 aikit 2023 3D與機械臂結合!
aikit 2023 3D與機械臂結合!
引言
今天我們主要了解3D攝像頭是如何跟機械臂應用相結合的。我們最近準備推出一款新的機械臂套裝AI Kit 2023 3D,熟悉我們的老用戶應該知道,我們之前的AI Kit 2023套裝使用的是2D攝像頭。
隨著技術進步,市場需求和領域的擴大,2D的攝像頭已經不能夠滿足很多場景。3D攝像頭也在近些年間火了起來。隨著我們的步伐,一起來認識一下3D攝像頭帶給我們的應用。
產品介紹
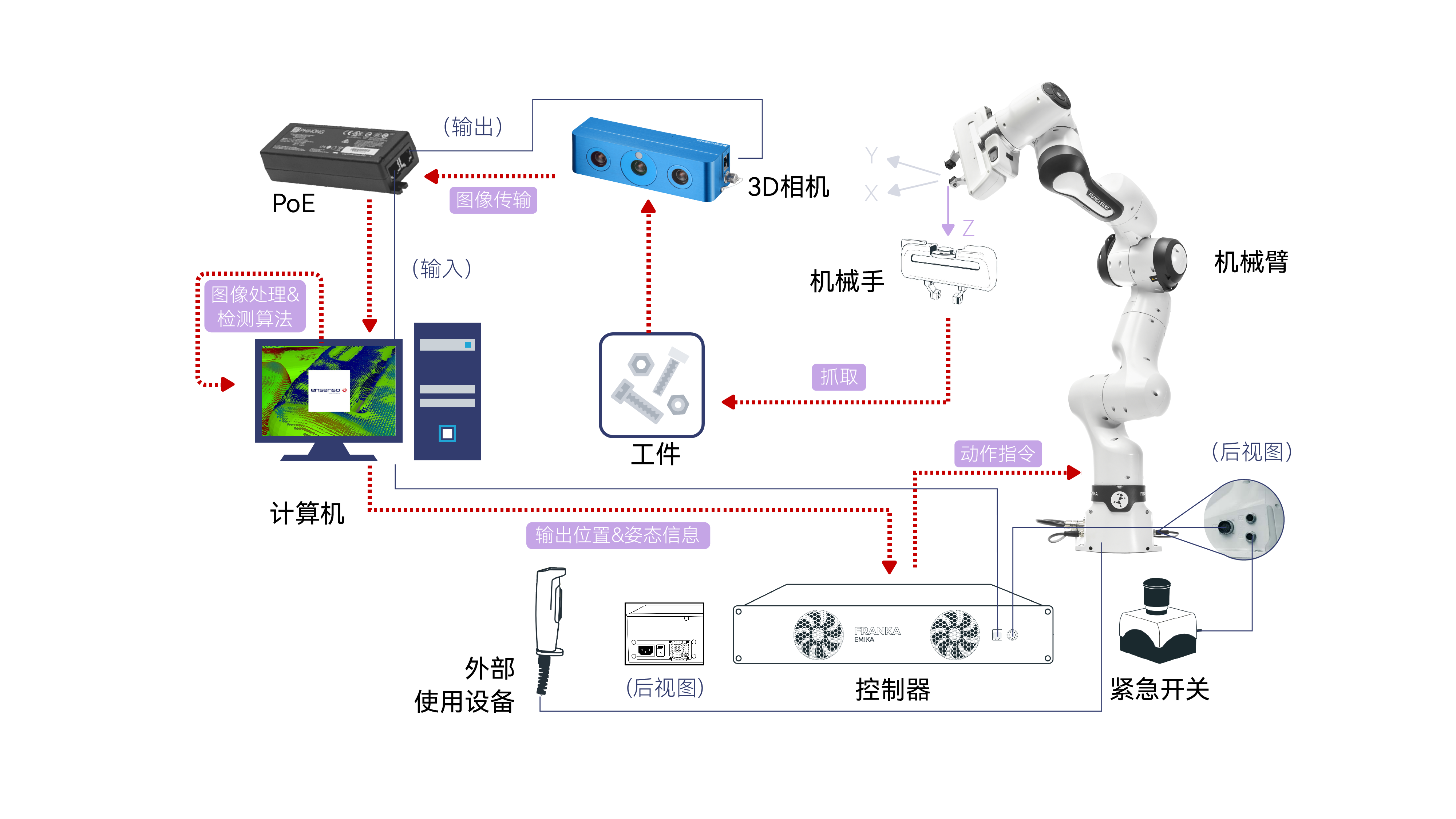
RealSence-Depth camera

我們今天涉及到的3D攝像頭是RealSence是Intel公司開發的一種深度感知攝像頭。可以從圖片中看出來,這個相機有四個鏡頭,它們分別是一個紅外激光投影儀,兩個紅外攝像頭和一個彩色攝像頭。這幾個鏡頭具體有啥作用:
紅外激光投影儀:
投射一個紅外光點網格到場景中,然后這些光點被紅外攝像頭捕獲。因為投影儀和攝像頭的位置是固定的,所以通過計算光點在攝像頭中的位置偏移,可以推算出每個光點對應的物體距離攝像頭的距離,從而得到場景的深度信息。
紅外攝像頭:
紅外攝像頭是一種能夠捕獲紅外光譜的攝像頭。紅外光譜是電磁譜中的一部分,其波長長于可見光,但短于微波。紅外攝像頭的主要作用是能夠在無可見光照明的條件下進行成像,因為許多物體會發射、反射或透過紅外光。
彩色攝像頭:
通常用于捕獲場景的常規視覺信息,而其他的攝像頭則用于捕獲額外的信息,如場景的深度信息或在低光照條件下的圖像。這些信息可以與彩色攝像頭捕獲的圖像相結合,以提供更豐富的視覺數據,支持更高級的功能,如面部識別、增強現實或3D建模等。
結合這四個攝像頭的功能,能夠獲取一個物體的三維信息,這種技術可以用于人臉識別、手勢識別、物體識別、測量物體的深度等多種應用。

Artificial Intelligence Kit 3D

人工智能3D套裝是機械臂應用人工智能,機器視覺的入門款套裝。套裝使用了四種識別算法,顏色識別,形狀識別,yolov8等,適配可視化的操作界面,使用3D攝像頭解決了2D攝像頭需要標志定位的短板,開源代碼基于python平臺,可通過開發軟件實現機械臂的控制。
該套裝是搭配機械臂(myCobot,mechArm,myArm)進行使用,仿工業場景的構造。

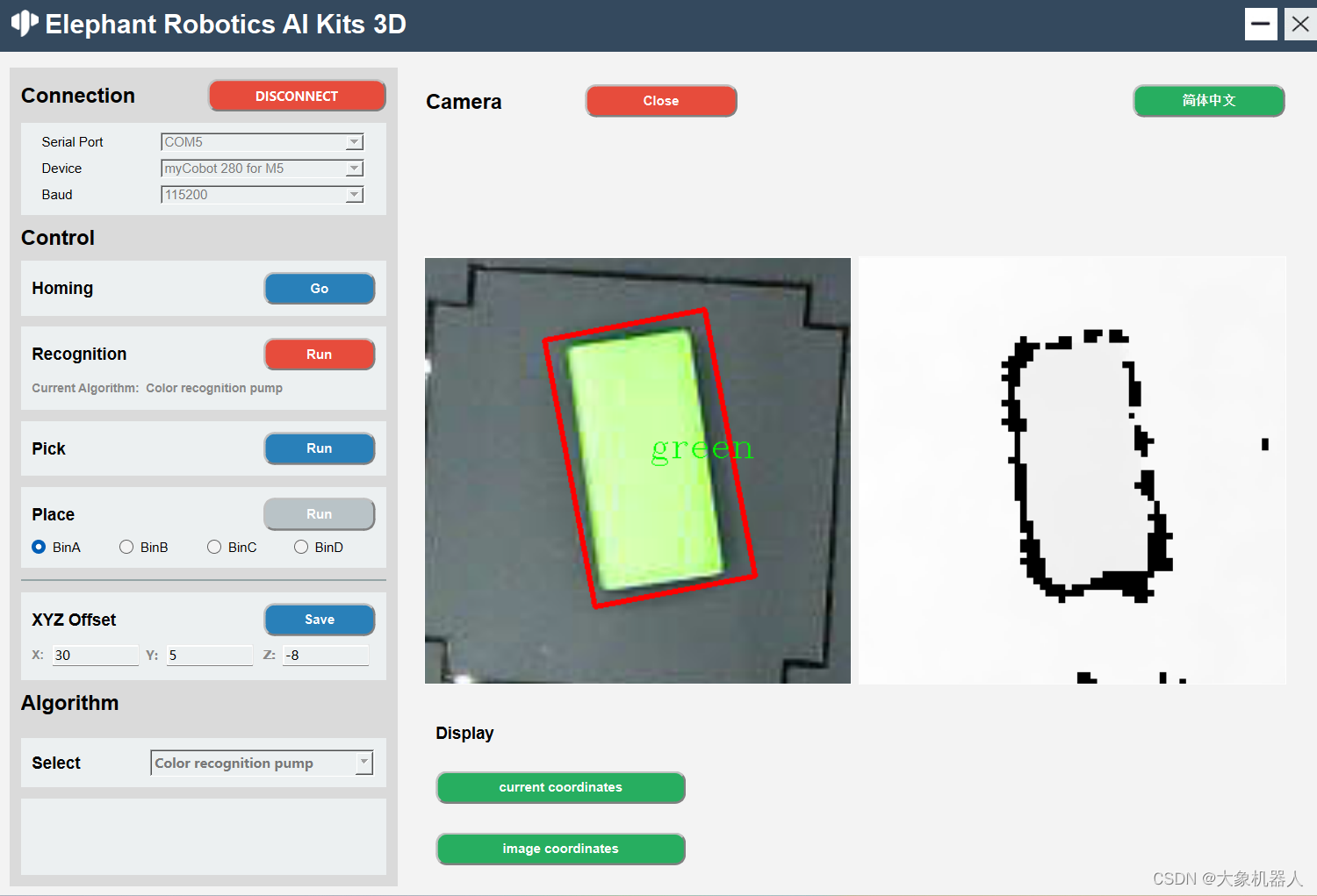
myCobot 280
myCobot 280 M5是一款由Elephant Robotics和M5Stack聯合開發的最小和最輕的六軸協作機器人。它采用集成模塊化設計,重量僅為850克,非常輕巧,搭載6個高性能伺服電機,具有快速響應,慣性小和平滑旋轉的特點。

3D攝像頭應用領域
如果在同一個應用領域中,用2D攝像頭和3D攝像頭它們的表型性能會怎樣。從我們身邊常見的來了解:
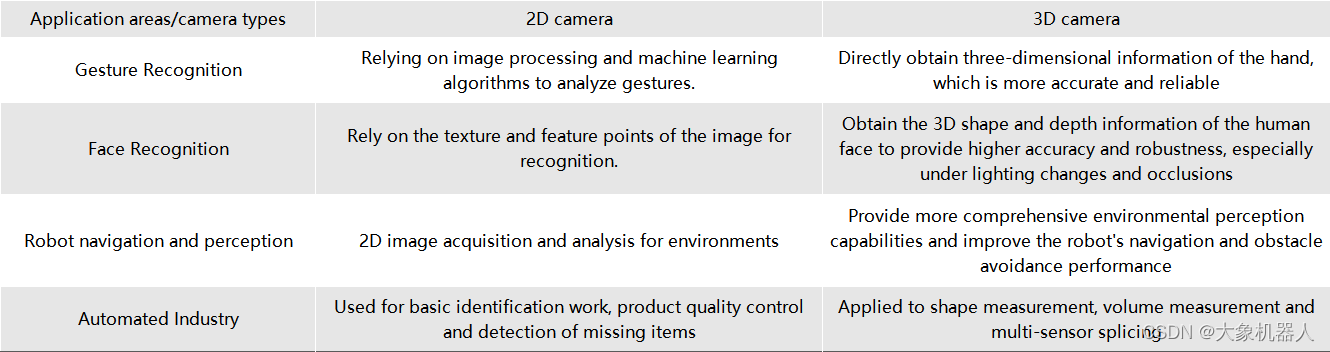
從圖標中可以知道,2D攝像頭需要通過特定的算法來得到一些參數,而3D攝像頭能夠直接獲取較多的信息,在同一應用領域下的性能更加精準。在未來的,3D攝像頭的趨勢必然是飛速增長的!
這也是我們推出3D人工智能套裝的原因之一,跟上時代的步伐。
算法介紹
機械臂視覺識別,一定會涉及手眼標定。雖然兩種版本的手眼標定的流程是一樣的,但是他們在計算中還是會有一些差別,我們先看它們的識別區。
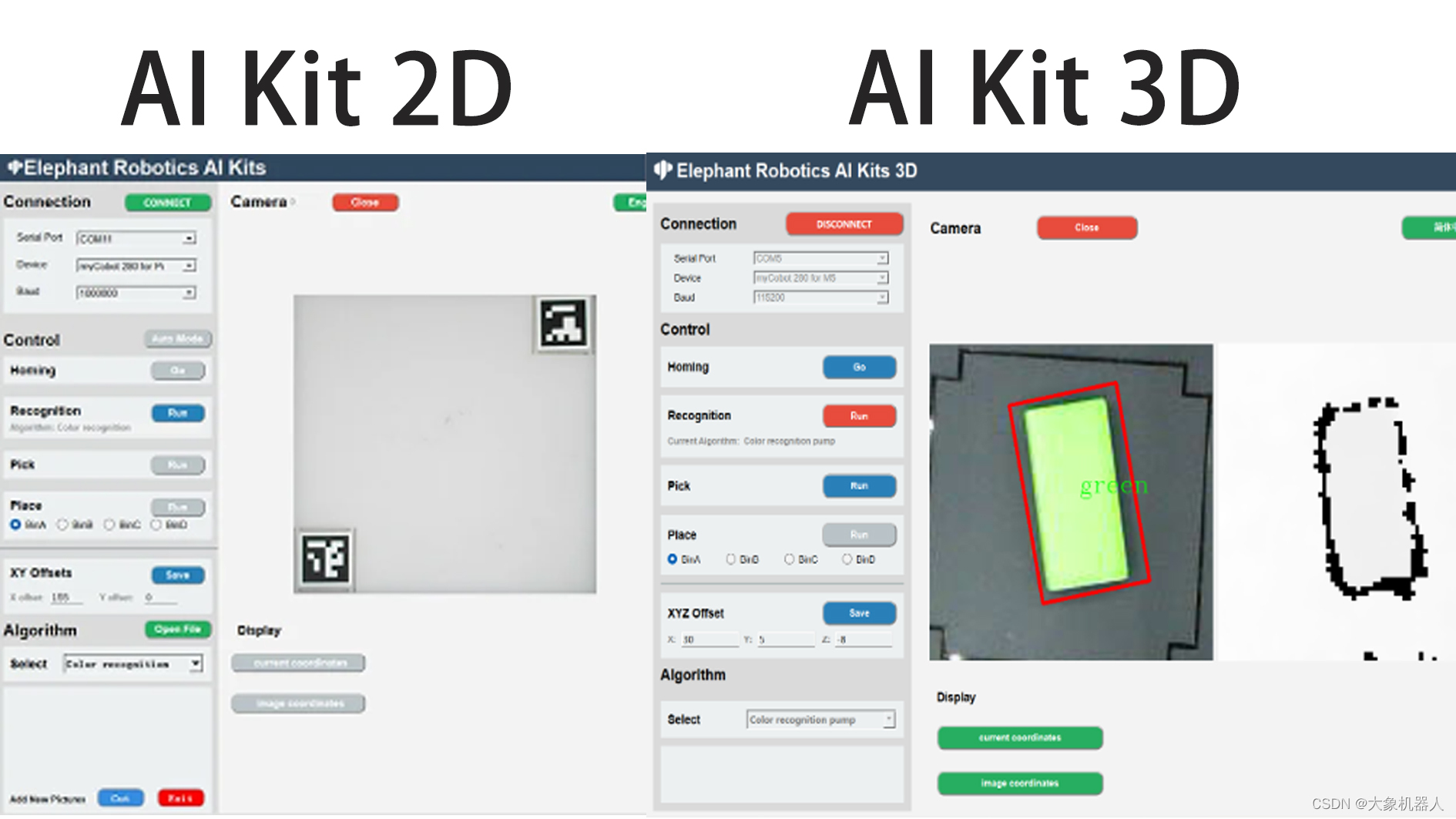
從中間的是被區域可以看到,3D版本已經沒有了二維碼的標識,在2D版本上二維碼的標識的主要功能是確定識別的區域,以及提供一個固定高度的值。在獲取了三維數據之后,就不需要用到二維碼進行標識了,可以直接獲取到相機距離平面高度的值。
這一點體現了3D攝像頭能夠直接獲取深度的信息。
如何使用 realsence 在python中 environment build operate system:window10/11 program language:python 3.9+ libraries: from typing import Tuple, Optional import pyrealsense2 as rs import numpy as np import cv2 import time class RealSenseCamera: def __init__(self): super().__init__() # Configure depth and color streams self.pipeline = rs.pipeline() self.config = rs.config() self.config.enable_stream(rs.stream.color, 1920, 1080, rs.format.bgr8, 30) # Is the camera mirror image reversed self.flip_h = False self.flip_v = False # Get device product line for setting a supporting resolution pipeline_wrapper = rs.pipeline_wrapper(self.pipeline) pipeline_profile = self.config.resolve(pipeline_wrapper) # set auto exposure color = pipeline_profile.get_device().query_sensors()[0] color.set_option(rs.option.enable_auto_exposure, True) device = pipeline_profile.get_device() sensor_infos = list( map(lambda x: x.get_info(rs.camera_info.name), device.sensors) ) # set resolution self.config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) self.config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) align_to = rs.stream.color self.align = rs.align(align_to) def capture(self): # Start streaming self.pipeline.start(self.config) # warm up for i in range(60): pipeline = self.pipeline frames = pipeline.wait_for_frames() def release(self): self.pipeline.stop() def update_frame(self) -> None: pipeline = self.pipeline frames = pipeline.wait_for_frames() aligned_frames = self.align.process(frames) self.curr_frame = aligned_frames self.curr_frame_time = time.time_ns() def color_frame(self) -> Optional[np.ndarray]: frame = self.curr_frame.get_color_frame() if not frame: return None frame = np.asanyarray(frame.get_data()) if self.flip_h: frame = cv2.flip(frame, 1) if self.flip_v: frame = cv2.flip(frame, 0) return frame def depth_frame(self) -> Optional[np.ndarray]: frame = self.curr_frame.get_depth_frame() if not frame: return None frame = np.asanyarray(frame.get_data()) if self.flip_h: frame = cv2.flip(frame, 1) if self.flip_v: frame = cv2.flip(frame, 0) return frame 顏色識別和形狀識別都是基于openCV提供的算法來識別物體抓取物體。只需要簡單的做一個hsv的檢測的算法就能夠檢測出來顏色。
# 初始化要識別的顏色
def __init__(self) -> None:
self.area_low_threshold = 15000
self.detected_name = None
self.hsv_range = {
"green": ((40, 50, 50), (90, 256, 256)),
# "blueA": ((91, 100, 100), (105, 256, 256)),
# "yellow": ((20, 240, 170), (30, 256, 256)),
"yellow": ((15, 46, 43), (30, 256, 256)),
"redA": ((0, 100, 100), (6, 256, 256)),
"redB": ((170, 100, 100), (179, 256, 256)),
# "orange": ((8, 100, 100), (15, 256, 256)),
"blue": ((100, 43, 46), (124, 256, 256)),
}
# 對圖像的處理
result = []
for color, (hsv_low, hsv_high) in self.hsv_range.items():
hsv_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
in_range = cv2.inRange(hsv_frame, hsv_low, hsv_high)
# 對顏色區域進行膨脹和腐蝕
kernel = np.ones((5, 5), np.uint8)
in_range = cv2.morphologyEx(in_range, cv2.MORPH_CLOSE, kernel)
in_range = cv2.morphologyEx(in_range, cv2.MORPH_OPEN, kernel)
contours, hierarchy = cv2.findContours(
in_range, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
)
contours = list(
filter(lambda x: cv2.contourArea(x) > self.area_low_threshold, contours)
)
rects = list(map(cv2.minAreaRect, contours))
boxes = list(map(cv2.boxPoints, rects))
boxes = list(map(np.int32, boxes))
if len(boxes) != 0:
if color.startswith("red"):
color = "red"
for box in boxes:
result.append(ColorDetector.DetectResult(color, box))
# self.detected_name = result
self.detected_name = result[0].color
return result
YOLOv8 和拆碼垛
我們在這個套裝里面還使用到了目前比較火的一款識別模型YOLOv8,此模型還涉及到深度學習和模型訓練等功能。
YOLOv8是一種目標檢測算法,它是基于深度學習的YOLO(You Only Look Once)系列算法的最新版本。YOLO算法是一種實時目標檢測算法,其特點是能夠在一次前向傳播中同時完成目標檢測和定位,速度非常快。Home - Ultralytics YOLOv8 Docs
主要特點:
高性能:YOLOv8在目標檢測任務中具有較高的準確性和速度。它能夠在實時或接近實時的速度下進行目標檢測,適用于各種應用場景。
簡單而有效的設計:YOLOv8采用了簡單而有效的設計,通過使用更深的網絡結構和更多的特征層來提高檢測性能。它還使用了一種自適應的訓練策略,可以在不同的目標檢測任務上進行快速訓練和調整。
多種規模的檢測:YOLOv8提供了不同的模型大小,包括小型、中型和大型模型,以滿足不同場景下的需求。這些模型可以在不同的硬件設備上進行部署和使用。
開源和易用性:YOLOv8是開源的,代碼和預訓練模型都可以在GitHub上獲得。它還提供了簡單易用的API,使得用戶可以方便地進行模型訓練、推理和部署。
要使用YOLOv8是需要進行自定義訓練模型的,在進行目標檢測任務是,根據具體應用場景和需求,通過在自定義數據集上進行訓練得到模型。
為什么要訓練模型呢?訓練模型的目的是讓計算機能夠自動識別和定位圖像或視頻中的目標物體。通過訓練模型,我們可以讓計算機學會如何識別不同種類的物體,并且能夠準確地定位它們的位置。這對于許多應用場景非常重要,比如自動駕駛、安防監控、智能交通等。
對此我們的源碼文件中已經包含了我們自己訓練的模型,如果你對YOLOv8的技術很熟練了,你可以自己對識別物體進行訓練。
下面的代碼是程序中使用的代碼
class YOLODetector:
DetectResult = List[ultralytics.engine.results.Results]
def __init__(self) -> None:
"""
init YOLO model。
"""
self.model_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) + '/resources/yolo/best.pt'
self.model = YOLO(self.model_path)
self.predict_args = {"conf": 0.2}
self.detected_name = None
def get_radian(self, res: DetectResult):
return 0
def detect(self, frame: np.ndarray):
"""
Perform object detection on input images.
Args:
frame (np.ndarray): Input image frame.
Returns:
List[DetectResult]: A list containing the detection results.
"""
res = self.model.predict(frame, **self.predict_args)
res = list(filter(lambda x: len(x.boxes) != 0, res))
if len(res) == 0:
return None
else:
names = self.get_names(res)
self.detected_name = names
return res
def draw_result(self, frame: np.ndarray, res: List[DetectResult]):
"""
Draws the bounding box of the detection results on the image.
Args:
frame (np.ndarray): Input image frame.
res (List[DetectResult]): List of detection results.
"""
res = list(filter(lambda x: len(x.boxes) != 0, res))
for r in res:
boxes = r.boxes.xyxy.numpy()
for box in boxes:
x1, y1, x2, y2 = box.astype(int)
cv2.rectangle(frame, (x1, y1), (x2, y2), color=(0, 255, 0), thickness=1)
cv2.putText(frame, "Name: " + str(self.detected_name), (20, 80),
cv2.FONT_HERSHEY_COMPLEX_SMALL, 1,
(0, 0, 255))
# x1, y1, x2, y2 = np.squeeze(r.boxes.xyxy.numpy()).astype(int)
# cv2.rectangle(frame, (x1, y1), (x2, y2), color=(0, 255, 0), thickness=1)
def target_position(self, res: DetectResult) -> Tuple[int, int]:
"""
Extract the location information of the target from the detection results.
Args:
res (DetectResult): detection result.
Returns:
Tuple[int, int]: The position coordinates (x, y) of the target.
"""
boxes = res.boxes.xywh.numpy()
boxs_list = []
for box in boxes:
x, y, w, h = box.astype(int)
boxs_list.append((x, y))
boxs_list = tuple(boxs_list)
return boxs_list
def get_rect(self, res: DetectResult):
"""
Obtain the bounding box coordinate information of the target from the detection result.
Args:
res (DetectResult): detection result.
Returns:
List[Tuple[int, int]]: The bounding box coordinate information of the target, including four vertex coordinates.
"""
boxes = res.boxes.xywh.numpy()
box_list = []
for box in boxes:
x, y, w, h = box.astype(int)
size = 3
rect = [
[x - size, y - size],
[x + size, y - size],
[x + size, y + size],
[x - size, y + size],
]
box_list.append(rect)
return box_list
def get_names(self, res: DetectResult):
"""
Get the category name in the detection results
Args:
res (DetectResult): detection result.
Returns:
List[names]: A list category names.
"""
names_dict = {
0: 'jeep', 1: 'apple', 2: 'banana1', 3: 'bed', 4: 'grape',
5: 'laptop', 6: 'microwave', 7: 'orange', 8: 'pear',
9: 'refrigerator1', 10: 'refrigerator2', 11: 'sofa', 12: 'sofa2',
13: 'tv', 14: 'washing machine1'
}
ids = [int(cls) for cls in res[0].boxes.cls.numpy()] # Assuming you have only one result in the list
names = [names_dict.get(id, 'Unknown') for id in ids]
return names

搭配上3D攝像頭的特性,獲取被識別的物體的高度實現拆碼垛的demo,能夠將他們像拆積木一樣拆除。

總結
我們的機械臂和深度攝像頭套裝不僅是一款產品,更是一個開啟學習之門的機會。這個套裝以用戶友好的方式,提供了一個理想的平臺,讓初學者可以在實踐中探索和學習機械臂操作和機器視覺的知識,更重要的是,它提供了一個獨特的機會,讓用戶能夠深入理解和掌握3D相機算法。
隨著科技的進步,3D攝像頭的應用正在迅速擴展到多個領域,包括但不限于制造、安全、娛樂和醫療。我們堅信,通過使用我們的套裝,用戶將能夠把握這一技術趨勢,為自己的未來學習和職業生涯奠定堅實的基礎。
審核編輯 黃宇
-
機器人
+關注
關注
211文章
28562瀏覽量
207700 -
人工智能
+關注
關注
1792文章
47513瀏覽量
239227 -
開源
+關注
關注
3文章
3381瀏覽量
42604 -
機械臂
+關注
關注
12文章
517瀏覽量
24646
發布評論請先 登錄
相關推薦
使用myCobot 280機械臂結合ROS2系統搭建機械分揀站
FPC與3D打印技術的結合 FPC在汽車電子中的應用前景



歡創播報 騰訊元寶首發3D生成應用

裸眼3D筆記本電腦——先進的光場裸眼3D技術

大象機器人開源協作機械臂機械臂接入GPT4o大模型!


包含具有多種類型信息的3D模型
友思特案例 | 雙目散斑3D視覺引導自動化上下料解決方案






 工商網監
工商網監
評論