") 三項SOTA!MasQCLIP:開放詞匯通用圖像分割新網絡
三項SOTA!MasQCLIP:開放詞匯通用圖像分割新網絡
1. 效果展示
MasQCLIP在開放詞匯實例分割、語義分割和全景分割三項任務上均實現了SOTA,漲點非常明顯。這里也推薦工坊推出的新課程《徹底搞懂視覺-慣性SLAM:VINS-Fusion原理精講與源碼剖析》。
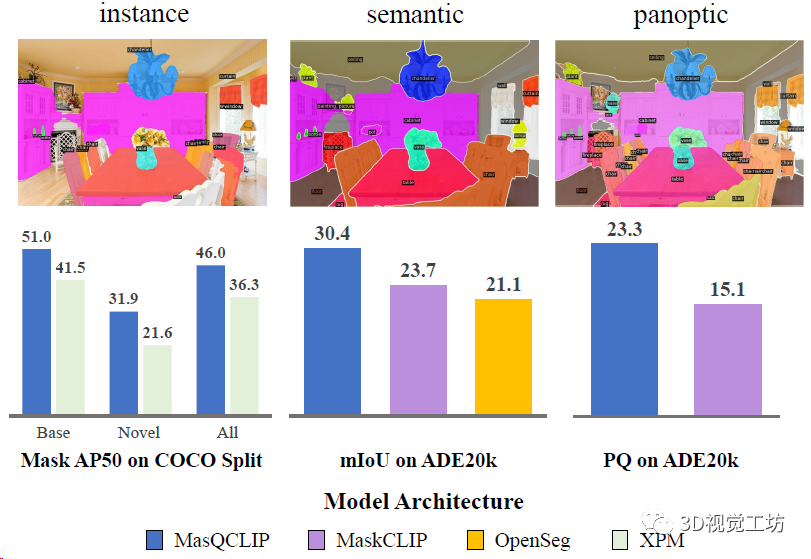
再來看看開放詞匯全景分割的定性效果,圖片來源于ADE20k,可以發(fā)現MasQCLIP分割出的Mask和類別精度更高。

2. 具體原理是什么?
先介紹一下基礎的CLIP模型:ICML-2021的工作,多模態(tài)視覺-語言模型代表。主要用來提取zero-shot目標的特征。核心思想是,很多模型需要預定義圖像類別,但是文本實際上就已經提供了未見類別的信息,融合文本就可以極大增強模型的泛化性。
而MasQCLIP的思想是,利用稠密特征與預訓練的CLIP模型無縫集成,從而避免訓練大規(guī)模參數。MasQCLIP在使用CLIP模型構建圖像分割時側重兩方面:
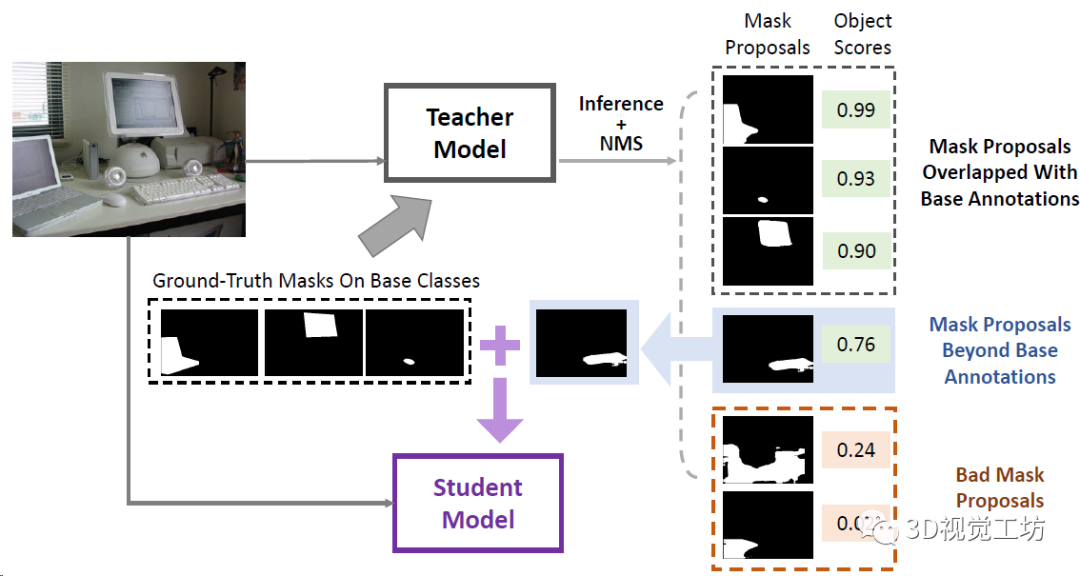
(1)學生-教師模塊,通過從基礎(已見)類中提取信息來處理新(未見)類的Mask;
(2)更新CLIP模型中查詢的模型參數的微調過程。
具體Pipeline是,MasQCLIP由類無關Mask提議網絡和基于CLIP的Mask分類模塊組成。在Mask提議網絡中,應用漸進蒸餾來分割基類之外的Mask。之后將預測的Mask送入分類模塊以獲得標簽。為了有效利用密集CLIP特征,還提出了MasQ-Tuning策略。
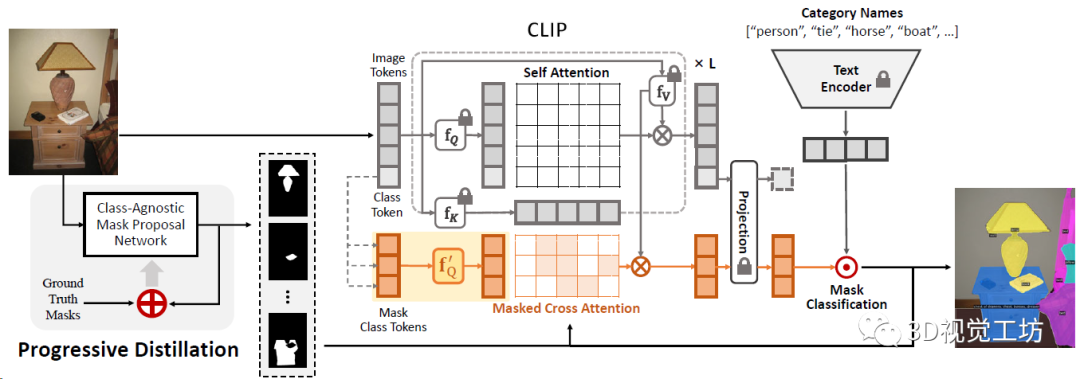
再來看看這個漸進蒸餾,就是從教師模型的分割圖中提取和基礎類別沒有重疊的Mask,用來做輔助訓練,將這些額外的標注蒸餾到學生模型中,然后不停的迭代循環(huán)來提高泛化性。
3. 再來看看效果如何
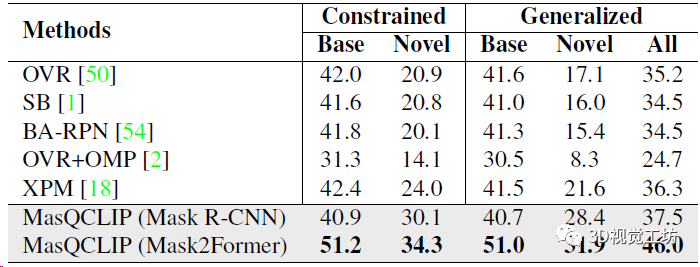
開放詞匯通用圖像分割的定量結果,直接對比了實例分割、語義分割、全景分割三個任務。三大任務漲點都非常明顯!
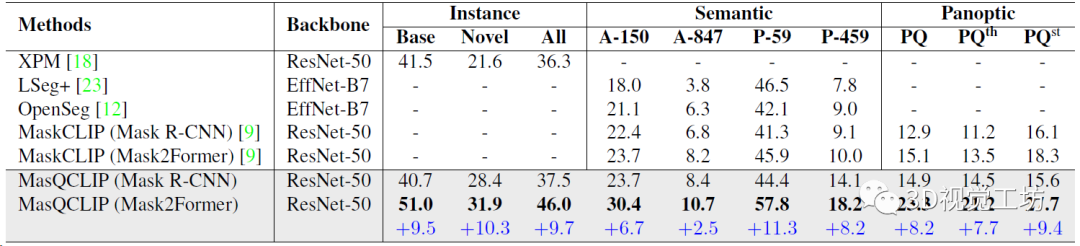
開放詞匯實例分割結果,分別對比基類和新類別的定量精度,展示了模型的泛化性。這里也推薦工坊推出的新課程《徹底搞懂視覺-慣性SLAM:VINS-Fusion原理精講與源碼剖析》。
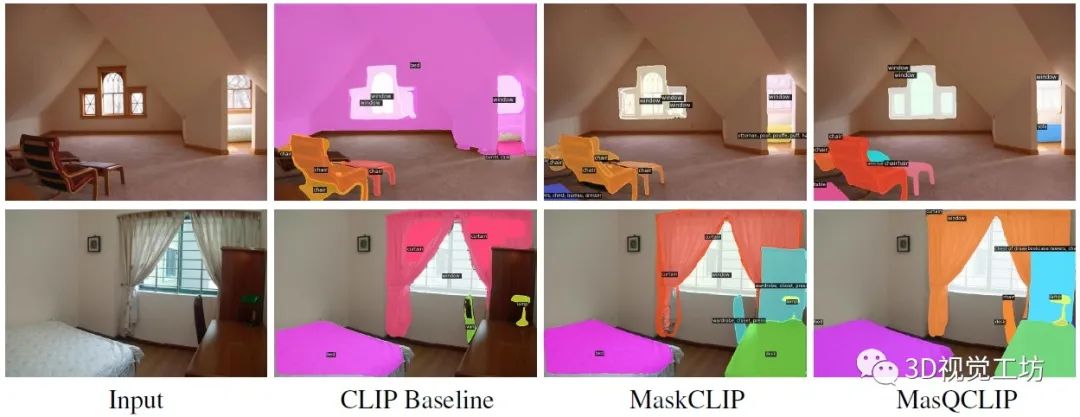
開放詞匯實例分割定性對比,可以發(fā)現MasQCLIP分割精度更高!
審核編輯:劉清
-
圖像分割
+關注
關注
4文章
182瀏覽量
18018 -
Clip
+關注
關注
0文章
31瀏覽量
6672
原文標題:北大&清華最新開源 | 三項SOTA!MasQCLIP:開放詞匯通用圖像分割新網絡
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
Mamba入局圖像復原,達成新SOTA





 工商網監(jiān)
工商網監(jiān)
評論