 理解KV cache的作用及優化方法
理解KV cache的作用及優化方法
作者丨紫氣東來
在 Transformer 的 Encoder-base 的模型(如 BERT系列)中,推理和訓練過程保持了高度的統一性(差異僅僅在于是否存在反向過程)。而在 Decoder-base 的生成式模型(如 GPT系列)中,推理和訓練存在相當大的差異性,主要體現在推理過程具有以下3點特征:
自回歸
兩階段(第一階段輸入 prompt,第二階段輸入上一個生成的token)
KV cache
以上三點實際上也是相輔相成、不可分割的,其中自回歸的生成模式是根本原因,兩階段是外在的體現形式,KV cache是優化手段。
下面將通過梳理整個推理過程,來理解 KV cache 的作用及優化方法。
一、KV cache 的由來與基本矛盾

第一階段(prompt 輸入):

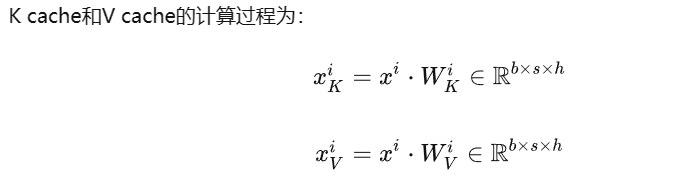

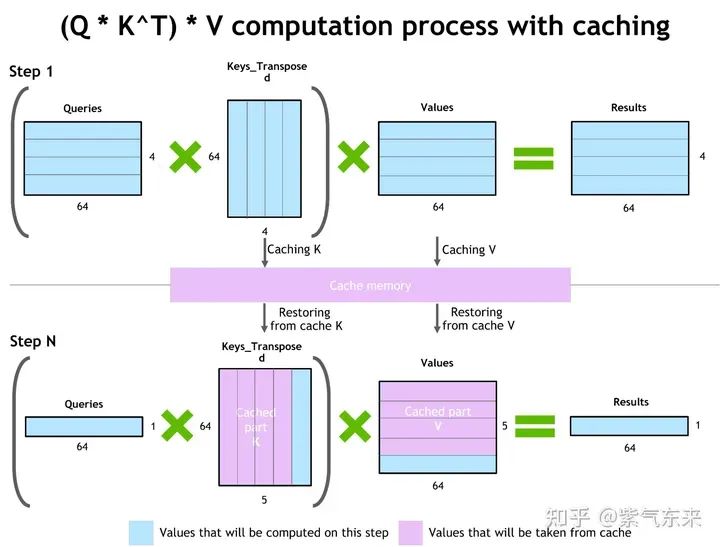
KV cache 作用過程
第二階段(token by token):
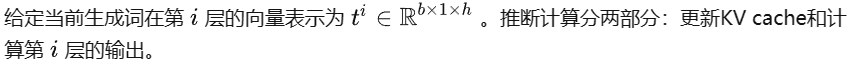

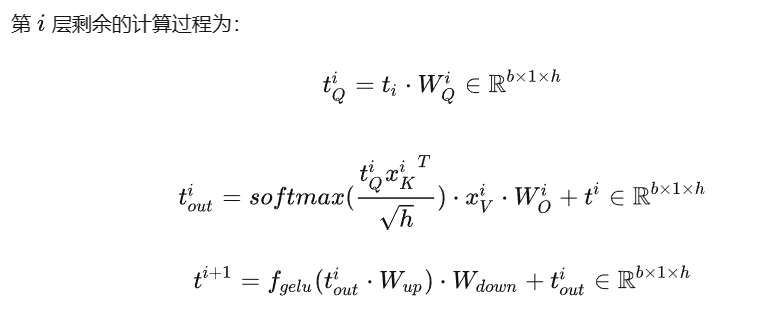
KV cache的顯存占用分析
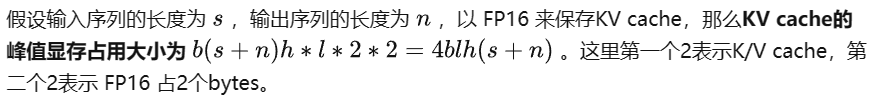

| batch size | s+n | KV cache(GB) | KV cache/weight |
|---|---|---|---|
| 4 | 4096 | 81 | 0.23 |
| 16 | 4096 | 324 | 0.93 |
| 64 | 4096 | 1297 | 3.71 |
可見隨著 batch size 和 長度的增大,KV cache 占用的顯存開銷快速增大,甚至會超過模型本身。
而 LLM 的窗口長度也在不斷增大,因此就出現一組主要矛盾,即:對不斷增長的 LLM 的窗口長度的需要與有限的 GPU 顯存之間的矛盾。因此優化 KV cache 就顯得非常必要。
二、KV cache 優化的典型方法
2.1 共用 KV cache:MQA,GQA
MQA (Multi Query Attention,多查詢注意力) 是多頭注意力的一種變體。其主要區別在于,在 MQA 中不同的注意力頭共享一個K和V的集合,每個頭只單獨保留了一份查詢參數。因此K和V的矩陣僅有一份,這大幅度減少了顯存占用,使其更高效。由于MQA改變了注意力機制的結構,因此模型通常需要從訓練開始就支持 MQA 。也可以通過對已經訓練好的模型進行微調來添加多查詢注意力支持,僅需要約 5% 的原始訓練數據量 就可以達到不錯的效果。包括 Falcon、SantaCoder、StarCoder 等在內很多模型都采用了 MQA 機制。
# Multi Head Attention self.Wqkv = nn.Linear( # Multi-Head Attention 的創建方法 self.d_model, 3 * self.d_model, # Q、K和V 3 個矩陣, 所以是 3 * d_model device=device ) query, key, value = qkv.chunk(3, dim=2) # 每個 tensor 都是 (1, 512, 768) # Multi Query Attention self.Wqkv = nn.Linear( # Multi-Query Attention 的創建方法 d_model, d_model + 2 * self.head_dim, # 只創建Q的頭向量,所以是 1* d_model, 而K和V不再具備單獨的頭向量, 所以是 2 * self.head_dim device=device, ) query, key, value = qkv.split( [self.d_model, self.head_dim, self.head_dim], # query -> (1, 512, 768), key -> (1, 512, 96), value -> (1, 512, 96) dim=2 )
MHA v.s. GQA v.s. MQA
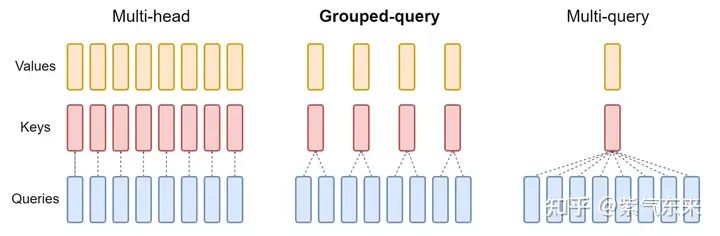
GQA(Grouped Query Attention,分組查詢注意力)是一種介于多頭注意力和 MQA 之間的折中方案。它將查詢頭(Query Heads)分組,并在每組中共享一個鍵頭(Key Head)和一個值頭(Value Head)。表達能力與推理速度:GQA既保留了多頭注意力的一定表達能力,又通過減少內存訪問壓力來加速推理速度。
MHA, GQA, MQA 性能比較
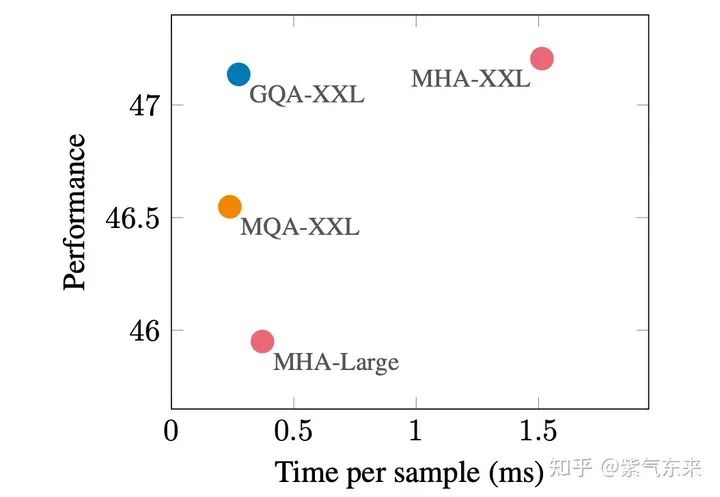
2.2 窗口優化

3)箭型 attention 窗口,在LM-Infinit中就已經被提出了,其基本原理和StreamingLLM是一致的。
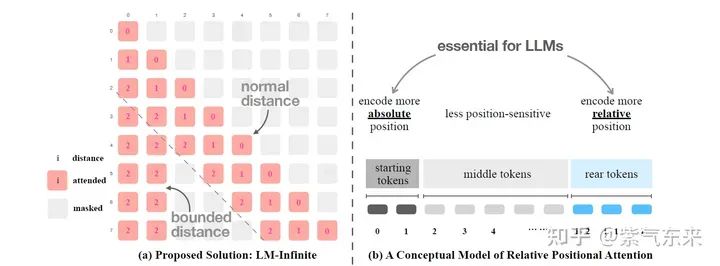
2.3 量化與稀疏
該類方法是基于壓縮的思想,通過量化與稀疏壓縮 KV cache 的 顯存消耗。
當前主流推理框架都在逐步支持 KV cache 量化,一個典型的案例是lmdeploy,下圖展示了其在TurboMind框架下 KV INT8 的支持情況。
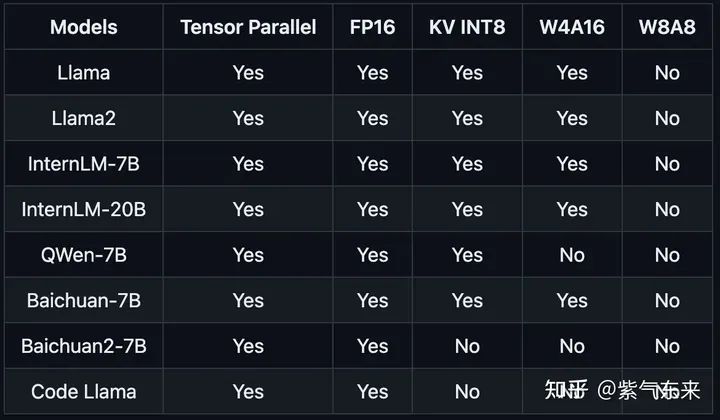
lmdeploy 的推理特性
稀疏的方法也比較簡單,其做法無外乎以下幾種方式:
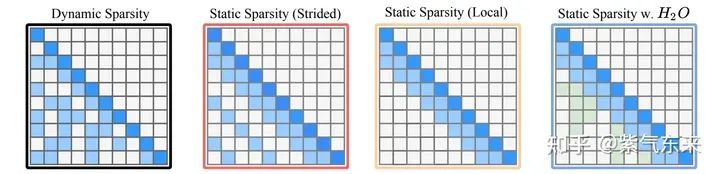
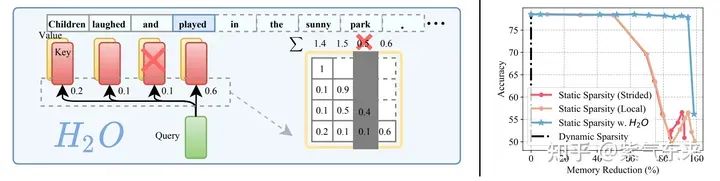
這里最值得一提的是H2O。簡單來說就是通過動態的評價方式來判斷需要保留和廢棄的KV值,其評估的算法如下所示:

結果顯示,在 KV cache 稀疏到只有原來的 20% 時仍然可以保持很高的精度。
2.4 存儲與計算優化
該方法的典型代表即vLLM的 PagedAttention,簡單來說就是允許在非連續的內存空間中存儲連續的 K 和 V。詳情可參考筆者之前的文章,在此不予贅述
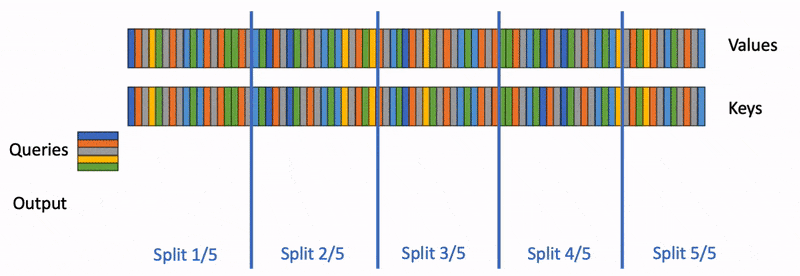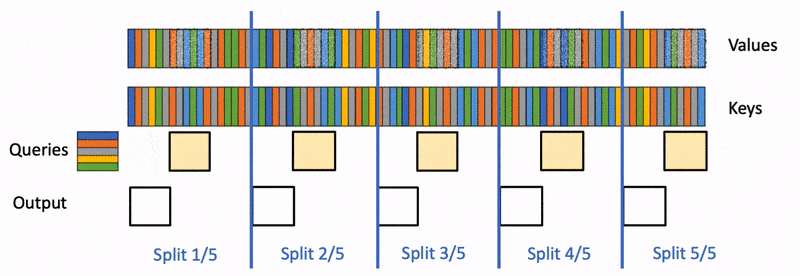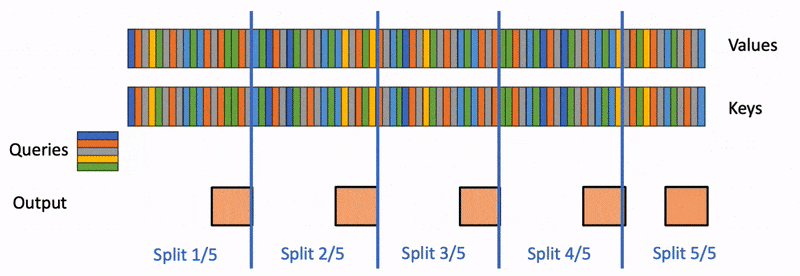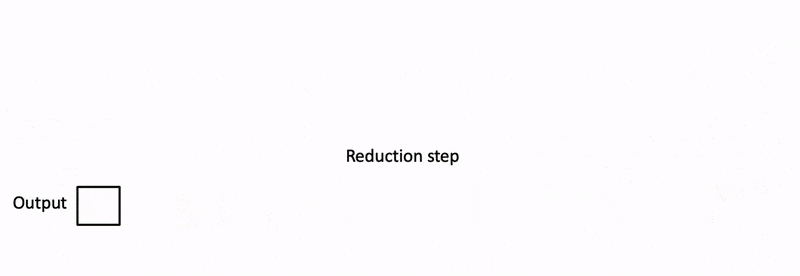
FlashDecoding 是在 FlashAttention 的基礎上針對 inference 的優化主要分為三步:
長文本下將KV分成更小且方便并行的chunk
對每個chunk的KV,Q和他們進行之前一樣的FlashAttention獲取這個chunk的結果
對每個chunk的結果進行reduce
三、StreamingLLM:簡潔高效的“無限長度”
StreamingLLM 的基本思想同樣是來源于上述的窗口思想,其最大的創新在于提出了識別并保存模型固有的「注意力池」(attention sinks)錨定其推理的初始 token。下面將詳細討論其工作的原理。
3.1 精度是如何保證的?
核心的發現:Lost in the Middle。
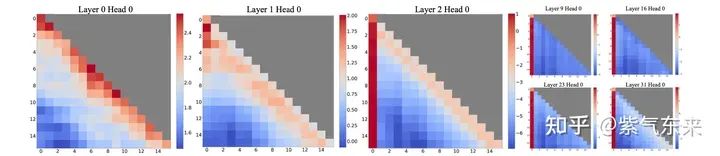
多個研究都發現,self-attention 的注意力比較集中于頭部和尾部,對文本中段的注意力相對較弱,如下圖所示:
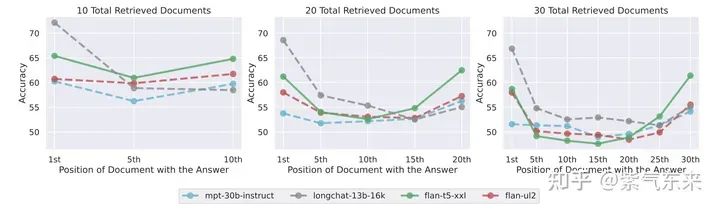
繪制出 self-attention 的熱力圖也能看到這一點,由此當文本長度超過額定長度時,頭部的 token 就會被遺棄掉,這就會在 softmax 階段產生很大的問題。


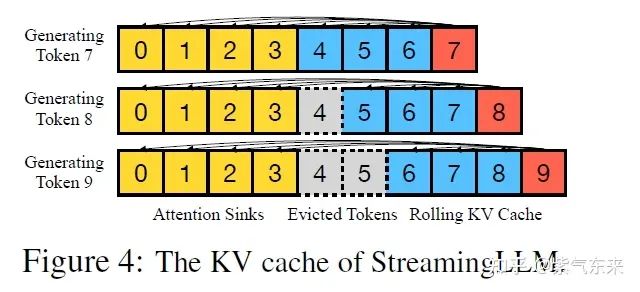
3.2 “無限長度”是如何做到的?
該問實際上可以換種表述為:如何在文本長度不斷增加的情況下,保證GPU顯存不會溢出。由于該方案主要應用于多輪對話的場景,那么有必要回顧一下當前多輪對話生成的主流做法,概括起來就以下幾點:
將用戶輸入與模型輸出拼接,中間做必要分割;
多個輪次之間倒序排列,并拼接;
如果前邊所有輪次長度之和超過最大長度,則截斷到最大長度;
上述過程可以用代碼描述如下:
history = ["
[|Human|]{}
[|AI|]{}".format(x[0], x[1]) for x in history]
history.append("
[|Human|]{}
[|AI|]".format(text))
history_text = ""
flag = False
for x in history[::-1]:
if tokenizer(prompt + history_text + x, return_tensors="pt")["input_ids"].size(-1) <= max_length:
? ? ? ? ? ?history_text = x + history_text
? ? ? ? ? ?flag = True
? ? ? ?else:
? ? ? ? ? ?break
? ?if flag:
? ? ? ?inputs = tokenizer(prompt + history_text, return_tensors="pt")
? ? ? ?input_ids = inputs["input_ids"][:, -max_length:].to(device)
? ? ? ?torch.cuda.empty_cache()
? ? ? ?return input_ids, text
? ?else:
? ? ? ?return None
實際上這就是典型的滑動窗口的做法,滑窗?的存在保證了 GPU 的顯存不會溢出,但是由于上節的討論,會存在精度損失。

審核編輯:黃飛
-
gpu
+關注
關注
28文章
4740瀏覽量
128949 -
GPT
+關注
關注
0文章
354瀏覽量
15373 -
LLM
+關注
關注
0文章
288瀏覽量
335
原文標題:漫談 KV Cache 優化方法,深度理解 StreamingLLM
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
內存分配及Cache優化
如何理解C6678中關于cache的描述?
請教關于EDMA和cache優化的疑惑
使用CACHE_disableCaching函數禁止cache沒起作用
Cache為什么還要分I-Cache,D-Cache,L2 Cache,作用是什么?
基于修正LRU的壓縮Cache替換策略
Cache中Tag電路的設計
降低Cache失效率的方法[2]
一種有效的Cache優化替換策略

Page Cache是什么 一文帶你深入理解Linux的Page Cache
什么是 Cache? Cache讀寫原理
Cache與性能優化精彩問答38條
深入理解Cache工作原理
Cache分類與替換算法





 工商網監
工商網監
評論