 燧原科技和芯礪智能發布Chiplet高效NPU聯合計算架構
燧原科技和芯礪智能發布Chiplet高效NPU聯合計算架構
近日,芯礪智能與燧原科技聯手推出了基于Chiplet定制化NPU的高效協同運算架構,這項成果顯著提升了多個精巧芯片(Chiplet)內眾多NPU運算單元之間的協同工作效率,有助于推動AI算力向著更高性能、更低成本以及更加易于擴展的趨勢邁進,有力地推動算力基礎設施的構建。
伴隨著AI大模型時代的來臨,全球算力需求呈現出旺盛增長態勢。在摩爾定律放緩背景下,傳統單一芯片模式已無法準確應對日益復雜多元的算法和應用需求。而高性能的Chiplet芯片作為解決此難題的關鍵方案正逐漸成為主流選擇。然而,如何使兩個及更多的算力單元達成至線性算力疊加的極致效果,始終是業界面臨的重大挑戰。
本次財經新聞中提到的燧原科技與芯礪智能的合作研發項目,是雙方團隊長期積累的技術碩果和緊密協作的產物。他們共同開發的這套全新NPU協同運算架構,建立在芯礪智能超低延遲(《5ns)的專利Chiplet D2D互連技術之上,成功填補了跨Die數據傳輸導致的性能損失。此外,結合芯礪智能獨特的模型切割及優化技術,實現在跨Die算力單元NPU上的復雜大型網絡部署,進而確保了高效的運算效率。
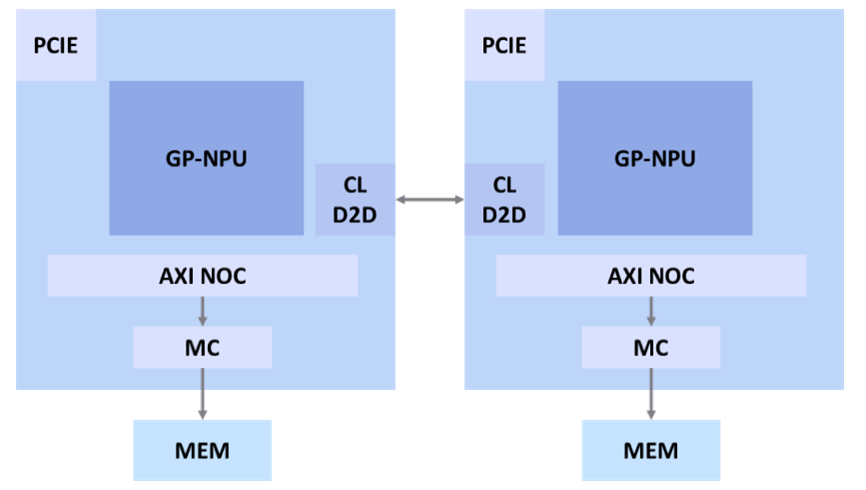
經過工程團隊在FPGA原型平臺上的反復測試驗證,他們發現Resnet50等常見算法在雙FPGA機組與單FPGA組相比,聯合運的效率提升達到驚人的1.936倍,基本達到預期的線性疊加效果。
對此,燧原科技首席運營官張亞林表示,基于Chiplet的NPU協同運算架構具有極高的實用價值,它是我們關注的重點方向之一,也是我們基于人工智能算力基礎設施建設的一次重大嘗試與突破。通過與芯礪智能的深度合作,我們成功展示了如何運用這種新的算力擴展方式來更好地適應超大規模數據中心對于性能與功能的持續提升需求。展望未來,我們期待能夠繼續深化與芯礪智能的合作關系,共同為中國算力底座的建設添磚加瓦。
尤其值得一提的是,芯礪智能首席執行官張宏宇透露,該公司推出的首款基于Chiplet的高效NPU協同運算架構為其Chiplet D2D互連IP技術的又一重要突破。他深感欣慰的是,本次與燧原科技攜手推出NPU協同運算架構,更進一步強化了兩家企業的戰略合作伙伴關系。未來,芯礪智能將繼續積極響應并配合燧原的算力普惠戰略,大力推進算力基礎設施的搭建進程。同時,這種新型的協同運算架構也表明,芯礪智能具備向邊緣端應用場景提供多種可擴展AI算力的堅實實力,進一步堅定了芯礪智能構建人工智能時代算力基礎設施,致力于提供人人共享可用算力的宏愿。
-
摩爾定律
+關注
關注
4文章
636瀏覽量
79197 -
chiplet
+關注
關注
6文章
434瀏覽量
12618 -
大模型
+關注
關注
2文章
2544瀏覽量
3055
發布評論請先 登錄
相關推薦
燧原科技聯合騰訊云入選“行業云平臺領航者典型案例”
勇芯科技智能戒指 Chiplet 新品發布會盛大召開,開啟智能穿戴新紀元

NPU的工作原理解析
NPU在邊緣計算中的優勢
NPU技術如何提升AI性能
RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測
IMEC組建汽車Chiplet聯盟

RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測
蘋芯科技發布AI革命新品,引領高效能計算新紀元
基于RK3588的NPU案例分享!6T是真的強!
英偉達聯合計算機制造商發布Blackwell架構系統
黑芝麻智能推出基于武當C1296芯片多域融合計算平臺方案






 工商網監
工商網監
評論