 AI時代,你需要了解的GPU互聯技術:NVLink、IB、ROCE
AI時代,你需要了解的GPU互聯技術:NVLink、IB、ROCE
AI 時代 GPU 成為核心處理器,分布式訓練訴求提升。GPU 采用并行計算方式,擅長處理大量、簡單的運算,因此多適用于圖像圖形處理和 AI 推理。但是大模型復雜度日益提升,單卡 GPU 顯存有限,無法滿足訓練需求,比如百度文心一言大模型有 2600 億個參數,但是實際上一個 80G 顯存的 A800,算上訓練中間的計算狀態,只能存放 10-20 億參數,存放 2600 億的模型就需要 100-200 塊 GPU;此外,后續大模型訓練需要更多參數和更多計算,由此產生的 GPU 需求更為龐大。為適應算力需求,需要聯合多張 GPU 甚至多臺服務器協同工作,分布式訓練成為核心訓練方式。
網絡連接在分布式系統中擔任重要角色。網絡在分布式系統中提供了連接作用,可以根據連接層級區分為單卡、多卡、多機互聯,單卡內的網絡為計算用的神經網,多卡之間的連接(即 GPU 互聯)通常采用 PCIe 或各種高帶寬通信網絡,多機之間的連接(即服務器互聯)通常采用 RDMA 網絡。
總線是數據通信必備管道,PCIe 是最泛使用的總線協議。總線是服務器主板上不同硬件互相進行數據通信的管道,對數據傳輸速度起到決定性作用,目前最普及的總線協議為英特爾 2001 年提出的 PCIe(PCI-Express)協議,PCIe 主要用于連接 CPU 與其他高速設備如 GPU、SSD、網卡、顯卡等,2003 年 PCIe1.0 版本發布,后續大致每過三年會更新一代,目前已經更新到6.0版本,傳輸速率高達64GT/s,16通道的帶寬達到256GB/s,性能和可擴展性不斷提高。
PCIe 總線樹形拓撲和端到端傳輸方式限制了連接數量和速度,PCIe Switch 誕生。PCIe采用端對端數據傳輸鏈路,PCIe 鏈路的兩端只能各接入一個設備,設備識別數量有限,無法滿足有大量設備連接或需要高速數據傳輸的場景,因此 PCIe Switch 誕生。PCIe Switch 具備連接和交換雙重功能,可以讓一個 PCIe 端口識別和連接更多設備,解決通道數量不夠的問題,并可以將多條 PCIe 總線連接在一起,從而形成一個高速網絡,實現多設備通信,簡言之 PCIe Switch 相當于 PCIe 的拓展器。
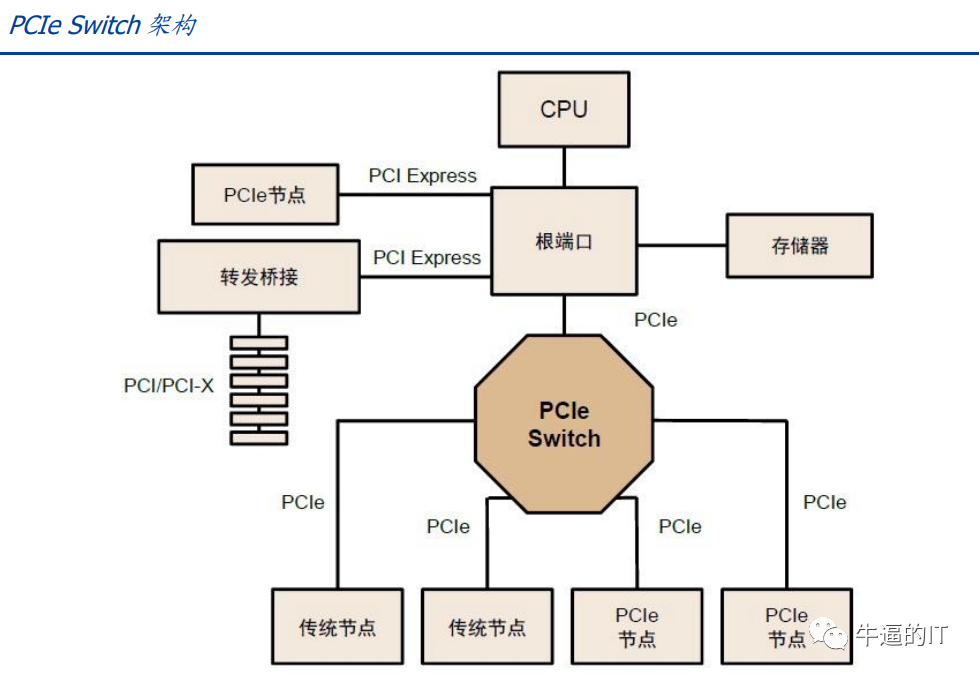
GPU 互 聯 時 代 , PCIe 傳 輸 速 率 和 網 絡 延 遲 無 法 滿 足 需 求 ,NVLINK、CAPI、GenZ、CCIX、CXL 等“百家爭鳴”時代開啟。AIGC 的發展極大刺激算力需求的增加,GPU 多卡組合成為趨勢,GPU 互聯的帶寬通常需要在數百 GB/S以上,PCIe 的數據傳輸速率成為瓶頸,鏈路接口的串并轉換會網絡延時,影響 GPU 并行計算效率,還由于 GPU 發出的信號需要先傳遞到 PCIe Switch,PCIe Switch 涉及到數據的處理又會造成額外的網絡延時,此外 PCIe 總線與存儲器地址分離,每次訪問內存會加重網絡延遲,因此 PCIe 協議在 GPU 多卡通信中效率并不高。為了將總線通信效率提升,降低延時,各家紛紛推出替代協議:
CAPI 協議:由 IBM 最早推出,后逐漸演化成 Open CAPI,本質是現有高速 I/O 標準之上的應用程序擴展,添加了緩存一致性和更低延遲等內容,但由于 IBM 服務器份額的持續下降,CAPI 協議缺少用戶基礎,最終未能廣泛流傳。
GenZ 協議:GenZ 是不依賴于任何芯片平臺的開放性組織,眾多廠家參與其中包括AMD、ARM、IBM、Nvidia、Xilinx 等,GenZ 將總線協議拓展成交換式網絡并加入GenZSwitch 提高了拓展性。
CXL 協議(陸續兼并上述兩個協議):2019 年由 Intel 推出,與 CAPI 協議思路類似,2021 年底吸收 GenZ 協議共同發展,2022 年兼并 Open CAPI 協議,CXL 具備內存接口,逐漸成長為設備互連標準的重要主導協議之一。
CCIX 協議:ARM 加入的另一個開放協議,功能類似 GenZ 但未被吸收兼并。
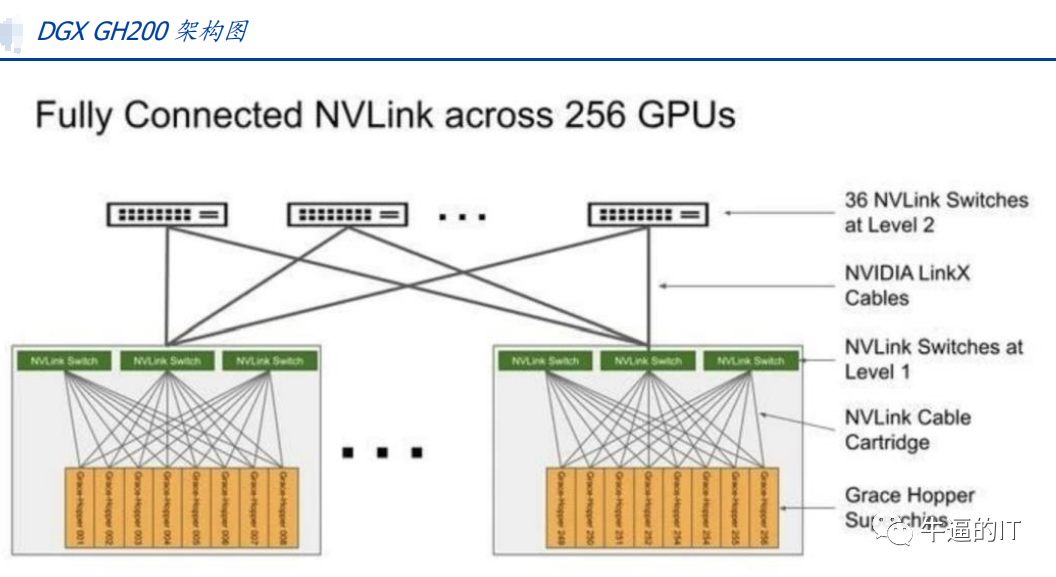
NVLINK 協議:英偉達提出的高速 GPU 互聯協議,對比傳統 PCIe 總線協議,NVLINK主要在三個方面做出較大改變:1)支持網狀拓撲目,解決通道有限問題;2)統一內存,允許 GPU 共享公共內存池,減少 GPU 之間復制數據的需要,從而提高效率;3)直接內存訪問,不需要 CPU 參與,GPU 可直接讀取彼此的內存,從而降低網絡延遲。此外,為解決 GPU 之間通訊不均衡問題,英偉達還引入 NVSwitch,一種類似交換機 ASIC 的物理芯片,通過 NVLink 接口將多個 GPU 高速互聯,創建高帶寬多節點 GPU 集群。2023 年 5 月 29 日,英偉達推出 AI 超級計算機 DGX GH200,通過 NVLink 和 NVSwitch 連接 256 個 GH200 芯片,所有 GPU 連接成一個整體協同運行,可訪問內存突破 100TB。
多機互聯:IB 網絡與以太網絡并存
分布式訓練下 RDMA 網絡成為最佳選擇,包含 IB 網絡和以太網絡。傳統的 TCP/IP 網絡通信是通過內核發送消息,涉及較多數據移動和數據復制,不適用高性能計算、大數據分析等需要 IO 高并發、低時延的場景。RDMA 是一種計算機網絡技術,可以直接遠程訪問內存數據,無需操作系統內核介入,不占用 CPU 資源,可以顯著提高數據傳輸的性能并且降低延遲,因此更適配于大規模并行計算機集群的網絡需求。目前有三種 RDMA:Infiniband、RoCE、iWARP,后兩者是基于以太網的技術:
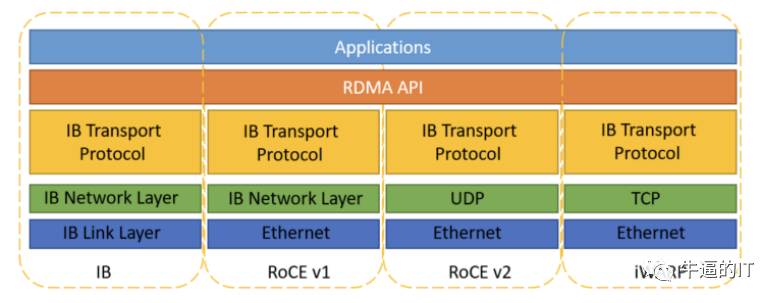
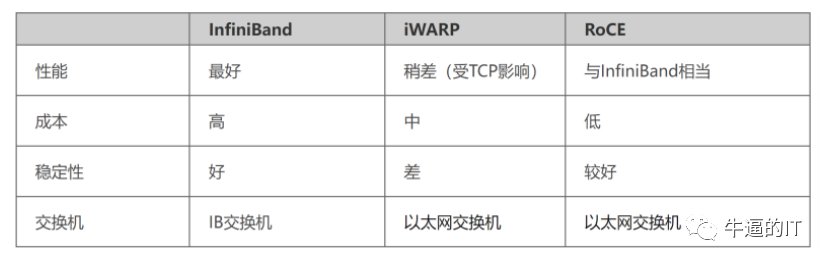
Infiniband:是專為 RDMA 設計的網絡,從硬件級別保證可靠傳輸,具備更高的帶寬和更低的時延。但是成本高,需要配套 IB 網卡和 IB 交換機。
RoCE:基于以太網做 RDMA,可以使用普通的以太網交換機,成本較低,但是需要支持 RoCE 的網卡。
iWARP:基于 TCP 的 RDMA 網絡,利用 TCP 達到可靠傳輸。相比 RoCE,在大型組網的情況下,iWARP 的大量 TCP 連接會占用大量的內存資源,對系統規格要求更高。可以使用普通的以太網交換機,但是需要支持 iWARP 的網卡。
-
數據傳輸
+關注
關注
9文章
1919瀏覽量
64673 -
gpu
+關注
關注
28文章
4752瀏覽量
129055 -
AI
+關注
關注
87文章
31097瀏覽量
269429
原文標題:AI時代,你需要了解的GPU互聯技術:NVLink、IB、ROCE
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
GPU集群組網技術詳解
AI訓練,為什么需要GPU?

RoCE與IB對比分析(一):協議棧層級篇
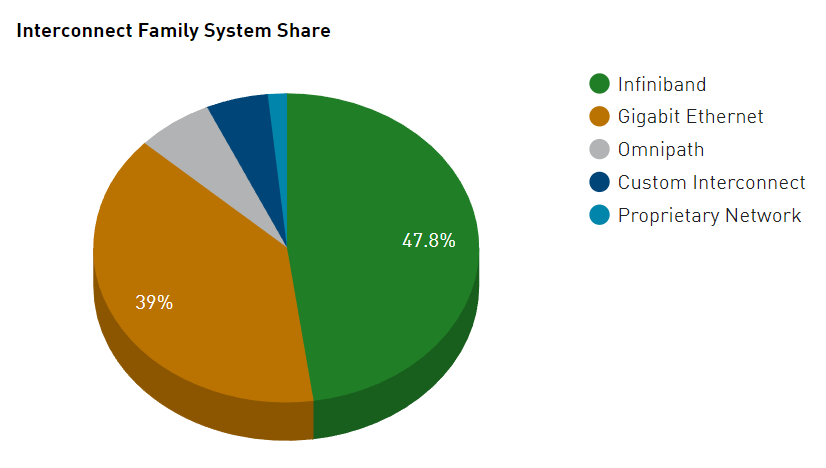
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
吳霽虹:AI時代,你是否會變成「數據奴隸」?
特斯拉V100 Nvlink是否支持v100卡的nvlink變種的GPU直通?
為什么要了解電機的工作原理
英偉達GPU卡多卡互聯NVLink,系統累積的公差,是怎么解決的?是連接器吸收的?
你需要了解的嵌入式Linux

NVLink的演進:從內部互聯到超級網絡

全面解讀英偉達NVLink技術

RoCE與IB對比分析(二):功能應用篇





 工商網監
工商網監
評論