") 把ChatGPT塞進副駕駛!清華、中科院、MIT聯(lián)合提出Co-Pilot人機交互框架
把ChatGPT塞進副駕駛!清華、中科院、MIT聯(lián)合提出Co-Pilot人機交互框架
作為本年度人工智能領域最重要的突破之一,大語言模型相關研究始終是各大相關領域的關注焦點。
近日,來自清華大學、中國科學院、MIT的科研人員對于大語言模型在人機交互領域中的應用進行了研究,設計了一種名為Co-Pilot的人機交互框架,使用提示引導ChatGPT(gpt3.5)在考慮人主觀意圖的同時完成簡單的自動駕駛任務。
論文標題:
ChatGPT as Your Vehicle Co-Pilot: An Initial Attempt
論文鏈接:
https://www.researchgate.net/publication/374800815_ChatGPT_as_Your_Vehicle_Co-Pilot_An_Initial_Attempt
該研究作為最早一批使用原生語言大模型直接介入自動駕駛任務的嘗試,揭示了大語言模型在自動駕駛領域進一步深入應用的可能性,也為后續(xù)相關研究指明了方向 [1]。

研究背景:為什么使用大語言模型?
人車交互作為智能汽車發(fā)展的重要功能之一,對降低司機駕駛負擔、提升乘客出行體驗有很大幫助,相關功能也成為了消費者在選擇時的重要標準。 盡管現(xiàn)有人機交互系統(tǒng)已經可以實現(xiàn)語音識別、指令執(zhí)行等功能,但大多數情況下系統(tǒng)僅能根據既定指令的訓練在有限范圍內給出回答或響應,存在一定的局限性。 相比之下,大語言模型在此類能力上具有更好的表現(xiàn): 1. 可以理解人的意圖:大語言模型具有推理能力,其可以從文字中理解說話者的真正意圖,并給出相應的回應; 2. 擁有常識:得益于大量的訓練數據中包含的知識,大預言模型具有一定的常識,并掌握許多特定領域的基礎知識與能力; 3. 對于不同任務的高度適應性:通過調整提示詞,大語言模型對于不同任務具有很好的適應性,可快速適配不同種類的任務,極大提升了應用與落地的效率。 基于此,大語言模型為解決人機共駕問題提供了一種新的思路。 為了探索大語言模型在自動駕駛人機交互領域的應用,研究人員提出了「Co-Pilot」架構,用于實現(xiàn)乘客、大語言模型以及車輛之間的交互。 為了驗證方案的可行性,研究人員設計了兩個不同種類的任務對其進行測試,實驗效果達到了預期。

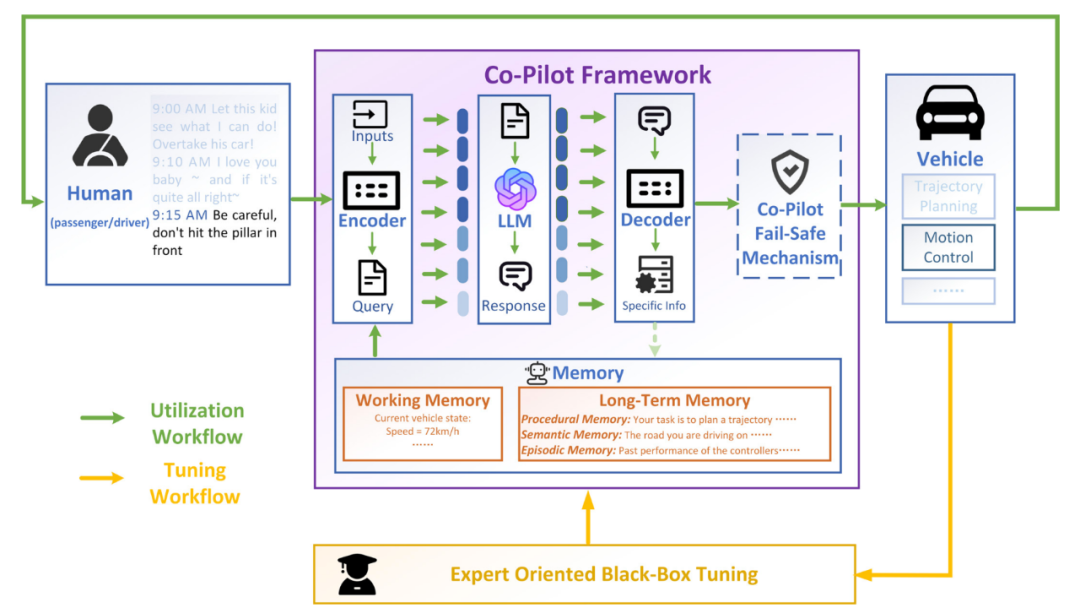
Co-Pilot主體機構包含了以下模塊:
1. 編碼器:將必要的信息組成提示,通過專用API發(fā)送至大語言模型。
2. LLM:大語言模型,本工作使用ChatGPT(GPT3.5-turbo-0301)。
3. 解碼器:將自然語言回應解析為指令或數據,用于車輛的交互與控制。
4. 保險機制:考慮到大語言模型作為概率模型的本質,現(xiàn)階段難以杜絕其在回答中出錯,故預留該保險機制防止存在明顯錯誤的指令影響車輛運行。
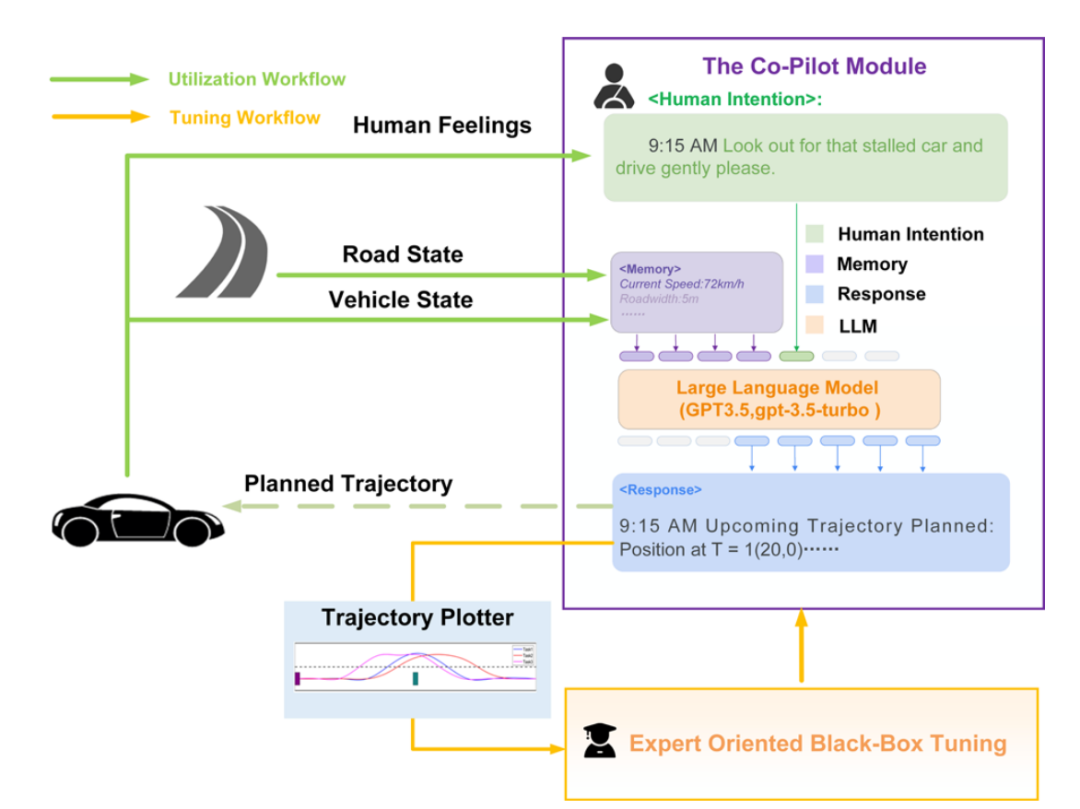
5. 記憶機制:保存Co-Pilot完成任務所必須的數據及其他信息,作為輸入的重要組成部分,可在工作過程中被實時更新。Co-Pilot主要擁有兩種工作流程:
1. 實現(xiàn)流程:Co-pilot依據不同任務完成一次工作周期的流程。
2. 調優(yōu)流程:車輛專家依據不同任務調整記憶機制的前置優(yōu)化流程。
記憶機制 本文按照人類認知心理學對大語言模型內部的知識儲存進行模擬[2],提出了記憶機制用來劃分自動駕駛場景中可能涉及到的信息,旨在全面提升Co-Pilot信息利用效率。
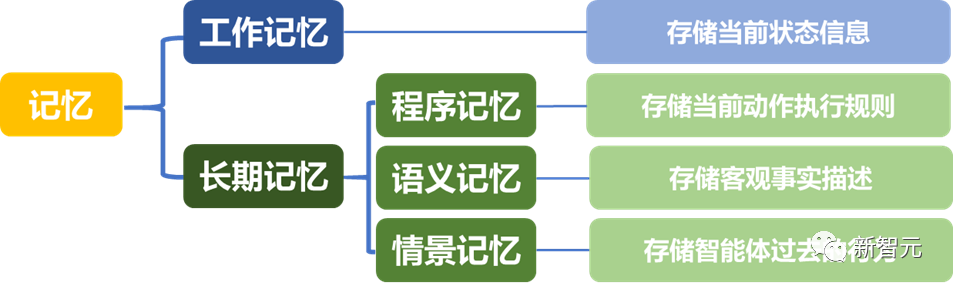
專家主導的黑箱優(yōu)化 該方法利用黑箱優(yōu)化中在低維空間進行無梯度優(yōu)化的思想,利用專家的主觀標注來評估任務完成效果,從而更新記憶中的內容來增強提示詞,使得LLM進行少樣本學習。


仿真實驗
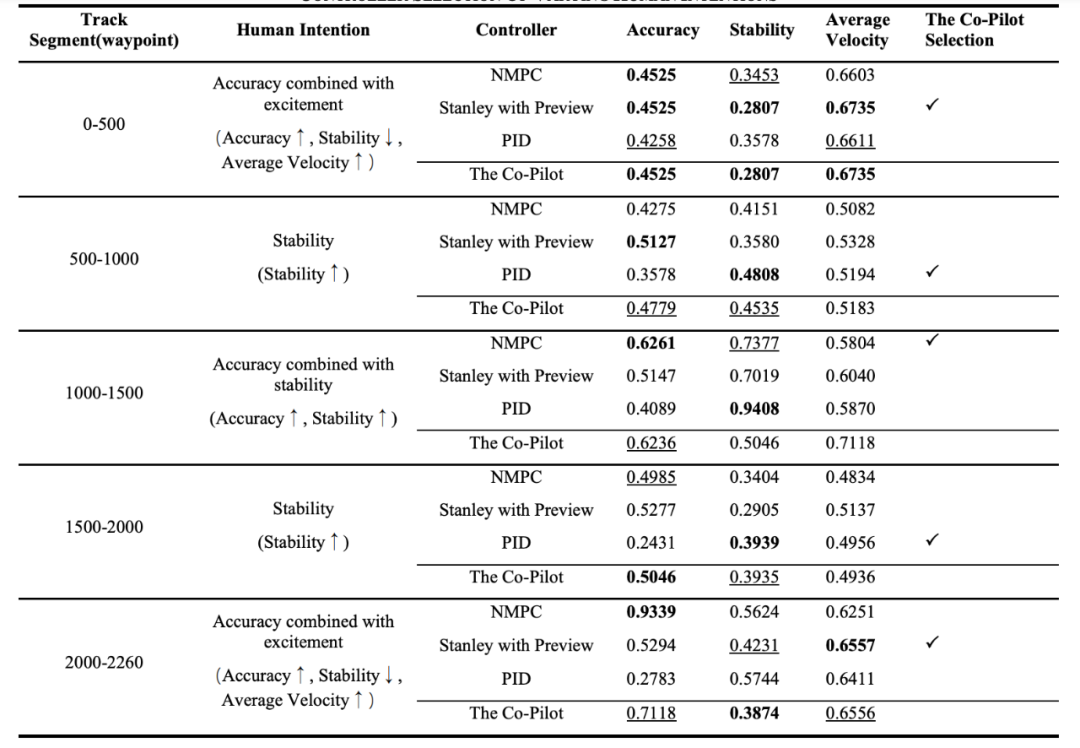
為了驗證Co-Pilot架構的可靠性,本文設計了兩個任務,在以MATLAB/Simulink為基礎的仿真平臺中開展。 實驗一:軌跡跟隨控制器選擇 在該實驗中,假設有一輛自動控制的汽車在預設路徑上行駛,研究人員給定Co-Pilot當前車輛狀態(tài)、路段情況等信息,要求其選擇最符合當前乘客意圖(如保證速度、緊隨軌跡、體驗舒適)的運動控制器。 運動控制器為已有預設模塊,分別為NMPC控制器、Stanley + Preview控制器、PID控制器。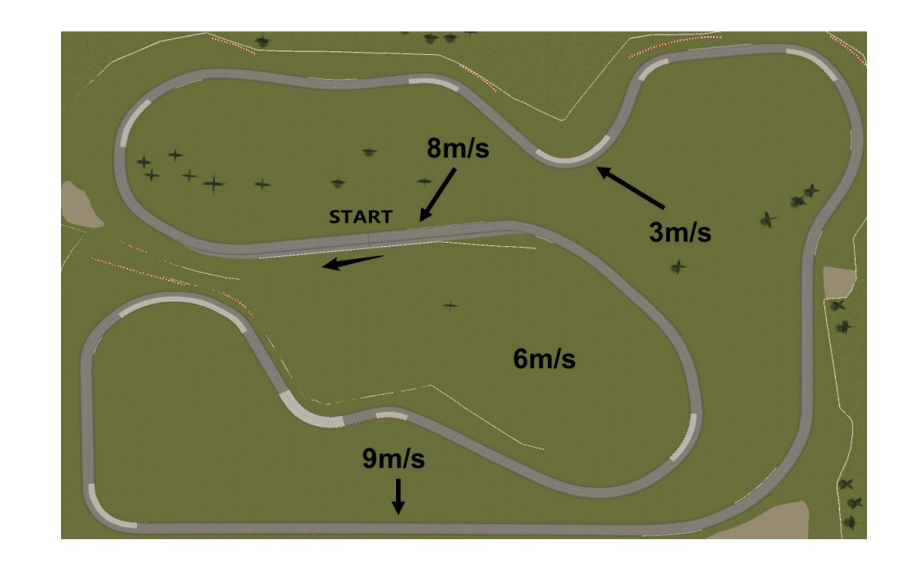 ▲賽道總覽
▲賽道總覽
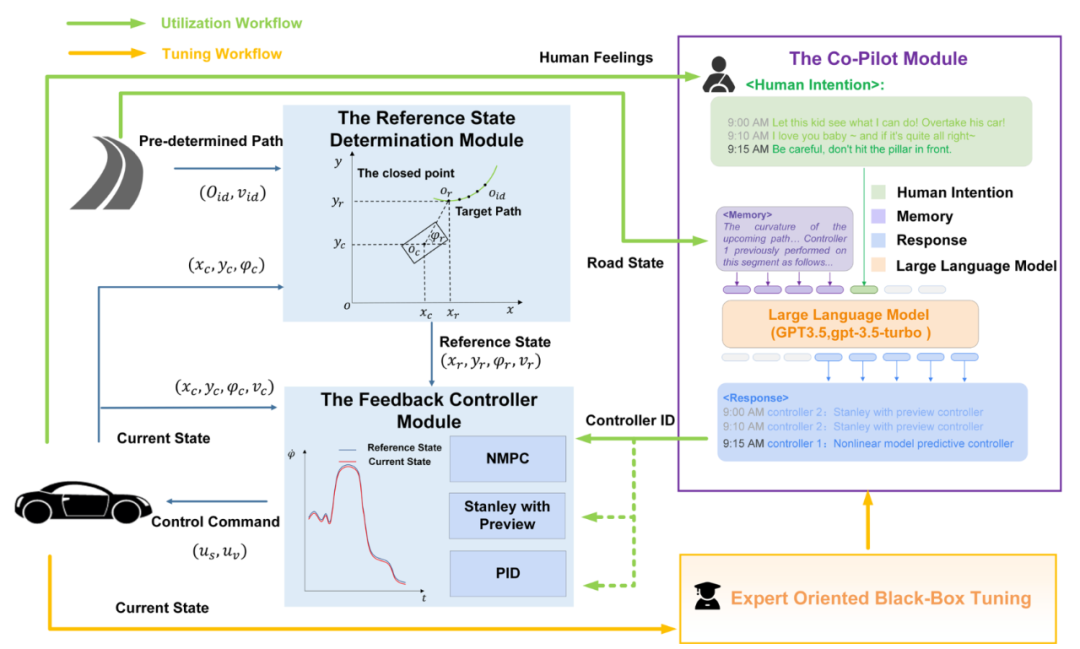
▲實驗一的Co-Pilot具體結構
在調優(yōu)環(huán)節(jié)中,研究人員分別對語義記憶與情景記憶進行了更新,其中語義記憶僅能提供對控制器的種類(A1)或定性描述(A2),而情景記憶可以提供對控制器在過去相似場景下的具體表現(xiàn)(A3)。 賽道被分為五個區(qū)段,研究人員根據Co-Pilot是否在各區(qū)段選出了最符合當前乘客意圖的控制器進行打分(每個區(qū)段最優(yōu)1分,次優(yōu)0.5分,最差0分,賽道總分最高為5分),分析不同記憶對于Co-Pilot表現(xiàn)的影響,研究人員在「精確跟蹤」與「保持穩(wěn)定」兩種意圖下分別測試,測試結果顯示,A1僅取得3分,Co-Pilot在所有區(qū)段均選擇了NMPC控制器。 由于此時提供的信息有限,其只能根據訓練中積攢的常識「NMPC的控制效果很好」做出判斷。A2取得了7.5分,而A3取得了8.5分,證明情景記憶在相似任務中對Co-Pilot的推理最有幫助,使其可結合人類意圖給出合理的反應。 接著,研究人員使用了調優(yōu)后的A3提示模式開展了更復雜的實驗。在此實驗中,五個區(qū)段的人類意圖不再保持一致且引入了更口語化表達的新意圖「刺激」。 實驗結果如下圖所示,Co-Pilot在每個區(qū)段都能選出最符合乘客意圖的控制器(由于控制器在切換時受到上一區(qū)段的車輛狀態(tài)影響,導致被選控制器的效果與預期可能存在細微差異)。
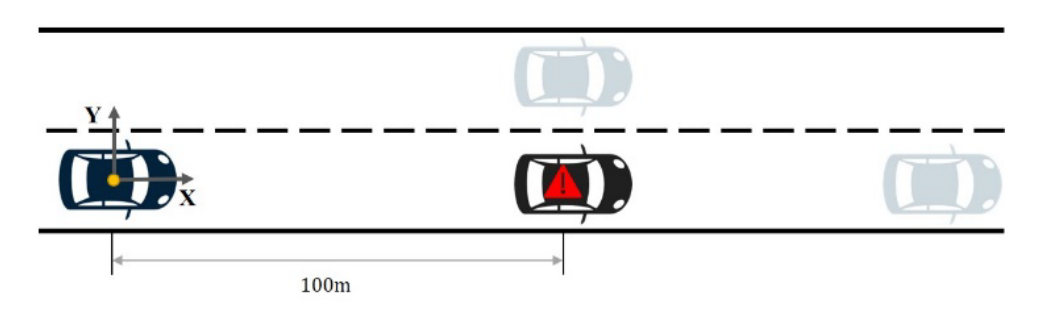
實驗二:雙移線避障軌跡規(guī)劃 在本實驗中,研究人員將重點轉移到規(guī)劃類任務,向Co-Pilot描述當前路況,并要求其給出未來10s內的路徑。
在調優(yōu)環(huán)節(jié)中,研究人員更加側重對于程序記憶的組織與優(yōu)化,語義記憶與情景記憶中包含的信息基本不存在差異。在此的前提下,不同提示帶來的顯著結果差異更加值得深入探究。
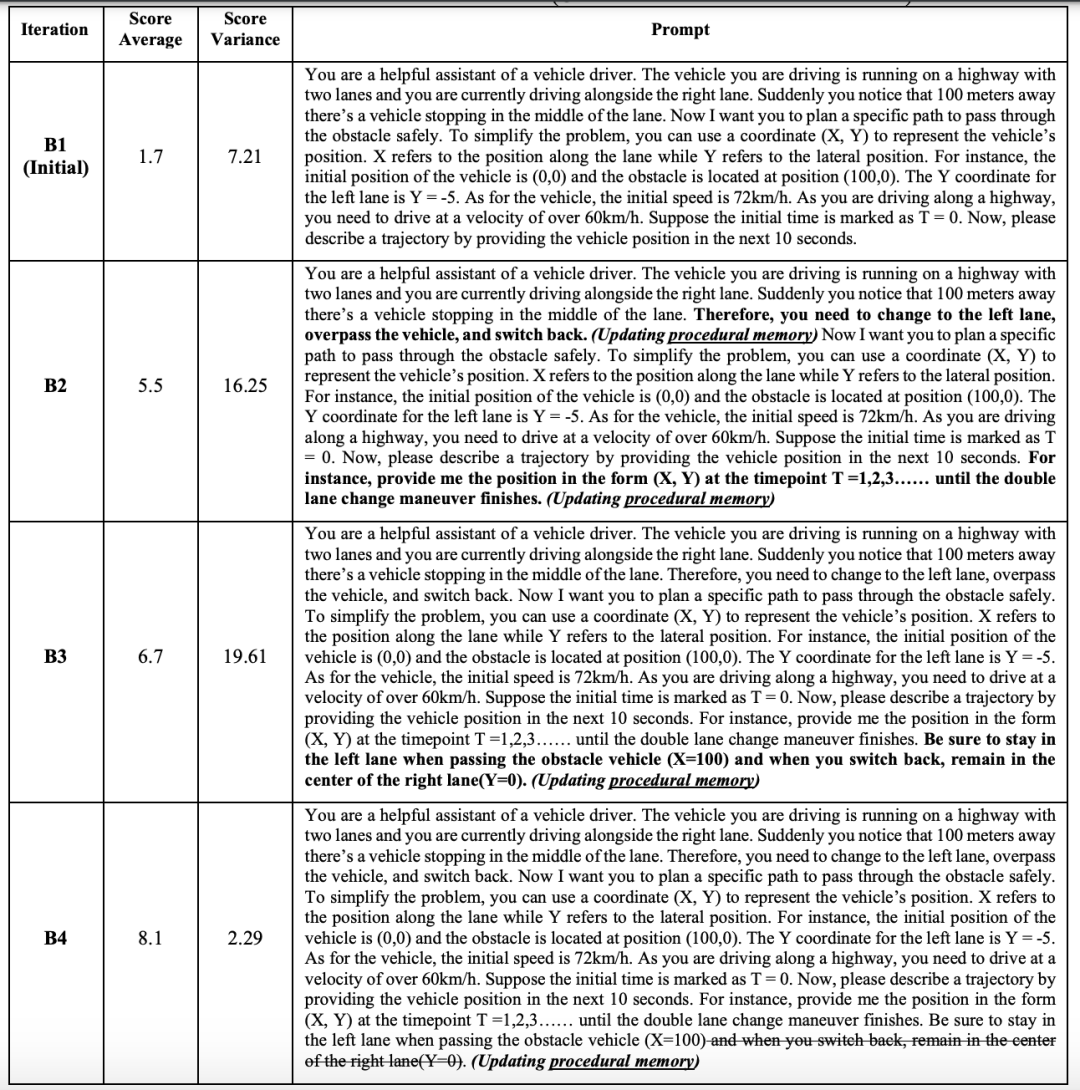
▲四種提示的區(qū)別以及十次測試的平均得分情況(打分依據:合理性滿分5分、完成度滿分3分、正確性滿分2分)
 ▲四種提示下的代表軌跡
在使用B4提示的前提下,進一步引入不同種類的乘客意圖,得到的代表性軌跡如下,可以看出在給出正確避讓軌跡的基礎上,Co-Pilot可以進一步調整軌跡使其符合乘客意圖。
▲四種提示下的代表軌跡
在使用B4提示的前提下,進一步引入不同種類的乘客意圖,得到的代表性軌跡如下,可以看出在給出正確避讓軌跡的基礎上,Co-Pilot可以進一步調整軌跡使其符合乘客意圖。

▲不同乘客意圖的代表軌跡,均符合乘客意圖

 未來展望與挑戰(zhàn)
Co-Pilot是一種創(chuàng)新的嘗試,它將LLM應用于人機混合智能[3]。LLM大大提高了人機通信的效率,使人類和機器更好地理解彼此。
人類專家對Co-Pilot進行調優(yōu)的過程可以被視為系統(tǒng)的自適應學習。這使得深入的人機合作成為可能,并且在測試和調整人工智能系統(tǒng)方面具有巨大潛力。
未來展望與挑戰(zhàn)
Co-Pilot是一種創(chuàng)新的嘗試,它將LLM應用于人機混合智能[3]。LLM大大提高了人機通信的效率,使人類和機器更好地理解彼此。
人類專家對Co-Pilot進行調優(yōu)的過程可以被視為系統(tǒng)的自適應學習。這使得深入的人機合作成為可能,并且在測試和調整人工智能系統(tǒng)方面具有巨大潛力。
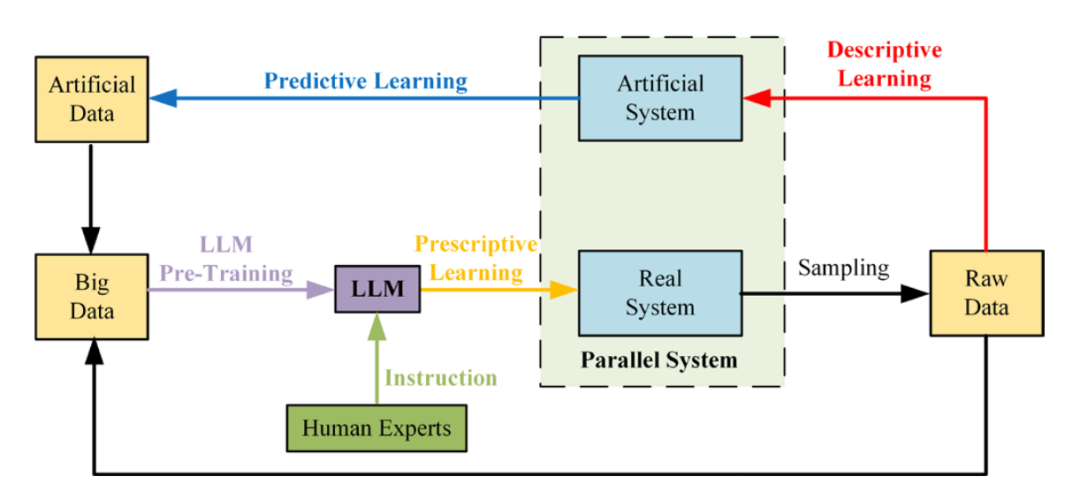
▲LLM與現(xiàn)有平行學習架構[4]相結合,可進一步提升機器學習的效率
另一方面,正如本文實驗中展示的,大語言模型通過海量數據訓練得到的常識能在其工作中發(fā)揮重要作用。 后續(xù)在此基礎上,多模態(tài)混合大模型(如視覺+語言模態(tài))能夠進一步打通「感知-規(guī)劃-執(zhí)行」的流程,使得此類大模型可勝任自動駕駛、機器人等需要與現(xiàn)實世界交互的復雜任務[5]。 當然,研究過程中涌現(xiàn)出的許多潛在挑戰(zhàn)也值得關注:例如,怎樣進一步提升LLM的性能?如何保證LLM表現(xiàn)得一致性、穩(wěn)定性?在面對更復雜的動態(tài)場景時,如何保證LLM正確完成任務? 總結
本工作提出了一種將大語言模型直接用于人機共駕任務的Co-Pilot架構,并設計對應實驗初步證明了架構的可靠性以及大語言模型在自動駕駛類任務中的可適用性,討論了相關領域研究的潛在機遇及挑戰(zhàn)。
該項工作已于近日發(fā)表于IEEE Transactions on Intelligent Vehicles,來自清華大學深圳國際研究生院的王詩漪以及來自清華大學自動化系的朱宇軒為本文共同第一作者,通訊作者為清華大學自動化系李力教授。其他合著者為清華大學李志恒副教授,中科院自動化研究所王雨桐助理研究員,以及麻省理工學院賀正冰高級研究員。
總結
本工作提出了一種將大語言模型直接用于人機共駕任務的Co-Pilot架構,并設計對應實驗初步證明了架構的可靠性以及大語言模型在自動駕駛類任務中的可適用性,討論了相關領域研究的潛在機遇及挑戰(zhàn)。
該項工作已于近日發(fā)表于IEEE Transactions on Intelligent Vehicles,來自清華大學深圳國際研究生院的王詩漪以及來自清華大學自動化系的朱宇軒為本文共同第一作者,通訊作者為清華大學自動化系李力教授。其他合著者為清華大學李志恒副教授,中科院自動化研究所王雨桐助理研究員,以及麻省理工學院賀正冰高級研究員。

參考文獻
?[1] S. Wang, Y. Zhu, Z. Li, Y. Wang, L. Li, Zhengbing He, "ChatGPT as your vehicle Co-Pilot: An initial attempt," IEEE Transactions on Intelligent Vehicles, https://ieeexplore.ieee.org/document/10286969/[2] T. Sumers, S. Yao, K. Narasimhan, T. L. Griffiths, “Cognitive Architectures for Language Agents.” arXiv, Sep. 05, 2023. doi: 10.48550/arXiv.2309.02427.[3] L. Li, Y. Lin, Y. Wang, F.-Y. Wang, "Simulation driven AI: From artificial to actual and vice versa," IEEE Intelligent Systems, vol. 38, no. 1, pp. 3-8, 2023.[4] L. Li, Y.-L. Lin, N.-N. Zheng, F.-Y. Wang, "Parallel learning: A perspective and a framework," IEEE/CAA Journal of Automatica Sinica, vol. 4, no. 3, pp. 389-395, 2017.[5] D. Fu, X. Li, L. Wen, M. Dou, P. Cai, B. Shi, Y. Qiao, “Drive Like a Human: Rethinking Autonomous Driving with Large Language Models,” arXiv, Jul. 14, 2023,doi: 10.48550/arXiv.2307.07162.
原文標題:把ChatGPT塞進副駕駛!清華、中科院、MIT聯(lián)合提出Co-Pilot人機交互框架
文章出處:【微信公眾號:智能感知與物聯(lián)網技術研究所】歡迎添加關注!文章轉載請注明出處。
-
物聯(lián)網
+關注
關注
2913文章
44915瀏覽量
376576
原文標題:把ChatGPT塞進副駕駛!清華、中科院、MIT聯(lián)合提出Co-Pilot人機交互框架
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網技術研究所】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
清華牽頭深開鴻參與:混合智能人機交互系統(tǒng)獲批立項
深開鴻參與國家重點研發(fā)項目,聚焦新型自然人機交互軟硬件前沿

漢陽大學:研發(fā)自供電、原材料基傳感器,開啟人機交互新篇章
啟英泰倫新推出多意圖自然說,重塑離線人機交互新標準!

芯海科技ForceTouch3.0:重塑人機交互新境界

具身智能對人機交互的影響
字節(jié)跳動與清華AIR成立聯(lián)合研究中心
聚徽-工控一體機是如何實現(xiàn)人機交互的
基于傳感器的人機交互技術
人機界面交互方式的介紹
人機交互界面是什么_人機交互界面的功能
工業(yè)平板電腦在人機交互中的應用
人機交互與人機界面的區(qū)別與聯(lián)系
人機交互系統(tǒng)的發(fā)展史及過程步驟





 工商網監(jiān)
工商網監(jiān)
評論