 放下你的PhotoShop!無限圖像編輯已開源!
放下你的PhotoShop!無限圖像編輯已開源!
0. 筆者個人體會
最近文本到圖像的工作很火,生成的圖像也非常真實。但還有個問題,現有工作效率比較低,往往只能接受一次text指令,再修改就要重新輸入text重新生成,可能會影響原本的語義信息,這樣導出的圖像和最初圖像可能差距甚遠。
今天筆者將為大家分享一項最新開源的工作LEDITS++,可以一次輸入無限多的編輯指令,一次性生成真實圖像!而且LEDITS++是無參數方案,不需要微調和優化。不得不感慨AI發展之迅速,距離人們真實生活也越來越近了。
下面一起來閱讀一下這項工作,文末附論文和代碼鏈接~
1. 效果展示
先看一下具體效果,輸入具體指令就可以直接產生對應效果。PS要想在幾十秒內達到同等效果應該是有點困難。

LEDITS++很強調編輯前后的圖像一致性,也就是僅修改圖像的相關區域,保持原始圖像的語義信息。這里也推薦工坊推出的新課程《徹底搞懂視覺-慣性SLAM:VINS-Fusion原理精講與源碼剖析》。

代碼已經開源了,官方主頁也開放了交互式demo,感興趣的讀者可以上傳自己的圖像和文本指令嘗鮮一下效果。
2. 具體原理是什么?
LEDITS++可以分為三個部分:(1)有效的圖像反轉;(3)多功能文本編輯;(3)圖像變化的語義基礎。
我們知道擴散模型生成圖像是通過反轉采樣來進行的,重點是識別噪聲。LEDITS++從DDPM反演中提取特征,并提出一種有效的反演方法,大大減少所需的步驟,同時降低重建誤差。當將反向擴散過程公式化為SDE時,DDPM可以被視為一階SDE解算器。使用高階微分方程解算器可以更有效地解算,因此作者推導出一種新的更快技術------DPM-solver++反演。

在創建重建序列之后,可以通過一組編輯指令操縱噪聲來編輯圖像。根據有條件和無條件估計,作者分別設計了一個專門的引導項,既反映了編輯的方向,又最大化了對所需編輯效果的細粒度控制。

最后,LEDITS++還包括一個Mask項,由交叉注意層生成的Mask和噪聲估計導出的Mask取交集計算得到。Mask可以捕捉與編輯概念相關的圖像區域,對于多次編輯特別有效。這里也推薦工坊推出的新課程《徹底搞懂視覺-慣性SLAM:VINS-Fusion原理精講與源碼剖析》。

3. 和其他SOTA方法對比如何?
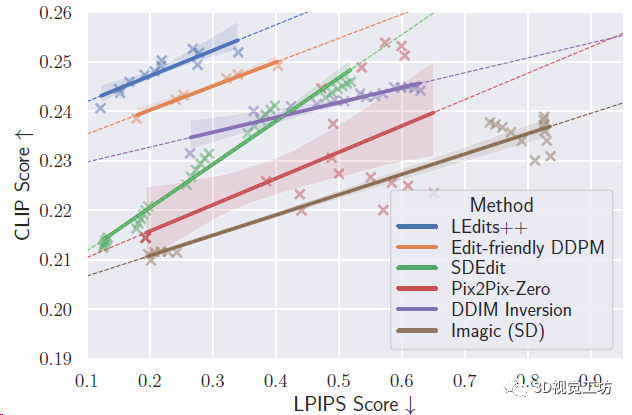
不同編輯方法的指令對齊和圖像相似度權衡的比較,側重CLIP得分(越高越好)與LPIPS相似度(越低越好),也就是圖中越靠近左上角效果越好。
-
圖像
+關注
關注
2文章
1084瀏覽量
40461 -
AI
+關注
關注
87文章
30887瀏覽量
269065 -
開源
+關注
關注
3文章
3348瀏覽量
42496
原文標題:放下你的PhotoShop!無限圖像編輯已開源!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
開源鴻蒙技術分論壇在武漢成功舉辦
與鴻同行,探索無限!開源鴻蒙技術分論壇在武漢成功舉辦

高倍金相自動測量顯微鏡無限遠光學系統

字節發布SeedEdit圖像編輯模型
圖像采集卡的接口類型有哪些?






 工商網監
工商網監
評論