") 爬蟲的基本工作原理 用Scrapy實(shí)現(xiàn)一個(gè)簡單的爬蟲
爬蟲的基本工作原理 用Scrapy實(shí)現(xiàn)一個(gè)簡單的爬蟲
數(shù)以萬億的網(wǎng)頁通過鏈接構(gòu)成了互聯(lián)網(wǎng),爬蟲的工作就是從這數(shù)以萬億的網(wǎng)頁中爬取需要的網(wǎng)頁,從網(wǎng)頁中采集內(nèi)容并形成結(jié)構(gòu)化的數(shù)據(jù)。
1、 爬蟲的基本工作原理
爬蟲是就是一個(gè)程序,這個(gè)程序的任務(wù)就是從給出的一組種子URL開始爬取網(wǎng)頁,并通過網(wǎng)頁間的鏈接爬取更多的網(wǎng)頁,根據(jù)爬蟲任務(wù)的需求,最終可能會(huì)爬取整個(gè)互聯(lián)網(wǎng)的網(wǎng)頁。
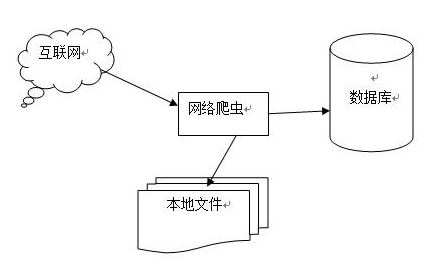
爬蟲的工作機(jī)制如下圖示:

URL就是網(wǎng)頁的網(wǎng)址,種子URL就是爬蟲要首先爬取的網(wǎng)頁網(wǎng)址,確定你的爬蟲程序首先從哪些網(wǎng)頁開始爬取。一組種子URL是指一個(gè)或多個(gè)的網(wǎng)頁地址。
爬蟲程序開始工作后,種子URL會(huì)先加入到待爬取網(wǎng)頁的隊(duì)列中,爬蟲程序從隊(duì)列按照先進(jìn)先出的原則獲取網(wǎng)頁URL,爬蟲程序開始爬取網(wǎng)頁,爬蟲會(huì)下載整個(gè)網(wǎng)頁內(nèi)容,然后提取網(wǎng)頁內(nèi)容,分析出網(wǎng)頁內(nèi)容包含的URL,并把新的URL加入到隊(duì)列。
當(dāng)隊(duì)列為空時(shí),爬蟲停止工作,否則爬蟲會(huì)繼續(xù)從隊(duì)列獲取網(wǎng)頁URL,爬取下一個(gè)網(wǎng)頁。
Python爬蟲基礎(chǔ)代碼如下:
# 導(dǎo)入隊(duì)列模塊
import queue as q
# 定義種子URL
seed_url = ["https://news.baidu.com/","https://money.163.com/"]
# 定義URL隊(duì)列
url_queue = q.Queue()
# 定義添加種子到隊(duì)列的函數(shù)
def put_seed():
for s in seed_url:
url_queue.put(s)
# 定義網(wǎng)址添加到隊(duì)列的函數(shù)
def put_url(url):
url_queue.put(url)
# 定義判斷隊(duì)列是否不為空函數(shù)
def is_queue_noempty():
if url_queue.empty():
return False
return True
# 定義從隊(duì)列獲取URL的函數(shù)
def get_url():
return url_queue.get()
# 定義網(wǎng)頁下載函數(shù)
def download_url(url):
text = "";
# 此處為下載代碼
pass
return text
# 定義網(wǎng)頁解析函數(shù)
def analysis(text):
# 此處為網(wǎng)頁內(nèi)容解析代碼
pass
# 網(wǎng)頁內(nèi)容處理與存儲(chǔ)代碼
process()
# 添加新URL到隊(duì)列
pass
# 定義網(wǎng)頁內(nèi)容處理與存儲(chǔ)函數(shù)
def process(objec=None):
# 此處為網(wǎng)頁內(nèi)容處理與存儲(chǔ)代碼
pass
if __name__ == "__main__":
print("------啟動(dòng)爬蟲------")
# 種子URL加入隊(duì)列
put_seed()
# 循環(huán)爬取隊(duì)列的URL
while is_queue_noempty():
# 從隊(duì)列獲取URL
url = get_url()
# 下載URL
text = download_url(url)
# 解析網(wǎng)頁內(nèi)容
analysis(text)
# 隊(duì)列為空,爬蟲停止
print("------爬蟲停止------")
用Scrapy實(shí)現(xiàn)一個(gè)簡單的爬蟲
Scrapy是一個(gè)為了爬取網(wǎng)站數(shù)據(jù),提取結(jié)構(gòu)性數(shù)據(jù)而編寫的應(yīng)用框架。應(yīng)用框架提供了很多工具和程序,讓我們可以輕松開發(fā)商業(yè)化爬蟲,商業(yè)化爬蟲是指實(shí)用的爬蟲程序。
下面用Scrapy實(shí)現(xiàn)一個(gè)簡單的爬蟲。
(1)創(chuàng)建爬蟲項(xiàng)目
使用Scrapy實(shí)現(xiàn)爬蟲,需要?jiǎng)?chuàng)建一個(gè)新的Scrapy項(xiàng)目。創(chuàng)建一個(gè)Scrapy項(xiàng)目非常簡單,使用Scrapy命令行工具就可以創(chuàng)建Scrapy項(xiàng)目,Scrapy命令行工具可以運(yùn)行在Windows的命令行窗口或Linux的終端窗口。
運(yùn)行命令行工具的語法如下:
scrapy < command > [options] [args]
其中,scrapy是工具名稱,command是命令,options是命令的選項(xiàng),args是命令需要的參數(shù),options和args是可選的,依據(jù)命令的要求傳入。
下面介紹三個(gè)主要的命令,創(chuàng)建項(xiàng)目命令、爬蟲創(chuàng)建命令和運(yùn)行項(xiàng)目爬蟲命令,因?yàn)檫@三個(gè)命令是馬上要用到的。其它命令會(huì)專門安排一個(gè)小節(jié)介紹。
創(chuàng)建項(xiàng)目命令
創(chuàng)建項(xiàng)目的語法如下:
scrapy startproject < project_name >
其中startproject是創(chuàng)建項(xiàng)目的命令名稱,project_name是項(xiàng)目名稱。例如:要?jiǎng)?chuàng)建一個(gè)爬取百度新聞網(wǎng)站數(shù)據(jù)的爬蟲,項(xiàng)目名稱可以是newsbaidu。
創(chuàng)建newsbaidu項(xiàng)目的命令如下:
scrapy startproject newsbaidu
爬蟲創(chuàng)建命令
爬蟲創(chuàng)建命令用于在項(xiàng)目中創(chuàng)建一個(gè)爬蟲,爬蟲的英文名稱spider。這是創(chuàng)建spider的一種快捷方法,該命令可以使用提前定義好的模板來生成spider,也可以自己創(chuàng)建spider的源碼文件。
爬蟲創(chuàng)建命令的語法如下:
scrapy genspider [-t template] < name > < domain >
其中g(shù)enspider是爬蟲創(chuàng)建命令的命令名稱,template用來設(shè)置爬蟲源代碼的模板名稱,這是一個(gè)可選項(xiàng),采用scrapy的默認(rèn)爬蟲模板即可,name是爬蟲名稱,domain是該爬蟲要爬取的網(wǎng)站域名。
運(yùn)行項(xiàng)目爬蟲命令
一個(gè)scrapy項(xiàng)目可以運(yùn)行多個(gè)爬蟲,運(yùn)行項(xiàng)目爬蟲命令的語法如下:
scrapy crawl < spider >
其中crawl是運(yùn)行項(xiàng)目爬蟲命令的名稱,spider是爬蟲名稱,也就是使用爬蟲創(chuàng)建命令創(chuàng)建的爬蟲名稱。
創(chuàng)建爬蟲項(xiàng)目及爬蟲
在Windows命令行窗口,將存儲(chǔ)項(xiàng)目文件的目錄設(shè)置為當(dāng)前目錄,使用scrapy工具的startproject命令創(chuàng)建爬蟲項(xiàng)目newsbaidu,項(xiàng)目名稱也可以是其它名稱,在Windows命令行窗口輸入下面的命令:
scrapy startproject newsbaidu
在項(xiàng)目中創(chuàng)建爬蟲spider_newsbaidu,設(shè)置項(xiàng)目所在目錄為當(dāng)前工作目錄,在Windows命令行窗口輸入下面的命令:
scrapy genspider spider_newsbaidu https://news.baidu.com
(2)定義要抓取的數(shù)據(jù)
開發(fā)爬蟲的目的是要爬取網(wǎng)站數(shù)據(jù),并提取出結(jié)構(gòu)化數(shù)據(jù)。要做的第一步工作就是根據(jù)要爬取的網(wǎng)站內(nèi)容構(gòu)成,定義一個(gè)結(jié)構(gòu)化數(shù)據(jù),存儲(chǔ)從網(wǎng)站提取的數(shù)據(jù)。
在scrapy中,通過scrapy Items來完成結(jié)構(gòu)化數(shù)據(jù)的定義。在scrapy創(chuàng)建的爬蟲項(xiàng)目中,items.py文件就是一個(gè)Items,在Items可以定義要爬取的數(shù)據(jù)。
例如:要抓取百度新聞網(wǎng)站(news.baidu.com)的熱點(diǎn)新聞條目,并獲取新聞條目的文章標(biāo)題、文章鏈接數(shù)據(jù)。
可以在項(xiàng)目的items.py文件中定義下面的數(shù)據(jù)結(jié)構(gòu):
# 導(dǎo)入scrapy庫
import scrapy
#自定義NewsbaiduItem用于存儲(chǔ)爬蟲所抓取的字段內(nèi)容
class NewsbaiduItem(scrapy.Item):
# 定義要爬取的數(shù)據(jù):
# 文章標(biāo)題
news_title = scrapy.Field()
# 文章鏈接
news_link = scrapy.Field()
NewsbaiduItem類繼承scrapy.Item類,它是一個(gè)Scrapy Items,它定義了兩個(gè)數(shù)據(jù)字段,分別是news_title和news_link。
類似這樣的Scrapy Items可以定義多個(gè),以適應(yīng)爬取不同的網(wǎng)站數(shù)據(jù)。
(3)編寫一個(gè)爬蟲程序
定義了存儲(chǔ)爬取數(shù)據(jù)的Scrapy Items,就可以開始編寫爬蟲程序了。首先要確定百度新聞網(wǎng)站的起始頁,也就是百度新聞網(wǎng)站的種子URL。
爬蟲的種子URL:www.news.baidu.com
種子URL是百度新聞網(wǎng)站的首頁,需要查看百度新聞網(wǎng)站的首頁源碼,確定提取新聞條目的規(guī)則,編寫XPath表達(dá)式。
如何查看網(wǎng)頁源碼?
使用瀏覽器打開百度新聞網(wǎng)站的首頁,單擊鼠標(biāo)右鍵,在彈出的菜單中選擇“查看網(wǎng)頁源代碼”命令,不同瀏覽器可能有不同的命令名稱。
觀察網(wǎng)頁源代碼,找出數(shù)據(jù)提取規(guī)則
觀察首頁源代碼發(fā)現(xiàn),新聞條目的源代碼一般都通過下面的超鏈接標(biāo)簽實(shí)現(xiàn):
< a href="https://3w.huanqiu.com/a/9eda3d/3zT0a2ZsWaC?agt=8"
mon="ct=1&a=2&c=top&pn=15"
target="_blank" >
英國將法國荷蘭列入隔離清單,法國:將采取“對等措施”
< /a >
其中,“a”是超鏈接標(biāo)簽,也稱為a標(biāo)簽。“href”是超鏈接的目標(biāo)屬性,“mon”應(yīng)是百度新聞網(wǎng)站自定義的一個(gè)超鏈接屬性,每個(gè)新聞條目的a標(biāo)簽都帶有mon屬性,通過a標(biāo)簽的mon屬性可以和網(wǎng)頁的其它a標(biāo)簽區(qū)分開。
提取新聞條目的XPath表達(dá)式如下:
//a[contains(@mon,'ct=1')]
a標(biāo)簽的mon屬性值的“&”是轉(zhuǎn)義符,表示這是一個(gè)“&”字符,在XPath表達(dá)式中只有判斷mon屬性值包含字符串“ct=1”就可以提取網(wǎng)頁所有的新聞條目。
編寫爬蟲代碼
項(xiàng)目spiders目錄下的spider_newsbaidu.py是scrapy創(chuàng)建的一個(gè)爬蟲模板文件,可以在此基礎(chǔ)上修改代碼。
模板文件代碼如下:
import scrapy
class SpiderNewsbaiduSpider(scrapy.Spider):
name = 'spider_newsbaidu'
allowed_domains = ['https://news.baidu.com']
start_urls = ['https://news.baidu.com/']
def parse(self, response):
pass
SpiderNewsbaiduSpider類繼承scrapy.Spider類。屬性name是爬蟲名稱,該名稱可用于運(yùn)行項(xiàng)目爬蟲的crawl命令;屬性allowed_domains是要爬取的網(wǎng)站域名,start_urls是種子URL,start_urls是一個(gè)列表對象,可以定義多個(gè)種子URL。
在SpiderNewsbaiduSpider類可以編寫爬取網(wǎng)站的代碼,從下載的網(wǎng)頁代碼中提取超鏈接,加入爬取隊(duì)列,以及從網(wǎng)頁的內(nèi)容中提取結(jié)構(gòu)化數(shù)據(jù)。
類方法parse(response)用于解析網(wǎng)頁內(nèi)容,提取網(wǎng)頁的超鏈接和結(jié)構(gòu)化數(shù)據(jù)。該方法是一個(gè)回調(diào)函數(shù),會(huì)被Request對象調(diào)用,Request對象是向網(wǎng)頁發(fā)出請求訪問的對象,該對象會(huì)返回一個(gè)response對象,并調(diào)用parse(response)方法對response對象進(jìn)行處理。
傳入的參數(shù)是response對象,response對象封裝了爬蟲從網(wǎng)站爬取的內(nèi)容,通過response對象可以獲取爬取的網(wǎng)頁內(nèi)容。
修改后的爬蟲代碼如下:
import scrapy
# 導(dǎo)入scrapy選擇器
from scrapy.selector import Selector
# 導(dǎo)入NewsbaiduItem
from newsbaidu.items import NewsbaiduItem
class SpiderNewsbaiduSpider(scrapy.Spider):
name = 'spider_newsbaidu'
allowed_domains = ['https://news.baidu.com']
start_urls = ['https://news.baidu.com/']
def parse(self, response):
# 獲取爬取下來的網(wǎng)頁內(nèi)容
html = response.text
# 使用xpath表達(dá)式搜尋指定的a標(biāo)簽節(jié)點(diǎn),節(jié)點(diǎn)以列表方式返回
item_nodes = response.xpath("http://a[contains(@mon,'ct=1')]").extract()
# 遍歷節(jié)點(diǎn)
for item_node in item_nodes:
# 使用xpath表達(dá)式獲取節(jié)點(diǎn)的href屬性值
a_href = Selector(text=str(item_node)).xpath('//@href').extract()
# 使用xpath表達(dá)式獲取節(jié)點(diǎn)的文本內(nèi)容
a_text = Selector(text=str(item_node)).xpath('//text()').extract()
# 實(shí)例化NewsbaiduItem對象
item = NewsbaiduItem()
item["news_title"] = a_text
item["news_link"] = a_href
# 使用yield語句返回item給parse的調(diào)用者
yield item
主要修改了parse()方法,在parse()方法內(nèi),通過response對象的text屬性獲取scrapy下載的網(wǎng)頁內(nèi)容,通過response對象的xpath()方法執(zhí)行XPath表達(dá)式選取網(wǎng)頁節(jié)點(diǎn)或節(jié)點(diǎn)文本,將提取的網(wǎng)頁數(shù)據(jù)存儲(chǔ)到NewsbaiduItem對象。
parse()方法使用了yield語句,因此parse()方法是一個(gè)生成器函數(shù),當(dāng)parse()方法的調(diào)用者需要一個(gè)迭代對象時(shí),parse()方法會(huì)返回這個(gè)迭代對象。
parse()方法返回的迭代對象主要是兩類:一類是scrapy Items類型的實(shí)例對象;一類是scrapy Request類型的實(shí)例對象,Request對象封裝了請求的URL。
(4)運(yùn)行爬蟲
當(dāng)前創(chuàng)建的SpiderNewsbaiduSpider爬蟲還是非常簡單的,在爬蟲內(nèi)并沒有處理網(wǎng)頁內(nèi)新聞條目外的超鏈接,因此爬蟲處理完該網(wǎng)頁內(nèi)容后,就會(huì)自行結(jié)束爬取過程。隨著對scrapy框架的深入了解,會(huì)逐漸完善SpiderNewsbaiduSpider爬蟲。
現(xiàn)在可以運(yùn)行爬蟲了,爬取的數(shù)據(jù)暫時(shí)存儲(chǔ)到j(luò)son文件,在后面的課程會(huì)存儲(chǔ)到數(shù)據(jù)庫。
在Windows命令行窗口,將當(dāng)前目錄切換到項(xiàng)目的根目錄,輸入下面的命令:
scrapy crawl spider_newsbaidu -o items.json
其中spider_newsbaidu是爬蟲名稱,選項(xiàng)-o是將Items輸出到文件,選項(xiàng)-o后面的參數(shù)是文件名稱。
執(zhí)行運(yùn)行爬蟲的命令后,爬蟲爬取的數(shù)據(jù)會(huì)存儲(chǔ)到項(xiàng)目根目錄下的items.json文件,可以使用記事本查看items.json文件內(nèi)容。
若items.json文件的中文內(nèi)容顯示為文字編碼,需要在setting.py文件中添加FEED_EXPORT_ENCODING配置項(xiàng),該配置項(xiàng)用于設(shè)置輸出文件的字符編碼方式,scrapy輸出文件的默認(rèn)字符編碼是ASCII。
通過在setting.py文件添加下面的配置項(xiàng)將scrapy輸出文件字符編碼設(shè)置為utf-8。
FEED_EXPORT_ENCODING = 'utf-8'
** Scrapy爬蟲的工作機(jī)制**
基于當(dāng)前學(xué)到的scrapy知識(shí),整理出scrapy的工作機(jī)制,在后面的課程會(huì)逐步完善scrapy的工作機(jī)制。

Scrapy引擎是Scrapy框架的核心,它可以啟動(dòng)多個(gè)爬蟲,并管理爬蟲的運(yùn)行。
它會(huì)將爬蟲提取的Request對象放入到Scrapy調(diào)度器(可以把Scrapy調(diào)度器看作是URL隊(duì)列管理),同時(shí)它會(huì)調(diào)用Items數(shù)據(jù)處理器處理爬蟲提取的Items數(shù)據(jù)。
Scrapy引擎會(huì)維持爬蟲的運(yùn)行,維持爬蟲運(yùn)行的機(jī)制就是不斷從URL隊(duì)列管理器獲取Request對象,調(diào)用下載管理器向Request對象指定的URL發(fā)出Request請求,下載URL所在服務(wù)器返回的內(nèi)容,并返回Responses對象。
Request對象會(huì)回調(diào)在Request對象設(shè)置的回調(diào)函數(shù),并傳入Responses對象。若Request對象沒有設(shè)置回調(diào)函數(shù),將會(huì)調(diào)用Spider的parse()方法。
-
互聯(lián)網(wǎng)
+關(guān)注
關(guān)注
54文章
11155瀏覽量
103309 -
代碼
+關(guān)注
關(guān)注
30文章
4788瀏覽量
68612 -
python
+關(guān)注
關(guān)注
56文章
4797瀏覽量
84688 -
爬蟲
+關(guān)注
關(guān)注
0文章
82瀏覽量
6880
發(fā)布評論請先 登錄
相關(guān)推薦
Python數(shù)據(jù)爬蟲學(xué)習(xí)內(nèi)容
Python爬蟲與Web開發(fā)庫盤點(diǎn)
Python爬蟲初學(xué)者需要準(zhǔn)備什么?
什么語言適合寫爬蟲
什么語言適合寫爬蟲
Python爬蟲速成指南讓你快速的學(xué)會(huì)寫一個(gè)最簡單的爬蟲
爬蟲是如何實(shí)現(xiàn)數(shù)據(jù)的獲取爬蟲程序如何實(shí)現(xiàn)
如何理解爬蟲工程師
python實(shí)現(xiàn)簡單爬蟲的資料說明






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論