 ARM NEON在矩陣&向量計算中的加速概述
ARM NEON在矩陣&向量計算中的加速概述
一、概述
NEON是ARM上使用的一種SIMD(Single Instruction Multiple Data – 單指令多數據)指令集。可實現64位/128位的并行計算。簡單理解就是一個計算指令,可以指定4個Float和4個Float并行計算(也可以是其他數據類型,但是必須包含在64位/128位內),得到4個Float結果。而不是一次只能一個Float和一個Float的計算。
比如在RGB顏色轉灰色時,計算公式為:Gray = R *0.299 + G *0.587 + B * 0.114,計算過程是由3個float乘法,2個加發組成,共有5個計算指令;如果直接使用NEON指令,就是可以直接通過一個指令計算完成,提升80%的理論性能。
矩陣計算就更為明顯,在4x4的矩陣和4個元素的向量相乘時,有16個float乘法和12個加法計算;NEON可以4個指令直接計算,提升的性能更明顯。
當然,這種計算需要是一種矩陣或者像素計算密集型的場景,比如RGB圖片轉黑白色,不通過GPU加速,而是通過CPU計算的場景;有多個3D模型,每幀需要為每個3D模型進行矩陣計算等等。
二、NEON在矩陣&向量中的計算示例
向量的點積運算示例(這里向量以4個元素為例,前3個元素通常表示3D空間的xyz坐標,第4個元素w用于齊次坐標;也可以表示顏色的RGBA)。兩個向量分別是:,,向量的點積計算公式:。對應的NEON加速代碼如下:

類似vdupq_n_f32、vld1q_f32、vmlaq_f32、vadd_f32、vget_lane_f32等等APIs,都是ARM NEON的intrinsics指令,C格式的API。并且這些APIs都定義在arm_neon.h頭文件中。ARM NEON指令有兩種實現方式,一種就是示例中的Intrinsics指令,另外一種就是直接使用NEON的匯編指令,嵌入到C語言代碼中。我們這里只是以Intrinsics指令為例,匯編指令在原理上一樣。
三、示例代碼中APIs的說明
3.1 ARM NEON向量寄存器
向量寄存器用來存放向量數據,每個向量元素的類型必須相同。這個向量寄存器有128位,AArch64有32個這個寄存器,AArch32/Armv7有16個這個寄存器。
每個寄存器可以表示2個double float類型數據(每個數據占用64位),4個float類型數據(每個數據占用32位),8個short類型數據(每個數據占用16位),16個byte類型數據(每個數據占用8位)。數據類型可以是整形,也可以是浮點數,只要占用位數對齊,類型統一即可。

3.2 示例說明
在計算時,第一步是要把C代碼中定義的數據(數組的形式存在,在運行棧中,或者在堆中)加載到向量寄存器中,第二步通過寄存器進行并行計算,第三步把結果寫入到指定寄存器,第四步寄存器結果寫入C代碼對應的變量中(即C語言的棧或者堆中)。

第一步:vld1q_f32的意思就是把” A + k”地址指向的內容加載到向量寄存器。f32的意思是,一個值是32位。這個命令是從指定地址,連續復制數據到寄存器,并填滿寄存器。比如,這里一個數據是32位,一個寄存器128位,也就是這個命令會連續填充4個f32值。說明:這里是多對(“K”個)向量進行點積計算。
第二步:vmlaq_f32意思是把兩個寄存器中,并行4個通道的4個f32分別對應相乘,同時把結果和保存結果的寄存器對應通道進行累加。
第三步:vget_high_f32、vget_low_f32是取寄存器的高位和低位(按照f32的type,分別有2個通道),vadd_f32就是獲取高位2通道和低位2通道分別相加,存到一個float32x2_t數據格式用(f32類型,2通道)。vpadd_f32中的p是pairwise,意思是將參數兩個向量的相鄰數據進行計算,這里就是r自己的2個相鄰通道相加。
第四步:vget_lane_f32比較簡單,就是獲取第一個參數寄存器中指定通道的值。這里就是第0通道的值。并寫會到一個float值中。
四、點積的推廣
這里的點積相對比較復雜,考慮到了一些通用性。這里使用了一個for循環,當只是計算兩個4元素向量的點積時,可以把for循環去掉,vmlaq_f32由vmull_f32替換即可。vmull_f32的原型:Result_t vmull_type(Vector_t N, Vector_t M),Result_t可以是float32x4_t,M和N就是left_vec和right_vec。
如果進行叉乘,則不需要進行第三步,直接返回一個float32x4_t的類型數據即可。
如果計算矩陣(4x4)和向量(4通道)相乘,就是計算點積4次,并且結果分別放到float32x4_t類型的4個通道中。
如果是矩陣(4x4)相乘則是4個叉乘。
這四種情況可以自己根據上方點積的計算方式,獨立寫出。
五、數據類型和函數指令說明
其實NEON Intrinsics指令中,對使用的變量類型、函數定義做了擴展,便于記憶和理解。
1.比如下方的數據類型:

A. int是數據類型,可以是int/uint/float/poly等等。
B. 后邊幾個數字由‘x’號鏈接,第一個數字就是每個元素的大小,這里是bit,而非Byte,可以是8/16/32/64。
C. 第二個數字是通道。比如表示顏色的RGBA,就是4通道,每個通道可以用一個byte表示(這里其實就是int8類型)。表示3D空間坐標,可以是xyz,就是3通道。如果是一個2D平面,就是一個xy,2通道了。
D. 最后一個數字表示有多少個。比如一個3D空間坐標xyz,一個四邊形有4個頂點,這里就可以表示4(這個值通常是一個2的次冪數)。
這里可以根據實際情況選擇自己的數據類型。不過要注意,這里要和128位對齊,符合自己實際數據對齊邏輯,不能超出。
2.函數也有類似的表達方式,例如:

v表示的AArch32/Armv7的指令
p表示pairwise計算。這里表示的是a和b向量的相鄰數據進行兩兩和操作,如下方的操作方式:

add就是加法,加減乘除普通計算,還有一些操作,比如加載、存儲、移位、邏輯計算、類型轉換等等。
q表示試用128位的向量計算器,不然就使用64位向量寄存器。
s8就是數類型了,可以是:u8、s8、u16、s16、u32、s32、f32、f64。
更多的內容可以在底部參考資料中,找到相關內容。
通過數據類型和函數類型,我們就可以根據實際情況,結合這些函數,封裝我們自己的加速代碼邏輯,達到優化的目的。
六、總結
這里只是對點積計算方式進行了解析,同時對于其他情況的推廣。其實對于int、char等類型可以類比計算。對像素、向量、矩陣等等的計算會成倍提升(理論性能提升16、8、4、2倍不等,根據實際類型確定)。特別是在移動端,圖形計算、圖形處理領域,CPU性能遇到瓶頸,進行性能優化時,NEON指令是一個不錯的優化點。
-
ARM
+關注
關注
134文章
9097瀏覽量
367585 -
寄存器
+關注
關注
31文章
5343瀏覽量
120377 -
RGB
+關注
關注
4文章
798瀏覽量
58510 -
C語言
+關注
關注
180文章
7604瀏覽量
136842 -
NEON技術
+關注
關注
1文章
9瀏覽量
6089
發布評論請先 登錄
相關推薦
張量計算在神經網絡加速器中的實現形式
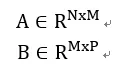
gprs流量計算軟件
MATLAB變量—標量,向量,矩陣
電池的電量計算
Vector向量計算技術與SIMD技術的對比
Vector向量計算技術與SIMD技術的對比簡述
簡述ARM SVE的發展以及和NEON的區別來探討Vector在AI中的應用
電感量計算






 工商網監
工商網監
評論