") 香港大學最新提出!實現(xiàn)超現(xiàn)實的人類圖像生成:HyperHuman
香港大學最新提出!實現(xiàn)超現(xiàn)實的人類圖像生成:HyperHuman
1、導讀
盡管大規(guī)模文本到圖像模型取得了重大進展,但實現(xiàn)超現(xiàn)實的人類圖像生成仍然是一項理想但尚未解決的任務。現(xiàn)有模型(例如穩(wěn)定擴散和DALL·E2)往往會生成部分不連貫或姿勢不自然的人體圖像。為了應對這些挑戰(zhàn),我們的主要見解是,人類圖像本質(zhì)上具有多個粒度的結(jié)構(gòu),從粗粒度的身體骨骼到細粒度的空間幾何。因此,在一個模型中捕獲顯式外觀和潛在結(jié)構(gòu)之間的這種相關(guān)性對于生成連貫且自然的人類圖像至關(guān)重要。為此,我們提出了一個統(tǒng)一的框架HyperHuman,它可以生成高度真實和多樣化布局的野外人類圖像。具體來說:
我們首先構(gòu)建一個以人類為中心的大規(guī)模數(shù)據(jù)集,名為HumanVerse,它由3.4億張圖像組成,具有人體姿勢、深度和表面法線等全面注釋。
接下來,我們提出了一種潛在結(jié)構(gòu)擴散模型,該模型可以同時對深度和表面法線以及合成的 RGB 圖像進行去噪。我們的模型在統(tǒng)一網(wǎng)絡(luò)中強制執(zhí)行圖像外觀、空間關(guān)系和幾何形狀的聯(lián)合學習,其中模型中的每個分支在結(jié)構(gòu)意識和紋理豐富性方面相互補充。
最后,為了進一步提高視覺質(zhì)量,我們提出了一種結(jié)構(gòu)引導細化器來組合預測條件,以更詳細地生成更高分辨率。大量的實驗表明,我們的框架具有最先進的性能,可以在不同的場景下生成超逼真的人類圖像。
2、介紹

所提出的HyperHuman同時生成以文本和骨架為條件的粗略 RGB、深度、法線和高分辨率圖像。可以創(chuàng)建逼真的圖像和風格化的渲染。

我們與最近的T2I模型進行比較,顯示出更好的真實性、質(zhì)量、多樣性和可控性。請注意,在每個2x2網(wǎng)格(左)中,左上角是輸入骨架,而其他部分是聯(lián)合去噪的法線、深度和512x512的粗略 RGB。對于完整模型,我們合成的圖像高達 1024x1024(右)
3、方法
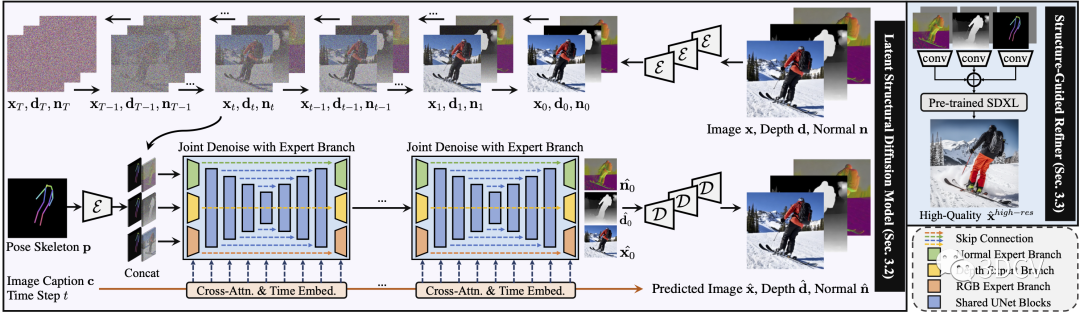
在潛在結(jié)構(gòu)擴散模型(紫色)中,圖像x、深度d和表面法線n對標題c和姿勢骨架p進行聯(lián)合去噪調(diào)節(jié)。在結(jié)構(gòu)引導精煉器(藍色)中,我們構(gòu)建了更高分辨率生成的預測條件。請注意,灰色圖像是指隨機丟棄條件,以實現(xiàn)更穩(wěn)健的訓練。
4、實驗
MS-COCO 2014 驗證人類的零樣本評估
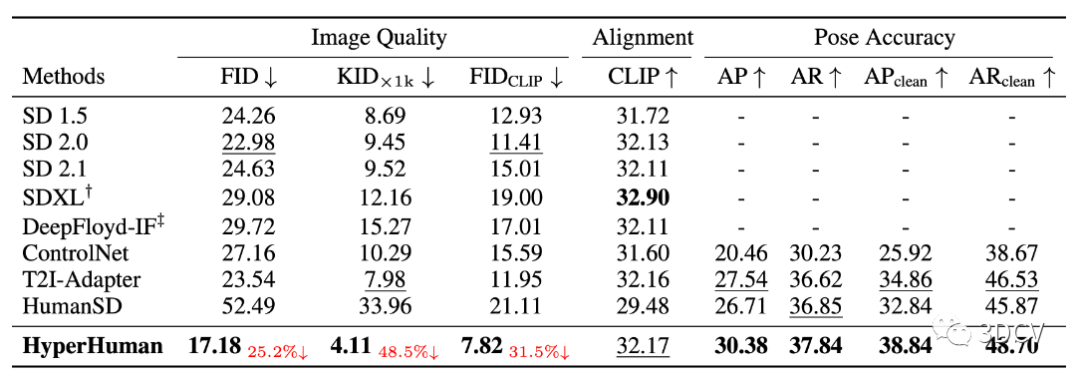
我們將我們的模型與最近的 SOTA 通用 T2I 模型(Stable Diffusion v1.5、v2.0、v2.1;SDXL;DeepFloyd-IF)和可控方法(ControlNet;T2I-Adapter;HumanSD)進行比較。請注意,SDXL 生成 512x512 的藝術(shù)風格,而 IF 僅創(chuàng)建固定大小的圖像,我們首先生成 1024x1024 結(jié)果,然后針對這兩種方法將大小調(diào)整回 512x512。
MS-COCO 2014 驗證人類子集的評估曲線
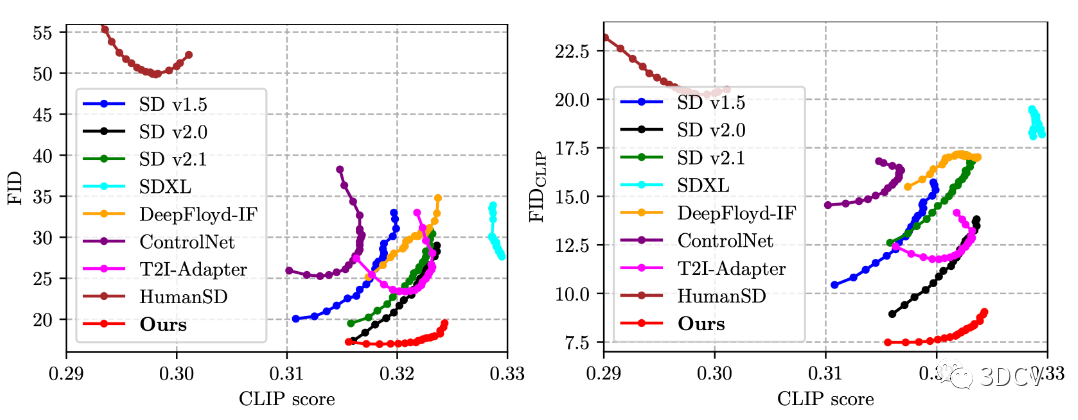
我們展示了所有方法的FID-CLIP(左)和FID CLIP -CLIP(右曲線,CFG比例范圍為4.0至20.0。
用戶偏好比較

我們報告了用戶更喜歡我們的模型而不是基線的比率
5、結(jié)論
我們提出了一種新穎的框架HyperHuman來生成高質(zhì)量的野外人體圖像。為了在統(tǒng)一網(wǎng)絡(luò)中加強圖像外觀、空間關(guān)系和幾何形狀的聯(lián)合學習,我們提出了潛在結(jié)構(gòu)擴散模型,該模型可同時對深度和法線以及RGB進行去噪。然后我們設(shè)計了結(jié)構(gòu)引導優(yōu)化器來構(gòu)建詳細生成的預測條件。大量的實驗證明我們的框架具有卓越的性能,可以在不同的場景下生成逼真的人類。
-
框架
+關(guān)注
關(guān)注
0文章
403瀏覽量
17497 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24710 -
圖像生成
+關(guān)注
關(guān)注
0文章
22瀏覽量
6896
原文標題:香港大學最新提出!實現(xiàn)超現(xiàn)實的人類圖像生成:HyperHuman
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于擴散模型的圖像生成過程

香港大學首創(chuàng)光熱電統(tǒng)一理論可解決LED燈泡發(fā)光不均與壽命問題
香港大學借助基因工程造出世界首個人造心臟
一場探索人類與太陽關(guān)系的VR舞蹈體驗
清華大學將與香港大學合作進行AI研究
香港大學發(fā)布新冠肺炎AI成果,準確率高達88%
人體圖像合成制作可信和逼真的人類圖像
香港大學實現(xiàn)機器人觸覺傳感器的自解耦和超分辨率
香港大學機器魚創(chuàng)下吉尼斯世界紀錄






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論