") 谷歌新作UFOGen:通過擴散GAN實現(xiàn)大規(guī)模文本到圖像生成
谷歌新作UFOGen:通過擴散GAN實現(xiàn)大規(guī)模文本到圖像生成
最近一年來,以 Stable Diffusion 為代表的一系列文生圖擴散模型徹底改變了視覺創(chuàng)作領域。數(shù)不清的用戶通過擴散模型產生的圖片提升生產力。但是,擴散模型的生成速度是一個老生常談的問題。因為降噪模型依賴于多步降噪來逐漸將初始的高斯噪音變?yōu)閳D片,因此需要對網絡多次計算,導致生成速度很慢。這導致大規(guī)模的文生圖擴散模型對一些注重實時性,互動性的應用非常不友好。隨著一系列技術的提出,從擴散模型中采樣所需的步數(shù)已經從最初的幾百步,到幾十步,甚至只需要 4-8 步。
最近,來自谷歌的研究團隊提出了UFOGen 模型,一種能極速采樣的擴散模型變種。通過論文提出的方法對 Stable Diffusion 進行微調,UFOGen 只需要一步就能生成高質量的圖片。與此同時,Stable Diffusion 的下游應用,比如圖生圖,ControlNet 等能力也能得到保留。

論文:https://arxiv.org/abs/2311.09257
從下圖可以看到,UFOGen 只需一步即可生成高質量,多樣的圖片。

提升擴散模型的生成速度并不是一個新的研究方向。之前關于這方面的研究主要集中在兩個方向。一個方向是設計更高效的數(shù)值計算方法,以求能達到利用更少的離散步數(shù)求解擴散模型的采樣 ODE 的目的。比如清華的朱軍團隊提出的 DPM 系列數(shù)值求解器,被驗證在 Stable Diffusion 上非常有效,能顯著地把求解步數(shù)從 DDIM 默認的 50 步降到 20 步以內。另一個方向是利用知識蒸餾的方法,將模型的基于 ODE 的采樣路徑壓縮到更小的步數(shù)。這個方向的例子是 CVPR2023 最佳論文候選之一的 Guided distillation,以及最近大火的 Latent Consistency Model (LCM)。尤其是 LCM,通過對一致性目標進行蒸餾,能夠將采樣步數(shù)降到只需 4 步,由此催生了不少實時生成的應用。
然而,谷歌的研究團隊在 UFOGen 模型中并沒有跟隨以上大方向,而是另辟蹊徑,利用了一年多前提出的擴散模型和 GAN 的混合模型思路。他們認為前面提到的基于 ODE 的采樣和蒸餾有其根本的局限性,很難將采樣步數(shù)壓縮到極限。因此想實現(xiàn)一步生成的目標,需要打開新的思路。
擴散模型和 GAN 的混合模型最早是英偉達的研究團隊在 ICLR 2022 上提出的 DDGAN(《Tackling the Generative Learning Trilemma with Denoising Diffusion GANs》)。其靈感來自于普通擴散模型對降噪分布進行高斯假設的根本缺陷。簡單來說,擴散模型假設其降噪分布(給定一個加了噪音的樣本,對噪音含量更少的樣本的條件分布)是一個簡單的高斯分布。然而,隨機微分方程理論證明這樣的假設只在降噪步長趨于 0 的時候成立,因此擴散模型需要大量重復的降噪步數(shù)來保證小的降噪步長,導致很慢的生成速度。
DDGAN 提出拋棄降噪分布的高斯假設,而是用一個帶條件的 GAN 來模擬這個降噪分布。因為 GAN 具有極強的表示能力,能模擬復雜的分布,所以可以取較大的降噪步長來達到減少步數(shù)的目的。然而,DDGAN 將擴散模型穩(wěn)定的重構訓練目標變成了 GAN 的訓練目標,很容易造成訓練不穩(wěn)定,從而難以延伸到更復雜的任務。在 NeurIPS 2023 上,和創(chuàng)造 UGOGen 的同樣的谷歌研究團隊提出了 SIDDM(論文標題 Semi-Implicit Denoising Diffusion Models),將重構目標函數(shù)重新引入了 DDGAN 的訓練目標,使訓練的穩(wěn)定性和生成質量都相比于 DDGAN 大幅提高。
SIDDM 作為 UFOGen 的前身,只需要 4 步就能在 CIFAR-10, ImageNet 等研究數(shù)據(jù)集上生成高質量的圖片。但是SIDDM 有兩個問題需要解決:首先,它不能做到理想狀況的一步生成;其次,將其擴展到更受關注的文生圖領域并不簡單。為此,谷歌的研究團隊提出了 UFOGen,解決這兩個問題。
具體來說,對于問題一,通過簡單的數(shù)學分析,該團隊發(fā)現(xiàn)通過改變生成器的參數(shù)化方式,以及改變重構損失函數(shù)計算的計算方式,理論上模型可以實現(xiàn)一步生成。對于問題二,該團隊提出利用已有的 Stable Diffusion 模型進行初始化來讓 UFOGen 模型更快更好的擴展到文生圖任務上。值得注意的是,SIDDM 就已經提出讓生成器和判別器都采用 UNet 架構,因此基于該設計,UFOGen 的生成器和判別器都是由 Stable Diffusion 模型初始化的。這樣做可以最大限度地利用 Stable Diffusion 的內部信息,尤其是關于圖片和文字的關系的信息。這樣的信息很難通過對抗學習來獲得。訓練算法和圖示見下。

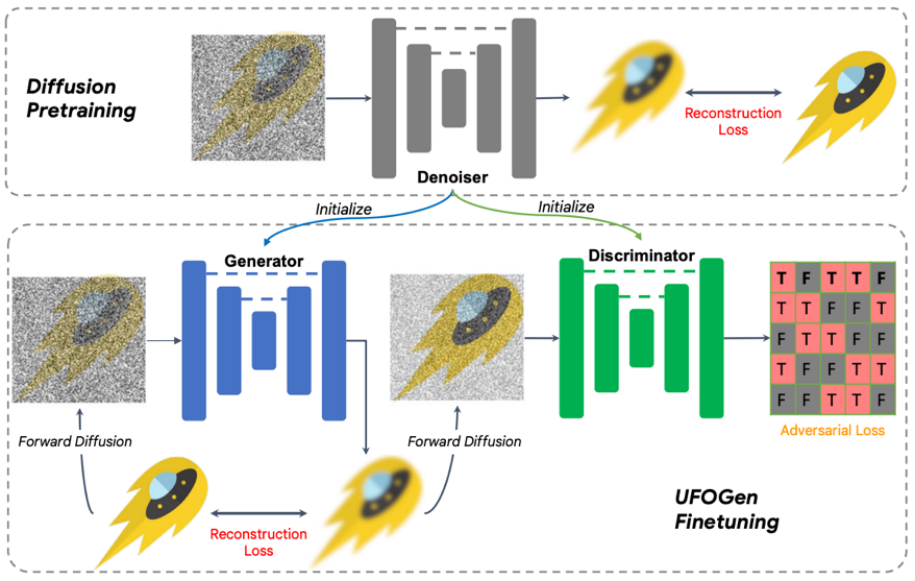
值得注意的是,在這之前也有一些利用 GAN 做文生圖的工作,比如英偉達的 StyleGAN-T,Adobe 的 GigaGAN,都是將 StyleGAN 的基本架構擴展到更大的規(guī)模,從而也能一步文生圖。UFOGen 的作者指出,比起之前基于 GAN 的工作,除了生成質量外,UFOGen 還有幾點優(yōu)勢:
1. 純粹的 GAN 訓練非常不穩(wěn)定,尤其是對文生圖任務來說,判別器不但需要判別圖片的紋理,還需要理解圖片和文字的匹配程度,而這是十分困難的任務,尤其在訓練早期。因此,之前的 GAN 模型比如 GigaGAN,引入大量的輔助 loss 來幫助訓練,這使得訓練和調參變得異常困難。UFOGen 因為有重構損失,GAN 在這里起到輔助作用,因此訓練非常穩(wěn)定。
2. 直接從頭開始訓練 GAN 除了不穩(wěn)定還異常昂貴,尤其是在文生圖這樣需要大量數(shù)據(jù)和訓練步數(shù)的任務下。因為需要同時更新兩組參數(shù),GAN 的訓練比擴散模型來說消耗的時間和內存都更大。UFOGen 的創(chuàng)新設計能從 Stable Diffusion 中初始化參數(shù),大大節(jié)約了訓練時間。通常收斂只需要幾萬步訓練。
3. 文生圖擴散模型的一大魅力在于能適用于其他任務,包括不需要微調的應用比如圖生圖,已經需要微調的應用比如可控生成。之前的 GAN 模型很難擴展到這些下游任務,因為微調 GAN 一直是個難題。相反,UFOGen 擁有擴散模型的框架,因此能更簡單地應用到這些任務上。下圖展示了 UFOGen 的圖生圖以及可控生成的例子,注意這些生成也只需要一步采樣。

實驗表明,UFOGen 只需一步采樣便可以生成高質量的,符合文字描述的圖片。在和近期提出的針對擴散模型的高速采樣方法的對比中(包括 Instaflow,以及大火的 LCM),UFOGen 展示出了很強的競爭力。甚至和 50 步采樣的 Stable Diffusion 相比,UFOGen 生成的樣本在觀感上也沒有表現(xiàn)得更弱。下面是一些對比結果:

總結
通過提升現(xiàn)有的擴散模型和 GAN 的混合模型,谷歌團隊提出了強大的能實現(xiàn)一步文生圖的 UFOGen 模型。該模型可以由 Stable Diffusion 微調而來,在保證一步文生圖能力的同時,還能適用于不同的下游應用。作為實現(xiàn)超快速文本到圖像合成的早期工作之一,UFOGen 為高效率生成模型領域開啟了一條新道路。
-
GaN
+關注
關注
19文章
1936瀏覽量
73489 -
生成器
+關注
關注
7文章
315瀏覽量
21020 -
圖像生成
+關注
關注
0文章
22瀏覽量
6896
原文標題:谷歌新作UFOGen:通過擴散GAN實現(xiàn)大規(guī)模文本到圖像生成
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦

大規(guī)模MIMO的性能
圖像生成對抗生成網絡gan_GAN生成汽車圖像 精選資料推薦
一個benchmark實現(xiàn)大規(guī)模數(shù)據(jù)集上的OOD檢測
必讀!生成對抗網絡GAN論文TOP 10
生成對抗網絡GAN論文TOP 10,幫助你理解最先進技術的基礎
擴散模型在視頻領域表現(xiàn)如何?
蒸餾無分類器指導擴散模型的方法
一種「個性化」的文本到圖像擴散模型 DreamBooth
通過Arduino代碼生成器或藍牙加載圖像和文本

谷歌新作Muse:通過掩碼生成Transformer進行文本到圖像生成
基于文本到圖像模型的可控文本到視頻生成






 工商網監(jiān)
工商網監(jiān)
評論