 簡單認識高級處理器
簡單認識高級處理器
除了傳統的處理器 (CPU、MPU/MCU、DSP 和 GPU),面向當代各種應用的高級處理器(Advanced Processors)層出不窮,例如加速處理單元 (AcceleratedProcessing Unit, APU) 、采用異構系統架構 ( Heterogeneous System Architecture,HSA) 特征設計的集成電路、基于人工神經網絡(Artificial Neural Networks,ANN) 深度學習 (Deep Learning)的高級處理器等。
1. 加速處理單元
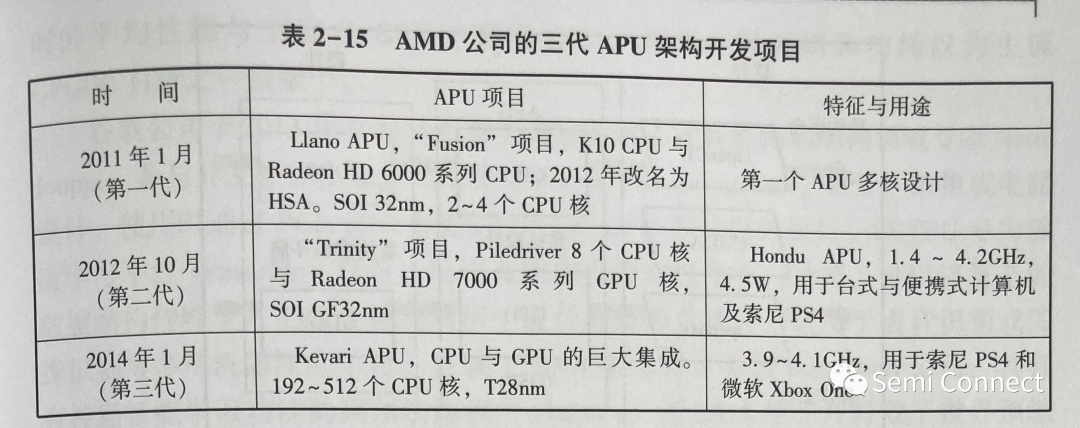
AMD 公司于2006 年收購了 ATI 公司,從設計傳統的串行計算處理器 CPU過渡到并行圖形處理器 GPU;經過研發升級,再將 CPU 和GPU 合為一體成為APU,集成為單個芯片,使得微處理器的性能得到改進,處理能力得以提高。APU 為隨后被擴展為 HSA 走出了一條新路。AMD 公司的三代 APU 架構開發項目見表 2-15。
2.采用異構系統架構特征設計的集成電路
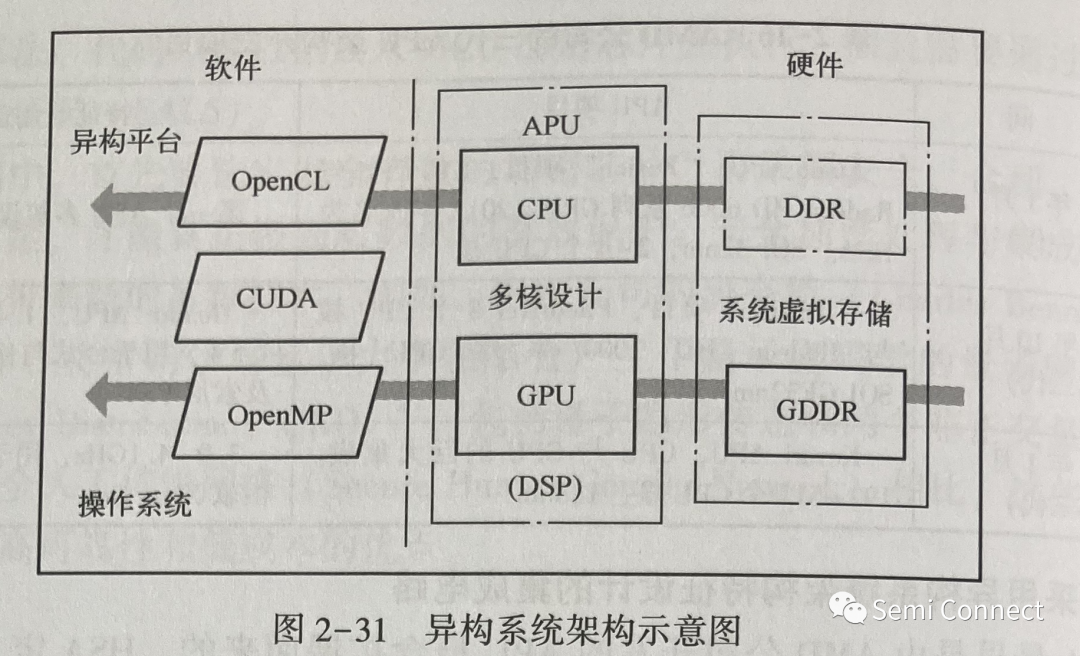
HSA 最早是由 AMD 公司開發的 APU 概念擴展而來的。HSA 定義了一套計算機硬件規范,其核心為 CPU 標量處理和 GPU (或者 DSP)并行處理的結合。與此相應的有開源軟件的開發與應用,包括系統級 C/C++高級語言、用于異構系統的開放計算語言 (Open Computing Language, OpenCL)結構、針對三維圖形(例如 GPU)的開放圖形庫 (Open Graphics Library, OpenGL)、開放多進程(Open Multi-Processing, OpenMP)應用程序接口、NVIDIA 公司開發的平行計算與應用接口 ( Compute Unified Device Architecture, CUDA) 的模型、支持多種操作系統的Python 等語言。2012年6月由 AMD、ARM、Imagination、聯發科(MediaTek)、高通和三星成立了非營利組織 HSA 協會。HSA 協會著重于開發和定義各種處理器(包括 CPU、GPU、DSP)以及存儲器的特點和接口;之后,該協會又添加了 ASIC 設計公司成員,從而建立起新型的并行計算異構系統架構,如圖2-31 所示。HSA 包括軟件和硬件兩大部分。軟件包括 OpenCL、OpenMP、CUDA 模型等。圖2-31中 CPU 和其專用存儲器 DDR,以及 GPU 和其專用存儲器 GDDR, 使用指針 (Pointer)功能傳遞,在HSA 系統中形成了共享的系統虛擬存儲器 (System Virtual Memory, SVM)。
3.基于人工神經網絡深度學習的高級處理量
約翰?麥卡錫(John McCarthy)在1956年最早使用了人工智能 (ArtificialIntelligence, AI)這個詞,他也因此被稱為 “人工智能之父”。AI通過使用機器學習 (Machine Learning)而設計的產品應用廣泛,發展迅速。1986 年 GeffreyHinton 等人發表了神經網絡中反向傳播算法(Back-Propagation Algorithm)的文章。2006 年Hinton 的這一研究有了新的突破,并提出了深度學習(DeepLearning)的概念。近年來,深度神經網絡 (Deep Neural Network, DNN)、卷積神經網絡 ( Convolutional Neural Network, CNN)、循環神經網絡 (RecurrentNeural Network,RNN,例如時間遞歸神經網絡,即 Long Short - Term Memory,LSTM)等深度學習方法大大推動了各種芯片的設計進程。
Intel 公司 2017 年推出了 Nervana 平臺,利用其 APU 產品 LakeCrest, 采用CPU 與FPGA 重組架構設計,用在深度學習的分析算法領域中。另外,Intel于2016-2017 年發布的高級CPU 都可以用在深度學習的相關領域。例如,2016年第一季度發布了 14nm 工藝制造的 Atom x5-Z8330 處理器,含有4 核4線程,L2緩存(Cache)為 2MB, 最高工作頻率為 1.92GHz。 Intel 于 2016 年第四季度發布了至強(Xeon Phi)系列處理器 7290,含72核,采用14nm 工藝,集成16GB 緩存,工作頻率為 1.5GHz。Intel 于 2017 年發布了第七代4核處理器 IntelCore-i7 系列,工作頻率為 3.5~4.5GHz。
IBM 公司承擔美國 DARPA 的 SyNAPSE 項目,基于 CNN 設計了認知計算機(Cognitive Computer),從而于 2014 年設計出備受關注的具有 4096 個 CPU 眾核的真北(TrueNorth) 神經網絡芯片,它有54 億個晶體管,功耗只有70mW。它模擬2.68 億個神經軸突(Synapse),每個 CPU 核可以模仿 256 個可編程的神經元 (Neuron),總共等效于 100 萬個神經元。??
中國科學院計算所2016年報道了結合 GPU 和 CPU 的深度學習專用處理器寒武紀(Cambrian)芯片,計算速度大為提高,為其虛擬現實研究建立了基礎。寒武紀1號(DianNao)芯片采用 65nm 工藝.芯片面積為 3.02mm2,主頻為0.98GHz,功耗為 0.485W,峰值性能達每秘 4520 億次神經網絡基本運算。寒武紀2 號(DaDianNao)芯片包含 16個處理器核,采用28nm 工藝,面積為67.7mm2,主頻為 606MHz,功耗約為 16W。據稱與主流 GPU 相比,寒武紀2號單芯片性能超過若干倍,能耗極低,高效能計算系統性能提升數百倍。寒武紀3號(PuDianNao)芯片采用 65nm 工藝,面積為 3.51mm2,主頻為 1GHz,功耗為0.596W,峰值性能達每秒10 560 億次基本操作。PuDianNao 運行機器學習算法時的平均性能與主流 GPGPU (通用GPU)相當,但面積和功耗僅為主流GPGPU 百分之一量級。???
谷歌公司于2013 年9月從惠普實驗室聘請了計算機體系結構領域專家 NormJouppi,參與開發被稱作張量處理器 (Tensor Processing Unit, TPU)的集成電路設計,使用時通過 PCle插口去優化 CPU 和 GPU 芯片組的運行。該TPU 專為深度學習平臺TensorFlow 打造,運用高層次機器深度學習與計算,可以將復雜的數據結構傳輸至人工智能神經網絡中進行分析和處理,可以用于語音識別或圖像識別等多項機器深度學習。谷歌于 2014 年合并了英國 DeepMind 公司,其具有神經智能學習功能的阿爾法圍棋(AlphaGo)于2016 年5月打敗了世界頂級圍棋棋手李世石。AlphaGo 2.0于2017 年6月打敗個人圍棋大賽四冠王柯潔。阿爾法圍棋是在 TPU 之上運行的,在人機比賽時最多使用了 1920 個 CPU 和 280個GPU。谷歌公司于2017 年4月5 日公開發表官方博客,介紹TPU 的架構,其處理 AI 事務速度比其他 GPU 與 CPU 結合模式快 15~30倍,計算能效高 50~80倍。這些進展為未來各種新型的高級處理器產品設計帶來新的激勵。
-
處理器
+關注
關注
68文章
19548瀏覽量
231873 -
dsp
+關注
關注
555文章
8080瀏覽量
352234 -
amd
+關注
關注
25文章
5520瀏覽量
135043 -
gpu
+關注
關注
28文章
4832瀏覽量
129802 -
深度學習
+關注
關注
73文章
5527瀏覽量
121893
原文標題:高級處理器,高級處理器,Advanced Processors
文章出處:【微信號:Semi Connect,微信公眾號:Semi Connect】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
別讓處理器編號混淆您的認識

視頻處理器讓投影變得更簡單

簡單認識IA-64架構處理器
簡單認識POWER系列架構處理器

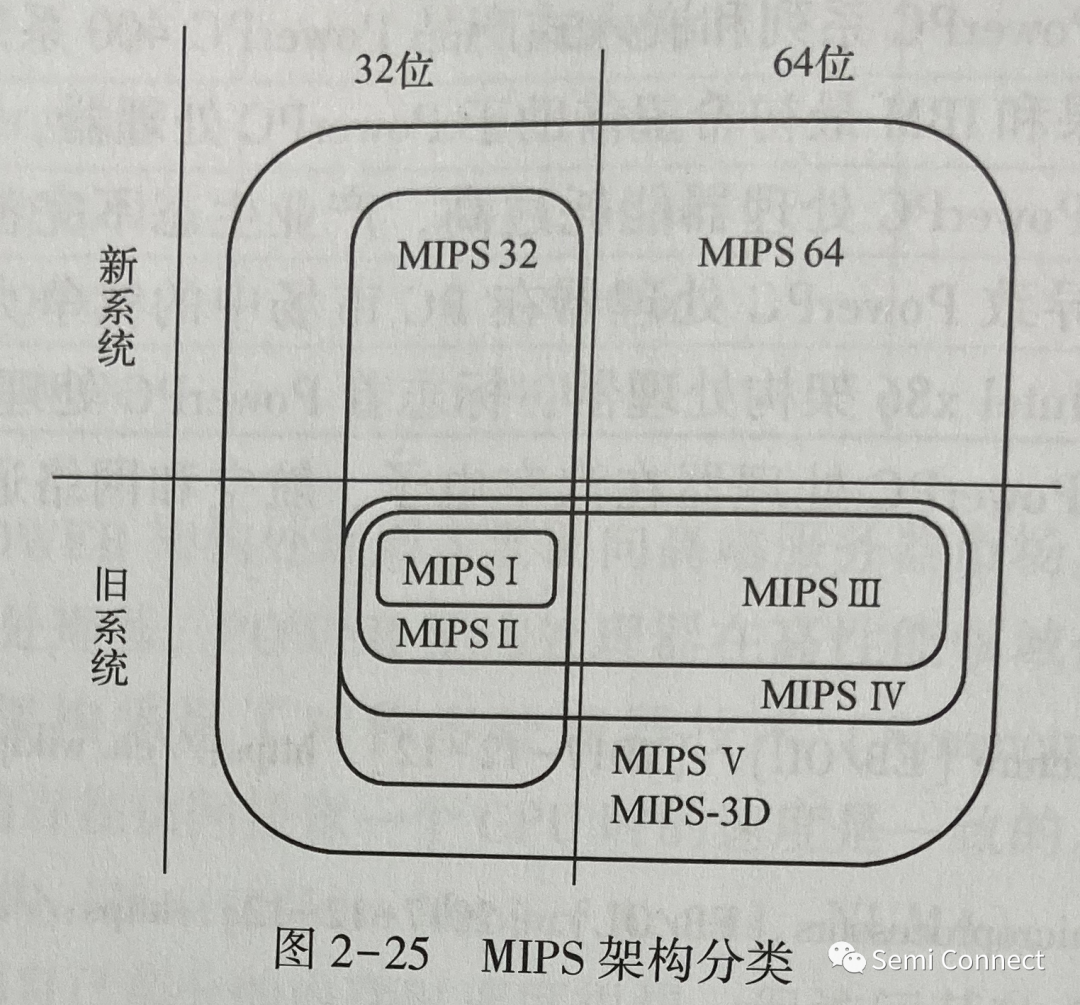
簡單認識MIPS架構處理器
簡單認識數字信號處理器







 工商網監
工商網監
評論