") 決策樹:技術(shù)全解與案例實(shí)戰(zhàn)
決策樹:技術(shù)全解與案例實(shí)戰(zhàn)
一、引言
決策樹算法是機(jī)器學(xué)習(xí)領(lǐng)域的基石之一,其強(qiáng)大的數(shù)據(jù)分割能力讓它在各種預(yù)測(cè)和分類問(wèn)題中扮演著重要的角色。從它的名字便能窺見(jiàn)其工作原理的直觀性:就像一棵樹一樣,從根到葉子的每一分叉都是一個(gè)決策節(jié)點(diǎn),指引數(shù)據(jù)點(diǎn)最終歸類到相應(yīng)的葉節(jié)點(diǎn),或者說(shuō)是最終的決策結(jié)果。
在現(xiàn)實(shí)世界中,決策樹的概念可以追溯到簡(jiǎn)單而普遍的決策過(guò)程。例如,醫(yī)生在診斷病人時(shí),會(huì)根據(jù)一系列的檢查結(jié)果來(lái)逐步縮小疾病的范圍,這個(gè)過(guò)程可以被視作一種決策樹的實(shí)際應(yīng)用。從癥狀到測(cè)試,每一個(gè)節(jié)點(diǎn)都是決策點(diǎn),攜帶著是否進(jìn)一步檢查或是得出診斷的決策。
在機(jī)器學(xué)習(xí)的世界里,這種決策過(guò)程被數(shù)學(xué)化和算法化。我們不再是用肉眼觀察,而是讓計(jì)算機(jī)通過(guò)算法模擬這一過(guò)程。舉個(gè)例子,電子郵件過(guò)濾器就是決策樹應(yīng)用的一個(gè)經(jīng)典案例。它通過(guò)學(xué)習(xí)識(shí)別垃圾郵件和非垃圾郵件的特征,比如關(guān)鍵詞的出現(xiàn)頻率、發(fā)件人信譽(yù)等,電子郵件過(guò)濾器能夠自動(dòng)地將郵件分類為“垃圾郵件”或“正常郵件”。
在更廣泛的機(jī)器學(xué)習(xí)應(yīng)用領(lǐng)域,決策樹可以處理各種各樣的數(shù)據(jù),不論是數(shù)字還是分類數(shù)據(jù),它都能以其獨(dú)到的方式進(jìn)行分析。例如,在金融領(lǐng)域,決策樹能夠幫助評(píng)估和預(yù)測(cè)貸款違約的可能性;在電子商務(wù)中,它可以用來(lái)預(yù)測(cè)用戶的購(gòu)買行為,甚至在更復(fù)雜的領(lǐng)域,比如生物信息學(xué)中,決策樹可以輔助從復(fù)雜的基因數(shù)據(jù)中發(fā)現(xiàn)疾病與特定基因之間的關(guān)聯(lián)。
通過(guò)引入機(jī)器學(xué)習(xí),我們讓決策樹這一概念超越了人類直覺(jué)的局限性,使它能處理遠(yuǎn)超人腦處理能力的數(shù)據(jù)量和復(fù)雜度。它們不僅能夠基于現(xiàn)有數(shù)據(jù)做出判斷,還能從數(shù)據(jù)中學(xué)習(xí),不斷優(yōu)化自身的決策規(guī)則,這是決策樹在現(xiàn)實(shí)世界中不可替代的意義。
決策樹之所以在機(jī)器學(xué)習(xí)中占有一席之地,還因?yàn)樗哪P涂山忉屝詮?qiáng),這在需要透明決策過(guò)程的領(lǐng)域尤為重要。與深度學(xué)習(xí)的黑盒模型相比,決策樹提供的決策路徑是清晰可追蹤的。每一次分支都基于數(shù)據(jù)特征的顯著性進(jìn)行選擇,這讓非專業(yè)人士也能夠理解模型的決策邏輯。
在本文中,我們將深入探討決策樹的核心技術(shù),從它的數(shù)學(xué)基礎(chǔ)到如何優(yōu)化算法以處理各類數(shù)據(jù)挑戰(zhàn),再到通過(guò)實(shí)際案例展示它們?nèi)绾谓鉀Q現(xiàn)實(shí)世界的問(wèn)題。我們將走進(jìn)決策樹的世界,了解這一技術(shù)如何在機(jī)器學(xué)習(xí)的眾多領(lǐng)域中發(fā)揮著它的重要作用。
二、決策樹基礎(chǔ)
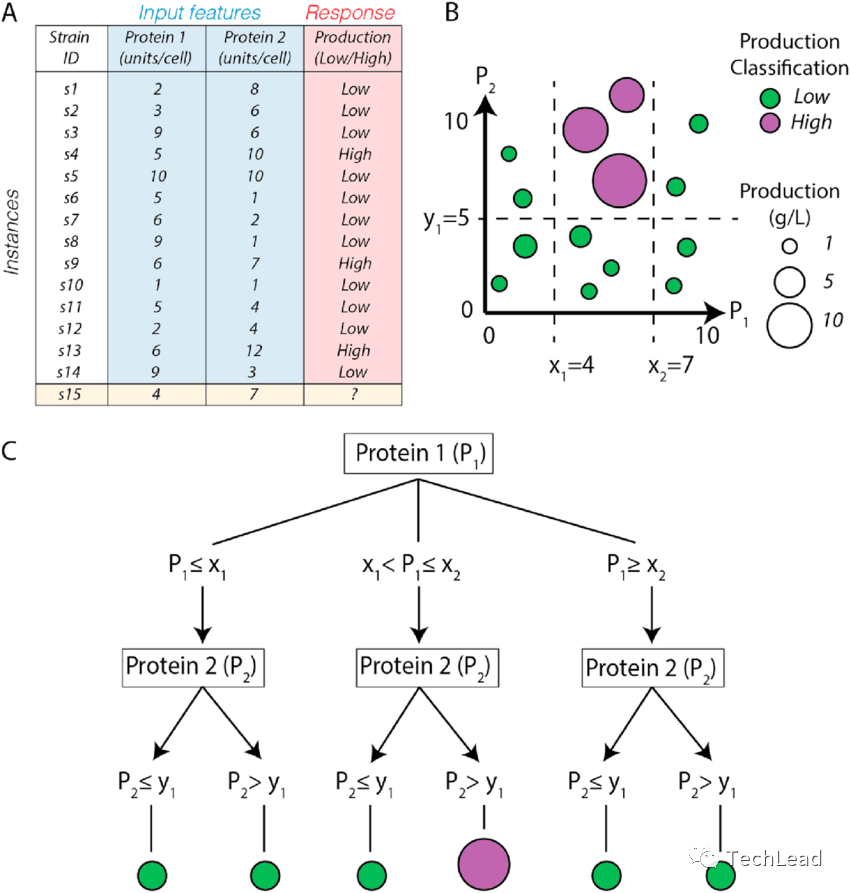
決策樹,作為一種符號(hào)學(xué)習(xí)方法,將復(fù)雜的決策規(guī)則轉(zhuǎn)化為一系列簡(jiǎn)單的比較問(wèn)題,從而對(duì)數(shù)據(jù)進(jìn)行分類或回歸。它們通過(guò)遞歸分裂訓(xùn)練數(shù)據(jù)集,構(gòu)建一個(gè)樹狀的模型。
決策樹模型概述
在決策樹中,每個(gè)內(nèi)部節(jié)點(diǎn)代表一個(gè)特征上的測(cè)試,每個(gè)分支代表測(cè)試的結(jié)果,而每個(gè)葉節(jié)點(diǎn)代表最終的決策結(jié)果。決策樹的構(gòu)建始于根節(jié)點(diǎn),包含整個(gè)訓(xùn)練集,通過(guò)分裂成子節(jié)點(diǎn)的過(guò)程,逐漸學(xué)習(xí)數(shù)據(jù)中的規(guī)律。
想象一下,我們面前有一籃水果,目的是區(qū)分蘋果和橘子。一棵決策樹可能首先詢問(wèn):“這個(gè)水果的顏色是紅色嗎?”如果答案是肯定的,它可能會(huì)將這個(gè)水果分類為蘋果;否則,它會(huì)繼續(xù)詢問(wèn):“這個(gè)水果的質(zhì)感是光滑的嗎?”這樣的一系列問(wèn)題最終導(dǎo)致分類的結(jié)果,這就是決策樹的工作方式。
構(gòu)建決策樹的關(guān)鍵概念
特征選擇
決策樹如何確定在每個(gè)節(jié)點(diǎn)上提出哪個(gè)問(wèn)題?這就涉及到一個(gè)關(guān)鍵的概念——特征選擇。特征選擇是決定用哪個(gè)特征來(lái)分裂節(jié)點(diǎn)的過(guò)程,它對(duì)決策樹的性能有著至關(guān)重要的影響。主要的特征選擇方法包括:
信息增益:度量分裂前后信息不確定性的減少,也就是說(shuō),它尋找能夠最好地清理數(shù)據(jù)的特征。
增益率:調(diào)整信息增益,解決偏向于選擇擁有大量值的特征的問(wèn)題。
基尼不純度:常用于CART算法,度量數(shù)據(jù)集的不純度,基尼不純度越小,數(shù)據(jù)集的純度越高。
假設(shè)我們要從一個(gè)包含蘋果和橘子的籃子中分類水果,信息增益會(huì)衡量按照顏色或按照質(zhì)地分裂數(shù)據(jù)所帶來(lái)的信息純度提升。如果顏色的信息增益更高,那么顏色就是該節(jié)點(diǎn)的最佳分裂特征。
決策樹的生成
樹的生成是通過(guò)遞歸分裂的方式進(jìn)行的。從根節(jié)點(diǎn)開始,使用特征選擇方法選擇最佳的分裂特征,創(chuàng)建分支,直到滿足某個(gè)停止條件,比如達(dá)到了設(shè)定的最大深度,或者節(jié)點(diǎn)中的樣本數(shù)量少于閾值。
舉一個(gè)現(xiàn)實(shí)生活中的例子,假如一個(gè)電信公司想要預(yù)測(cè)哪些客戶可能會(huì)流失。在構(gòu)建決策樹時(shí),它可能會(huì)首先考慮賬單金額,如果賬單金額大于平均值,那么進(jìn)一步考慮客戶的合同期限;如果合同期限短,那么客戶流失的可能性就更高。
決策樹的剪枝
為了防止過(guò)擬合——即模型對(duì)訓(xùn)練數(shù)據(jù)過(guò)于敏感,從而無(wú)法泛化到新的數(shù)據(jù)上——決策樹需要進(jìn)行剪枝。剪枝可以理解為對(duì)樹
進(jìn)行簡(jiǎn)化的過(guò)程,包括預(yù)剪枝和后剪枝。預(yù)剪枝意味著在樹完全生成之前停止樹的生長(zhǎng);后剪枝則是在樹生成之后去掉某些分支。
例如,在預(yù)測(cè)客戶流失的決策樹中,如果我們發(fā)現(xiàn)分裂后每個(gè)節(jié)點(diǎn)只包含極少量的客戶,那么這可能是一個(gè)過(guò)擬合的信號(hào)。通過(guò)預(yù)剪枝或后剪枝,我們可以移除這些僅對(duì)訓(xùn)練數(shù)據(jù)有特定判斷能力的規(guī)則。
決策樹的基礎(chǔ)原理既直觀又深邃。它將復(fù)雜的決策過(guò)程簡(jiǎn)化為易于理解的規(guī)則,并且通過(guò)學(xué)習(xí)數(shù)據(jù)中固有的模式,適用于各種機(jī)器學(xué)習(xí)任務(wù)。
三、算法研究進(jìn)階
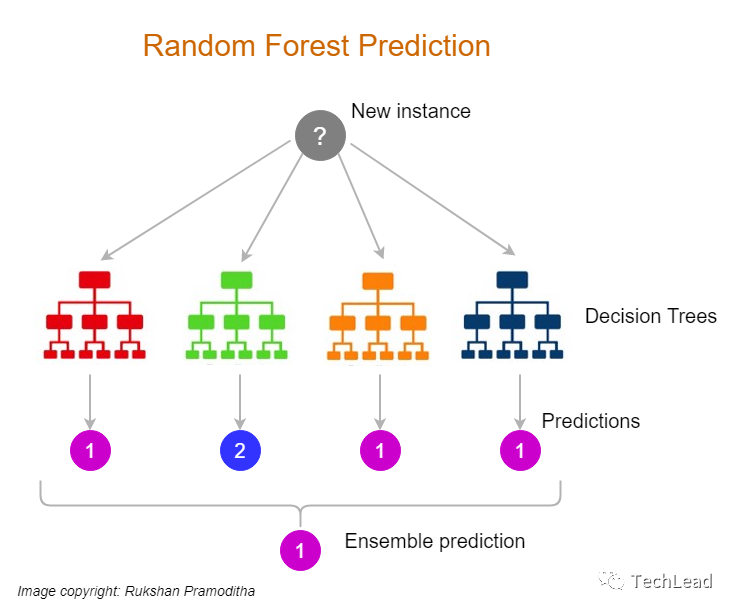
進(jìn)入到算法研究的進(jìn)階階段,我們將探討決策樹的深層次技術(shù)演進(jìn)和最新研究成果,以及如何將這些先進(jìn)的理念應(yīng)用于解決更復(fù)雜的問(wèn)題。
提升樹和隨機(jī)森林
決策樹的強(qiáng)大之處不僅在于它們單獨(dú)的決策能力,而且還在于它們可以組合成更強(qiáng)大的模型,如提升樹(Boosted Trees)和隨機(jī)森林(Random Forests)。
提升樹(Boosted Trees)
提升樹是通過(guò)結(jié)合多個(gè)弱決策樹構(gòu)建的,每一棵樹都試圖糾正前一棵樹的錯(cuò)誤。使用梯度提升(Gradient Boosting)的方法可以系統(tǒng)地將新模型添加到已經(jīng)存在的模型集合中,從而逐步提升模型的準(zhǔn)確率。
以預(yù)測(cè)房?jī)r(jià)為例,我們可能首先使用一個(gè)簡(jiǎn)單的決策樹來(lái)預(yù)測(cè)價(jià)格,然后第二棵樹會(huì)專注于第一棵樹預(yù)測(cè)錯(cuò)誤的部分,通過(guò)減少這些錯(cuò)誤來(lái)提升模型的性能,直到達(dá)到一定的準(zhǔn)確率或樹的數(shù)量。
隨機(jī)森林(Random Forests)
隨機(jī)森林通過(guò)創(chuàng)建多個(gè)獨(dú)立的決策樹,并讓它們對(duì)最終結(jié)果進(jìn)行投票,來(lái)提高決策樹的準(zhǔn)確性和魯棒性。每一棵樹都是在數(shù)據(jù)集的一個(gè)隨機(jī)子集上訓(xùn)練得到的,這種方法即提高了模型的泛化能力,也增加了結(jié)果的穩(wěn)定性。
設(shè)想一個(gè)信用評(píng)分的場(chǎng)景,單一決策樹可能會(huì)因?yàn)橛?xùn)練數(shù)據(jù)中的隨機(jī)波動(dòng)或噪聲而產(chǎn)生過(guò)度特定的規(guī)則。而隨機(jī)森林通過(guò)集成多個(gè)樹的決策來(lái)平均這些波動(dòng),生成更為穩(wěn)定和可靠的信用評(píng)分。
進(jìn)化算法與決策樹
研究人員還在探索如何使用進(jìn)化算法(Evolutionary Algorithms)來(lái)優(yōu)化決策樹的結(jié)構(gòu)和參數(shù)。進(jìn)化算法模擬生物進(jìn)化的過(guò)程,通過(guò)選擇、交叉和變異操作來(lái)優(yōu)化問(wèn)題的解。
決策樹結(jié)構(gòu)的進(jìn)化
在實(shí)踐中,可能會(huì)將決策樹的每一部分——分裂規(guī)則、特征選擇、甚至是剪枝策略——看作是個(gè)體的基因。通過(guò)定義適應(yīng)度函數(shù)來(lái)評(píng)估樹的性能,進(jìn)化算法會(huì)不斷迭代,選擇出性能最佳的樹進(jìn)行繁衍,從而得到更加優(yōu)化的決策樹結(jié)構(gòu)。
例如,在電子商務(wù)推薦系統(tǒng)中,我們可以利用進(jìn)化算法來(lái)不斷進(jìn)化決策樹的結(jié)構(gòu),以提高推薦的準(zhǔn)確性。不同的樹結(jié)構(gòu)被視為不同的“物種”,經(jīng)過(guò)迭代的“自然選擇”,最適應(yīng)用戶行為模式的決策樹結(jié)構(gòu)會(huì)被保留下來(lái)。
多目標(biāo)決策樹優(yōu)化
在某些復(fù)雜的機(jī)器學(xué)習(xí)任務(wù)中,我們不僅僅想要優(yōu)化單一的性能指標(biāo),如準(zhǔn)確度,我們還可能關(guān)心模型的可解釋性、速
度或是占用的內(nèi)存大小。多目標(biāo)優(yōu)化(Multi-Objective Optimization)技術(shù)能夠在這些不同的指標(biāo)之間找到最佳的平衡。
應(yīng)用實(shí)例:財(cái)務(wù)風(fēng)險(xiǎn)評(píng)估
在財(cái)務(wù)風(fēng)險(xiǎn)評(píng)估中,我們需要一個(gè)既準(zhǔn)確又快速的模型來(lái)實(shí)時(shí)分析交易的風(fēng)險(xiǎn)。通過(guò)多目標(biāo)優(yōu)化,我們可以設(shè)計(jì)出既能快速執(zhí)行又有著較高準(zhǔn)確度的決策樹模型,以適應(yīng)高頻交易環(huán)境的需求。
通過(guò)這一節(jié)的深入探討,我們看到了決策樹不僅僅是一個(gè)簡(jiǎn)單的分類或回歸工具,而是一個(gè)可擴(kuò)展的、能與其他算法相結(jié)合、并且能夠適應(yīng)復(fù)雜應(yīng)用需求的強(qiáng)大機(jī)器學(xué)習(xí)方法。
四、案例實(shí)戰(zhàn)
在本節(jié)中,我們將通過(guò)一個(gè)實(shí)戰(zhàn)案例來(lái)展示如何使用Python和PyTorch實(shí)現(xiàn)決策樹算法。我們將使用一個(gè)公開的銀行營(yíng)銷數(shù)據(jù)集,目標(biāo)是預(yù)測(cè)客戶是否會(huì)訂閱定期存款。這是一個(gè)典型的二分類問(wèn)題。
場(chǎng)景描述
假設(shè)我們是一家銀行,希望建立一個(gè)模型來(lái)預(yù)測(cè)哪些客戶更有可能訂閱定期存款。成功預(yù)測(cè)出這些客戶可以幫助銀行更精準(zhǔn)地進(jìn)行營(yíng)銷,提高資源利用效率。
數(shù)據(jù)預(yù)處理
在開始之前,我們需要進(jìn)行數(shù)據(jù)預(yù)處理,包括加載數(shù)據(jù)、清洗數(shù)據(jù)、進(jìn)行特征編碼等。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # 加載數(shù)據(jù) data = pd.read_csv('bank.csv', sep=';') # 數(shù)據(jù)預(yù)處理 # 將分類變量轉(zhuǎn)換為數(shù)值 labelencoder = LabelEncoder() data['job'] = labelencoder.fit_transform(data['job']) data['marital'] = labelencoder.fit_transform(data['marital']) # ...對(duì)其他分類變量進(jìn)行編碼 # 定義特征集和標(biāo)簽 X = data.iloc[:, :-1].values y = data.iloc[:, -1].values # 劃分訓(xùn)練集和測(cè)試集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
決策樹模型
下面,我們將使用DecisionTreeClassifier來(lái)訓(xùn)練模型,并對(duì)其進(jìn)行評(píng)估。
# 創(chuàng)建決策樹分類器實(shí)例 clf = DecisionTreeClassifier(criterion='entropy', random_state=42) # 訓(xùn)練模型 clf.fit(X_train, y_train) # 在測(cè)試集上進(jìn)行預(yù)測(cè) y_pred = clf.predict(X_test) # 評(píng)估模型 accuracy = accuracy_score(y_test, y_pred) print(f'模型準(zhǔn)確率: {accuracy:.2f}')
結(jié)果分析
這段代碼會(huì)輸出模型的準(zhǔn)確率,作為評(píng)估其性能的指標(biāo)。在現(xiàn)實(shí)應(yīng)用中,我們還會(huì)關(guān)注模型的召回率、精確率和F1分?jǐn)?shù),以及通過(guò)混淆矩陣來(lái)進(jìn)一步分析模型的性能。
在這個(gè)案例中,決策樹模型可以幫助銀行預(yù)測(cè)客戶是否會(huì)訂閱定期存款。通過(guò)準(zhǔn)確率的高低,我們可以了解到模型在解決實(shí)際問(wèn)題上的有效性。
輸出展示
輸出將直接顯示模型在測(cè)試數(shù)據(jù)上的準(zhǔn)確率,為銀行提供了一個(gè)量化的工具來(lái)判斷營(yíng)銷活動(dòng)的潛在效果。
實(shí)際操作中,模型的輸出還會(huì)進(jìn)一步轉(zhuǎn)換為決策支持,例如,通過(guò)模型預(yù)測(cè)的概率閾值來(lái)確定是否對(duì)某個(gè)客戶進(jìn)行營(yíng)銷活動(dòng)。
總結(jié)
通過(guò)這個(gè)案例,我們展示了如何使用Python實(shí)現(xiàn)一個(gè)簡(jiǎn)單的決策樹分類器,以及如何應(yīng)用它在實(shí)際的商業(yè)場(chǎng)景中進(jìn)行決策。這個(gè)實(shí)戰(zhàn)案例僅是決策樹應(yīng)用的冰山一角,決策樹的強(qiáng)大和靈活性使其在各種不同的領(lǐng)域都有廣泛的應(yīng)用。
五、總結(jié)
決策樹算法作為機(jī)器學(xué)習(xí)領(lǐng)域的基石之一,其直觀性和易于解釋的特性為其贏得了廣泛的應(yīng)用。本文從決策樹的基礎(chǔ)知識(shí)出發(fā),逐步深入到算法優(yōu)化、研究進(jìn)展,最終以一個(gè)實(shí)戰(zhàn)案例來(lái)集中展示其在實(shí)際問(wèn)題中的應(yīng)用。
在技術(shù)的深度和復(fù)雜性不斷提高的今天,決策樹算法仍然保持著其獨(dú)特的魅力。它能夠與新興的機(jī)器學(xué)習(xí)技術(shù)如深度學(xué)習(xí)、強(qiáng)化學(xué)習(xí)等相結(jié)合,創(chuàng)造出更為強(qiáng)大和適應(yīng)性強(qiáng)的模型。例如,通過(guò)集成學(xué)習(xí)中的隨機(jī)森林或提升方法,決策樹的預(yù)測(cè)性能得到了顯著提升,同時(shí)保留了模型的可解釋性。
決策樹的結(jié)構(gòu)使其成為理解數(shù)據(jù)屬性和做出預(yù)測(cè)決策的有力工具,尤其是在需要快速?zèng)Q策和解釋決策過(guò)程的場(chǎng)景中。這對(duì)于處在法規(guī)要求高透明度決策過(guò)程的行業(yè),如金融和醫(yī)療保健,尤為重要。
然而,決策樹算法并不是沒(méi)有挑戰(zhàn)。過(guò)擬合和處理高維數(shù)據(jù)時(shí)的效率問(wèn)題是其兩大主要的技術(shù)難題。盡管存在這些挑戰(zhàn),但隨著算法研究的不斷深入,例如引入剪枝技術(shù)、特征選擇和多目標(biāo)優(yōu)化等方法,我們有望設(shè)計(jì)出更為高效和魯棒的決策樹模型。
在案例實(shí)戰(zhàn)中,我們利用Python和PyTorch展示了如何具體實(shí)現(xiàn)和應(yīng)用決策樹,這樣的實(shí)操經(jīng)驗(yàn)對(duì)于理解算法的實(shí)際效果和限制至關(guān)重要。
最后,可以預(yù)見(jiàn),決策樹算法將繼續(xù)在人工智能的各個(gè)領(lǐng)域發(fā)揮其獨(dú)特的價(jià)值。其簡(jiǎn)單、高效和易于解釋的特點(diǎn),將使其在可解釋的AI(XAI)領(lǐng)域發(fā)揮重要作用,助力人類構(gòu)建更加公正、透明和可信的機(jī)器學(xué)習(xí)系統(tǒng)。
審核編輯:劉清
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8418瀏覽量
132646 -
python
+關(guān)注
關(guān)注
56文章
4797瀏覽量
84690 -
決策樹
+關(guān)注
關(guān)注
3文章
96瀏覽量
13552 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13226
原文標(biāo)題:機(jī)器學(xué)習(xí) - 決策樹:技術(shù)全解與案例實(shí)戰(zhàn)
文章出處:【微信號(hào):OSC開源社區(qū),微信公眾號(hào):OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
關(guān)于決策樹,這些知識(shí)點(diǎn)不可錯(cuò)過(guò)
決策樹的生成資料
一個(gè)基于粗集的決策樹規(guī)則提取算法
改進(jìn)決策樹算法的應(yīng)用研究
決策樹的原理和決策樹構(gòu)建的準(zhǔn)備工作,機(jī)器學(xué)習(xí)決策樹的原理
決策樹和隨機(jī)森林模型
決策樹的構(gòu)成要素及算法
決策樹的基本概念/學(xué)習(xí)步驟/算法/優(yōu)缺點(diǎn)
什么是決策樹模型,決策樹模型的繪制方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論