") 用語(yǔ)言對(duì)齊多模態(tài)信息,北大騰訊等提出LanguageBind,刷新多個(gè)榜單
用語(yǔ)言對(duì)齊多模態(tài)信息,北大騰訊等提出LanguageBind,刷新多個(gè)榜單
在博士畢業(yè)就有10篇ACL一作的師兄指導(dǎo)下是種什么體驗(yàn)
北京大學(xué)與騰訊等機(jī)構(gòu)的研究者們提出了多模態(tài)對(duì)齊框架 ——LanguageBind。該框架在視頻、音頻、文本、深度圖和熱圖像等五種不同模態(tài)的下游任務(wù)中取得了卓越的性能,刷榜多項(xiàng)評(píng)估榜單,這標(biāo)志著多模態(tài)學(xué)習(xí)領(lǐng)域向著「大一統(tǒng)」理念邁進(jìn)了重要一步。
在現(xiàn)代社會(huì),信息傳遞和交流不再局限于單一模態(tài)。我們生活在一個(gè)多模態(tài)的世界里,聲音、視頻、文字和深度圖等模態(tài)信息相互交織,共同構(gòu)成了我們豐富的感知體驗(yàn)。這種多模態(tài)的信息交互不僅存在于人類社會(huì)的溝通中,同樣也是機(jī)器理解世界所必須面對(duì)的挑戰(zhàn)。
如何讓機(jī)器像人類一樣理解和處理這種多模態(tài)的數(shù)據(jù),成為了人工智能領(lǐng)域研究的前沿問題。
在過去的十年里,隨著互聯(lián)網(wǎng)和智能設(shè)備的普及,視頻內(nèi)容的數(shù)量呈爆炸式增長(zhǎng)。視頻平臺(tái)如 YouTube、TikTok 和 Bilibili 等匯聚了億萬(wàn)用戶上傳和分享的視頻內(nèi)容,涵蓋了娛樂、教育、新聞報(bào)道、個(gè)人日志等各個(gè)方面。如此龐大的視頻數(shù)據(jù)量為人類提供了前所未有的信息和知識(shí)。為了解決這些視頻理解任務(wù),人們采用了視頻 - 語(yǔ)言(VL)預(yù)訓(xùn)練方法,將計(jì)算機(jī)視覺和自然語(yǔ)言處理結(jié)合起來,這些模型能夠捕捉視頻語(yǔ)義并解決下游任務(wù)。
然而,目前的 VL 預(yù)訓(xùn)練方法通常僅適用于視覺和語(yǔ)言模態(tài),而現(xiàn)實(shí)世界中的應(yīng)用場(chǎng)景往往包含更多的模態(tài)信息,如深度圖、熱圖像等。如何整合和分析不同模態(tài)的信息,并且能夠在多個(gè)模態(tài)之間建立準(zhǔn)確的語(yǔ)義對(duì)應(yīng)關(guān)系,成為了多模態(tài)領(lǐng)域的一個(gè)新的挑戰(zhàn)。
為了應(yīng)對(duì)這一難題,北大與騰訊的研究人員提出了一種新穎的多模態(tài)對(duì)齊框架 ——LanguageBind。與以往依賴圖像作為主導(dǎo)模態(tài)的方法不同,LanguageBind 采用語(yǔ)言作為多模態(tài)信息對(duì)齊的紐帶。

論文地址:https://arxiv.org/pdf/2310.01852.pdf
GitHub 地址:https://github.com/PKU-YuanGroup/LanguageBind
Huggingface 地址:https://huggingface.co/LanguageBind
語(yǔ)言因其內(nèi)在的語(yǔ)義豐富性和表現(xiàn)力,被賦予了整合和引導(dǎo)其他模態(tài)信息對(duì)齊的能力。在這個(gè)框架下,語(yǔ)言不再是附屬于視覺信息的標(biāo)注或說明,而是成為了聯(lián)合視覺、音頻和其他模態(tài)的中心通道。
LanguageBind 通過將所有模態(tài)的信息映射到一個(gè)統(tǒng)一的語(yǔ)言導(dǎo)向的嵌入空間,實(shí)現(xiàn)了不同模態(tài)之間的語(yǔ)義對(duì)齊。這種對(duì)齊方法避免了通過圖像中介可能引入的信息損失,提高了多模態(tài)信息處理的準(zhǔn)確性和效率。更重要的是,這種方法為未來的擴(kuò)展提供了靈活性,允許簡(jiǎn)單地添加新的模態(tài),而無(wú)需重新設(shè)計(jì)整個(gè)系統(tǒng)。
此外,該研究團(tuán)隊(duì)構(gòu)建了 VIDAL-10M 數(shù)據(jù)集,這是一個(gè)大規(guī)模、包含多模態(tài)數(shù)據(jù)對(duì)的數(shù)據(jù)集。
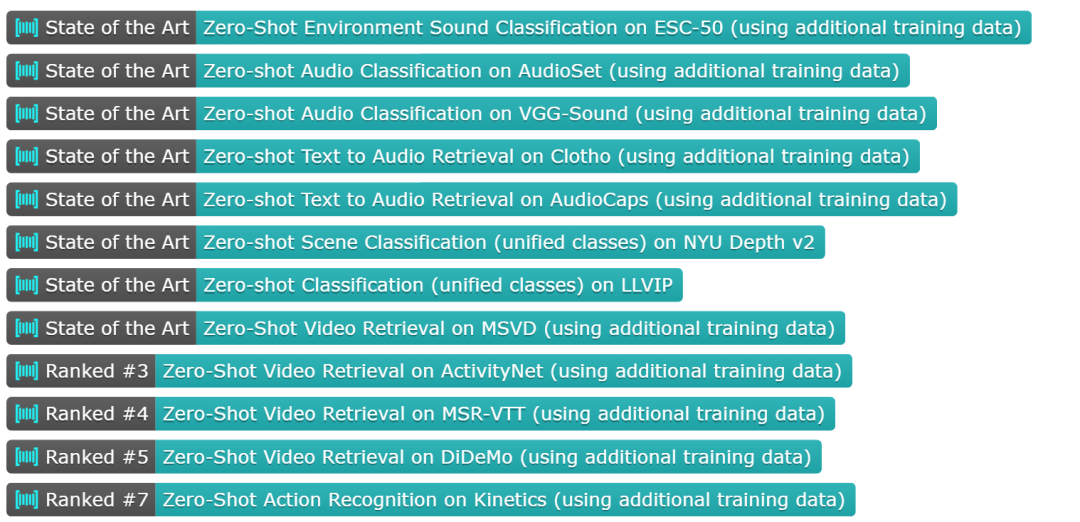
VIDAL-10M 涵蓋了視頻 - 語(yǔ)言、紅外 - 語(yǔ)言、深度 - 語(yǔ)言和音頻 - 語(yǔ)言配對(duì),以確保跨模態(tài)的信息是完整且一致的。通過在該數(shù)據(jù)集上進(jìn)行訓(xùn)練,LanguageBind 在視頻、音頻、深度和紅外等 15 個(gè)廣泛的基準(zhǔn)測(cè)試中取得了卓越的性能表現(xiàn)。
方法介紹
在多模態(tài)信息處理領(lǐng)域,主流的對(duì)齊技術(shù),如 ImageBind,主要依賴圖像作為橋梁來實(shí)現(xiàn)不同模態(tài)之間的間接對(duì)齊。這種方法在對(duì)其他模態(tài)和語(yǔ)言模態(tài)的對(duì)齊上可能會(huì)導(dǎo)致性能次優(yōu)化,因?yàn)樗枰獌刹睫D(zhuǎn)換過程 —— 首先是從目標(biāo)模態(tài)到圖像模態(tài),然后是從圖像模態(tài)到語(yǔ)言模態(tài)。這種間接對(duì)齊可能導(dǎo)致語(yǔ)義信息在轉(zhuǎn)換過程中的衰減,從而影響最終的性能表現(xiàn)。
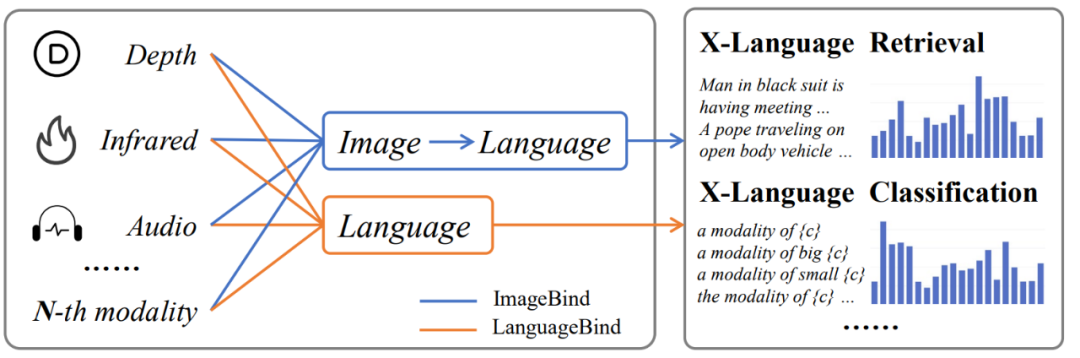
針對(duì)這一問題,該團(tuán)隊(duì)提出了一種名為 LanguageBind 的多模態(tài)語(yǔ)義對(duì)齊預(yù)訓(xùn)練框架。該框架摒棄了依賴圖像作為中介的傳統(tǒng)模式,而是直接利用語(yǔ)言模態(tài)作為不同模態(tài)之間的紐帶。語(yǔ)言模態(tài)因其天然的語(yǔ)義豐富性,成為連接視覺、音頻、深度等模態(tài)的理想選擇。LanguageBind 框架通過利用對(duì)比學(xué)習(xí)機(jī)制,將不同模態(tài)的數(shù)據(jù)映射到一個(gè)共享的語(yǔ)義嵌入空間中。在這個(gè)空間里,不同模態(tài)的信息可以直接進(jìn)行語(yǔ)義層面的理解與對(duì)齊。
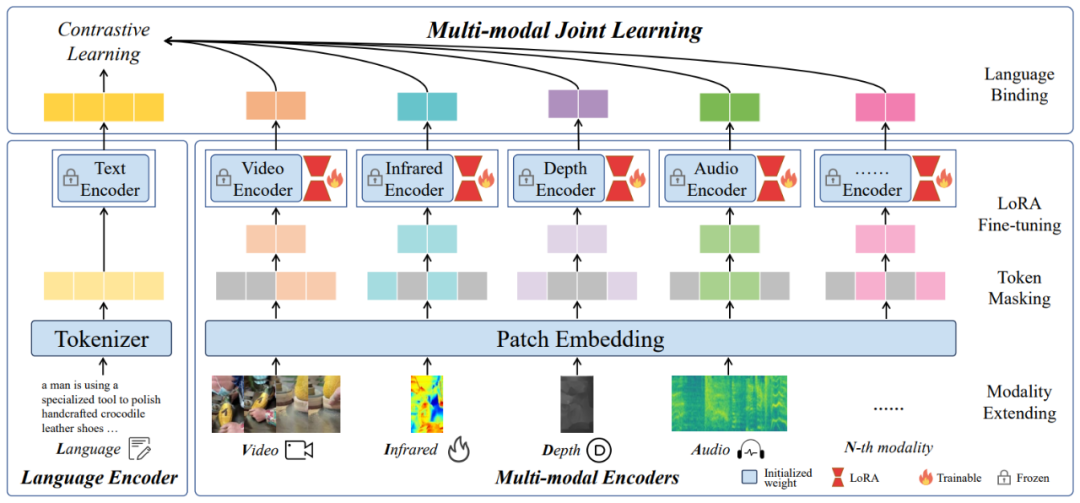
LanguageBind 概覽圖
具體而言,LanguageBind 通過錨定語(yǔ)言模態(tài),采用一系列優(yōu)化的對(duì)比學(xué)習(xí)策略,對(duì)多模態(tài)數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練。這一過程中,模型學(xué)習(xí)將來自不同模態(tài)的數(shù)據(jù)編碼到與語(yǔ)言模態(tài)相兼容的表征中,確保了模態(tài)間的語(yǔ)義一致性。這種直接的跨模態(tài)語(yǔ)義對(duì)齊避免了傳統(tǒng)方法中的性能損失,同時(shí)提高了模型在下游多模態(tài)任務(wù)中的泛化能力和適用性。
LanguageBind 框架的另一個(gè)優(yōu)點(diǎn)是其擴(kuò)展性。由于直接使用語(yǔ)言作為核心對(duì)齊模態(tài),當(dāng)引入新的模態(tài)時(shí),無(wú)需重構(gòu)整個(gè)對(duì)齊機(jī)制,只需通過相同的對(duì)比學(xué)習(xí)過程,將新模態(tài)的數(shù)據(jù)映射到已經(jīng)建立的語(yǔ)言導(dǎo)向嵌入空間。這使得 LanguageBind 不僅適用于現(xiàn)有的模態(tài),也能輕松適應(yīng)未來可能出現(xiàn)的新模態(tài),為多模態(tài)預(yù)訓(xùn)練技術(shù)的發(fā)展奠定了堅(jiān)實(shí)基礎(chǔ)。
數(shù)據(jù)集介紹
在跨模態(tài)預(yù)訓(xùn)練領(lǐng)域,數(shù)據(jù)集的構(gòu)建及其質(zhì)量對(duì)于預(yù)訓(xùn)練模型的性能與應(yīng)用效能具有決定性影響。傳統(tǒng)的多模態(tài)數(shù)據(jù)集大多局限于二模態(tài)或三模態(tài)的配對(duì)數(shù)據(jù),這種限制導(dǎo)致了對(duì)更豐富模態(tài)對(duì)齊數(shù)據(jù)集的需求。
因而,該團(tuán)隊(duì)開發(fā)了 VIDAL-10M 數(shù)據(jù)集,這是一個(gè)創(chuàng)新的五模態(tài)數(shù)據(jù)集,包含了視頻 - 語(yǔ)言(VL)、紅外 - 語(yǔ)言(IL)、深度 - 語(yǔ)言(DL)、音頻 - 語(yǔ)言(AL)等數(shù)據(jù)對(duì)。每個(gè)數(shù)據(jù)對(duì)都經(jīng)過了精心的質(zhì)量篩選,旨在為跨模態(tài)預(yù)訓(xùn)練領(lǐng)域提供一個(gè)高品質(zhì)、高完整性的訓(xùn)練基礎(chǔ)。

VIDAL-10M 數(shù)據(jù)集示例
VIDAL-10M 數(shù)據(jù)集的構(gòu)建主要包括三步:
視覺相關(guān)搜索詞庫(kù)構(gòu)建。設(shè)計(jì)一種創(chuàng)新的搜索詞獲取策略,該策略綜合利用了各類視覺任務(wù)數(shù)據(jù)集中的文本信息,如標(biāo)簽和標(biāo)題,以構(gòu)建一個(gè)豐富視覺概念且多樣化的視頻數(shù)據(jù)集,從而增強(qiáng)了數(shù)據(jù)多樣性和覆蓋度。
視頻和音頻數(shù)據(jù)的收集、清洗與篩選:在數(shù)據(jù)的收集過程中,該研究采取了基于文本、視覺和音頻內(nèi)容的多種過濾機(jī)制,這些機(jī)制確保收集到的視頻和音頻數(shù)據(jù)與搜索詞高度相關(guān),并且滿足高標(biāo)準(zhǔn)的質(zhì)量要求。這一步驟是確保數(shù)據(jù)集質(zhì)量的關(guān)鍵環(huán)節(jié),它直接影響模型訓(xùn)練的效果和后續(xù)任務(wù)的性能。
紅外、深度模態(tài)數(shù)據(jù)生成與多視角文本增強(qiáng)。此階段,利用多種先進(jìn)的生成模型技術(shù)合成了紅外和深度模態(tài)數(shù)據(jù),并對(duì)文本內(nèi)容進(jìn)行了多角度的生成和增強(qiáng)。多視角文本增強(qiáng)包括了標(biāo)題、標(biāo)簽、關(guān)鍵幀描述、視頻概要等多個(gè)維度,它為視頻內(nèi)容提供了全面且細(xì)致的描述,增強(qiáng)了數(shù)據(jù)的語(yǔ)義豐富性和描述的細(xì)粒度。

VIDAL-10M 數(shù)據(jù)集的構(gòu)建過程
實(shí)驗(yàn)
LanguageBind 框架被應(yīng)用于多個(gè)模態(tài)的零樣本分類任務(wù),并與其他模型進(jìn)行了性能比較。實(shí)驗(yàn)結(jié)果顯示,LanguageBind 方法在包括視頻、音頻、深度圖像、熱成像等多模態(tài)數(shù)據(jù)上的 15 個(gè)零樣本分類與檢索任務(wù)中均展示了顯著的性能提升。這些實(shí)驗(yàn)成果強(qiáng)調(diào)了 LanguageBind 方法在理解和處理不同模態(tài)數(shù)據(jù)中的潛在能力,尤其是在沒有先前樣本可供學(xué)習(xí)的情況下。為了更深入地了解 LanguageBind 方法的性能,可以參照以下詳細(xì)的實(shí)驗(yàn)結(jié)果。
表 2 顯示,LanguageBind 的性能在 MSR-VTT 上超過 VideoCoca 和 OmniVL ,盡管僅使用 300 萬(wàn)個(gè)視頻 - 文本對(duì)。
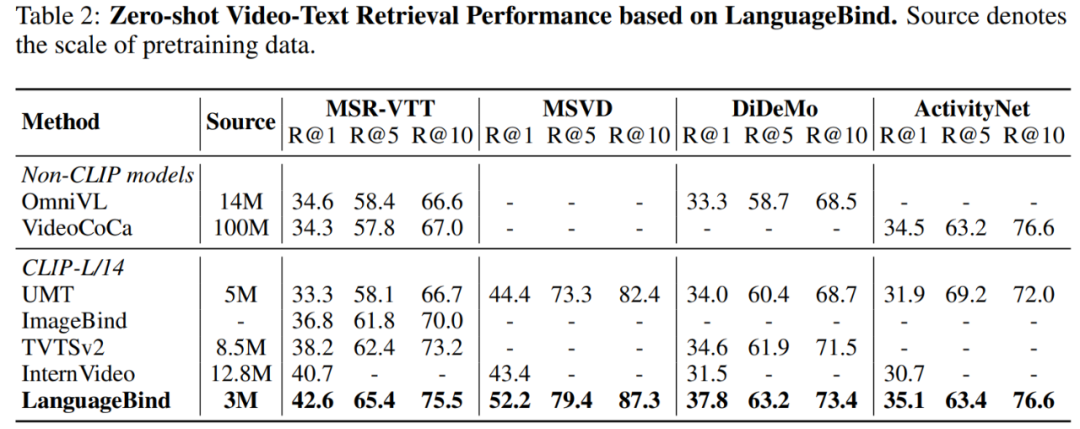
在兩個(gè)經(jīng)典數(shù)據(jù)集 MSR-VTT 和 MSVD 上進(jìn)行的零樣本視頻 - 文本檢索實(shí)驗(yàn)結(jié)果如表 3 所示:
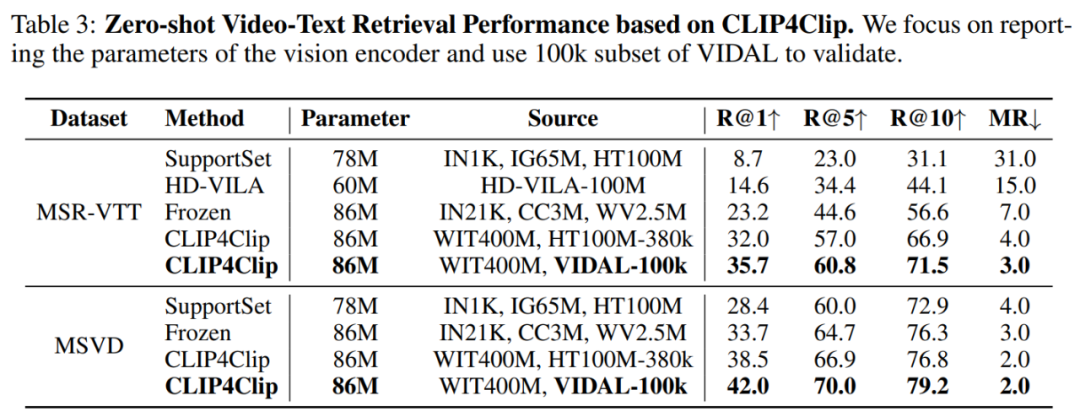
該研究還將本文模型與 SOTA 多模態(tài)預(yù)訓(xùn)練模型 OpenCLIP、ImageBind 在多模態(tài)理解任務(wù)上進(jìn)行了比較,結(jié)果如表 4 所示:
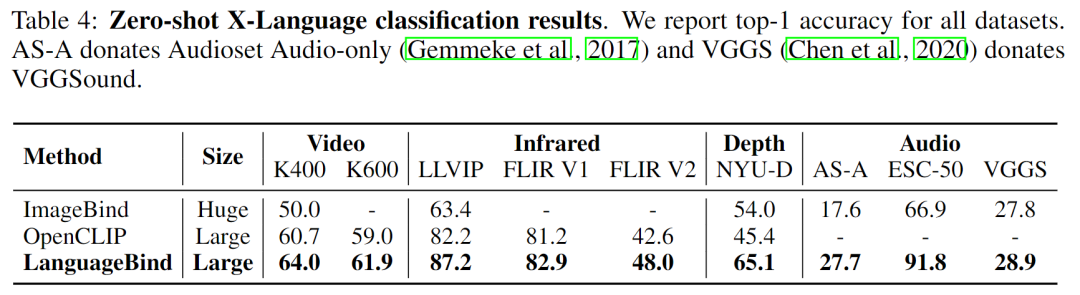
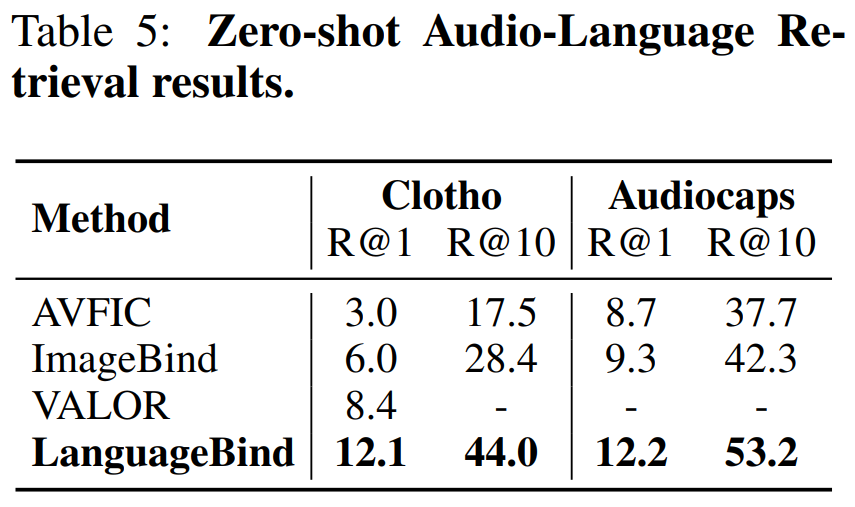
表 5 比較了在 Clotho 數(shù)據(jù)集和 Audiocaps 數(shù)據(jù)集上的零樣本文本 - 音頻檢索性能:
-
圖像
+關(guān)注
關(guān)注
2文章
1085瀏覽量
40475 -
模型
+關(guān)注
關(guān)注
1文章
3247瀏覽量
48855 -
智能設(shè)備
+關(guān)注
關(guān)注
5文章
1058瀏覽量
50600 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24710
原文標(biāo)題:用語(yǔ)言對(duì)齊多模態(tài)信息,北大騰訊等提出LanguageBind,刷新多個(gè)榜單
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
商湯日日新多模態(tài)大模型權(quán)威評(píng)測(cè)第一
一文理解多模態(tài)大語(yǔ)言模型——下

一文理解多模態(tài)大語(yǔ)言模型——上

利用OpenVINO部署Qwen2多模態(tài)模型
云知聲山海多模態(tài)大模型UniGPT-mMed登頂MMMU測(cè)評(píng)榜首

Meta發(fā)布多模態(tài)LLAMA 3.2人工智能模型
智譜AI發(fā)布全新多模態(tài)開源模型GLM-4-9B
智譜AI領(lǐng)跑司南OpenCompass 2.0月度榜單,GLM-4展示強(qiáng)大實(shí)力
李未可科技正式推出WAKE-AI多模態(tài)AI大模型

AI機(jī)器人迎來多模態(tài)模型
fpga通用語(yǔ)言是什么
韓國(guó)Kakao宣布開發(fā)多模態(tài)大語(yǔ)言模型“蜜蜂”
機(jī)器人基于開源的多模態(tài)語(yǔ)言視覺大模型

什么是多模態(tài)?多模態(tài)的難題是什么?

OneLLM:對(duì)齊所有模態(tài)的框架!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論