 為什么HashMap會產生死循環呢?
為什么HashMap會產生死循環呢?
HashMap 死循環是一個比較常見、比較經典的問題,在日常的面試中出現的頻率比較高,今天這篇文章咱們就通過圖解的方式,帶大家徹底梳理和理解一下這個問題。
前置知識
首先我們要了解一下為什么會有這個問題的發生?
死循環問題發生在 JDK 1.7 版本中,造成這個問題主要是由于 HashMap 自身的運行機制,加上并發操作,從而導致了死循環。在 JDK 1.7 中 HashMap 的底層數據實現是數組 + 鏈表的方式,如下圖所示: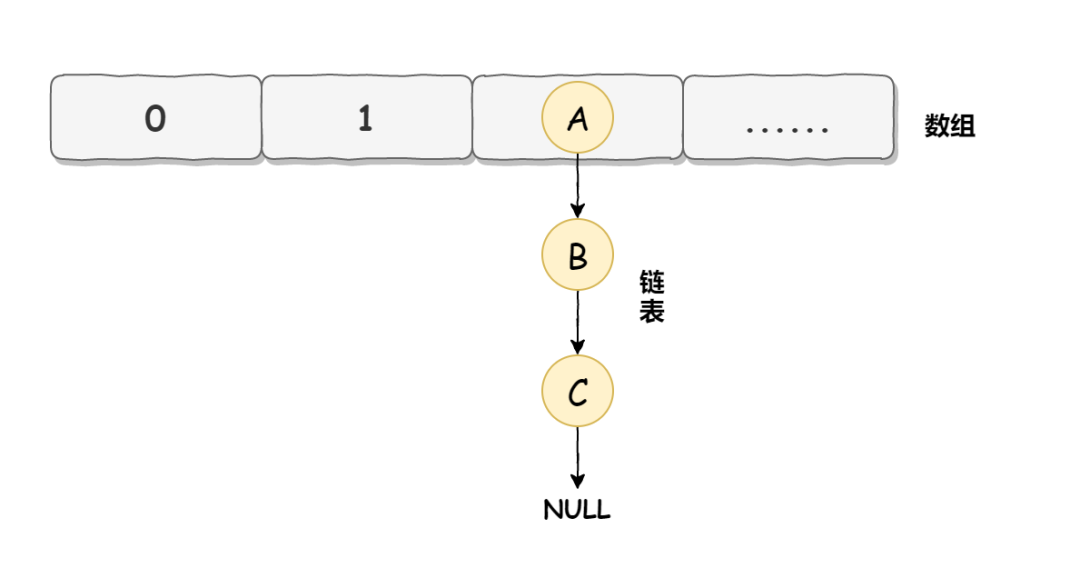
而 HashMap 在數據添加時使用的是頭插入,如下圖所示: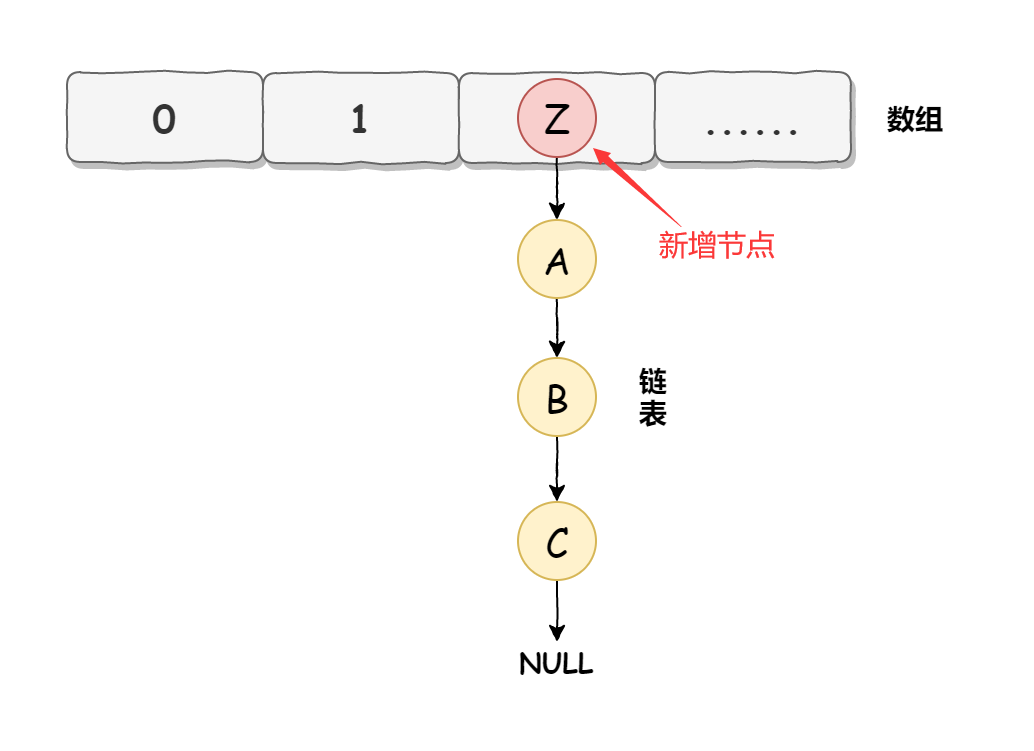
HashMap 正常情況下的擴容實現如下圖所示: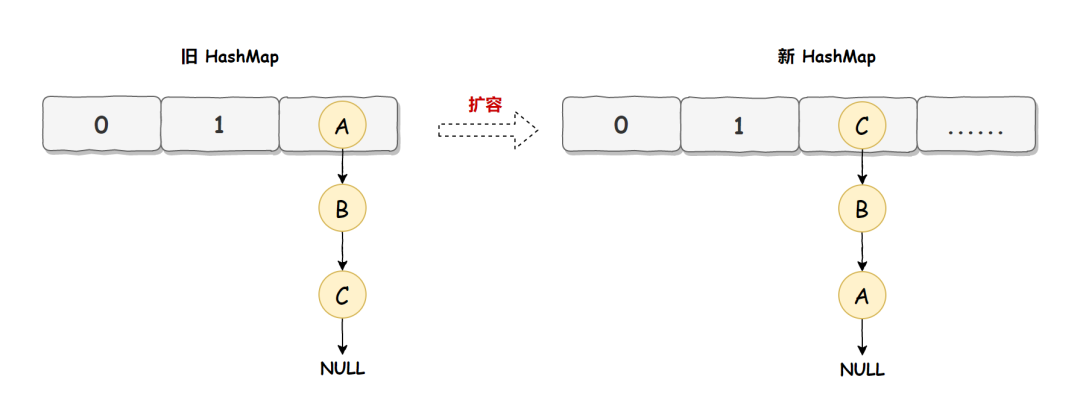
舊 HashMap 的節點會依次轉移到新 HashMap 中,舊 HashMap 轉移的順序是 A、B、C,而新 HashMap 使用的是頭插法,所以最終在新 HashMap 中的順序是 C、B、A,也就是上圖展示的那樣。有了這些前置知識之后,咱們來看死循環是如何誕生的?
死循環執行步驟1
死循環是因為并發 HashMap 擴容導致的,并發擴容的第一步,線程 T1 和線程 T2 要對 HashMap 進行擴容操作,此時 T1 和 T2 指向的是鏈表的頭結點元素 A,而 T1 和 T2 的下一個節點,也就是 T1.next 和 T2.next 指向的是 B 節點,如下圖所示: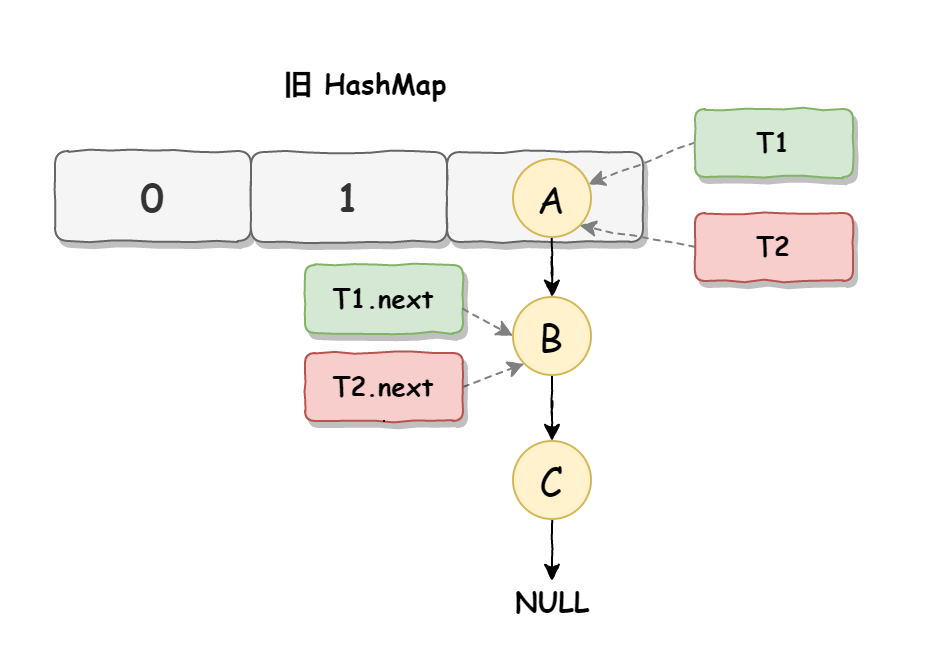
死循環執行步驟2
死循環的第二步操作是,線程 T2 時間片用完進入休眠狀態,而線程 T1 開始執行擴容操作,一直到線程 T1 擴容完成后,線程 T2 才被喚醒,擴容之后的場景如下圖所示: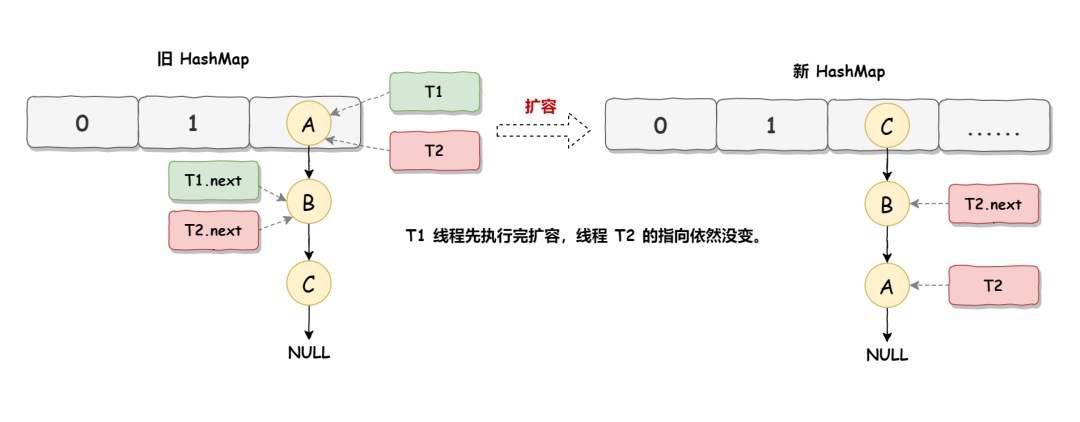
從上圖可知線程 T1 執行之后,因為是頭插法,所以 HashMap 的順序已經發生了改變,但線程 T2 對于發生的一切是不可知的,所以它的指向元素依然沒變,如上圖展示的那樣,T2 指向的是 A 元素,T2.next 指向的節點是 B 元素。
死循環執行步驟3
當線程 T1 執行完,而線程 T2 恢復執行時,死循環就建立了,如下圖所示: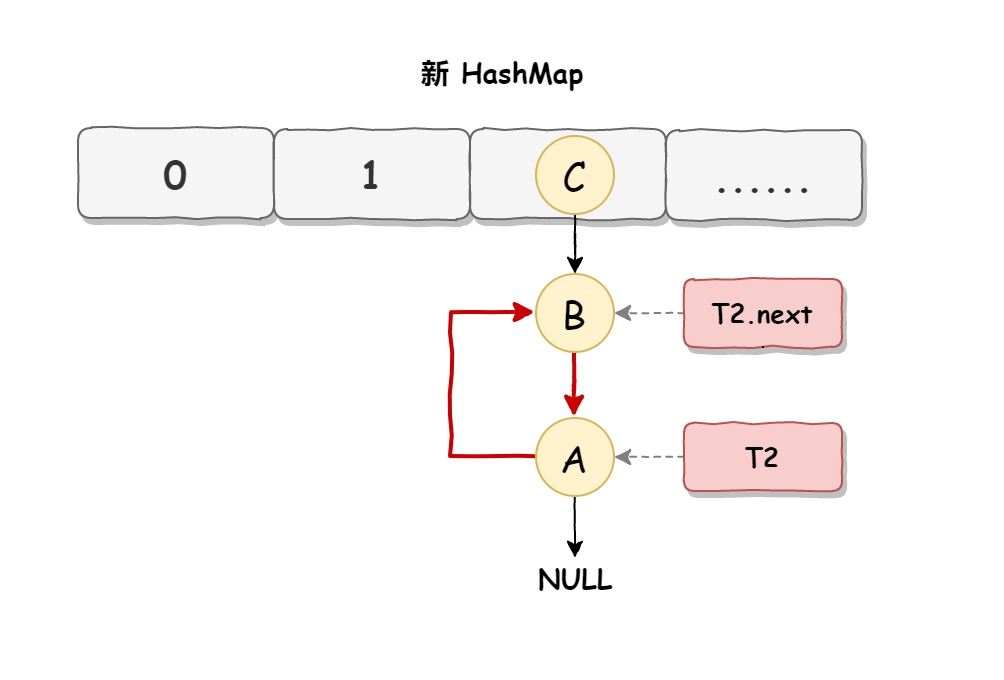
因為 T1 執行完擴容之后 B 節點的下一個節點是 A,而 T2 線程指向的首節點是 A,第二個節點是 B,這個順序剛好和 T1 擴完容完之后的節點順序是相反的。
T1 執行完之后的順序是 B 到 A,而 T2 的順序是 A 到 B,這樣 A 節點和 B 節點就形成死循環了,這就是 HashMap 死循環導致的原因。
解決方案
HashMap 死循環的常用解決方案有以下 3 個:
使用線程安全容器 ConcurrentHashMap 替代(推薦使用此方案)。
使用線程安全容器 Hashtable 替代(性能低,不建議使用)。
使用 synchronized 或 Lock 加鎖 HashMap 之后,再進行操作,相當于多線程排隊執行(比較麻煩,也不建議使用)。
總結
HashMap 死循環發生在 JDK 1.7 版本中,形成死循環的原因是 HashMap 在 JDK 1.7 使用的是頭插法,頭插法 + 鏈表 + 多線程并發 + HashMap 擴容,這幾個點加在一起就形成了 HashMap 的死循環,解決死鎖可以采用線程安全容器 ConcurrentHashMap 替代。
審核編輯:劉清
-
多線程
+關注
關注
0文章
278瀏覽量
19954 -
JDK
+關注
關注
0文章
81瀏覽量
16596 -
hashmap
+關注
關注
0文章
14瀏覽量
2288
原文標題:阿里二面:為什么HashMap會產生死循環
文章出處:【微信號:CodeSheep,微信公眾號:CodeSheep】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
你怎么樣用C語言編寫死循環呢
死鎖是什么?產生死鎖的主要原因有哪些
RT-Thread如何去發現該線程已經進入異常的死循環了呢?
關于Java HashMap的認知
為什么單片機的程序必須是死循環
為什么單片機的主程序是死循環
單片機的死循環有什么作用
如何避免Xil_Assert系列宏導致的死循環的情況

Too many open files錯誤導致服務器死循環
聊聊MCU死循環,用for(;;)還是while(1)?






 工商網監
工商網監
評論