") Linux是如何對容器下的進(jìn)程進(jìn)行CPU限制的,底層是如何工作的?
Linux是如何對容器下的進(jìn)程進(jìn)行CPU限制的,底層是如何工作的?
現(xiàn)在很多公司的服務(wù)都是跑在容器下,我來問幾個容器 CPU 相關(guān)的問題,看大家對天天在用的技術(shù)是否熟悉。
容器中的核是真的邏輯核嗎?
Linux 是如何對容器下的進(jìn)程進(jìn)行 CPU 限制的,底層是如何工作的?
容器中的 throttle 是什么意思?
為什么關(guān)注容器 CPU 性能的時候,除了關(guān)注使用率,還要關(guān)注 throttle 的次數(shù)和時間?
和真正使用物理機(jī)不同,Linux 容器中所謂的核并不是真正的 CPU 核。所以在理解容器 CPU 性能的時候,必然要有一些特殊的地方需要考慮。
各家公司的容器云上,底層不管使用的是 docker 引擎,還是 containerd 引擎,都是依賴 Linux 的 cgroup 的 cpu 子系統(tǒng)來工作的,所以今天我們就來深入地學(xué)習(xí)一下 cgroup cpu 子系統(tǒng) 。理解了這個,你將會對容器進(jìn)程的 CPU 性能有更深入的把握。
一、cgroup 的 cpu 子系統(tǒng)
在 Linux 下, cgroup 提供了對 CPU、內(nèi)存等資源實現(xiàn)精細(xì)化控制的能力。它的全稱是 control groups。允許對某一個進(jìn)程,或者一組進(jìn)程所用到的資源進(jìn)行控制。現(xiàn)在流行的 Docker 就是在這個底層機(jī)制上成長起來的。
在你的機(jī)器執(zhí)行執(zhí)行下面的命令可以查看當(dāng)前 cgroup 都支持對哪些資源進(jìn)行控制。
$lssubsys-a cpuset cpu,cpuacct ...
其中 cpu 和 cpuset 都是對 CPU 資源進(jìn)行控制的子系統(tǒng)。cpu 是通過執(zhí)行時間來控制進(jìn)程對 cpu 的使用,cpuset 是通過分配邏輯核的方式來分配 cpu。其它可控制的資源還包括 memory(內(nèi)存)、net_cls(網(wǎng)絡(luò)帶寬)等等。
cgroup 提供了一個原生接口并通過 cgroupfs 提供控制。類似于 procfs 和 sysfs,是一種虛擬文件系統(tǒng)。默認(rèn)情況下 cgroupfs 掛載在 /sys/fs/cgroup 目錄下,我們可以通過修改 /sys/fs/cgroup 下的文件和文件內(nèi)容來控制進(jìn)程對資源的使用。
比如,想實現(xiàn)讓某個進(jìn)程只使用兩個核,我們可以通過 cgroupfs 接口這樣來實現(xiàn),如下:
#cd/sys/fs/cgroup/cpu,cpuacct #mkdirtest #cdtest #echo100000>cpu.cfs_period_us//100ms #echo100000>cpu.cfs_quota_us//200ms #echo{$pid}>cgroup.procs
其中 cfs_period_us 用來配置時間周期長度,cfs_quota_us 用來配置當(dāng)前 cgroup 在設(shè)置的周期長度內(nèi)所能使用的 CPU 時間。這兩個文件配合起來就可以設(shè)置 CPU 的使用上限。
上面的配置就是設(shè)置改 cgroup 下的進(jìn)程每 100 ms 內(nèi)只能使用 200 ms 的 CPU 周期,也就是說限制使用最多兩個“核”。
要注意的是這種方式只限制的是 CPU 使用時間,具體調(diào)度的時候是可能會調(diào)度到任意 CPU 上執(zhí)行的。如果想限制進(jìn)程使用的 CPU 核,可以使用 cpuset 子系統(tǒng)。
docker 默認(rèn)情況下使用的就是 cgroupfs 接口,可以通過如下的命令來確認(rèn)。
#dockerinfo|grepcgroup CgroupDriver:cgroupfs
二、內(nèi)核中進(jìn)程和 cgroup 的關(guān)系
在上一節(jié)中,我們在 /sys/fs/cgroup/cpu,cpuacct 創(chuàng)建了一個目錄 test,這其實是創(chuàng)建了一個 cgroup 對象。當(dāng)我們把某個進(jìn)程的 pid 添加到 cgroup 后,又是建立了進(jìn)程結(jié)構(gòu)體和 cgroup 之間的關(guān)系。
所以要想理解清 cgroup 的工作過程,就得先來了解一下 cgroup 和 task_struct 結(jié)構(gòu)體之間的關(guān)系。
2.1 cgroup 內(nèi)核對象
一個 cgroup 對象中可以指定對 cpu、cpuset、memory 等一種或多種資源的限制。我們先來找到 cgroup 的定義。
//file:include/linux/cgroup-defs.h
structcgroup{
...
structcgroup_subsys_state__rcu*subsys[CGROUP_SUBSYS_COUNT];
...
}
每個 cgroup 都有一個 cgroup_subsys_state 類型的數(shù)組 subsys,其中的每一個元素代表的是一種資源控制,如 cpu、cpuset、memory 等等。
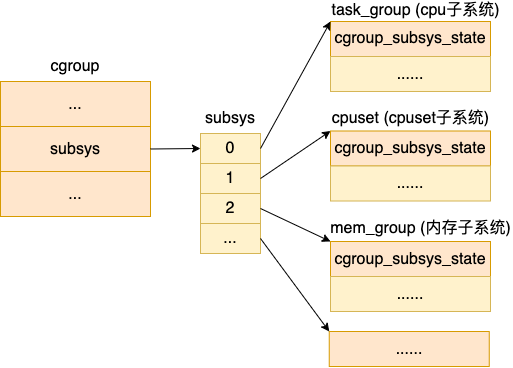
這里要注意的是,其實 cgroup_subsys_state 并不是真實的資源控制統(tǒng)計信息結(jié)構(gòu),對于 CPU 子系統(tǒng)真正的資源控制結(jié)構(gòu)是 task_group。它是 cgroup_subsys_state 結(jié)構(gòu)的擴(kuò)展,類似父類和子類的概念。
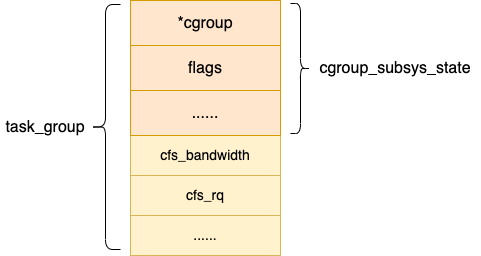
當(dāng) task_group 需要被當(dāng)成 cgroup_subsys_state 類型使用的時候,只需要強(qiáng)制類型轉(zhuǎn)換就可以。
對于內(nèi)存子系統(tǒng)控制統(tǒng)計信息結(jié)構(gòu)是 mem_cgroup,其它子系統(tǒng)也類似。
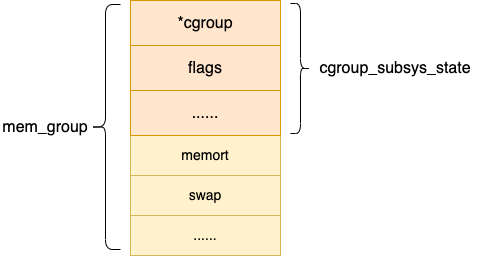
之所以要這么設(shè)計,目的是各個 cgroup 子系統(tǒng)都統(tǒng)一對外暴露 cgroup_subsys_state,其余部分不對外暴露,在自己的子系統(tǒng)內(nèi)部維護(hù)和使用。
2.2 進(jìn)程和 cgroup 子系統(tǒng)
一個 Linux 進(jìn)程既可以對它的 cpu 使用進(jìn)行限制,也可以對它的內(nèi)存進(jìn)行限制。所以,一個進(jìn)程 task_struct 是可以和多種子系統(tǒng)有關(guān)聯(lián)關(guān)系的。
和 cgroup 和多個子系統(tǒng)關(guān)聯(lián)定義類似,task_struct 中也定義了一個 cgroup_subsys_state 類型的數(shù)組 subsys,來表達(dá)這種一對多的關(guān)系。
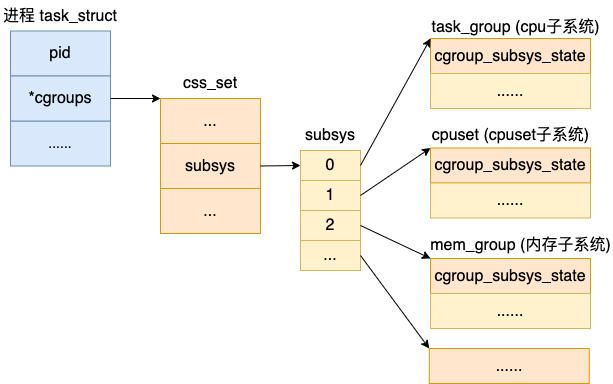
我們來簡單看下源碼的定義。
//file:include/linux/sched.h
structtask_struct{
...
structcss_set__rcu*cgroups;
...
}
//file:include/linux/cgroup-defs.h
structcss_set{
...
structcgroup_subsys_state*subsys[CGROUP_SUBSYS_COUNT];
}
其中subsys是一個指針數(shù)組,存儲一組指向 cgroup_subsys_state 的指針。一個 cgroup_subsys_state 就是進(jìn)程與一個特定的子系統(tǒng)相關(guān)的信息。
通過這個指針,進(jìn)程就可以獲得相關(guān)聯(lián)的 cgroups 控制信息了。能查到限制該進(jìn)程對資源使用的 task_group、cpuset、mem_group 等子系統(tǒng)對象。
2.3 內(nèi)核對象關(guān)系圖匯總
我們把上面的內(nèi)核對象關(guān)系圖匯總起來看一下。
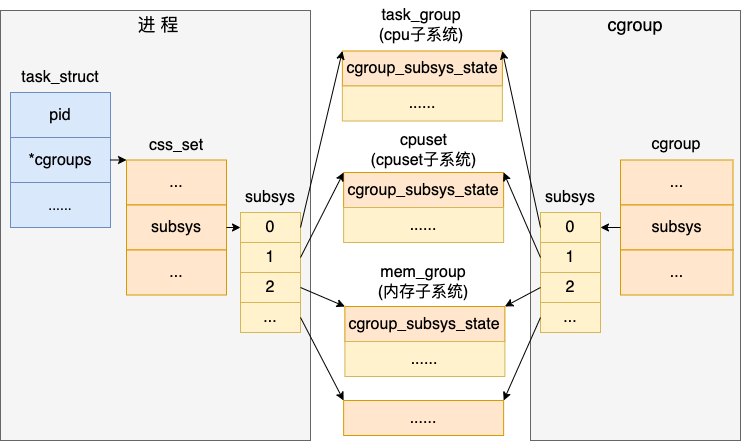
可以看到無論是進(jìn)程、還是 cgroup 對象,最后都能找到和其關(guān)聯(lián)的具體的 cpu、內(nèi)存等資源控制自系統(tǒng)的對象。
2.4 cpu 子系統(tǒng)
因為今天我們重點是介紹進(jìn)程的 cpu 限制,所以我們把 cpu 子系統(tǒng)相關(guān)的對象 task_group 專門拿出來理解理解。
//file:kernel/sched/sched.h
structtask_group{
structcgroup_subsys_statecss;
...
//task_group樹結(jié)構(gòu)
structtask_group*parent;
structlist_headsiblings;
structlist_headchildren;
//task_group持有的N個調(diào)度實體(N=CPU核數(shù))
structsched_entity**se;
//task_group自己的N個公平調(diào)度隊列(N=CPU核數(shù))
structcfs_rq**cfs_rq;
//公平調(diào)度帶寬限制
structcfs_bandwidthcfs_bandwidth;
...
}
第一個 cgroup_subsys_state css 成員我們在前面說過了,這相當(dāng)于它的“父類”。再來看 parent、siblings、children 等幾個對象。這些成員是樹相關(guān)的數(shù)據(jù)結(jié)構(gòu)。在整個系統(tǒng)中有一個 root_task_group。
//file:kernel/sched/core.c structtask_grouproot_task_group;
所有的 task_group 都是以 root_task_group 為根節(jié)點組成了一棵樹。
接下來的 se 和 cfs_rq 是完全公平調(diào)度的兩個對象。它們兩都是數(shù)組,元素個數(shù)等于當(dāng)前系統(tǒng)的 CPU 核數(shù)。每個 task_group 都會在上一級 task_group(比如 root_task_group)的 N 個調(diào)度隊列中有一個調(diào)度實體。
cfs_rq 是 task_group 自己所持有的完全公平調(diào)度隊列。是的,你沒看錯。每一個 task_group 內(nèi)部都有自己的一組調(diào)度隊列,其數(shù)量和 CPU 的核數(shù)一致。
假如當(dāng)前系統(tǒng)有兩個邏輯核,那么一個 task_group 樹和 cfs_rq 的簡單示意圖大概是下面這個樣子。
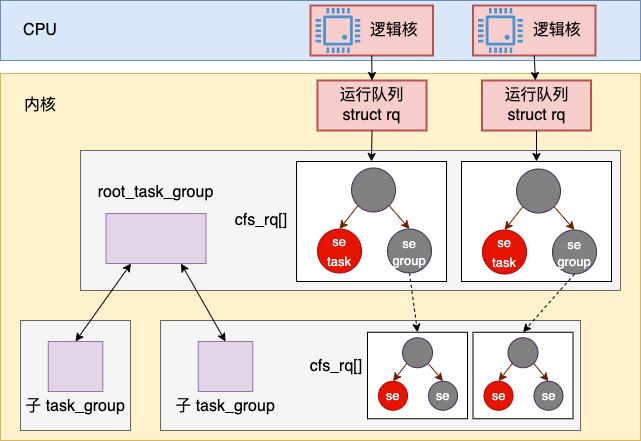
Linux 中的進(jìn)程調(diào)度是一個層級的結(jié)構(gòu)。對于容器來講,宿主機(jī)中進(jìn)行進(jìn)程調(diào)度的時候,先調(diào)度到的實際上不是容器中的具體某個進(jìn)程,而是一個 task_group。然后接下來再進(jìn)入容器 task_group 的調(diào)度隊列 cfs_rq 中進(jìn)行調(diào)度,才能最終確定具體的進(jìn)程 pid。
還有就是 cpu 帶寬限制 cfs_bandwidth, cpu 分配的管控相關(guān)的字段都是在 cfs_bandwidth 中定義維護(hù)的。
cgroup 相關(guān)的內(nèi)核對象我們就先介紹到這里,接下來我們看一下 cpu 子系統(tǒng)到底是如何實現(xiàn)的。
三、CPU 子系統(tǒng)的實現(xiàn)
在第一節(jié)中我們展示通過 cgroupfs 對 cpu 子系統(tǒng)使用,使用過程大概可以分成三步:
第一步:通過創(chuàng)建目錄來創(chuàng)建 cgroup
第二步:在目錄中設(shè)置 cpu 的限制情況
第三步:將進(jìn)程添加到 cgroup 中進(jìn)行資源管控
那本小節(jié)我們就從上面三步展開,看看在每一步中,內(nèi)核都具體做了哪些事情。限于篇幅所限,我們只講 cpu 子系統(tǒng),對于其他的子系統(tǒng)也是類似的分析過程。
3.1 創(chuàng)建 cgroup 對象
內(nèi)核定義了對 cgroupfs 操作的具體處理函數(shù)。在 /sys/fs/cgroup/ 下的目錄創(chuàng)建操作都將由下面 cgroup_kf_syscall_ops 定義的方法來執(zhí)行。
//file:kernel/cgroup/cgroup.c staticstructkernfs_syscall_opscgroup_kf_syscall_ops={ .mkdir=cgroup_mkdir, .rmdir=cgroup_rmdir, ... };
創(chuàng)建目錄執(zhí)行整個過程鏈條如下
vfs_mkdir ->kernfs_iop_mkdir ->cgroup_mkdir ->cgroup_apply_control_enable ->css_create ->cpu_cgroup_css_alloc
其中關(guān)鍵的創(chuàng)建過程有:
cgroup_mkdir:在這里創(chuàng)建了 cgroup 內(nèi)核對象
css_create:創(chuàng)建每一個子系統(tǒng)資源管理對象,對于 cpu 子系統(tǒng)會創(chuàng)建 task_group
cgroup 內(nèi)核對象是在 cgroup_mkdir 中創(chuàng)建的。除了 cgroup 內(nèi)核對象,這里還創(chuàng)建了文件系統(tǒng)重要展示的目錄。
//file:kernel/cgroup/cgroup.c
intcgroup_mkdir(structkernfs_node*parent_kn,constchar*name,umode_tmode)
{
...
//查找父cgroup
parent=cgroup_kn_lock_live(parent_kn,false);
//創(chuàng)建cgroup對象出來
cgrp=cgroup_create(parent);
//創(chuàng)建文件系統(tǒng)節(jié)點
kn=kernfs_create_dir(parent->kn,name,mode,cgrp);
cgrp->kn=kn;
...
}
在 cgroup 中,是有層次的概念的,這個層次結(jié)構(gòu)和 cgroupfs 中的目錄層次結(jié)構(gòu)一樣。所以在創(chuàng)建 cgroup 對象之前的第一步就是先找到其父 cgroup, 然后創(chuàng)建自己,并創(chuàng)建文件系統(tǒng)中的目錄以及文件。
在 cgroup_apply_control_enable 中,執(zhí)行子系統(tǒng)對象的創(chuàng)建。
//file:kernel/cgroup/cgroup.c
staticintcgroup_apply_control_enable(structcgroup*cgrp)
{
...
cgroup_for_each_live_descendant_pre(dsct,d_css,cgrp){
for_each_subsys(ss,ssid){
structcgroup_subsys_state*css=cgroup_css(dsct,ss);
css=css_create(dsct,ss);
...
}
}
return0;
}
通過 for_each_subsys 遍歷每一種 cgroup 子系統(tǒng),并調(diào)用其 css_alloc 來創(chuàng)建相應(yīng)的對象。
//file:kernel/cgroup/cgroup.c
staticstructcgroup_subsys_state*css_create(structcgroup*cgrp,
structcgroup_subsys*ss)
{
css=ss->css_alloc(parent_css);
...
}
上面的 css_alloc 是一個函數(shù)指針,對于 cpu 子系統(tǒng)來說,它指向的是 cpu_cgroup_css_alloc。這個對應(yīng)關(guān)系在 kernel/sched/core.c 文件仲可以找到
//file:kernel/sched/core.c
structcgroup_subsyscpu_cgrp_subsys={
.css_alloc=cpu_cgroup_css_alloc,
.css_online=cpu_cgroup_css_online,
...
};
通過 cpu_cgroup_css_alloc => sched_create_group 調(diào)用后,創(chuàng)建出了 cpu 子系統(tǒng)的內(nèi)核對象 task_group。
//file:kernel/sched/core.c
structtask_group*sched_create_group(structtask_group*parent)
{
structtask_group*tg;
tg=kmem_cache_alloc(task_group_cache,GFP_KERNEL|__GFP_ZERO);
...
}
3.2 設(shè)置 CPU 子系統(tǒng)限制
第一節(jié)中,我們通過對 cpu 子系統(tǒng)目錄下的 cfs_period_us 和 cfs_quota_us 值的修改,來完成了 cgroup 中限制的設(shè)置。我們這個小節(jié)再看看看這個設(shè)置過程。
當(dāng)用戶讀寫這兩個文件的時候,內(nèi)核中也定義了對應(yīng)的處理函數(shù)。
//file:kernel/sched/core.c
staticstructcftypecpu_legacy_files[]={
...
{
.name="cfs_quota_us",
.read_s64=cpu_cfs_quota_read_s64,
.write_s64=cpu_cfs_quota_write_s64,
},
{
.name="cfs_period_us",
.read_u64=cpu_cfs_period_read_u64,
.write_u64=cpu_cfs_period_write_u64,
},
...
}
寫處理函數(shù) cpu_cfs_quota_write_s64、cpu_cfs_period_write_u64 最終又都是調(diào)用 tg_set_cfs_bandwidth 來完成設(shè)置的。
//file:kernel/sched/core.c
staticinttg_set_cfs_bandwidth(structtask_group*tg,u64period,u64quota)
{
//定位cfs_bandwidth對象
structcfs_bandwidth*cfs_b=&tg->cfs_bandwidth;
...
//對cfs_bandwidth進(jìn)行設(shè)置
cfs_b->period=ns_to_ktime(period);
cfs_b->quota=quota;
...
}
在 task_group 中,其帶寬管理控制都是由 cfs_bandwidth 來完成的,所以一開始就需要先獲取 cfs_bandwidth 對象。接著將用戶設(shè)置的值都設(shè)置到 cfs_bandwidth 類型的對象 cfs_b 上。
3.3 寫 proc 進(jìn) group
cgroup 創(chuàng)建好了,cpu 限制規(guī)則也制定好了,下一步就是將進(jìn)程添加到這個限制中。在 cgroupfs 下的操作方式就是修改 cgroup.procs 文件。
內(nèi)核定義了修改 cgroup.procs 文件的處理函數(shù)為 cgroup_procs_write。
//file:kernel/cgroup/cgroup.c
staticstructcftypecgroup_base_files[]={
...
{
.name="cgroup.procs",
...
.write=cgroup_procs_write,
},
}
在 cgroup_procs_write 的處理中,主要做了這么幾件事情。
第一、邏根據(jù)用戶輸入的 pid 來查找 task_struct 內(nèi)核對象。
第二、從舊的調(diào)度組中退出,加入到新的調(diào)度組 task_group 中
第三、修改進(jìn)程其 cgroup 相關(guān)的指針,讓其指向上面創(chuàng)建好的 task_group。
我們來看下加入新調(diào)度組的過程,內(nèi)核的調(diào)用鏈條如下。
cgroup_procs_write ->cgroup_attach_task ->cgroup_migrate ->cgroup_migrate_execute
在 cgroup_migrate_execute 中遍歷各個子系統(tǒng),完成每一個子系統(tǒng)的遷移。
staticintcgroup_migrate_execute(structcgroup_mgctx*mgctx)
{
do_each_subsys_mask(ss,ssid,mgctx->ss_mask){
if(ss->attach){
tset->ssid=ssid;
ss->attach(tset);
}
}while_each_subsys_mask();
...
}
對于 cpu 子系統(tǒng)來講,attach 對應(yīng)的處理方法是 cpu_cgroup_attach。這也是在 kernel/sched/core.c 下的 cpu_cgrp_subsys 中定義的。
cpu_cgroup_attach 調(diào)用 sched_move_task 來完成將進(jìn)程加入到新調(diào)度組的過程。
//file:kernel/sched/core.c
voidsched_move_task(structtask_struct*tsk)
{
//找到task所在的runqueue
rq=task_rq_lock(tsk,&rf);
//從runqueue中出來
queued=task_on_rq_queued(tsk);
if(queued)
dequeue_task(rq,tsk,queue_flags);
//修改task的group
//將進(jìn)程先從舊tg的cfs_rq中移除且更新cfs_rq的負(fù)載;再將進(jìn)程添加入新tg的cfs_rq并更新新cfs_rq的負(fù)載
sched_change_group(tsk,TASK_MOVE_GROUP);
//此時進(jìn)程的調(diào)度組已經(jīng)更新,重新將進(jìn)程加回runqueue
if(queued)
enqueue_task(rq,tsk,queue_flags);
...
}
這個函數(shù)做了三件事。
第一、先調(diào)用 dequeue_task 從原歸屬的 queue 中退出來,
第二、修改進(jìn)程的 task_group
第三、重新將進(jìn)程添加到新 task_group 的 runqueue 中。
//file:kernel/sched/core.c
staticvoidsched_change_group(structtask_struct*tsk,inttype)
{
structtask_group*tg;
//查找task_group
tg=container_of(task_css_check(tsk,cpu_cgrp_id,true),
structtask_group,css);
tg=autogroup_task_group(tsk,tg);
//修改task_struct所對應(yīng)的task_group
tsk->sched_task_group=tg;
...
}
進(jìn)程 task_struct 的 sched_task_group 是表示其歸屬的 task_group, 這里設(shè)置到新歸屬上。
四、進(jìn)程 CPU 帶寬控制過程
在前面的操作完畢之后,我們只是將進(jìn)程添加到了 cgroup 中進(jìn)行管理而已。相當(dāng)于只是初始化,而真正的限制是貫穿在 Linux 運行是的進(jìn)程調(diào)度過程中的。
所添加的進(jìn)程將會受到 cpu 子系統(tǒng) task_group 下的 cfs_bandwidth 中記錄的 period 和 quota 的限制。
在你的新進(jìn)程是如何被內(nèi)核調(diào)度執(zhí)行到的?一文中我們介紹過完全公平調(diào)度器在選擇進(jìn)程時的核心方法 pick_next_task_fair。
這個方法的整個執(zhí)行過程一個自頂向下搜索可執(zhí)行的 task_struct 的過程。整個系統(tǒng)中有一個 root_task_group。
//file:kernel/sched/core.c structtask_grouproot_task_group;
CFS 中調(diào)度隊列是一顆紅黑樹, 紅黑樹的節(jié)點是 struct sched_entity, sched_entity 中既可以指向 struct task_struct 也可以指向 struct cfs_rq(可理解為 task_group)
調(diào)度 pick_next_task_fair()函數(shù)中的 prev 是本次調(diào)度時在執(zhí)行的上一個進(jìn)程。該函數(shù)通過 do {} while 循環(huán),自頂向下搜索到下一步可執(zhí)行進(jìn)程。
//file:kernel/sched/fair.c
staticstructtask_struct*
pick_next_task_fair(structrq*rq,structtask_struct*prev,structrq_flags*rf)
{
structcfs_rq*cfs_rq=&rq->cfs;
...
//選擇下一個調(diào)度的進(jìn)程
do{
...
se=pick_next_entity(cfs_rq,curr);
cfs_rq=group_cfs_rq(se);
}while(cfs_rq)
p=task_of(se);
//如果選出的進(jìn)程和上一個進(jìn)程不同
if(prev!=p){
structsched_entity*pse=&prev->se;
...
//對要放棄CPU的進(jìn)程執(zhí)行一些處理
put_prev_entity(cfs_rq,pse);
}
}
如果新進(jìn)程和上一次運行的進(jìn)程不是同一個,則要調(diào)用 put_prev_entity 做兩件和 CPU 的帶寬控制有關(guān)的事情。
//file:kernel/sched/fair.c
staticvoidput_prev_entity(structcfs_rq*cfs_rq,structsched_entity*prev)
{
//4.1運行隊列帶寬的更新與申請
if(prev->on_rq)
update_curr(cfs_rq);
//4.2判斷是否需要將容器掛起
check_cfs_rq_runtime(cfs_rq);
//更新負(fù)載數(shù)據(jù)
update_load_avg(cfs_rq,prev,0);
...
}
在上述代碼中,和 CPU 帶寬控制相關(guān)的操作有兩個。
運行隊列帶寬的更新與申請
判斷是否需要進(jìn)行帶寬限制
接下來我們分兩個小節(jié)詳細(xì)展開看看這兩個操作具體都做了哪些事情。
4.1 運行隊列帶寬的更新與申請
在這個小節(jié)中我們專門來看看 cfs_rq 隊列中 runtime_remaining 的更新與申請
在實現(xiàn)上帶寬控制是在 task_group 下屬的 cfs_rq 隊列中進(jìn)行的。cfs_rq 對帶寬時間的操作歸總起來就是更新與申請。申請到的時間保存在字段 runtime_remaining 字段中,每當(dāng)有時間支出需要更新的時候也是從這個字段值從去除。
其實除了上述場景外,系統(tǒng)在很多情況下都會調(diào)用 update_curr,包括任務(wù)在入隊、出隊時,調(diào)度中斷函數(shù)也會周期性地調(diào)用該方法,以確保任務(wù)的各種時間信息隨時都是最新的狀態(tài)。在這里會更新 cfs_rq 隊列中的 runtime_remaining 時間。如果 runtime_remaining 不足,會觸發(fā)時間申請。
//file:kernel/sched/fair.c
staticvoidupdate_curr(structcfs_rq*cfs_rq)
{
//計算一下運行了多久
u64now=rq_clock_task(rq_of(cfs_rq));
u64delta_exec;
delta_exec=now-curr->exec_start;
...
//更新帶寬限制
account_cfs_rq_runtime(cfs_rq,delta_exec);
}
在 update_curr 先計算當(dāng)前執(zhí)行了多少時間。然后在 cfs_rq 的 runtime_remaining 減去該時間值,具體減的過程是在 account_cfs_rq_runtime 中處理的。
//file:kernel/sched/fair.c
staticvoid__account_cfs_rq_runtime(structcfs_rq*cfs_rq,u64delta_exec)
{
cfs_rq->runtime_remaining-=delta_exec;
//如果還有剩余時間,則函數(shù)返回
if(likely(cfs_rq->runtime_remaining>0))
return;
...
//調(diào)用assign_cfs_rq_runtime申請時間余額
if(!assign_cfs_rq_runtime(cfs_rq)&&likely(cfs_rq->curr))
resched_curr(rq_of(cfs_rq));
}
更新帶寬時間的邏輯比較簡單,先從 cfs->runtime_remaining 減去本次執(zhí)行的物理時間。如果減去之后仍然大于 0 ,那么本次更新就算是結(jié)束了。
如果相減后發(fā)現(xiàn)是負(fù)數(shù),表示當(dāng)前 cfs_rq 的時間余額已經(jīng)耗盡,則會立即嘗試從任務(wù)組中申請。具體的申請函數(shù)是 assign_cfs_rq_runtime。如果申請沒能成功,調(diào)用 resched_curr 標(biāo)記 cfs_rq->curr 的 TIF_NEED_RESCHED 位,以便隨后將其調(diào)度出去。
我們展開看下申請過程 assign_cfs_rq_runtime 。
//file:kernel/sched/fair.c
staticintassign_cfs_rq_runtime(structcfs_rq*cfs_rq)
{
//獲取當(dāng)前task_group的cfs_bandwidth
structtask_group*tg=cfs_rq->tg;
structcfs_bandwidth*cfs_b=tg_cfs_bandwidth(tg);
//申請時間數(shù)量為保持下次有sysctl_sched_cfs_bandwidth_slice這么多
min_amount=sched_cfs_bandwidth_slice()-cfs_rq->runtime_remaining;
//如果沒有限制,則要多少給多少
if(cfs_b->quota==RUNTIME_INF)
amount=min_amount;
else{
//保證定時器是打開的,保證周期性地為任務(wù)組重置帶寬時間
start_cfs_bandwidth(cfs_b);
//如果本周期內(nèi)還有時間,則可以分配
if(cfs_b->runtime>0){
//確保不要透支
amount=min(cfs_b->runtime,min_amount);
cfs_b->runtime-=amount;
cfs_b->idle=0;
}
}
cfs_rq->runtime_remaining+=amount;
returncfs_rq->runtime_remaining>0;
}
首先,獲取當(dāng)前 task_group 的 cfs_bandwidth,因為整個任務(wù)組的帶寬數(shù)據(jù)都是封裝在這里的。接著調(diào)用 sched_cfs_bandwidth_slice 來獲取后面要留有多長時間,這個函數(shù)訪問的 sysctl 下的 sched_cfs_bandwidth_slice 參數(shù)。
//file:kernel/sched/fair.c
staticinlineu64sched_cfs_bandwidth_slice(void)
{
return(u64)sysctl_sched_cfs_bandwidth_slice*NSEC_PER_USEC;
}
這個參數(shù)在我的機(jī)器上是 5000 us(也就是說每次申請 5 ms)。
$sysctl-a|grepsched_cfs_bandwidth_slice kernel.sched_cfs_bandwidth_slice_us=5000
在計算要申請的時間的時候,還需要考慮現(xiàn)在有多少時間。如果 cfs_rq->runtime_remaining 為正的話,那可以少申請一點,如果已經(jīng)變?yōu)樨?fù)數(shù)的話,需要在 sched_cfs_bandwidth_slice 基礎(chǔ)之上再多申請一些。
所以,最終要申請的時間值 min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining
計算出 min_amount 后,直接在向自己所屬的 task_group 下的 cfs_bandwidth 把時間申請出來。整個 task_group 下可用的時間是保存在 cfs_b->runtime 中的。
這里你可能會問了,那 task_group 下的 cfs_b->runtime 的時間又是哪兒給分配的呢?我們將在 5.1 節(jié)來討論這個過程。
4.2 帶寬限制
check_cfs_rq_runtime 這個函數(shù)檢測 task group 的帶寬是否已經(jīng)耗盡, 如果是則調(diào)用 throttle_cfs_rq 對進(jìn)程進(jìn)行限流。
//file:kernel/sched/fair.c
staticboolcheck_cfs_rq_runtime(structcfs_rq*cfs_rq)
{
//判斷是不是時間余額已用盡
if(likely(!cfs_rq->runtime_enabled||cfs_rq->runtime_remaining>0))
returnfalse;
...
throttle_cfs_rq(cfs_rq);
returntrue;
}
我們再來看看 throttle_cfs_rq 的執(zhí)行過程。
//file:kernel/sched/fair.c staticvoidthrottle_cfs_rq(structcfs_rq*cfs_rq) { //1.查找到所屬的task_group下的se se=cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))]; ... //2.遍歷每一個可調(diào)度實體,并從隸屬的 cfs_rq 上面刪除。 for_each_sched_entity(se){ structcfs_rq*qcfs_rq=cfs_rq_of(se); if(dequeue) dequeue_entity(qcfs_rq,se,DEQUEUE_SLEEP); ... } //3.設(shè)置一些 throttled 信息。 cfs_rq->throttled=1; cfs_rq->throttled_clock=rq_clock(rq); //4.確保unthrottle的高精度定時器處于被激活的狀態(tài) start_cfs_bandwidth(cfs_b); ... }
在 throttle_cfs_rq 中,找到其所屬的 task_group 下的調(diào)度實體 se 數(shù)組,遍歷每一個元素,并從其隸屬的 cfs_rq 的紅黑樹上刪除。這樣下次再調(diào)度的時候,就不會再調(diào)度到這些進(jìn)程了。
那么 start_cfs_bandwidth 是干啥的呢?這正好是下一節(jié)的引子。
五、進(jìn)程的可運行時間的分配
在第四小節(jié)我們看到,task_group 下的進(jìn)程的運行時間都是從它的 cfs_b->runtime 中申請的。這個時間是在定時器中分配的。負(fù)責(zé)給 task_group 分配運行時間的定時器包括兩個,一個是 period_timer,另一個是 slack_timer。
structcfs_bandwidth{
ktime_tperiod;
u64 quota;
...
structhrtimerperiod_timer;
structhrtimerslack_timer;
...
}
peroid_timer 是周期性給 task_group 添加時間,缺點是 timer 周期比較長,通常是100ms。而 slack_timer 用于有 cfs_rq 處于 throttle 狀態(tài)且全局時間池有時間供分配但是 period_timer 有還有比較長時間(通常大于7ms)才超時的場景。這個時候我們就可以激活比較短的slack_timer(5ms超時)進(jìn)行throttle,這樣的設(shè)計可以提升系統(tǒng)的實時性。
這兩個 timer 在 cgroup 下的 cfs_bandwidth 初始化的時候,都設(shè)置好了到期回調(diào)函數(shù),分別是 sched_cfs_period_timer 和 sched_cfs_slack_timer。
//file:kernel/sched/fair.c
voidinit_cfs_bandwidth(structcfs_bandwidth*cfs_b)
{
cfs_b->runtime=0;
cfs_b->quota=RUNTIME_INF;
cfs_b->period=ns_to_ktime(default_cfs_period());
//初始化period_timer并設(shè)置回調(diào)函數(shù)
hrtimer_init(&cfs_b->period_timer,CLOCK_MONOTONIC,HRTIMER_MODE_ABS_PINNED);
cfs_b->period_timer.function=sched_cfs_period_timer;
//初始化slack_timer并設(shè)置回調(diào)函數(shù)
hrtimer_init(&cfs_b->slack_timer,CLOCK_MONOTONIC,HRTIMER_MODE_REL);
cfs_b->slack_timer.function=sched_cfs_slack_timer;
...
}
在上一節(jié)最后提到的 start_cfs_bandwidth 就是在打開 period_timer 定時器。
//file:kernel/sched/fair.c
voidstart_cfs_bandwidth(structcfs_bandwidth*cfs_b)
{
...
hrtimer_forward_now(&cfs_b->period_timer,cfs_b->period);
hrtimer_start_expires(&cfs_b->period_timer,HRTIMER_MODE_ABS_PINNED);
}
在 hrtimer_forward_now 調(diào)用時傳入的第二個參數(shù)表示是觸發(fā)的延遲時間。這個就是在 cgroup 是設(shè)置的 period,一般為 100 ms。
我們來分別看看這兩個 timer 是如何給 task_group 定期發(fā)工資(分配時間)的。
5.1 period_timer
在 period_timer 的回調(diào)函數(shù) sched_cfs_period_timer 中,周期性地為任務(wù)組分配帶寬時間,并且解掛當(dāng)前任務(wù)組中所有掛起的隊列。
分配帶寬時間是在 __refill_cfs_bandwidth_runtime 中執(zhí)行的,它的調(diào)用堆棧如下。
sched_cfs_period_timer ->do_sched_cfs_period_timer ->__refill_cfs_bandwidth_runtime
//file:kernel/sched/fair.c
void__refill_cfs_bandwidth_runtime(structcfs_bandwidth*cfs_b)
{
if(cfs_b->quota!=RUNTIME_INF)
cfs_b->runtime=cfs_b->quota;
}
可見,這里直接給 cfs_b->runtime 增加了 cfs_b->quota 這么多的時間。其中 cfs_b->quota 你就可以認(rèn)為是在 cgroupfs 目錄下,我們配置的那個值。在第一節(jié)中,我們配置的是 500 ms。
#echo500000>cpu.cfs_period_us//500ms
5.2 slack_timer
設(shè)想一下,假如說某個進(jìn)程申請了 5 ms 的執(zhí)行時間,但是當(dāng)進(jìn)程剛一啟動執(zhí)行便執(zhí)行了同步阻塞的邏輯,這時候所申請的時間根本都沒有用完。在這種情況下,申請但沒用完的時間大部分是要返還給 task_group 中的全局時間池的。
在內(nèi)核中的調(diào)用鏈如下
dequeue_task_fair –>dequeue_entity –>return_cfs_rq_runtime –>__return_cfs_rq_runtime
具體的返還是在 __return_cfs_rq_runtime 中處理的。
//file:kernel/sched/fair.c
staticvoid__return_cfs_rq_runtime(structcfs_rq*cfs_rq)
{
//給自己留一點
s64slack_runtime=cfs_rq->runtime_remaining-min_cfs_rq_runtime;
if(slack_runtime<=?0)
??return;
?//返還到全局時間池中
?if?(cfs_b->quota!=RUNTIME_INF){
cfs_b->runtime+=slack_runtime;
//如果時間又足夠多了,并且還有進(jìn)程被限制的話
//則調(diào)用start_cfs_slack_bandwidth來開啟slack_timer
if(cfs_b->runtime>sched_cfs_bandwidth_slice()&&
!list_empty(&cfs_b->throttled_cfs_rq))
start_cfs_slack_bandwidth(cfs_b);
}
...
}
這個函數(shù)做了這么幾件事情。
min_cfs_rq_runtime 的值是 1 ms,我們選擇至少保留 1ms 時間給自己
剩下的時間 slack_runtime 歸還給當(dāng)前的 cfs_b->runtime
如果時間又足夠多了,并且還有進(jìn)程被限制的話,開啟slack_timer,嘗試接觸進(jìn)程 CPU 限制
在 start_cfs_slack_bandwidth 中啟動了 slack_timer。
//file:kernel/sched/fair.c
staticvoidstart_cfs_slack_bandwidth(structcfs_bandwidth*cfs_b)
{
...
//啟動slack_timer
cfs_b->slack_started=true;
hrtimer_start(&cfs_b->slack_timer,
ns_to_ktime(cfs_bandwidth_slack_period),
HRTIMER_MODE_REL);
...
}
可見 slack_timer 的延遲回調(diào)時間是 cfs_bandwidth_slack_period,它的值是 5 ms。這就比 period_timer 要實時多了。
slack_timer 的回調(diào)函數(shù) sched_cfs_slack_timer 我們就不展開看了,它主要就是操作對進(jìn)程解除 CPU 限制
六、總結(jié)
今天我們介紹了 Linux cgroup 的 cpu 子系統(tǒng)給容器中的進(jìn)程分配 cpu 時間的原理。
和真正使用物理機(jī)不同,Linux 容器中所謂的核并不是真正的 CPU 核,而是轉(zhuǎn)化成了執(zhí)行時間的概念。在容器進(jìn)程調(diào)度的時候給其滿足一定的 CPU 執(zhí)行時間,而不是真正的分配邏輯核。
cgroup 提供了的原生接口是通過 cgroupfs 提供控制各個子系統(tǒng)的設(shè)置的。默認(rèn)是在 /sys/fs/cgroup/ 目錄下,內(nèi)核這個文件系統(tǒng)的處理是定義了特殊的處理,和普通的文件完全不一樣的。
內(nèi)核處理 cpu 帶寬控制的核心對象就是下面這個 cfs_bandwidth。
//file:kernel/sched/sched.h
structcfs_bandwidth{
//帶寬控制配置
ktime_tperiod;
u64quota;
//當(dāng)前task_group的全局可執(zhí)行時間
u64runtime;
...
//定時分配
structhrtimerperiod_timer;
structhrtimerslack_timer;
}
用戶在創(chuàng)建 cgroup cpu 子系統(tǒng)控制過程主要分成三步:
第一步:通過創(chuàng)建目錄來創(chuàng)建 cgroup 對象。在 /sys/fs/cgroup/cpu,cpuacct 創(chuàng)建一個目錄 test,實際上內(nèi)核是創(chuàng)建了 cgroup、task_group 等內(nèi)核對象。
第二步:在目錄中設(shè)置 cpu 的限制情況。在 task_group 下有個核心的 cfs_bandwidth 對象,用戶所設(shè)置的 cfs_quota_us 和 cfs_period_us 的值最后都存到它下面了。
第三步:將進(jìn)程添加到 cgroup 中進(jìn)行資源管控。當(dāng)在 cgroup 的 cgroup.proc 下添加進(jìn)程 pid 時,實際上是將該進(jìn)程加入到了這個新的 task_group 調(diào)度組了。將使用 task_group 的 runqueue,以及它的時間配額
當(dāng)創(chuàng)建完成后,內(nèi)核的 period_timer 會根據(jù) task_group->cfs_bandwidth 下用戶設(shè)置的 period 定時給可執(zhí)行時間 runtime 上加上 quota 這么多的時間(相當(dāng)于按月發(fā)工資),以供 task_group 下的進(jìn)程執(zhí)行(消費)的時候使用。
structcfs_rq{
...
intruntime_enabled;
s64runtime_remaining;
}
在完全公平器調(diào)度的時候,每次 pick_next_task_fair 時會做兩件事情
第一件:將從 cpu 上拿下來的進(jìn)程所在的運行隊列進(jìn)行執(zhí)行時間的更新與申請。會將 cfs_rq 的 runtime_remaining 減去已經(jīng)執(zhí)行了的時間。如果減為了負(fù)數(shù),則從 cfs_rq 所在的 task_group 下的 cfs_bandwidth 去申請一些。
第二件:判斷 cfs_rq 上是否申請到了可執(zhí)行時間,如果沒有申請到,需要將這個隊列上的所有進(jìn)程都從完全公平調(diào)度器的紅黑樹上取下。這樣再次調(diào)度的時候,這些進(jìn)程就不會被調(diào)度了。
當(dāng) period_timer 再次給 task_group 分配時間的時候,或者是自己有申請時間沒用完回收后觸發(fā) slack_timer 的時候,被限制調(diào)度的進(jìn)程會被解除調(diào)度限制,重新正常參與運行。
這里要注意的是,一般 period_timer 分配時間的周期都是 100 ms 左右。假如說你的進(jìn)程前 50 ms 就把 cpu 給用光了,那你收到的請求可能在后面的 50 ms 都沒有辦法處理,對請求處理耗時會有影響。這也是為啥在關(guān)注 CPU 性能的時候要關(guān)注對容器 throttle 次數(shù)和時間的原因了。
審核編輯:劉清
-
Linux
+關(guān)注
關(guān)注
87文章
11312瀏覽量
209738 -
調(diào)度器
+關(guān)注
關(guān)注
0文章
98瀏覽量
5261
原文標(biāo)題:內(nèi)核是如何給容器中的進(jìn)程分配CPU資源的?
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Linux開發(fā)_Linux下進(jìn)程編程

Linux系統(tǒng)下進(jìn)程的幾種狀態(tài)介紹
Linux進(jìn)程的睡眠和喚醒
Linux下的進(jìn)程結(jié)構(gòu)
Linux下進(jìn)程間通信
Linux下的進(jìn)程結(jié)構(gòu)
linux操作系統(tǒng)下的進(jìn)程通信設(shè)計
linux操作系統(tǒng)下的進(jìn)程通信
Linux CPU的性能應(yīng)該如何優(yōu)化
基于linux eBPF的進(jìn)程off-cpu的方法
Linux技術(shù)中Cgroup的原理和實踐
如何將進(jìn)程與 CPU 進(jìn)行綁定
如何限制容器可以使用的CPU資源






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論