") 怎樣讓PPO訓(xùn)練更穩(wěn)定?早期人類征服RLHF的馴化經(jīng)驗(yàn)
怎樣讓PPO訓(xùn)練更穩(wěn)定?早期人類征服RLHF的馴化經(jīng)驗(yàn)
做一個(gè)專門面向年輕NLPer的每周在線論文分享平臺(tái)
寫在前面
今天給大家?guī)?lái)一篇“如何穩(wěn)定且有效地訓(xùn)練 PPO”的論文解讀,來(lái)自知乎@何枝(已授權(quán))。在這篇文章中我們將學(xué)習(xí):哪些技巧能夠穩(wěn)定訓(xùn)練過程、哪些指標(biāo)能夠代表著訓(xùn)練的順利進(jìn)行等內(nèi)容。
作為 Reinforcement Learning 中的頂流算法,PPO 已經(jīng)統(tǒng)領(lǐng)這個(gè)領(lǐng)域多年。直到InstructGPT的爆火,PPO 開始進(jìn)軍 LLM 領(lǐng)域,憑借其 label-free 的特性不斷拔高基座的性能,在 Llama2 、 Baichuan 的工作中都能看到 RLHF 的身影。
于是你開始摩拳擦掌,躍躍欲試,準(zhǔn)備利用這項(xiàng)強(qiáng)大的技術(shù)來(lái)進(jìn)化自己的基座。但當(dāng)你信心滿滿地跑通訓(xùn)練任務(wù)時(shí),你看到的情況很有可能是這樣的:
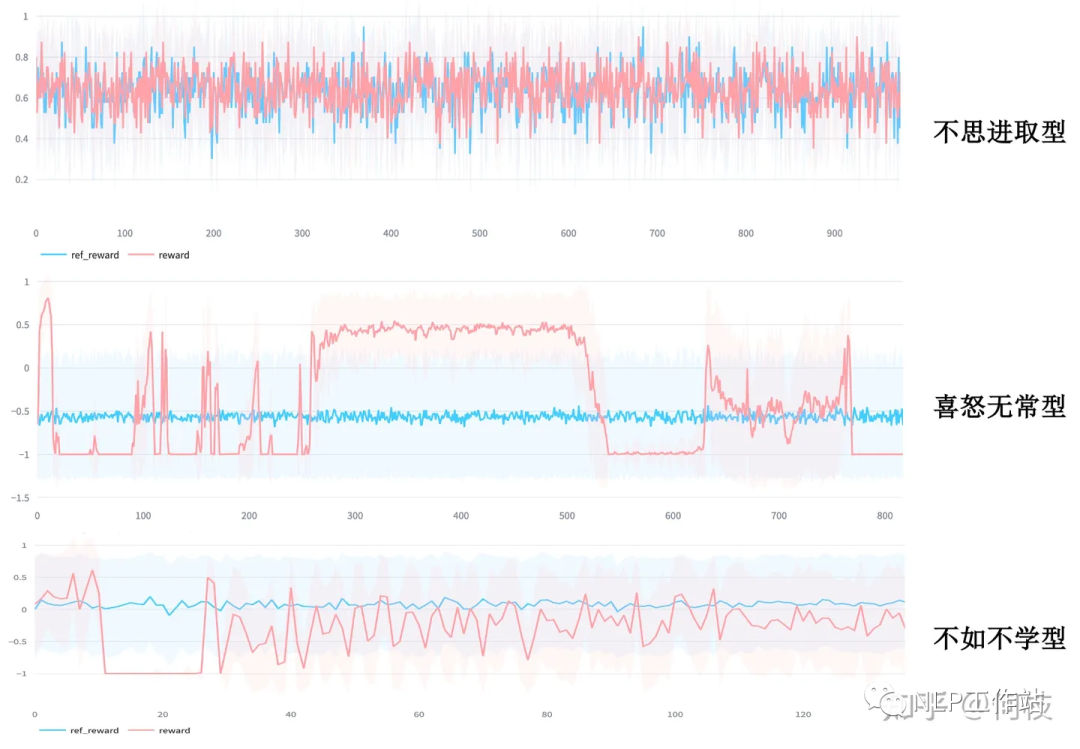 各種形形色色的失敗案例
各種形形色色的失敗案例盡管魯迅先生曾言:真的強(qiáng)化敢于直面慘淡的結(jié)果,敢于正視崩壞的曲線。但日復(fù)一復(fù)地開盲盒難免會(huì)讓人心臟承受不了,好在前人們留下了寶貴的馴化經(jīng)驗(yàn),今天讓我們一起看看“如何穩(wěn)定且有效地訓(xùn)練PPO”。
知乎:https://zhuanlan.zhihu.com/p/666455333
Paper:https://arxiv.org/pdf/2307.04964.pdf
Code:https://github.com/OpenLMLab/MOSS-RLHF/tree/main
1. Reward Model 訓(xùn)練
RL 的整個(gè)訓(xùn)練目標(biāo)都是圍繞著 reward 來(lái)進(jìn)行,傳統(tǒng) RM 的訓(xùn)練公式為拉開好/壞樣本之間的得分差:
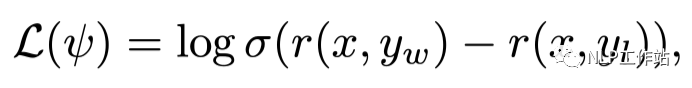 y_w 為 selected 樣本,y_l 為 rejecte 樣本
y_w 為 selected 樣本,y_l 為 rejecte 樣本但是,僅僅是「拉開得分差」這一個(gè)目標(biāo)很有可能讓 RM 陷入到「鉆牛角尖」的困境中。
為了保持住 RM 的本質(zhì)還是一個(gè)「語(yǔ)言模型」,文章在原本的 loss 中加入了對(duì)「好樣本」的 LM loss:
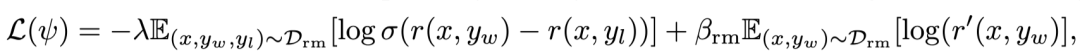 在原來(lái)的 loss 基礎(chǔ)上順便學(xué)習(xí)寫出「優(yōu)秀樣本」,保持住模型能寫句子的能力
在原來(lái)的 loss 基礎(chǔ)上順便學(xué)習(xí)寫出「優(yōu)秀樣本」,保持住模型能寫句子的能力值得一提的是:文章中的 r' 是用了另外一個(gè) RM' 來(lái)算 loss 的,RM' 的結(jié)構(gòu)和 RM 一樣,只不過輸出的維度不是 1,而是 vocab_size。但其實(shí)我認(rèn)為也可以使用一個(gè)帶有 ValueHead 的模型來(lái)既訓(xùn)練打分又訓(xùn)練寫句子,畢竟這 2 個(gè)任務(wù)都需要模型知道什么的句子是「好句子」—— 還能省顯存。
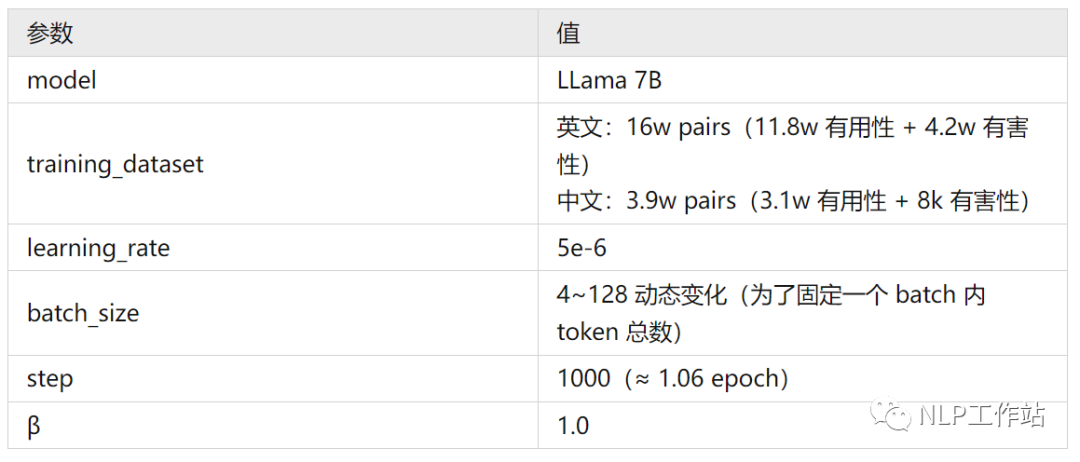
以下是論文訓(xùn)練 RM 的詳細(xì)參數(shù):
一般的,我們會(huì)使用 prefered sample - disprefered sample 的分差來(lái)衡量 RM 的效果:
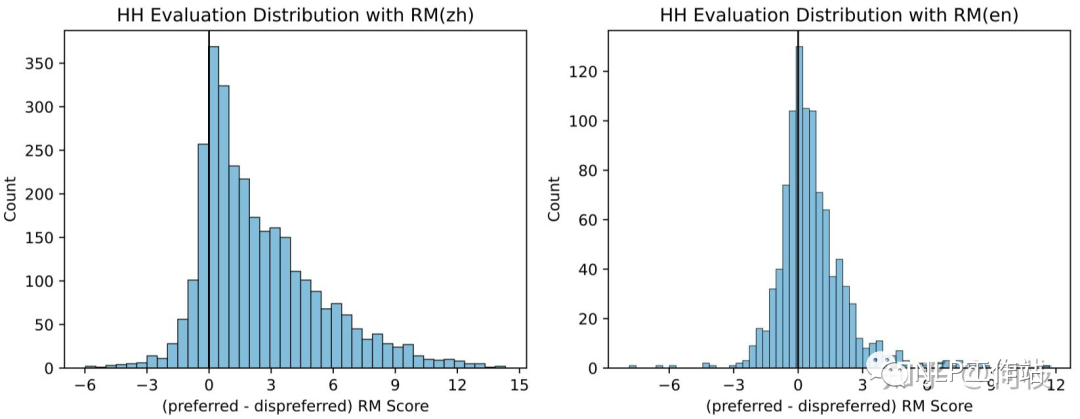 圖左為在中文標(biāo)注數(shù)據(jù)集上的分差分布,圖右為在英文數(shù)據(jù)集上的分差分布(區(qū)分度不如中文)
圖左為在中文標(biāo)注數(shù)據(jù)集上的分差分布,圖右為在英文數(shù)據(jù)集上的分差分布(區(qū)分度不如中文)完全理想的狀況下,prefered - disprefered 應(yīng)該都在 0 的右邊(好樣本的分?jǐn)?shù)更高),但考慮到標(biāo)注中的噪聲、模型的擬合能力等,存在少小部分 0 左邊的樣本是合理的,拉出來(lái)人工評(píng)估下即可。
此外,文中還提到:只看 Acc 并不能夠很好的衡量 RM 的性能,但尚未給出其他可以衡量的指標(biāo)。
2. PPO 的穩(wěn)定訓(xùn)練方法
2.1 及時(shí)發(fā)現(xiàn)訓(xùn)練過程中的異常
PPO 訓(xùn)練中很常見的一個(gè)問題是「模式崩潰」,其典型特征為:長(zhǎng)度很長(zhǎng)且無(wú)意義的文字。
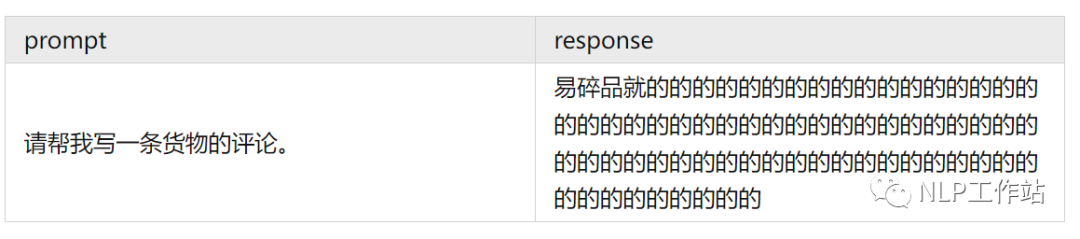
而對(duì)于這種「崩潰的輸出」Reward Model 往往還容易打出一個(gè)很高的分?jǐn)?shù),這將導(dǎo)致我們無(wú)法在訓(xùn)練過程中及時(shí)的發(fā)現(xiàn)問題,等訓(xùn)完對(duì)著一個(gè)滿意分?jǐn)?shù)的 checkpoint 看生成結(jié)果的時(shí)候才發(fā)現(xiàn)空歡喜一場(chǎng)。
對(duì)于上述這種問題,我們可以通過 3 個(gè)指標(biāo)來(lái)監(jiān)控:KL、Response Length、Perplexity。
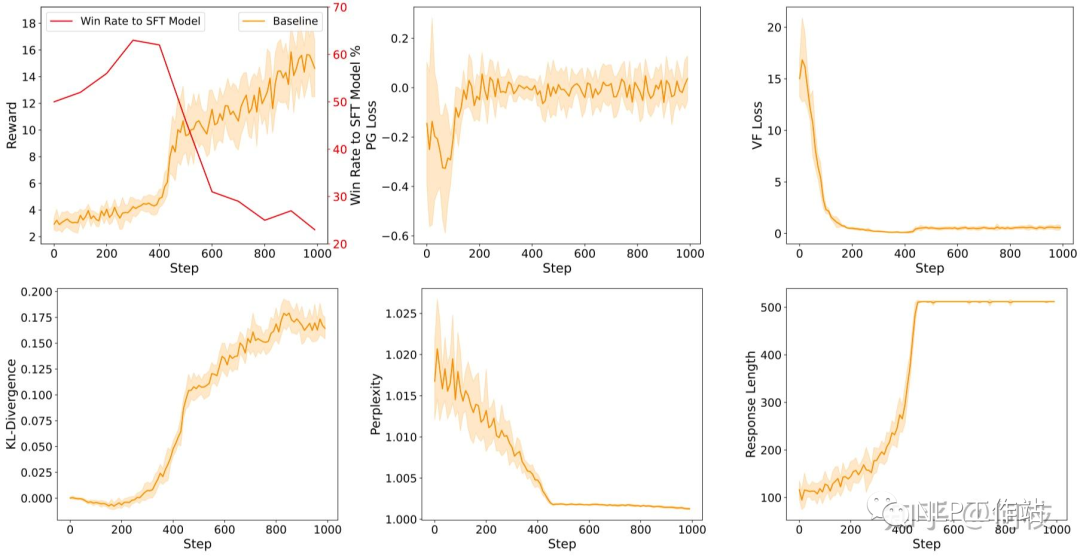 訓(xùn)練過程中的各種指標(biāo),從約第 420 step 開始: 1. reward 出現(xiàn)驟增。2. KL 出現(xiàn)驟增。3. Perplexity 出現(xiàn)驟降。4. Response Length 出現(xiàn)驟增。5. 訓(xùn)練效果出現(xiàn)驟降(圖左上紅線)
訓(xùn)練過程中的各種指標(biāo),從約第 420 step 開始: 1. reward 出現(xiàn)驟增。2. KL 出現(xiàn)驟增。3. Perplexity 出現(xiàn)驟降。4. Response Length 出現(xiàn)驟增。5. 訓(xùn)練效果出現(xiàn)驟降(圖左上紅線)因此我們可以總結(jié)出幾種指標(biāo)異常的情況:
- Reward 出現(xiàn)驟增:很可能 Policy Model 找到了某條 shortcut,比如通過模式崩潰來(lái)獲得更高的分?jǐn)?shù)。
- KL 出現(xiàn)驟增:同上,很可能此時(shí)的輸出模式已經(jīng)完全崩潰。
- Perplexity 驟降:由于 PPL 是指代模式對(duì)當(dāng)前生成結(jié)果的「確定性」,一般來(lái)講,句子的生成都會(huì)帶有一定的不確定性,當(dāng) Policy Model 對(duì)某一個(gè)生成結(jié)果突然「非常確定」的時(shí)候(無(wú)論是什么樣的上文都很確定接下來(lái)應(yīng)該輸出什么),那么它大概率是已經(jīng)擬合到了一個(gè)確定的「崩壞模式」上了。
- Response Length 驟增:這個(gè)對(duì)應(yīng)我們之前給的 bad case,回復(fù)長(zhǎng)度的驟增也可能代表當(dāng)前輸出已經(jīng)崩潰。
2.2 Score Normalization & Clipping
PPO 的整個(gè)訓(xùn)練都是圍繞優(yōu)化 Score 作為目標(biāo)來(lái)進(jìn)行的,和 Score 相關(guān)的變量有 2 個(gè):
- Reward:由 RM(≈ Human) 直接給出的反饋。
- Advantages:由 Reward 和 Critic Model 共同決定的優(yōu)勢(shì)值,最終用于 loss 計(jì)算。
對(duì)于這 2 個(gè)值,我們都可以對(duì)其進(jìn)行「歸一化」和「裁剪」。
Reward 的處理公式如下:
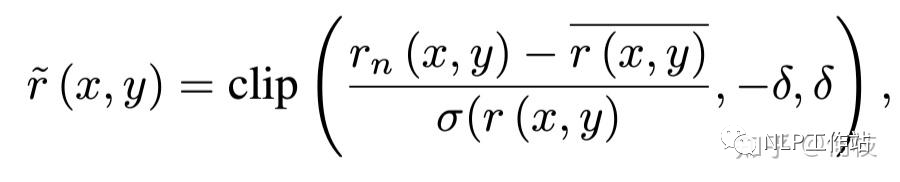 Reward Normalization & Clipping
Reward Normalization & Clipping上述式子將 reward 化成了一個(gè)均值為 0 的標(biāo)準(zhǔn)分布,均值為 0 是為了保證在訓(xùn)練過程中得到的正負(fù)獎(jiǎng)勵(lì)能夠盡可能的均勻,如果一段時(shí)間內(nèi)全為負(fù)或全為正從直覺上來(lái)講不太利于模型學(xué)習(xí)。
文中提到,使用 clipping 可以限制模型進(jìn)化的「最終分?jǐn)?shù)」沒有那么高,鑒于之前「分?jǐn)?shù)越高,并不一定有更好的效果」的結(jié)論,作者認(rèn)為使用 clipping 對(duì)最終的效果是有益的。
至于 Advantages,在 PPO 的標(biāo)準(zhǔn)流程里已經(jīng)會(huì)對(duì)其進(jìn)行 Normalization,而 advantage clipping 和 reward clipping 在本質(zhì)上其實(shí)很相似,則只用在 reward 階段進(jìn)行截?cái)嗉纯桑詫?duì)于 Advantage 來(lái)講不需要做太多其他額外的操作。
2.3 Policy Loss 設(shè)計(jì)
在傳統(tǒng)的 PPO 流程中,我們通常會(huì)對(duì) Policy Molde 的 Loss 上做以下 2 種操作:
- Importance Sampling:這是 PPO 中加快 On-Policy 算法訓(xùn)練速度的關(guān)鍵步驟,即一次采樣的數(shù)據(jù)可以進(jìn)行多次更新(通過系數(shù)補(bǔ)償)。這種方法通常和 KL 懲罰一起使用,實(shí)驗(yàn)表明這樣能夠更加穩(wěn)定 PPO 的訓(xùn)練,但對(duì)最終的效果會(huì)存在一定折損(所以最好的還是 1 輪 sample 只做一次 update,退化為原始的 PG 流程)。
- Entropy Loss:一般為了鼓勵(lì) Policy 在進(jìn)化的同時(shí)保留「探索」的能力,我們會(huì)在 loss 中加入 entropy(確定性)loss,但在 RLHF 中這項(xiàng)設(shè)置對(duì)超參非常敏感,很容易就崩掉。鑒于 KL 和 Entropy 有著相似的效果,因此作者更推薦使用 KL 來(lái)代替 Entropy Loss。
除了上述 2 個(gè)傳統(tǒng)設(shè)置外,RLHF 中加入一個(gè)新的指標(biāo):Token Level KL-Penalty。
在傳統(tǒng)的 RL 流程中,agent 每采取一個(gè) action 后都會(huì)得到一個(gè) action reward,對(duì)比到文本生成任務(wù)中,每新生成一個(gè) token 就等于做出了一次 action,但實(shí)際上我們無(wú)法每生成一個(gè) token 就打出一個(gè)分?jǐn)?shù),我們只能在一個(gè)完整句子(Trajectory)生成完成之后打出一個(gè) Total Reward。
這就比較痛苦了,當(dāng)我們只有一個(gè)長(zhǎng)序列的最后得分時(shí),前面的每一個(gè) step 的得分估計(jì)就變得非常困難。因此,為了避免「sparse reward」的同時(shí)限制 Policy Model 朝著「相對(duì)合理的方向」進(jìn)化,我們會(huì)通過計(jì)算每個(gè)生成 token 與參考模型之間的 KL 來(lái)作為單個(gè) token 的 reward 分?jǐn)?shù)。
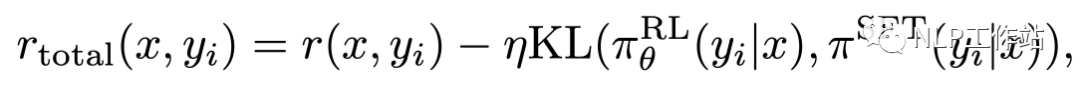 式子的前半部分為 reward(discounted)后半部分為 KL 懲罰分?jǐn)?shù)
式子的前半部分為 reward(discounted)后半部分為 KL 懲罰分?jǐn)?shù)2.4 模型初始化
PPO 繼承自 Actor-Critic 框架,因此算法中一共包含 2 個(gè)模型:Actor 和 Critic。
- Actor Model(Policy Model)
Policy Model 是指我們最終訓(xùn)練后使用的生成模型,Policy Model 需要具備一定基本的能力才能保證訓(xùn)練的穩(wěn)定性,通常會(huì)選用 SFT 之后的模型。這個(gè)比較好理解,如果我們選用 Pretrained Model 為起點(diǎn)的話,探索空間會(huì)非常大,同時(shí)也更加的不穩(wěn)定(對(duì) Reward Model 要求更高)。
- Critic Model
一種很直覺的想法是:同樣是「評(píng)判任務(wù)」,我們直接使用 Reward Model 來(lái)當(dāng)作 Critic Model 就好了。
但其實(shí)這種想法不完全正確,從本質(zhì)上來(lái)講 Critic 需要對(duì)每一個(gè) token 的狀態(tài)進(jìn)行打分,而 RM 是對(duì)整個(gè)句子進(jìn)行綜合得分評(píng)估,這兩個(gè)任務(wù)還是存在一定的區(qū)別。
因此,一種更好的方式是:先訓(xùn)練 Critic Model一段時(shí)間,直到 Critic Loss 降的相對(duì)較低為止。預(yù)先訓(xùn)練能夠幫助在正式訓(xùn)練的初期 Critic 能夠進(jìn)行較為正確的 value 預(yù)估,從而穩(wěn)定訓(xùn)練過程,至于使用 SFT 還是 RM 作為 Critic 的結(jié)構(gòu),實(shí)驗(yàn)結(jié)果顯示并沒有非常明顯的區(qū)別。
2.5 最優(yōu)策略集合(PPO-max)
文章的末尾給出了作者匯聚了各種實(shí)驗(yàn)結(jié)果給出的一套推薦的策略:
- reward normalize:使用歷史獲得過的所有 reward 的均值和方差進(jìn)行標(biāo)準(zhǔn)化。
- token KL penalty:限制模型更新方向。
- Critic Model:使用 RM 初始化 Critic,并在 PPO 正式訓(xùn)練之前先進(jìn)行 Critic 預(yù)訓(xùn)練。
- Global Gradient Clipping
- 使用相對(duì)較小的 Experience Buffer。
- Pretrain Loss:在 PPO 訓(xùn)練 loss 中加入 Pretrain Language Model Loss,和 [InstructGPT] 中保持一致。
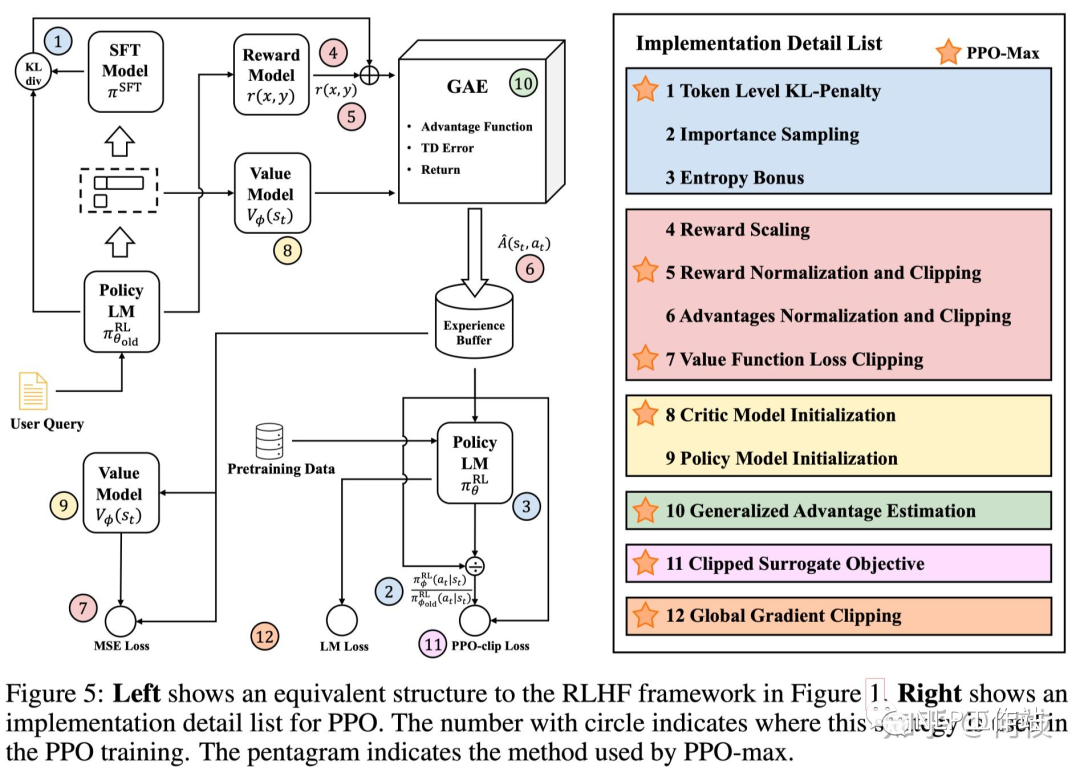 PPO-max 所使用的方法合集(標(biāo)星的方法)
PPO-max 所使用的方法合集(標(biāo)星的方法)
-
噪聲
+關(guān)注
關(guān)注
13文章
1122瀏覽量
47420 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
525瀏覽量
10277 -
LLM
+關(guān)注
關(guān)注
0文章
288瀏覽量
343
原文標(biāo)題:怎樣讓 PPO 訓(xùn)練更穩(wěn)定?早期人類征服 RLHF 的馴化經(jīng)驗(yàn)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
拆解大語(yǔ)言模型RLHF中的PPO算法
tas5711 DRC Time Constants怎樣配置出合理的時(shí)間使功率壓出更穩(wěn)定?
altium designer 哪個(gè)版本更穩(wěn)定好用?
請(qǐng)問怎么讓組件更穩(wěn)定?
STM32與PIC對(duì)比分析?哪個(gè)更穩(wěn)定?
如何讓AGP顯卡工作得更穩(wěn)定
了解如何讓您的汽車電池更穩(wěn)定、運(yùn)行時(shí)間更長(zhǎng)

微軟開源“傻瓜式”類ChatGPT模型訓(xùn)練工具
怎么讓直流調(diào)速更穩(wěn)?

RLHF實(shí)踐中的框架使用與一些坑 (TRL, LMFlow)
大語(yǔ)言模型(LLM)預(yù)訓(xùn)練數(shù)據(jù)集調(diào)研分析

插卡路由器設(shè)置教程,讓家庭網(wǎng)絡(luò)更穩(wěn)定高速!
一種基于表征工程的生成式語(yǔ)言大模型人類偏好對(duì)齊策略
圖解大模型RLHF系列之:人人都能看懂的PPO原理與源碼解讀






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論