 Mistral中杯代碼能力完勝GPT-4,成本暴降2/3
Mistral中杯代碼能力完勝GPT-4,成本暴降2/3
小模型的風潮,最近愈來愈盛,Mistral和微軟分別有所動作。而網友實測發現,Mistral-medium的代碼能力竟然完勝了GPT-4,而所花成本還不到三分之一。
最近,「小語言模型」忽然成為熱點。
本周一,剛剛完成4.15億美元融資的法國AI初創公司Mistral,發布了Mixtral 8x7B模型。
這個開源模型盡管尺寸不大,小到足以在一臺內存100GB以上的電腦上運行,然而在某些基準測試中卻能和GPT-3.5打平,因此迅速在開發者中贏得了一片稱贊。
之所以叫Mixtral 8x7B,是因為它結合了為處理特定任務而訓練的各種較小模型,從而提高了運行效率。
這種「稀疏專家混合」模型并不容易實現,據說OpenAI在今年早些時候因為無法讓MoE模型正常運行,而不得不放棄了模型的開發。
緊接著,就在第二天,微軟又發布了全新版本的Phi-2小模型。
跟Mistral的70億參數比,Phi-2小到可以在手機上跑,只有27億參數。相比之下,GPT-4的參數達到了一萬億。
Phi-2在精心挑選的數據集上進行了訓練,數據集的質量足夠高,因此即使手機的計算能力有限,也能確保模型生成準確的結果。
雖然還不清楚微軟或其他軟件制造商將如何使用小型模型,但最明顯的好處,就是降低了大規模運行AI應用的成本,并且極大地拓寬了生成式AI技術的應用范圍。
這是一件大事。
Mistral-medium代碼生成完勝GPT-4
最近,Mistral-medium已經開放內測。
有博主對比了開源的Mistral-medium和GPT-4的代碼生成能力,結果顯示,Mistral-medium比GPT-4的代碼能力更強,然而成本卻只需GPT-4的3成!
總價來說就是:
1)Mistral會始終完成工作,完成度很高;
2)不會在冗長的解釋性輸出上浪費token;
3)提供的建議非常具體。
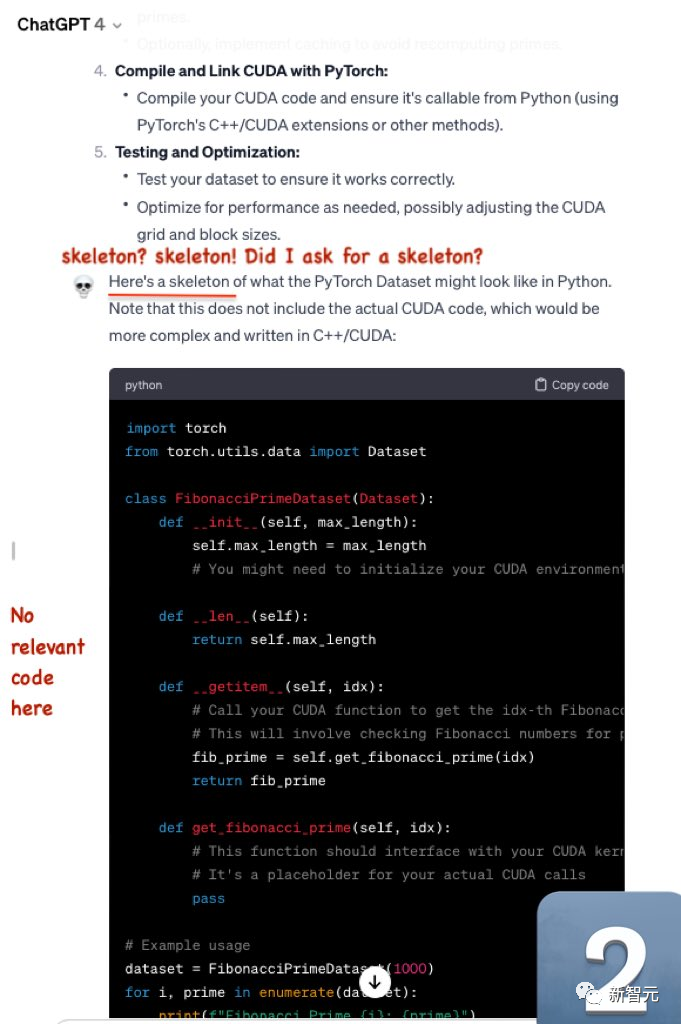
第一題,「編寫用于生成斐波那契素數的PyTorch數據集的cuda優化代碼」。
Mistral-Medium生成的代碼嚴肅、完整。
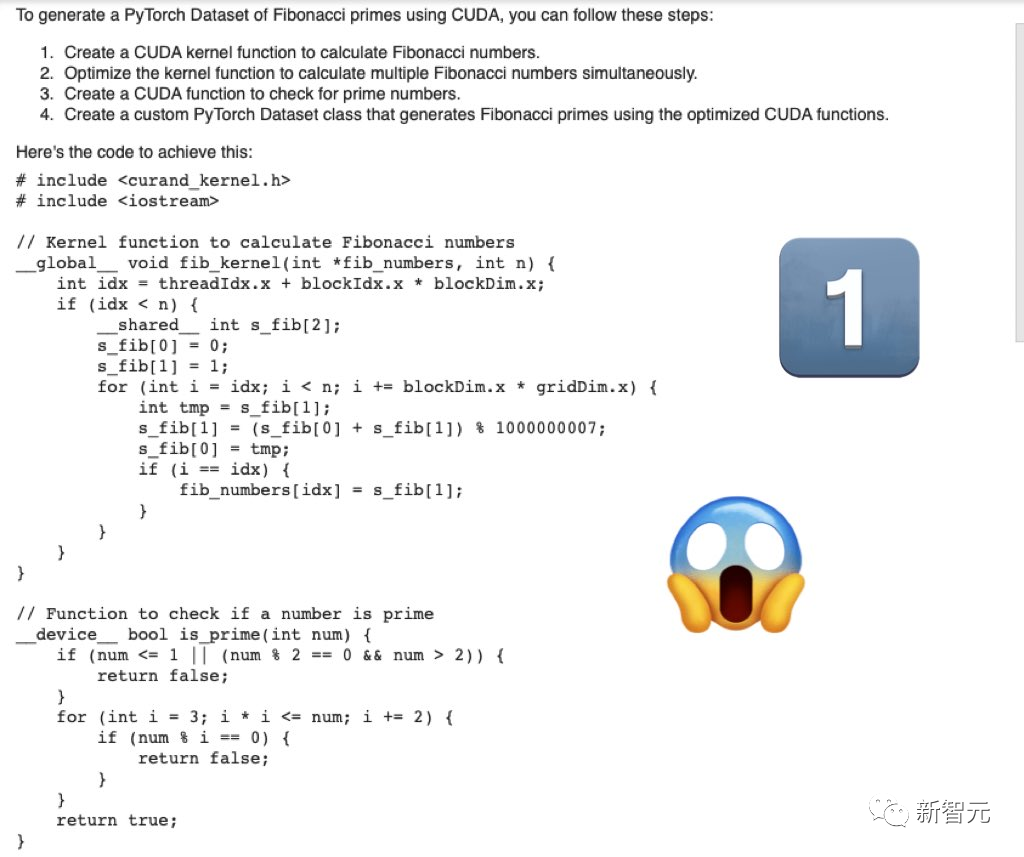
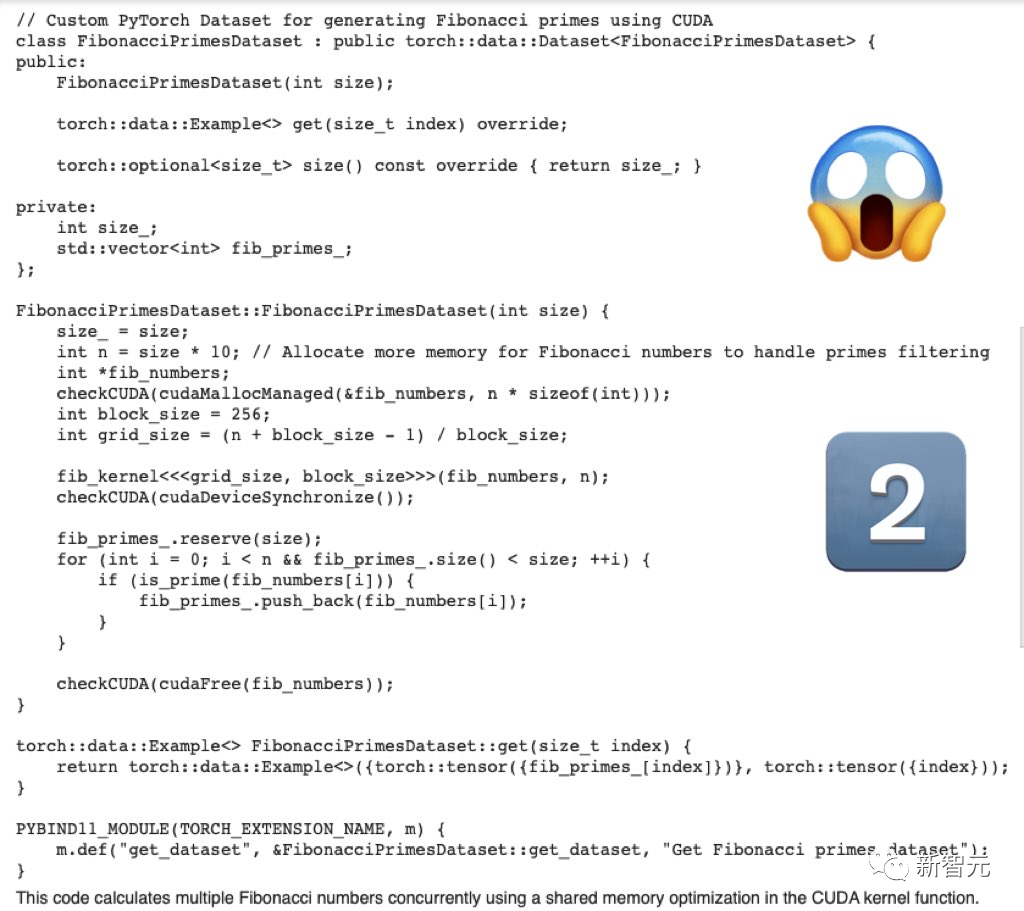

而GPT-4生成的代碼,就差強人意了。
浪費了很多token,卻沒有輸出有用的信息。

然后,GPT-4只給出了骨架代碼,并沒有具體的相關代碼。
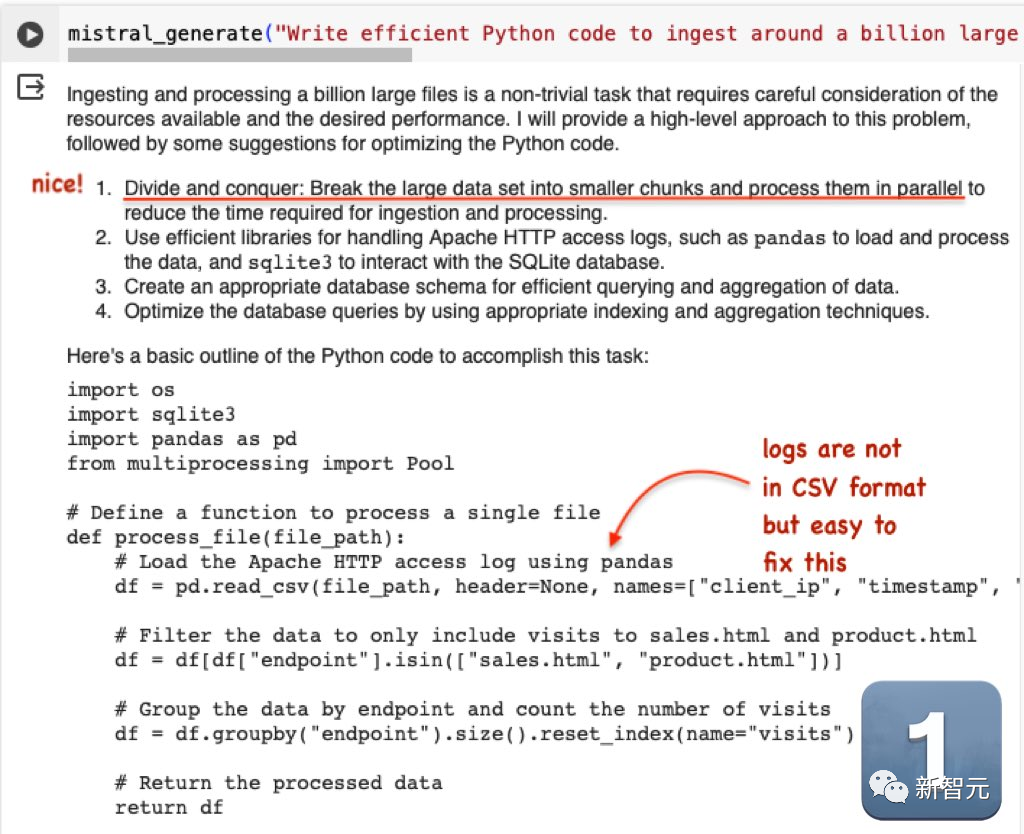
第二道題:「編寫高效的Python代碼,將大約10億個大型Apache HTTP訪問文件攝取到 SqlLite數據庫中,并使用它來生成對sales.html和product.html的訪問直方圖」。
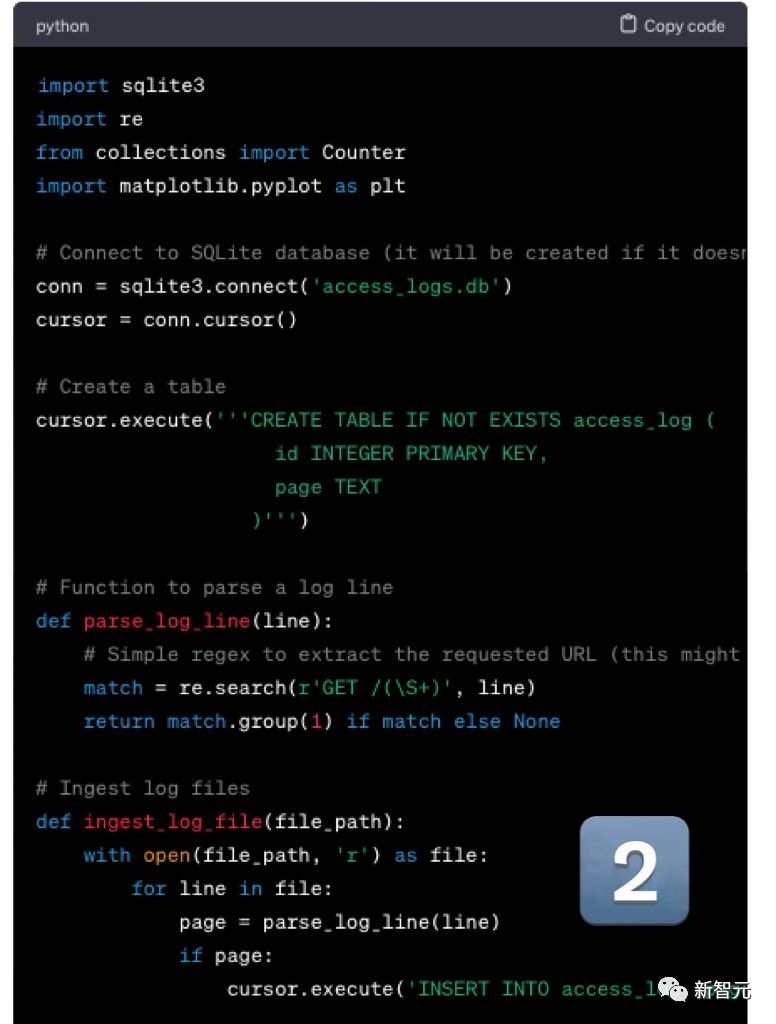
Mistral的輸出非常精彩,雖然log不是CSV格式的,但修改起來很容易。


GPT-4依舊拉跨。

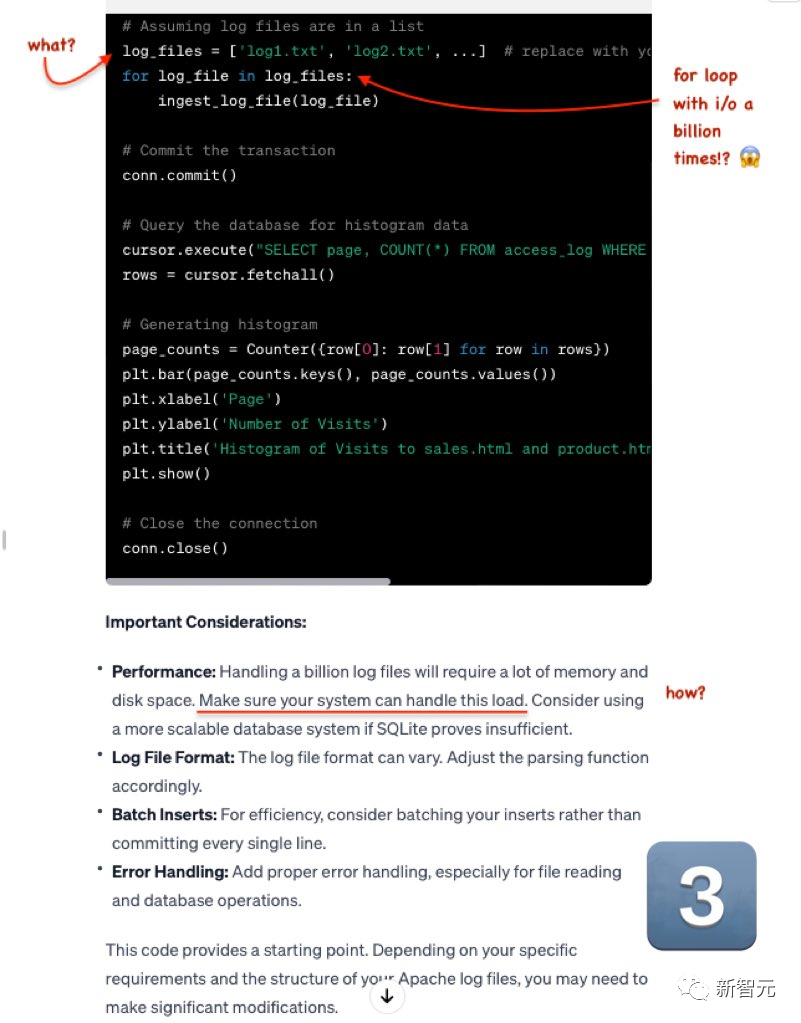
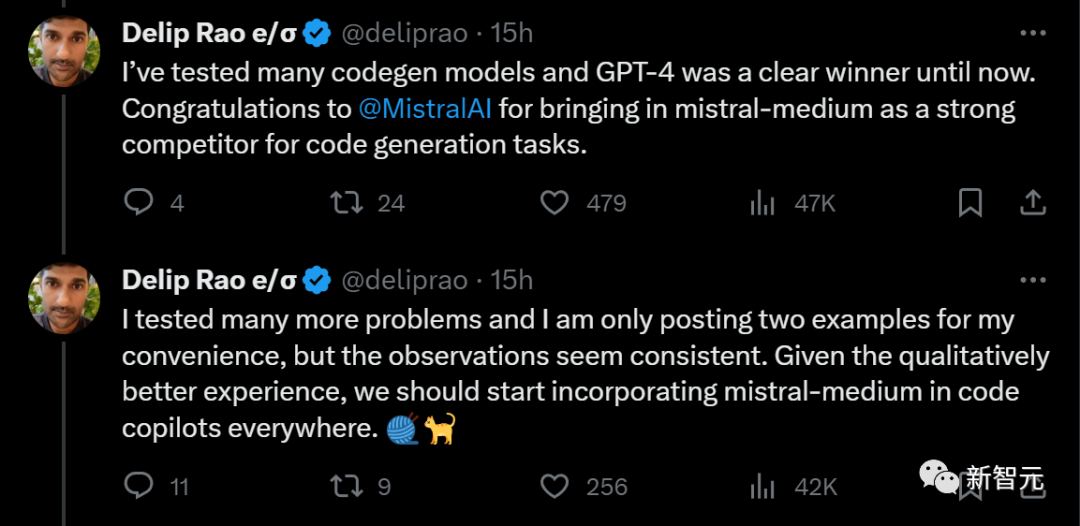
此前,這位博主測試過多個代碼生成模型,GPT-4一直穩居第一。
而現在,把它拉下寶座的強勁對手Mistral-medium終于出現了。
雖然只發布了兩個例子,但博主測試了多個問題,結果都差不多。
他建議:鑒于Mistral-medium在代碼生成質量上有更好的體驗,應該把它整合到各地的代碼copilot中。
有人按照每1000token算出了輸入和輸出的成本,發現Mistral-medium比起GPT-4直接降低了70%!

的確,節省了70%的token費用,可不是一件小事。甚至還可以通過不冗長的輸出,來進一步節省成本。

-
模型
+關注
關注
1文章
3279瀏覽量
48974 -
代碼
+關注
關注
30文章
4808瀏覽量
68816 -
語言模型
+關注
關注
0文章
533瀏覽量
10300
原文標題:Mistral攜微軟引爆「小語言模型」潮!Mistral中杯代碼能力完勝GPT-4,成本暴降2/3
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Llama 3 與 GPT-4 比較
科大訊飛發布訊飛星火4.0 Turbo:七大能力超GPT-4 Turbo
Mistral Large 2現已在Amazon Bedrock中正式可用
OpenAI推出新模型CriticGPT,用GPT-4自我糾錯
OpenAI API Key獲取:開發人員申請GPT-4 API Key教程
開發者如何調用OpenAI的GPT-4o API以及價格詳情指南
GPT-4人工智能模型預測公司未來盈利勝過人類分析師
OpenAI全新GPT-4o能力炸場!速度快/成本低,能讀懂人類情緒
阿里云發布通義千問2.5大模型,多項能力超越GPT-4
商湯科技發布5.0多模態大模型,綜合能力全面對標GPT-4 Turbo
微軟Copilot全面更新為OpenAI的GPT-4 Turbo模型
新火種AI|秒殺GPT-4,狙殺GPT-5,橫空出世的Claude 3振奮人心!






 工商網監
工商網監
評論