解碼、推理等方案,甚至是自適應的。
小結
這篇文章寫了挺久的,可以說是大開眼界吧,里面的論文看了不少,收獲還是挺大的,讓我知道有關檢索-LLM這個模式下有那么多前人嘗試過的玩法,后面有些我應該也會去嘗試,看看提升如何。
審核編輯:劉清
-
語言模型
+關注
關注
0文章
524瀏覽量
10277 -
LLM
+關注
關注
0文章
288瀏覽量
335
原文標題:ACL23 | 基于檢索的大語言模型-陳丹琦報告閱讀
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型開發語言是什么
大語言模型如何開發
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
Transformer語言模型簡介與實現過程
大語言模型(LLM)快速理解






 工商網監
工商網監
評論