 TVM編譯器的整體架構和基本方法
TVM編譯器的整體架構和基本方法
引言
有將近兩個月沒有學習一些新東西,更新一下博客了。一直在忙公司的一個項目,是做一款支持LSTM和RNN的通用架構加速IP。自己恰好負責指令編譯工作,雖然開始的指令比較粗糙,沒有一套完整的編譯器架構。但是這其中也去思考了一下基于FPGA加速器的編譯器架構。在FPGA深度學習加速器中,編譯器除了需要自動化生成指令外,還要優化指令的結構,來最大化加速器性能。TVM是一個支持GPU、CPU、FPGA指令生成的開源編譯器框架,雖然在我們自己的加速IP上無法直接拿過來用,但是其中的很多方法和思想還是很值得借鑒的。TVM最大的特點是基于圖和算符結構來優化指令生成,最大化硬件執行效率。其中使用了很多方法來改善硬件執行速度,包括算符融合、數據規劃、基于機器學習的優化器等。它向上對接Tensorflow、Pytorch等深度學習框架,向下兼容GPU、CPU、ARM、TPU等硬件設備。
1. 整體結構
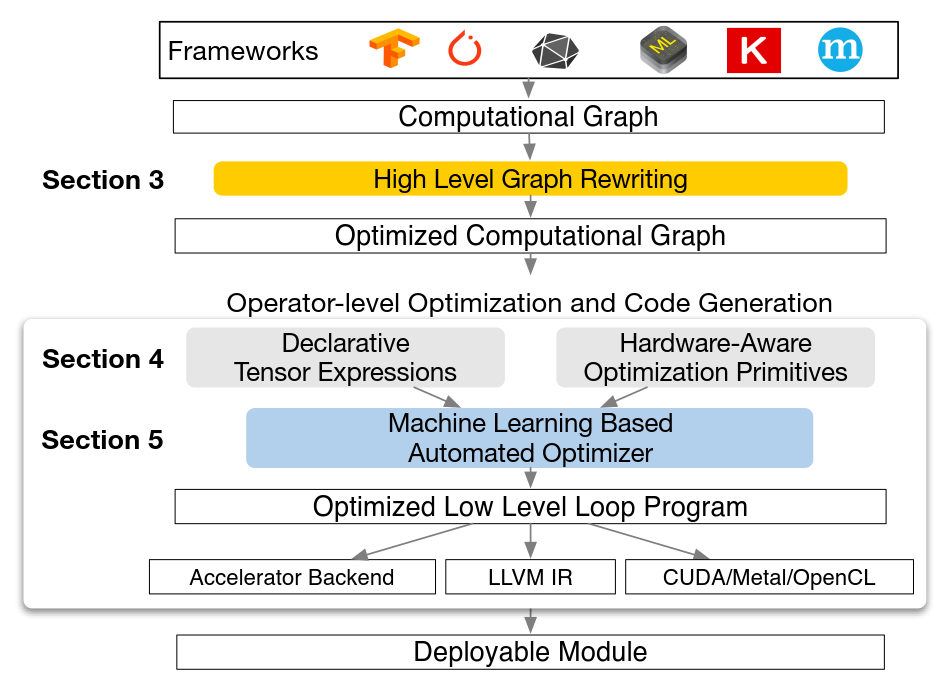
TVM是一個端到端的指令生成器。它從深度學習框架中接收模型輸入,然后進行圖的轉化和基本的優化,最后生成指令完成到硬件的部署。整個架構是基于圖描述結構,不論是對指令的優化還是指令生成,一個圖結構清晰的描述了數據流方向,操作之間的依賴關系等。基于機器學習的優化器是優化過程中的重點,指令空間很大,通過優化函數來尋找最優值是一個很合理的想法。它的主要特點如下:
1) 基于GPU、TPU等硬件結構,將張量運算作為一個基本的算符,通過把一個深度學習網絡描述成圖結構來抽象出數據計算流程。在這樣的圖結構基礎上,更方便記性優化。同時能夠有更好的向上向下兼容性,同時支持多種深度學習框架和硬件架構。
2) 巨大的優化搜索空間。在優化圖結構方面,其不再局限于通過某一種方式,而是通過機器學習方法來搜索可能的空間來最大化部署效率。這種方式雖然會導致編譯器較大的計算量,但是更加通用。
TVM提供了一個非常簡單的端到端用戶接口,通過調用TVM的API可以很方便的進行硬件部署。比如:

以上就是將Keras的模型輸入到TVM,指定部署的硬件GPU,然后進行優化和代碼生成。
TVM也提供了Java、C++和Python界面供用戶調用。
2. 圖結構基本優化
圖結構是大多數深度學習框架中普遍采用的描述方式。這種圖是一種高層次的描述,將一個張量運算用一個算符描述,而不是拆分的更細。這樣更有利于優化,而且也符合GPU、TPU的硬件架構,在這些芯片中計算核算力很大,通常可以完成一個較大的計算,比如卷積、矩陣運算等。以下是一個卷積計算的例子,整個計算圖包含了2D卷積、ReLu,dense、softmas等。這樣的圖結構也正好符合FPGA加速器的結構,在FPGA中也是用一個計算核來專門計算某個大的計算。TVM圖中節點描述一個張量數據或者算符,而邊表示了不同計算的依賴關系。
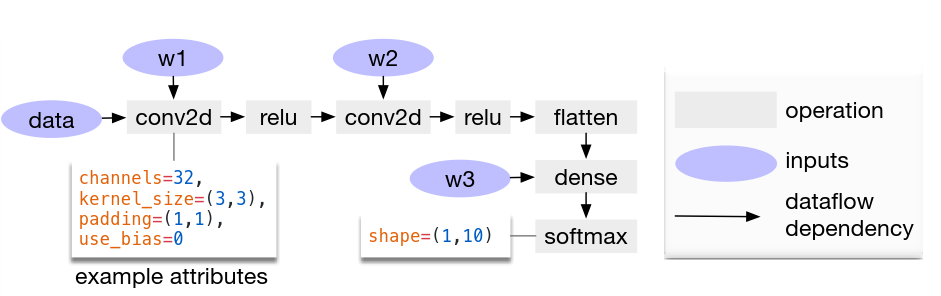
基于圖結構,TVM采用了很多圖優化策略。包括算符融合,將可以在硬件上用一個算符完成的多個連續運算合并;常量折疊,將可以預先計算的數據放在編譯器中完成,減少硬件計算;存儲規劃,預先為中間數據分配存儲空間來儲存中間值,避免中間數據無法存儲在片上而增加片外存儲開銷;數據規劃,重新排列數據有利于硬件計算。
1) 算符融合
TVM中將運算劃分為4種:1對1運算,比如加法、點乘;降運算,比如累加;復雜運算,比如2D卷積,融合了乘法和累加;不透明的,比如分類、數據排列等,這些不能被融合。算符融合可以減少存儲開銷,實現pipeline,特別是在FPGA中更有利。比如我們目前的項目中是開發一款通用RNN架構IP,其中涉及到矩陣乘法,加法。其中加法就可以融合到矩陣乘中,這樣就減少了單獨加法模塊計算開銷以及讀寫cache開銷。
2) 數據規劃
以我們XRNN來說,片上有一個矩陣運算陣列,由于陣列大小固定,一次計算矩陣大小也是固定的。比如計算一個32x32對應32x1的矩陣向量乘法,那么就要求權重和向量必須要按照32倍數進行對齊,這就需要對權重數據等進行規劃。
3. 張量計算
TVM中使用的張量描述語言是透明的,可以根據硬件需要進行修改。這樣更加靈活和有利于進行優化。但是這樣可能增加了編譯器優化的復雜性。TVM描述例子如下:

描述算符中包含結果大小,計算方式。但是這其中沒有涉及到循環結構和更多數據操作細節。TVM采用了Halide思想,通過使用schedule來對張量計算進行等價變換,從中計算出執行效率最高的schedule結構。整個schedule流程如下圖:

從中可以看出,TVM除了采用了Halide的schedule方式外,還增加了三種針對GPU和TPU的schedule方式:specile memory scope,tensorization,latency hiding。這些schedule方式可以對一個張量運算進行等價變換,產生多種代碼結構,從中選擇出最有利于硬件執行的代碼結構。
3.1 并行優化
并行計算是提高硬件執行效率的重要一步,因為諸如卷積、矩陣計算等都是大量的可以并發進行的計算,如何優化并行結構對改善硬件性能很關鍵。在這里需要考慮兩點問題:一個是并行度,另外一個是數據共享。如果數據不共享那么就會增加數據讀寫消耗。而盡量利用可共享數據,則需要盡心設計一個計算結構。
TVM提出了memory scope的概念,其將數據計算進行可并行和不可并行分類,對于可以并行計算的,就可以使用多線程來并行計算,而不可并行,則需要等待被依賴數據計算完成。比如一個矩陣乘法例子:

在XRNN中也會遇到類似的問題,對于不同的計算比如矩陣乘法和激活函數,如果沒有依賴的話,就是可以并行執行的。
3.2 存儲讀寫優化
在FPGA中讀寫cache或者external ddr也是一筆開銷。如何將存儲讀寫開銷降低也有利于提高硬件執行效率。比如在我們的XRNN中,save數據到ddr會消耗很多時間,而這個數據下一次又會被利用,同時又增加了load的時間。如果將數據緩存到片上,那么就減少了load和save開銷。還有比如片上cache也會來回讀寫數據,如果可以將一個計算完成的數據直接送給下一個計算核,實現流水,那么讀寫cache開銷也節省了。
對于隱藏存儲讀寫開銷還有一種方法,在下一次計算開始前而這一次計算正在進行的時候,就進行片外數據加載,就將加載和計算重合了,減少額外加載消耗的時間。
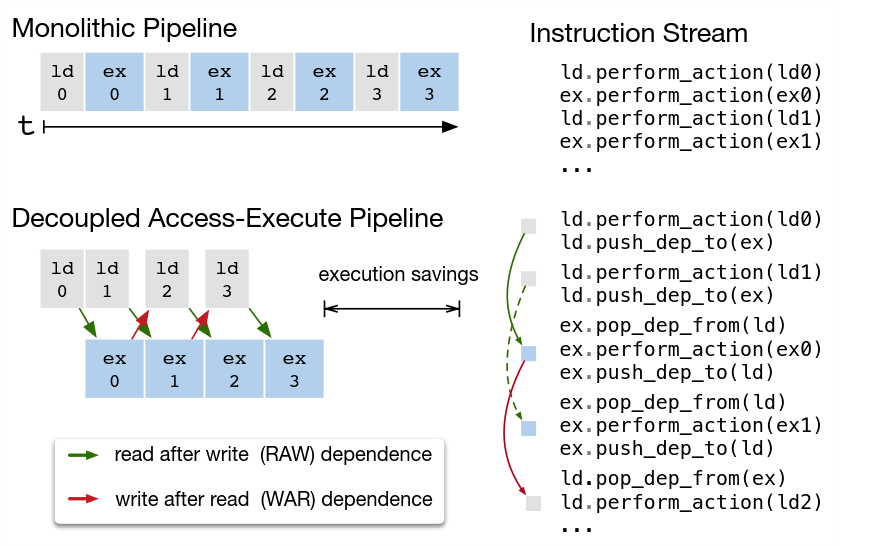
4. 自動優化器
TVM在豐富的schedule方式基礎上,提出了一個機器學習模型來尋找最優化的schedule結構。其包含兩部分:一部分是基于schedule方式產生所有可能的計算結構;另外一個是機器學習代駕模型來預測性能。
Schedule空間是巨大的,它可能產生很多種計算流結構,而對其中進行探索,找到最合適的結構。這會產生大量的計算。不過在我們的XRNN結構中,因為受到硬件內核的限制,還是可以對空間進行縮減的。只采用最可能影響性能schedule方式。比如矩陣乘、加法、點乘、激活這些不同的計算可以進行并發和非并發安排,這樣的空間相對小,有利于加速編譯器生成工作。
機器學習代價模型主要考慮了不同操作的延時來預測性能:存儲訪問方式,數據重利用,pipeline等。TVM中對代價函數的求解不是通過隨機統計方式,而是使用實時的配置數據進行訓練,周期性更替代碼結構。人為的探尋更合理的優化結構,然后提供給模型,讓其不斷更替。這種方式避免了探索大量schedule空間的時間消耗,同時也能更接近于實際情況。
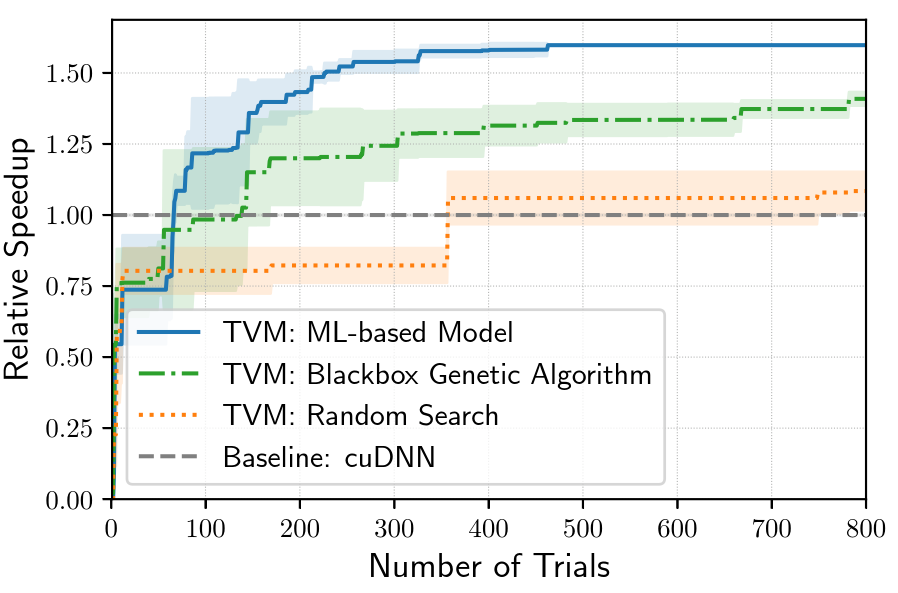
總結
以上簡要介紹了TVM的整體架構和基本方法,其實還挺符合FPGA加速硬件結構的。很多方法還是可以借用的。而且TVM是一個兼容更廣的編譯器架構,針對我們自身的FPGA特性,也會有很多不一樣的設計。
審核編輯:湯梓紅
-
FPGA
+關注
關注
1630文章
21769瀏覽量
604647 -
cpu
+關注
關注
68文章
10889瀏覽量
212383 -
編譯器
+關注
關注
1文章
1638瀏覽量
49197 -
深度學習
+關注
關注
73文章
5510瀏覽量
121337
原文標題:TVM編譯器
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

TVM主要的編譯過程解析
TVM整體結構,TVM代碼的基本構成
編譯器是如何工作的_編譯器的工作過程詳解
MPLAB? XC8 C編譯器的架構特性

TVM的編譯流程是什么

TVM學習(三)編譯流程
基于C++編譯器的節點融合優化方法
linux的系統移植——交叉編譯器

領域編譯器發展的前世今生
新版編譯器的設計思路和優化方法






 工商網監
工商網監
評論