 如何幫助提高CPU分支跳轉的正確率
如何幫助提高CPU分支跳轉的正確率
我們還是先看一個例子:
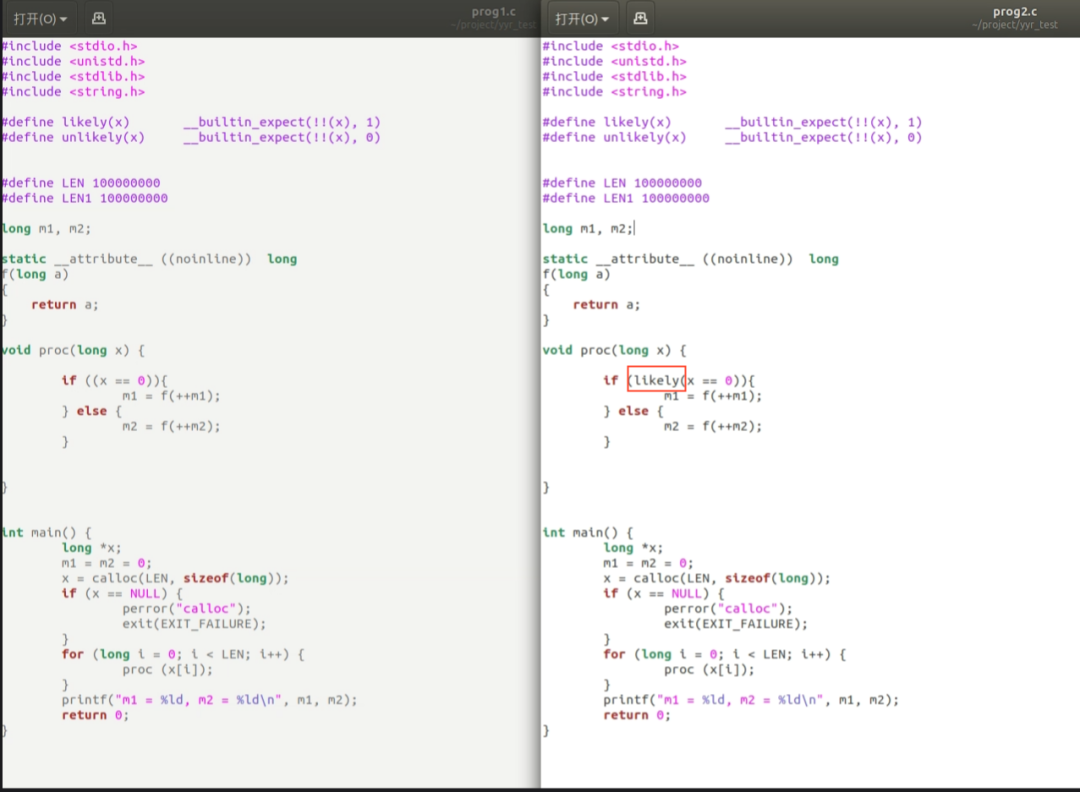
看上面的兩個函數,它們都是calloc一個全零數組x(這里不能直接用數組賦值,否則編譯器會足夠聰明進行自動的優化),遍歷x中的每個數,如果等于0,執行分支A,否則執行分支B。
唯一的不同就是在分支判斷的時候,prog2.c加了likely。我們先看下實際的結果如何:

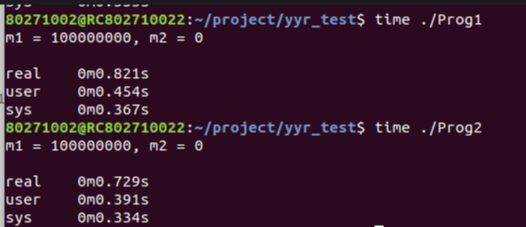
可以看出,加了likely的prog2,明顯用時變短。原因何在?
為了理解上面的例子,我們先介紹CPU流水線相關知識:
3.1. CPU流水線簡介
CPU流水線是一種使用多級緩存來提高處理器性能的技術。它是指將CPU操作分為多個階段,每個階段單獨完成一個操作,然后將結果傳遞給下一個階段,以此類推。每個階段都有一個獨立的部件,并且所有部件都能同時處理不同的指令。現代CPU都會采用這種技術來提高CPU的運行效率。
CPU流水線通常包括以下五個階段:
1)取指令(Instruction fetch):從存儲器中讀取指令。
2)指令譯碼(Instruction decode):將指令轉換為可執行的指令。
3)執行指令(Instruction execute):執行指令的操作。
4)寫回(Write back):將執行指令得到的結果寫回內存中。
5)更新程序計數器(Update program counter):將程序計數器加1,使它指向下一個指令。
舉個簡單的例子:
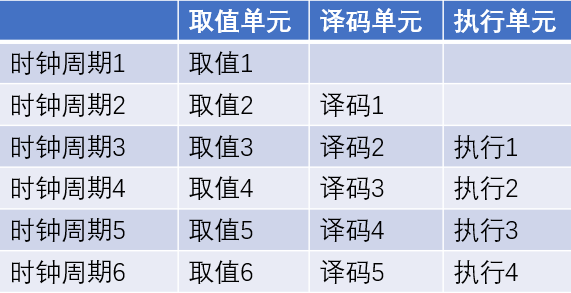
我們假設每一個步驟執行時間都是一個時鐘周期,那么一條指令執行需要3個時鐘周期

CPU 執行指令的3個時鐘周期里,取值單元只在第一個時鐘周期里工作,其余兩個時鐘周期都處于空閑狀態,其它兩個執行單元也是如此,效率太低了。
解決方法就是引入流水線,引入流水線工作模式后可以看到,除了剛開始第一個時鐘周期大家還可以偷懶外,其余的時間都不會閑著
CPU流水線的優點是可以同時執行多個指令,從而提高了處理器的效率。但它也存在一些問題,例如數據相關性(Data dependency)和控制相關性(Control dependency),這些問題可能導致流水線停滯,降低CPU的性能。
執行的程序指令如果是順序結構,沒有中斷或跳轉,流水線確實可以提高執行效率。但是當程序指令中存在跳轉、分支結構時,下面預取的指令可能就要全部丟掉了,需要到要跳轉的地方重新取指令執行。一般來說分支預測錯誤的處罰大約是19個時鐘周期。(具體計算方法這里不做詳細介紹了)。
我們看下前面提到的例子匯編出來的結果:
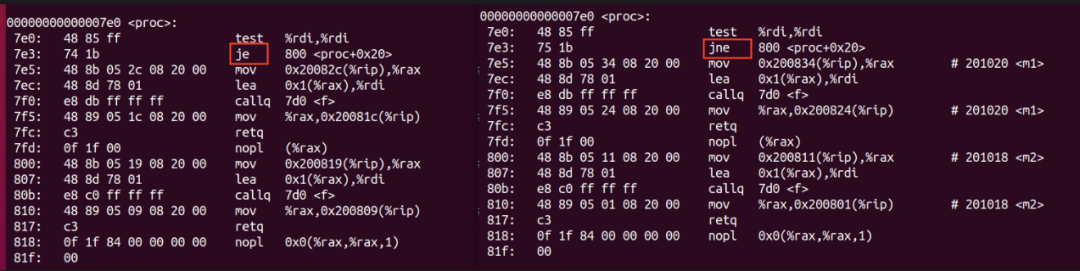
prog2,這里匯編是”jne”,意思是如果判斷結果不為0,就跳轉到地址 800的地方執行。我們知道這里的判斷一直是0。所以,cpu指令順序向下執行,并不會發生預判錯誤,預取的指令也不會丟棄。這樣就不會遭到分支預測錯誤的懲罰,效率會提高。
所以有些情況下,當我們根據實際的情況可以判斷出哪條分支的可能性更高的時候,我們就可以站在上帝視角給予一定的提示,這樣就可以降低分支預測錯誤,減少CPU的無用功了,從而可以有效的提高性能,同時也節省了功耗。
-
cpu
+關注
關注
68文章
10879瀏覽量
212201 -
代碼
+關注
關注
30文章
4802瀏覽量
68745
發布評論請先 登錄
相關推薦
CPU分支預測對程序的影響
提高繼電保護動作正確率的策略
labview如何立即退出當前事件分支
優化技巧:提前if判斷幫助CPU分支預測
怎樣去正確的配置CAN協議的波特率
使用智能外設提高CPU效率

Thumb指令集之Thumb跳轉指令

搜狗推“唇語識別”正確率達90%
ARM嵌入式系統的中斷服務例程跳轉
如何使用蝙蝠優化算法的網絡入侵檢測模型提高入侵檢測的正確率
GPU和CPU芯片的區別
如何才能解決圖像匹配算法的光照變化敏感和匹配正確率低的問題
cpu和gpu的結構區別





 工商網監
工商網監
評論